From Hallucination to Grounding: Diagnosing Visual Spatial Intelligence via CRISP
Pith reviewed 2026-06-26 05:28 UTC · model grok-4.3
The pith
CRISP reveals that proprietary VLMs have strong latent reasoning but fail at metric estimation and using internal structures, while open-source models lack multi-hop reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
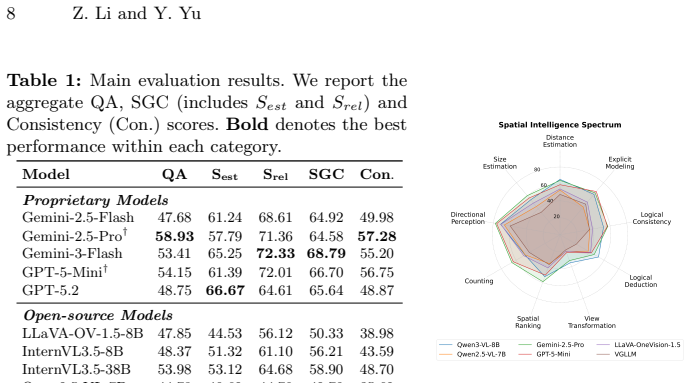
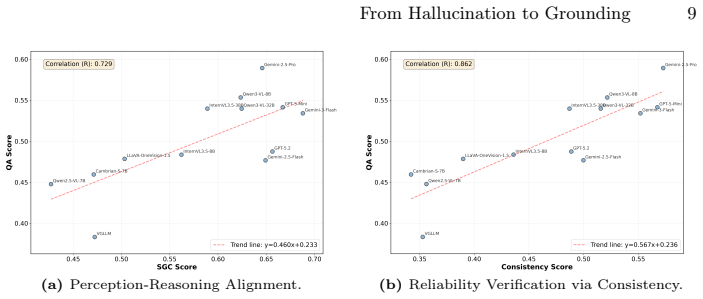
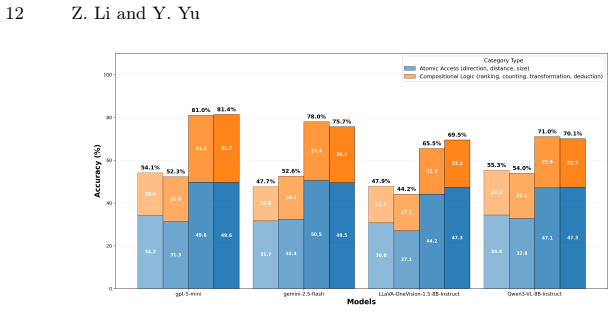
CRISP demonstrates a systematic perception-reasoning disconnect: proprietary models possess robust latent reasoning engines but suffer from inaccurate metric estimation and a critical failure to leverage their implicit structural representations, while open-source models remain fundamentally bottlenecked by their lack of multi-hop compositional reasoning.
What carries the argument
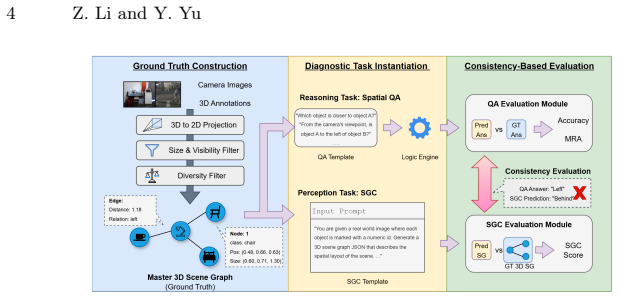
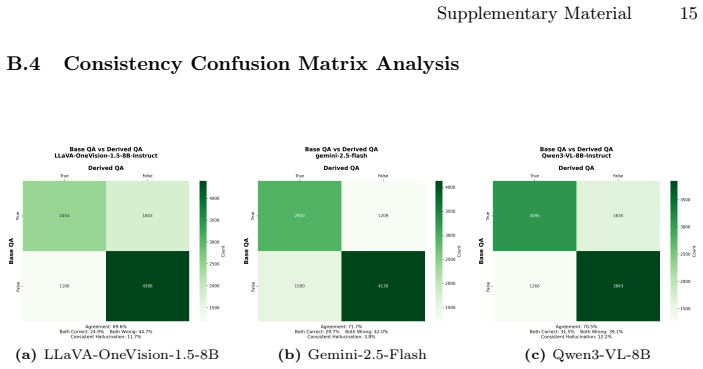
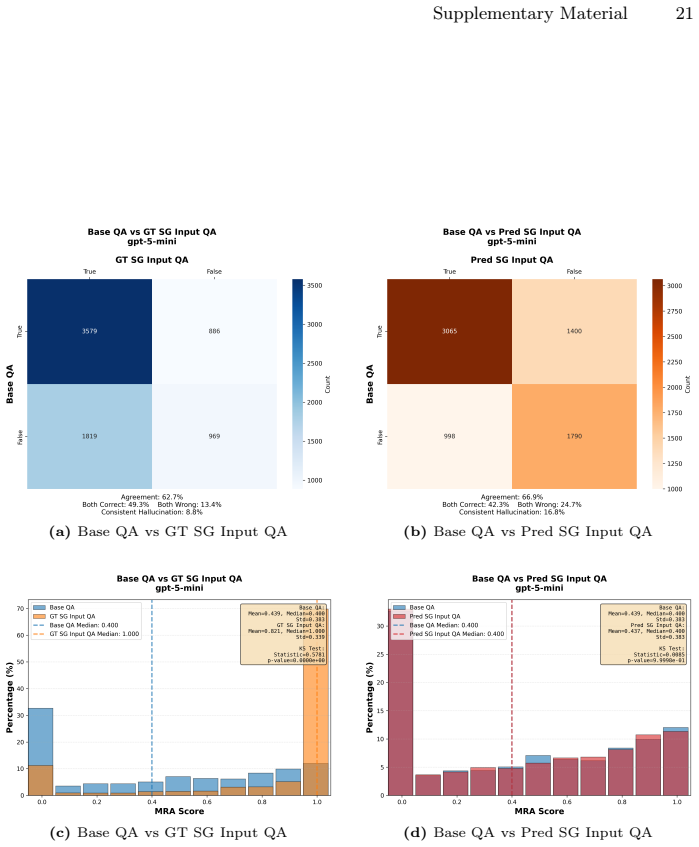
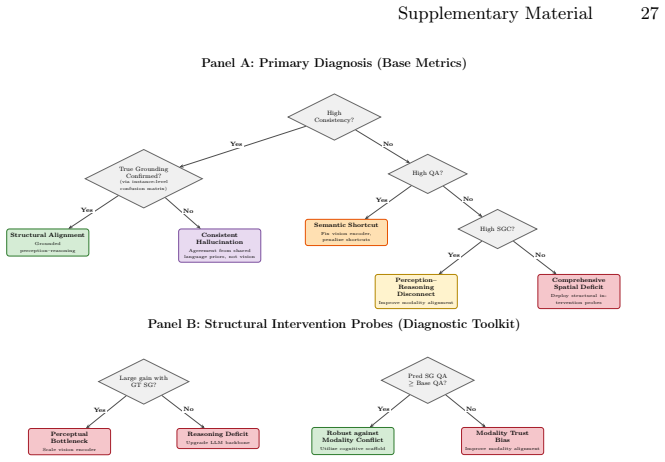
CRISP, the structural-diagnostic evaluation paradigm that measures consistency between implicit perception and explicit reasoning using metric 3D Scene Graphs and an oracle intervention protocol to isolate reasoning from perception.
If this is right
- Evaluation of vision-language models should shift from final-answer accuracy to explicit checks of perception-reasoning consistency.
- Proprietary models require targeted fixes for metric estimation and mechanisms that force use of already-present structural knowledge.
- Open-source models need architectural or training advances that enable multi-hop compositional reasoning.
- Progress in multimodal alignment will require methods that go beyond end-to-end post-training to enforce grounding.
Where Pith is reading between the lines
- CRISP-style diagnostics could be extended to other reasoning domains such as temporal or causal understanding to locate similar disconnects.
- Training objectives that reward explicit verification against internal representations might reduce the proprietary-model gap identified here.
- If the same disconnect appears on tasks outside spatial reasoning, current model scaling alone is unlikely to close it.
Load-bearing premise
The oracle intervention protocol and metric 3D Scene Graphs can separate latent reasoning from perceptual bottlenecks without adding their own biases or artifacts.
What would settle it
An experiment in which models given the oracle 3D graphs still produce the same error patterns as without them, or in which consistency scores remain low even after the intervention removes all perceptual error.
Figures






read the original abstract
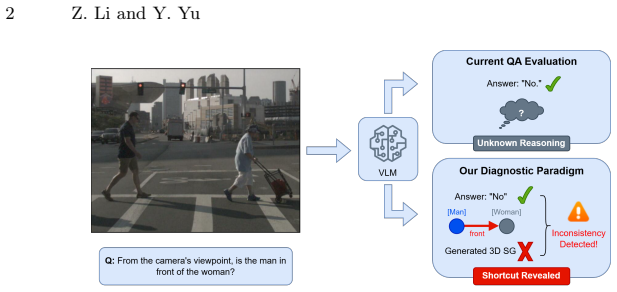
Current VLM evaluations often conflate language priors with genuine spatial reasoning. To address this, we introduce CRISP, a novel structural-diagnostic evaluation paradigm that assesses visual spatial intelligence through consistency, the alignment between implicit perception and explicit reasoning. Unlike traditional black-box QA, CRISP utilizes metric 3D Scene Graphs and an oracle intervention protocol to decouple latent reasoning capabilities from perceptual bottlenecks. This granular diagnosis uncovers a systematic perception-reasoning disconnect. Crucially, we reveal that while proprietary models possess robust latent reasoning engines, they suffer from inaccurate metric estimation and a critical failure to leverage their implicit structural representations. Conversely, open-source models remain fundamentally bottlenecked by their lack of multi-hop compositional reasoning. By shifting the focus from merely ``guessing correctly'' via language priors to genuinely ``perceiving, verifying, and reasoning,'' CRISP offers a rigorous roadmap for multimodal alignment beyond end-to-end post-training. The code and dataset are available at https://github.com/iiyamayuki/CRISP-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CRISP, a structural-diagnostic evaluation paradigm for assessing visual spatial intelligence in vision-language models (VLMs). Unlike standard black-box QA, CRISP employs metric 3D Scene Graphs as oracles and an intervention protocol to isolate latent reasoning from perceptual errors. The central findings are that proprietary models exhibit robust latent reasoning engines yet fail at accurate metric estimation and fail to exploit implicit structural representations, while open-source models are primarily limited by insufficient multi-hop compositional reasoning. Code and dataset are released.
Significance. If the oracle intervention protocol validly decouples perception from reasoning without artifacts, the work supplies a more granular diagnostic than existing VLM benchmarks and identifies concrete bottlenecks (metric estimation in proprietary models; compositional chaining in open-source models). The public release of the benchmark strengthens reproducibility and enables follow-up alignment research.
major comments (3)
- [Oracle intervention protocol (methodology section describing CRISP)] The central claim that proprietary models possess 'robust latent reasoning engines' while open-source models lack 'multi-hop compositional reasoning' depends on the oracle intervention protocol successfully isolating these capacities. The manuscript must demonstrate, via explicit ablations or controls, that injecting metric or structural information does not itself create new reasoning pathways or alter internal processing (see stress-test concern). Without such evidence the proprietary/open-source distinction risks being an artifact of the diagnostic setup.
- [Metric 3D Scene Graphs construction and validation] The assertion that 3D Scene Graphs provide an 'unbiased, complete structural representation' of the visual input actually received by the model requires verification that the graphs match the model's perceptual input distribution and do not introduce their own biases. The paper should report quantitative checks (e.g., agreement between graph-derived metrics and human annotations on the same images) and sensitivity analyses when graph completeness is varied.
- [Results and experimental setup] The reported perception-reasoning disconnect and model-type differences are presented as systematic; however, the abstract supplies no experimental details, sample sizes, statistical tests, or variance across runs. The results section must include these to establish that the observed gaps are not driven by prompt sensitivity or small test sets.
minor comments (2)
- [CRISP definition] Clarify the precise definition of 'consistency' used to measure alignment between implicit perception and explicit reasoning; the current description is high-level.
- [Reproducibility statement] The GitHub link is provided; ensure the released code exactly reproduces the reported oracle interventions and graph construction steps.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing our response and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Oracle intervention protocol (methodology section describing CRISP)] The central claim that proprietary models possess 'robust latent reasoning engines' while open-source models lack 'multi-hop compositional reasoning' depends on the oracle intervention protocol successfully isolating these capacities. The manuscript must demonstrate, via explicit ablations or controls, that injecting metric or structural information does not itself create new reasoning pathways or alter internal processing (see stress-test concern). Without such evidence the proprietary/open-source distinction risks being an artifact of the diagnostic setup.
Authors: We agree that explicit validation of the oracle intervention protocol is essential to support the claims. The manuscript describes the protocol and includes preliminary controls showing that open-source models continue to fail on compositional tasks even with full oracle input, while proprietary models improve on reasoning but not metric estimation. To further address potential artifacts, we will add dedicated ablations and stress-tests in the revision, including systematic variation of injected information and measurement of any changes in reasoning behavior. revision: yes
-
Referee: [Metric 3D Scene Graphs construction and validation] The assertion that 3D Scene Graphs provide an 'unbiased, complete structural representation' of the visual input actually received by the model requires verification that the graphs match the model's perceptual input distribution and do not introduce their own biases. The paper should report quantitative checks (e.g., agreement between graph-derived metrics and human annotations on the same images) and sensitivity analyses when graph completeness is varied.
Authors: We accept this point and will strengthen the validation of the metric 3D Scene Graphs. The revised manuscript will include quantitative agreement metrics between graph-derived values and human annotations on sampled images, along with sensitivity analyses that vary graph completeness and report resulting changes in model performance. These additions will confirm alignment with perceptual input and quantify any potential biases. revision: yes
-
Referee: [Results and experimental setup] The reported perception-reasoning disconnect and model-type differences are presented as systematic; however, the abstract supplies no experimental details, sample sizes, statistical tests, or variance across runs. The results section must include these to establish that the observed gaps are not driven by prompt sensitivity or small test sets.
Authors: We will expand the results section to report full experimental details, including test set sizes, statistical tests for significance, and variance across multiple runs and prompt variations. This will demonstrate that the observed perception-reasoning disconnect and model-type differences are robust. Note that abstracts conventionally omit such granular details, but the main text will be updated accordingly. revision: yes
Circularity Check
No circularity: empirical diagnosis relies on external oracles without self-referential reduction
full rationale
The paper's central claims rest on an introduced evaluation protocol (CRISP) that applies metric 3D Scene Graphs and oracle interventions to observed model outputs. These are presented as external diagnostic tools rather than quantities derived from or fitted to the target conclusions. No equations, predictions, or uniqueness theorems reduce by construction to the paper's own inputs or prior self-citations. The distinction between proprietary and open-source models is framed as an empirical finding from the protocol, not a definitional or fitted tautology. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Metric 3D Scene Graphs provide accurate ground-truth spatial relations independent of model perception
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Zhu, D., et al.: Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report (2025),https://arxiv.org/ abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621–11631 (2020)
2020
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Google: A new era of intelligence with Gemini 3 (2025),https://blog.google/ products/gemini/gemini-3, accessed: 2026-02-11
2025
-
[7]
arXiv preprint arXiv:2501.05444 (2025)
Hao, Y., Gu, J., Wang, H.W., Li, L., Yang, Z., Wang, L., Cheng, Y.: Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark. arXiv preprint arXiv:2501.05444 (2025)
-
[8]
arXiv preprint arXiv:2506.03135 (2025)
Jia, M., Qi, Z., Zhang, S., Zhang, W., Yu, X., He, J., Wang, H., Yi, L.: Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models. arXiv preprint arXiv:2506.03135 (2025)
-
[9]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Advances in neural information processing systems35, 24824–24837 (2022) 30 Z
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022) 30 Z. Li and Y.Yu
2022
-
[12]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Yang, S., Gupta, A.W., Han, R., Fei-Fei, L., Xie, S.: Thinking in space: How multimodal large language models see, remember, and recall spaces. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 10632– 10643 (2025)
2025
-
[13]
Cambrian-S: Towards Spatial Supersensing in Video
Yang, S., Yang, J., Huang, P., Brown, E., Yang, Z., Yu, Y., Tong, S., Zheng, Z., Xu, Y., Wang, M., et al.: Cambrian-s: Towards spatial supersensing in video. arXiv preprint arXiv:2511.04670 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Yang, S., Xu, R., Xie, Y., Yang, S., Li, M., Lin, J., Zhu, C., Chen, X., Duan, H., Yue, X., et al.: Mmsi-bench: A benchmark for multi-image spatial intelligence. arXiv preprint arXiv:2505.23764 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12–22 (2023)
2023
-
[16]
arXiv preprint arXiv:2505.24625 (2025)
Zheng, D., Huang, S., Li, Y., Wang, L.: Learning from videos for 3d world: En- hancing mllms with 3d vision geometry priors. arXiv preprint arXiv:2505.24625 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.