UniTac: A Unified Multimodal Model for Cross-Sensor Tactile Understanding and Generation
Pith reviewed 2026-07-01 05:53 UTC · model grok-4.3
The pith
UniTac unifies tactile understanding and generation across sensors by encoding both sensor and object attributes in a dual-level representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
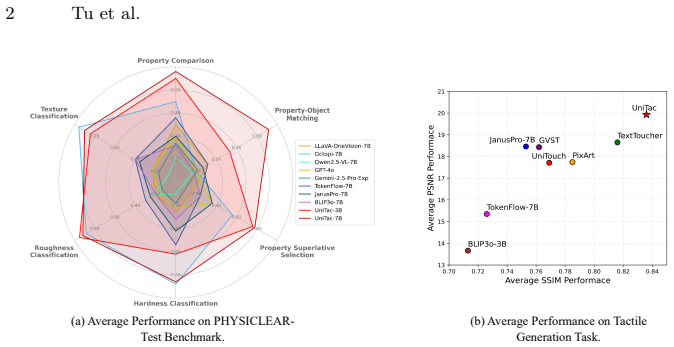
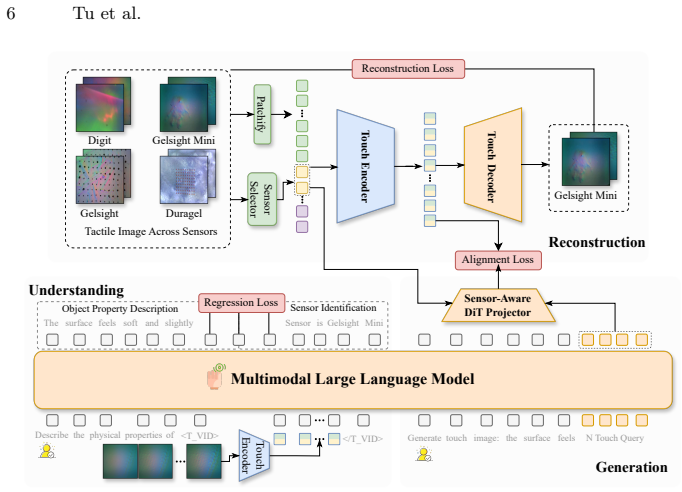
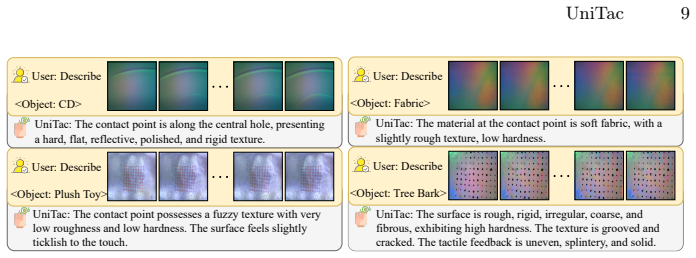
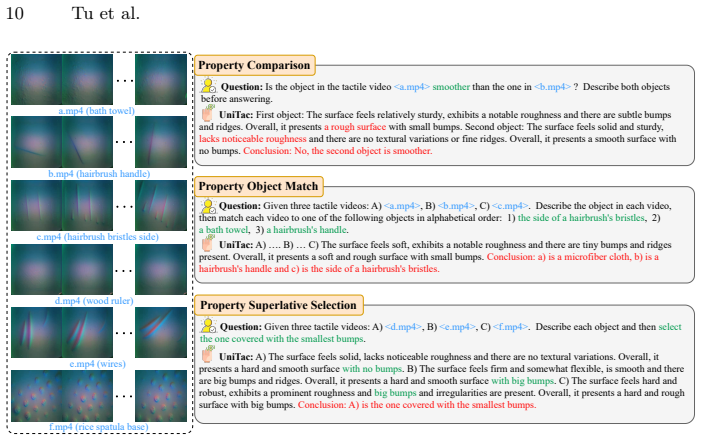
UniTac models the tactile process as a transition from non-contact to contact, capturing the physical interaction between sensors and objects through a dual-level representation that encodes both sensor and object attributes. For understanding, it introduces object property description and sensor identification tasks. For generation, a two-stage training paradigm consisting of reconstruction and alignment together with a sensor-prior-based sampling strategy enables realistic outputs. Trained on large-scale multi-sensor datasets, it achieves state-of-the-art performance in tactile understanding and generates realistic tactile signals across sensors.
What carries the argument
dual-level representation that jointly encodes sensor and object attributes, supported by sensor-prior-based sampling for contact simulation
If this is right
- Cross-sensor generalization in tactile tasks becomes possible without per-sensor engineering.
- Tactile understanding benefits from joint reasoning over object properties and sensor identity.
- Generated tactile signals can match the characteristics of multiple different sensor types.
- Two-stage reconstruction and alignment training produces realistic contact outputs.
Where Pith is reading between the lines
- Robotic systems could reuse the same tactile model when swapping between different hardware sensors.
- The emphasis on physical interaction modeling may extend to combining tactile data with other senses in one framework.
- Sensor priors could become a standard way to improve simulation accuracy for other contact-based modalities.
Load-bearing premise
The dual-level representation that jointly encodes sensor and object attributes, together with the sensor-prior-based sampling strategy, is sufficient to capture physical interactions and enable effective cross-sensor generalization without additional sensor-specific engineering.
What would settle it
Train on data from several known sensors, then generate tactile signals for a completely new unseen sensor type and measure whether the generated signals match real measurements collected from that sensor on the same objects.
Figures

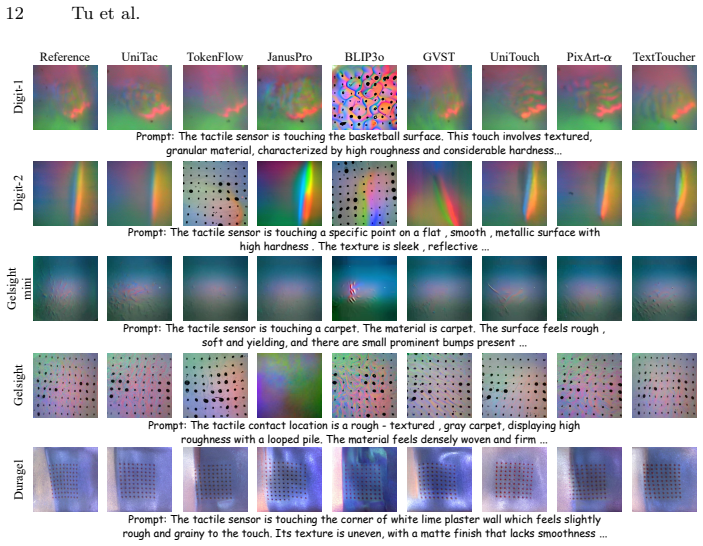
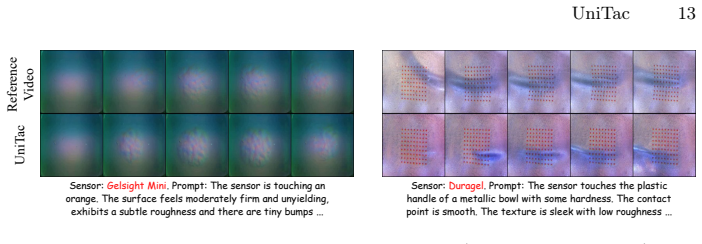

read the original abstract
Unified multimodal models (UMMs) have shown great promise in integrating understanding and generation across diverse modalities. However, existing research rarely extends this paradigm to the tactile domain, where both object-level semantics and sensor-level configurations jointly determine the meaning of touch. To address this gap, we propose UniTac, the first UMM designed for tactile understanding and generation. UniTac models the tactile process as a transition from non-contact to contact, capturing the physical interaction between sensors and objects through a dual-level representation that encodes both sensor and object attributes. For tactile understanding, UniTac introduces two tasks, object property description and sensor identification, to enhance reasoning over physical and cross-sensor information. For tactile generation, we design a two-stage training paradigm consisting of reconstruction and alignment, together with a sensor-prior-based sampling strategy that simulates realistic tactile contact. Trained on large-scale multi-sensor datasets, UniTac achieves state-of-the-art performance in tactile understanding and generates realistic tactile signals across sensors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniTac as the first unified multimodal model (UMM) for tactile understanding and generation across sensors. It frames tactile sensing as a non-contact to contact transition modeled via a dual-level representation jointly encoding sensor and object attributes. Understanding uses two tasks (object property description, sensor identification); generation uses two-stage training (reconstruction then alignment) plus sensor-prior-based sampling. Trained on large-scale multi-sensor data, the model claims SOTA performance in understanding tasks and realistic cross-sensor tactile signal generation.
Significance. If the central claims hold, the work would be significant for robotics by offering a single model that generalizes tactile understanding and generation across heterogeneous sensors without per-sensor engineering, potentially simplifying deployment in manipulation and perception pipelines. The dual-level attribute encoding and sensor-prior sampling constitute a concrete architectural hypothesis worth testing.
major comments (2)
- [Abstract] Abstract: the central SOTA and 'realistic generation' claims are asserted without any quantitative metrics, baselines, error bars, dataset sizes, or sensor counts, so the load-bearing performance assertions cannot be evaluated from the manuscript as presented.
- [Model description / §3] The dual-level representation (sensor + object attributes) plus sensor-prior sampling is presented as sufficient to capture the transition from non-contact to contact and enable cross-sensor generalization (§3, model description). However, tactile signals are generated by continuous mechanics (deformation fields, force propagation, material compliance) that are not obviously recoverable from discrete attribute embeddings; the manuscript provides no ablation or analysis showing that statistical correlations alone suffice without explicit physics-based inductive biases.
minor comments (2)
- [Abstract] Abstract: specify the exact number of sensors, total data volume, and the concrete understanding/generation metrics used to claim SOTA.
- [Training paradigm] Clarify whether the two-stage training paradigm includes any explicit contact-mechanics loss or simulation-based regularization, or relies solely on reconstruction + alignment objectives.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. We address each major point below and will revise the manuscript to strengthen the presentation of results and clarify the modeling assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA and 'realistic generation' claims are asserted without any quantitative metrics, baselines, error bars, dataset sizes, or sensor counts, so the load-bearing performance assertions cannot be evaluated from the manuscript as presented.
Authors: We agree that the abstract would benefit from concrete supporting details. In the revision we will add a concise summary of key quantitative results (e.g., accuracy/F1 on the two understanding tasks, generation metrics such as MSE or perceptual similarity, number of sensors and total samples) while remaining within length limits. revision: yes
-
Referee: [Model description / §3] The dual-level representation (sensor + object attributes) plus sensor-prior sampling is presented as sufficient to capture the transition from non-contact to contact and enable cross-sensor generalization (§3, model description). However, tactile signals are generated by continuous mechanics (deformation fields, force propagation, material compliance) that are not obviously recoverable from discrete attribute embeddings; the manuscript provides no ablation or analysis showing that statistical correlations alone suffice without explicit physics-based inductive biases.
Authors: The dual-level representation is deliberately attribute-based rather than physics-explicit; the model learns the mapping from these attributes to signals via large-scale multi-sensor data. Cross-sensor generation performance provides empirical evidence that the learned correlations are sufficient for the targeted tasks. We will add a short discussion paragraph in §3 and §5 acknowledging the absence of explicit mechanics and the reliance on data-driven capture, and we will include an ablation on the dual-level components if space permits. revision: partial
Circularity Check
No circularity: architecture and training claims rest on empirical results, not self-referential reductions
full rationale
The paper presents UniTac as a new multimodal model using dual-level sensor/object attribute encoding, two-stage training (reconstruction + alignment), and sensor-prior sampling. No equations, fitted parameters renamed as predictions, or derivation chains appear in the abstract or description. Central claims of SOTA performance and cross-sensor generalization are positioned as outcomes of training on large-scale multi-sensor datasets, with no load-bearing self-citations, uniqueness theorems, or ansatzes that reduce to the inputs by construction. This is a standard empirical ML proposal; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Baishya, S.S., Bäuml, B.: Robust material classification with a tactile skin using deep learning. In: 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 8–15. IEEE (2016)
2016
-
[3]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al.: Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568 (2025) 16 Tu et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., et al.: Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:2310.00426 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2505.04201 (2025)
Cheng, N., Xu, J., Chen, J., Han, W.: Stola: Self-adaptive touch-language frame- work with tactile commonsense reasoning in open-ended scenarios. arXiv preprint arXiv:2505.04201 (2025)
-
[7]
Information Fusion p
Cheng, N., Xu, J., Guan, C., Gao, J., Wang, W., Li, Y., Meng, F., Zhou, J., Fang, B., Han, W.: Touch100k: A large-scale touch-language-vision dataset for touch- centric multimodal representation. Information Fusion p. 103305 (2025)
2025
-
[8]
arXiv preprint arXiv:2508.08706 (2025)
Cheng, Z., Zhang, Y., Zhang, W., Li, H., Wang, K., Song, L., Zhang, H.: Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing. arXiv preprint arXiv:2508.08706 (2025)
-
[9]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Dou, Y., Yang, F., Liu, Y., Loquercio, A., Owens, A.: Tactile-augmented radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26529–26539 (2024)
2024
-
[11]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[12]
arXiv preprint arXiv:2502.12191 (2025)
Feng, R., Hu, J., Xia, W., Gao, T., Shen, A., Sun, Y., Fang, B., Hu, D.: Any- touch: Learning unified static-dynamic representation across multiple visuo-tactile sensors. arXiv preprint arXiv:2502.12191 (2025)
-
[13]
arXiv preprint arXiv:2402.13232 (2024)
Fu, L., Datta, G., Huang, H., Panitch, W.C.H., Drake, J., Ortiz, J., Mukadam, M., Lambeta, M., Calandra, R., Goldberg, K.: A touch, vision, and language dataset for multimodal alignment. arXiv preprint arXiv:2402.13232 (2024)
-
[14]
Advances in Neural Information Processing Systems37, 29839–29863 (2024)
Gao, R., Deng, K., Yang, G., Yuan, W., Zhu, J.Y.: Tactile dreamfusion: Exploit- ing tactile sensing for 3d generation. Advances in Neural Information Processing Systems37, 29839–29863 (2024)
2024
-
[15]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
In: 2010 IEEE International Conference on Robotics and Automation
Jamali, N., Sammut, C.: Material classification by tactile sensing using surface textures. In: 2010 IEEE International Conference on Robotics and Automation. pp. 2336–2341. IEEE (2010)
2010
-
[19]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition
Johnson,M.K.,Adelson,E.H.:Retrographicsensingforthemeasurementofsurface texture and shape. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 1070–1077. IEEE (2009) UniTac 17
2009
-
[20]
arXiv preprint arXiv:2209.13042 (2022)
Kerr, J., Huang, H., Wilcox, A., Hoque, R., Ichnowski, J., Calandra, R., Goldberg, K.: Self-supervised visuo-tactile pretraining to locate and follow garment features. arXiv preprint arXiv:2209.13042 (2022)
-
[21]
IEEE Robotics and Automation Letters5(3), 3838–3845 (2020)
Lambeta, M., Chou, P.W., Tian, S., Yang, B., Maloon, B., Most, V.R., Stroud, D., Santos, R., Byagowi, A., Kammerer, G., et al.: Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation. IEEE Robotics and Automation Letters5(3), 3838–3845 (2020)
2020
-
[22]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, S., Kallidromitis, K., Gokul, A., Liao, Z., Kato, Y., Kozuka, K., Grover, A.: Omniflow: Any-to-any generation with multi-modal rectified flows. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13178–13188 (2025)
2025
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Y., Zhu, J.Y., Tedrake, R., Torralba, A.: Connecting touch and vision via cross- modal prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10609–10618 (2019)
2019
-
[25]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
arXiv preprint arXiv:2505.20498 (2025)
Luo, D., Yu, K., Shahidzadeh, A.H., Fermüller, C., Aloimonos, Y., Gao, R.: Con- troltac: Force-and position-controlled tactile data augmentation with a single ref- erence image. arXiv preprint arXiv:2505.20498 (2025)
-
[27]
IEEE Transactions on Robotics39(3), 2003– 2019 (2023)
Luu, Q.K., Nguyen, N.H., et al.: Simulation, learning, and application of vision- based tactile sensing at large scale. IEEE Transactions on Robotics39(3), 2003– 2019 (2023)
2003
-
[28]
arXiv preprint arXiv:2505.08194 (2025)
Ma, W., Cao, X., Zhang, Y., Zhang, C., Yang, S., Hao, P., Fang, B., Cai, Y., Cui, S., Wang, S.: Cltp: Contrastive language-tactile pre-training for 3d contact geometry understanding. arXiv preprint arXiv:2505.08194 (2025)
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ma, Y., Liu, X., Chen, X., Liu, W., Wu, C., Wu, Z., Pan, Z., Xie, Z., Zhang, H., Yu, X., et al.: Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7739–7751 (2025)
2025
-
[30]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Qu, L., Zhang, H., Liu, Y., Wang, X., Jiang, Y., Gao, Y., Ye, H., Du, D.K., Yuan, Z., Wu, X.: Tokenflow: Unified image tokenizer for multimodal understanding and generation. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 2545–2555 (2025)
2025
-
[31]
arXiv preprint arXiv:2409.08269 (2024)
Rodriguez, S., Dou, Y., Oller, M., Owens, A., Fazeli, N.: Touch2touch: Cross-modal tactile generation for object manipulation. arXiv preprint arXiv:2409.08269 (2024)
-
[32]
arXiv preprint arXiv:2412.15188 (2024)
Shi,W.,Han,X.,Zhou,C.,Liang,W.,Lin,X.V.,Zettlemoyer,L.,Yu,L.:Lmfusion: Adapting pretrained language models for multimodal generation. arXiv preprint arXiv:2412.15188 (2024)
-
[33]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Stefani, A.L., Bisagno, N., Conci, N., De Natale, F.: Splattouch: Explicit 3d rep- resentation binding vision and touch. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 118–127 (2025)
2025
-
[34]
IEEE Transactions on Systems, Man, and Cyber- netics: Systems46(7), 969–979 (2016)
Sun, F., Liu, C., Huang, W., Zhang, J.: Object classification and grasp planning using visual and tactile sensing. IEEE Transactions on Systems, Man, and Cyber- netics: Systems46(7), 969–979 (2016)
2016
-
[35]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024) 18 Tu et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Tu, J., Fu, H., Yang, F., Zhao, H., Zhang, C., Qian, H.: Texttoucher: Fine-grained text-to-touch generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7455–7463 (2025)
2025
-
[37]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y., et al.: Sana: Efficient high-resolution image synthesis with linear diffusion transformers. arXiv preprint arXiv:2410.10629 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. arXiv preprint arXiv:2408.12528 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
arXiv preprint arXiv:2505.22566 (2025)
Xie, Y., Li, M., Li, S., Li, X., Chen, G., Ma, F., Yu, F.R., Ding, W.: Univer- sal visuo-tactile video understanding for embodied interaction. arXiv preprint arXiv:2505.22566 (2025)
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, F., Feng, C., Chen, Z., Park, H., Wang, D., Dou, Y., Zeng, Z., Chen, X., Gangopadhyay, R., Owens, A., et al.: Binding touch to everything: Learning unified multimodal tactile representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26340–26353 (2024)
2024
-
[44]
arXiv preprint arXiv:2211.12498 (2022)
Yang, F., Ma, C., Zhang, J., Zhu, J., Yuan, W., Owens, A.: Touch and go: Learning from human-collected vision and touch. arXiv preprint arXiv:2211.12498 (2022)
-
[45]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Yang, F., Zhang, J., Owens, A.: Generating visual scenes from touch. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 22070– 22080 (2023)
2023
-
[46]
arXiv preprint arXiv:2405.02794 (2024)
Yu, S., Lin, K., Xiao, A., Duan, J., Soh, H.: Octopi: Object property reasoning with large tactile-language models. arXiv preprint arXiv:2405.02794 (2024)
-
[47]
Sensors17(12), 2762 (2017)
Yuan, W., Dong, S., Adelson, E.H.: Gelsight: High-resolution robot tactile sensors for estimating geometry and force. Sensors17(12), 2762 (2017)
2017
-
[48]
arXiv preprint arXiv:2505.09577 (2025)
Zhang, C., Hao, P., Cao, X., Hao, X., Cui, S., Wang, S.: Vtla: Vision-tactile- language-action model with preference learning for insertion manipulation. arXiv preprint arXiv:2505.09577 (2025)
-
[49]
IEEE Sensors Journal 24(9), 15273–15282 (2024)
Zhang, S., Yang, Y., Sun, F., Bao, L., Shan, J., Gao, Y., Fang, B.: A compact visuo-tactile robotic skin for micron-level tactile perception. IEEE Sensors Journal 24(9), 15273–15282 (2024)
2024
-
[50]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., Levy, O.: Transfusion: Predict the next token and diffuse images with one multi-modal model. arXiv preprint arXiv:2408.11039 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
<T_VID>[tactile tokens]</T_VID>Describe the physical properties of the contacted surface,
Zhuo, L., Du, R., Xiao, H., Li, Y., Liu, D., Huang, R., Liu, W., Zhu, X., Wang, F.Y., Ma, Z., et al.: Lumina-next: Making lumina-t2x stronger and faster with next-dit. Advances in Neural Information Processing Systems37, 131278–131315 (2024) UniTac 1 Overview.In this supplementary material, we submit the source code in the “UniTac” folder and provide more...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.