What Memory Do GUI Agents Really Need? From Passive Records to Active Task-Driving States
Pith reviewed 2026-07-01 05:24 UTC · model grok-4.3
The pith
GUI agents perform long-horizon tasks more reliably when memory actively maintains each value's role and status instead of passive records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
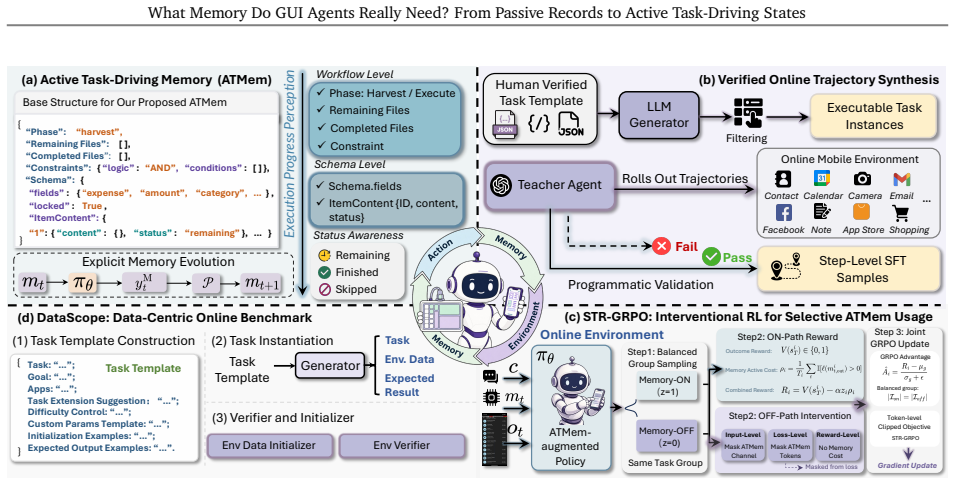
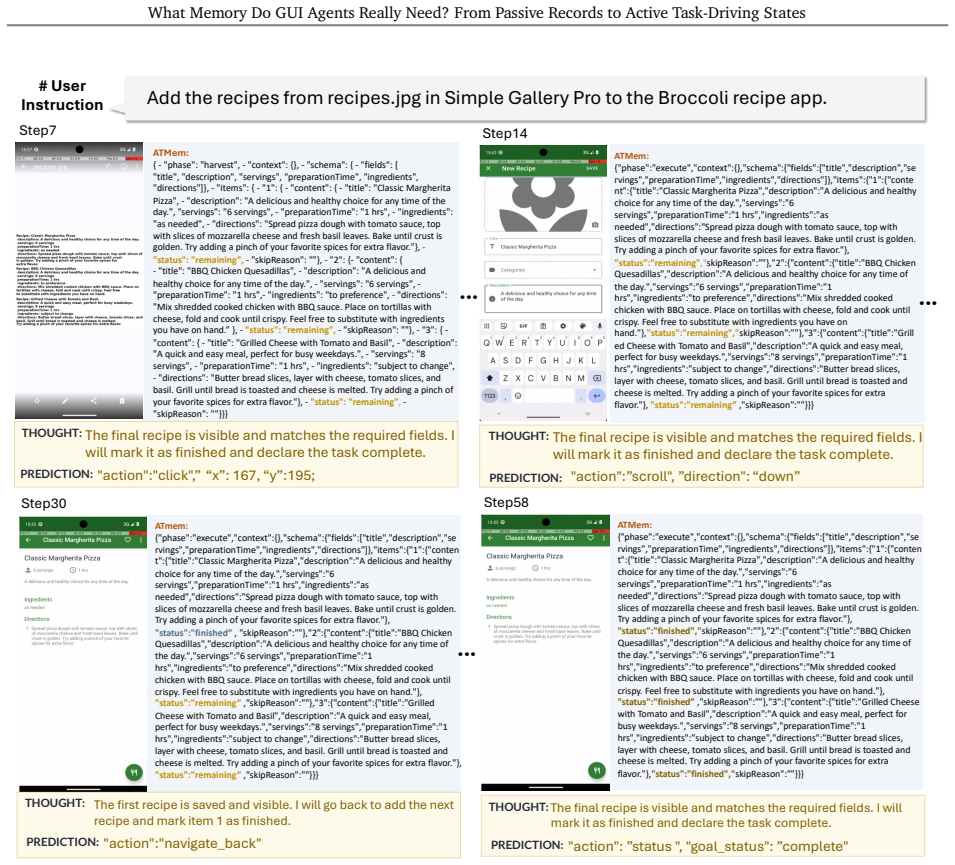
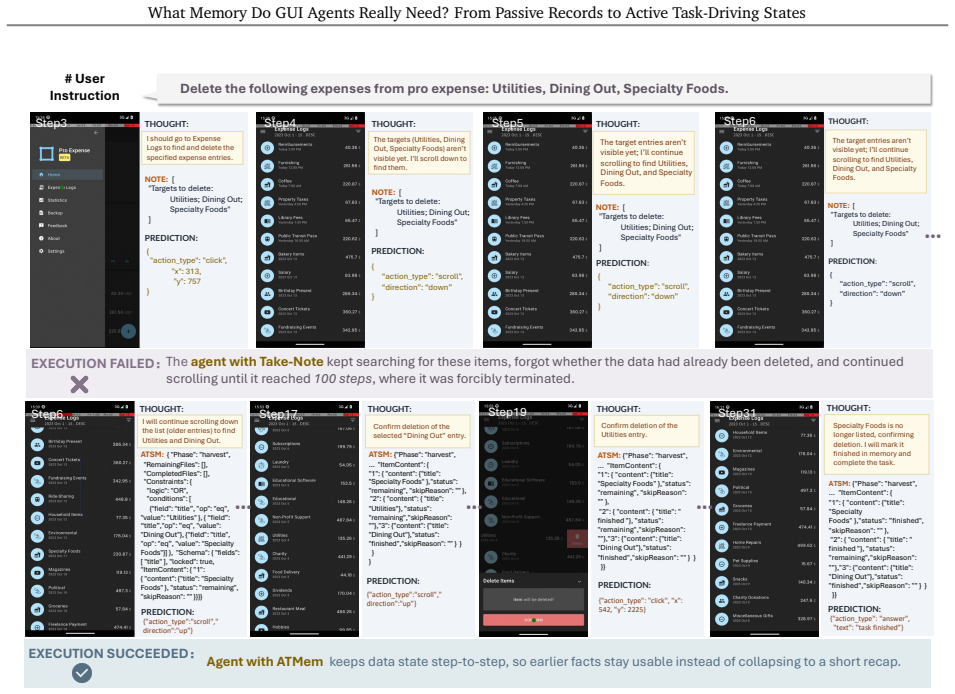
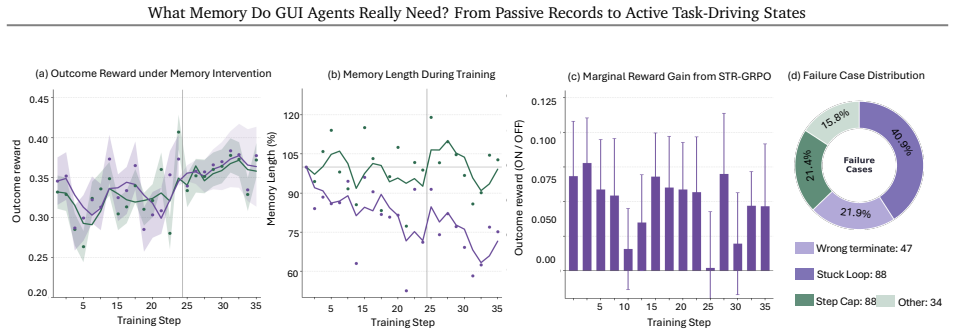
ATMem shifts GUI-agent memory from passive storage to an actively maintained execution state that links each value to its role and current status, enabling action selection based on the current workflow state rather than implicit reconstruction from accumulated records.
What carries the argument
Active Task Driving Memory (ATMem), which maintains an execution state linking values to roles and statuses for direct workflow-based decisions.
If this is right
- Agents can select actions without inferring value relevance from raw records, reducing errors in complex tasks.
- STR-GRPO enables learning when to use memory to improve task completion while minimizing unnecessary costs.
- The new benchmark allows evaluation of complete in-scope work and avoidance of out-of-scope actions over long horizons.
- Memory use becomes tied to actual contribution to execution success.
Where Pith is reading between the lines
- ATMem could be adapted to non-mobile GUI environments or other agent domains with similar long-horizon challenges.
- Explicit state maintenance might interact with LLM context limits in ways that reduce overall token usage.
- Future work might test if the role-status linking reduces the frequency of hallucinated or outdated actions.
- The contrastive RL approach in STR-GRPO may apply to other memory or tool-use decisions in agents.
Load-bearing premise
Explicitly linking each value to its role and current status will allow reliable action selection without introducing new inference errors or excessive overhead.
What would settle it
An experiment showing that agents with ATMem still repeat operations or miss required actions in trajectories containing similar fields, repeated values, and distractors would falsify the benefit of the active state.
Figures


read the original abstract
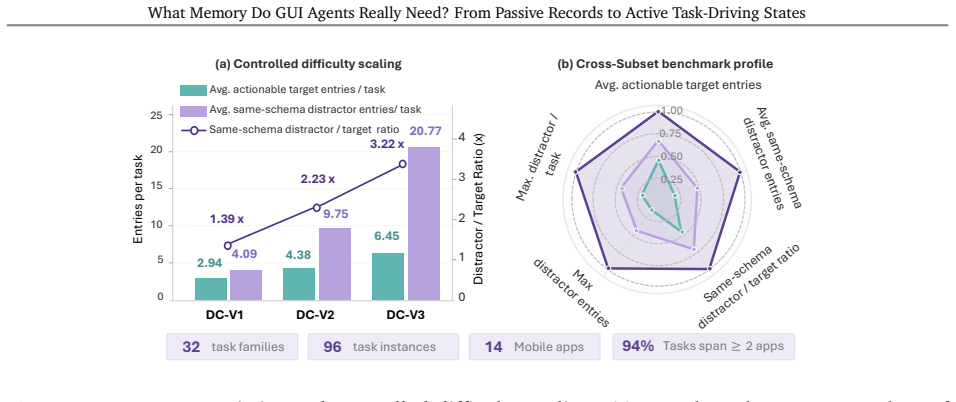
Mobile GUI agents increasingly face long-horizon tasks that require reading, updating, and reusing task-relevant data across pages and applications. Existing memory methods treat memory largely as passive storage, where past observations are accumulated and retrieved when needed. Yet retrieving a value does not reveal its current role in the workflow. The agent must still infer from accumulated records whether the value should be used now, has already been used, or must wait for a later dependency. This implicit reconstruction becomes unreliable in long trajectories with similar fields, repeated values, distractors, and outdated states, causing repeated or missed operations. We propose Active Task Driving Memory (ATMem), which shifts GUI-agent memory from passive storage to an actively maintained execution state. ATMem maintains task-relevant information as a continually updated execution state that links each value to its role and current status, enabling action selection based on the current workflow state. We therefore introduce \textbf{STR-GRPO}, an online reinforcement learning method that learns to use ATMem selectively according to its contribution to task completion. STR-GRPO contrasts memory-on and memory-off rollouts to estimate when memory use improves execution, while memory-cost-aware reward discourages costly memory usage that does not improve execution. To evaluate whether agents can complete all in-scope work while avoiding out-of-scope actions over long-horizon execution, we build a challenging mobile benchmark. From a list of near identical entries, agents must act on every entry that satisfies the instruction and reject entries that violate its constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that passive memory in GUI agents forces unreliable implicit inference of value roles and statuses in long-horizon tasks with distractors and repeated values, and proposes Active Task Driving Memory (ATMem) as an actively maintained execution state that explicitly links each value to its workflow role and current status. It introduces STR-GRPO, an online RL algorithm that contrasts memory-on and memory-off rollouts with a memory-cost-aware reward to learn selective use of ATMem, and presents a new mobile GUI benchmark requiring agents to act on every in-scope entry while rejecting out-of-scope ones.
Significance. If the empirical results hold, the work could usefully shift GUI-agent memory design toward explicit, actively updated state representations rather than passive retrieval. The benchmark's emphasis on complete coverage without extraneous actions addresses a relevant evaluation gap. STR-GRPO's on/off contrast provides a falsifiable way to measure memory utility, which is a methodological strength.
major comments (2)
- [§3] §3 (ATMem definition): the central claim that ATMem 'links each value to its role and current status' enabling reliable action selection is not supported by any description of the mechanism that populates or corrects those links. If role/status assignment is performed by the same LLM policy already shown to struggle with distractors, repeated values, and outdated states, the explicit representation relocates rather than removes the inference problem; this is load-bearing for the claim that ATMem improves execution over passive records.
- [§4] §4 (STR-GRPO): the memory-on vs memory-off contrast assumes that the difference isolates the benefit of explicit state maintenance, but without evidence that role/status links are assigned independently of the policy's inference errors, the contrast may simply compare two error-prone processes; this undermines the interpretation of the reward signal.
minor comments (2)
- [§3] The abstract and introduction repeatedly use 'execution state' without a formal definition or pseudocode; add a concise definition or diagram in §3.
- Table or figure captions for the benchmark should explicitly state the number of trajectories, average length, and distractor density to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important aspects of our claims regarding ATMem and STR-GRPO. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (ATMem definition): the central claim that ATMem 'links each value to its role and current status' enabling reliable action selection is not supported by any description of the mechanism that populates or corrects those links. If role/status assignment is performed by the same LLM policy already shown to struggle with distractors, repeated values, and outdated states, the explicit representation relocates rather than removes the inference problem; this is load-bearing for the claim that ATMem improves execution over passive records.
Authors: We agree that §3 currently presents ATMem at a conceptual level without sufficient detail on the population and correction mechanisms. The manuscript describes ATMem as a structured execution state that is actively updated during task execution, with the policy deciding updates based on new observations and workflow progress. The explicit linking is intended to reduce repeated implicit inference from raw records. However, we acknowledge the referee's point that without explicit mechanisms (e.g., update rules or examples), the claim risks relocating rather than resolving the inference burden. We will revise §3 to include a more precise description of the state update process, including how the policy interacts with the structured fields. revision: yes
-
Referee: [§4] §4 (STR-GRPO): the memory-on vs memory-off contrast assumes that the difference isolates the benefit of explicit state maintenance, but without evidence that role/status links are assigned independently of the policy's inference errors, the contrast may simply compare two error-prone processes; this undermines the interpretation of the reward signal.
Authors: The memory-on versus memory-off design in STR-GRPO is meant to isolate the value of explicit state access by giving the memory-off condition the same raw observations but without the structured ATMem representation. The reward signal derives from task completion metrics on the benchmark, which penalizes both missed in-scope actions and extraneous out-of-scope actions. We recognize that the links are not assigned by an independent oracle and that policy errors can affect both conditions; the contrast therefore measures net utility rather than pure isolation of maintenance quality. The empirical gains on long-horizon tasks with distractors support that the structured state provides a measurable advantage. We will add a limitations paragraph discussing this interpretive caveat while retaining the current experimental framing. revision: partial
Circularity Check
No circularity: proposal of new memory structure and RL method with no derivations or self-referential reductions.
full rationale
The paper proposes ATMem as an actively maintained execution state linking values to roles/status and STR-GRPO as an RL method contrasting memory-on/off rollouts with cost-aware rewards. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim is a design shift from passive to active memory, justified by described limitations of prior approaches rather than reducing to its own inputs by construction. The benchmark and evaluation are presented as external tests. This is a standard non-circular proposal of an architectural change.
Axiom & Free-Parameter Ledger
invented entities (2)
-
ATMem
no independent evidence
-
STR-GRPO
no independent evidence
Reference graph
Works this paper leans on
-
[3]
Spa-bench: A comprehensive benchmark for smartphone agent evaluation
Jingxuan Chen, Derek Yuen, Bin Xie, Yuhao Yang, Gongwei Chen, Zhihao Wu, Li Yixing, Xurui Zhou, Weiwen Liu, Shuai Wang, et al. Spa-bench: A comprehensive benchmark for smartphone agent evaluation. In NeurIPS 2024 Workshop on Open-World Agents, 2024
2024
-
[7]
Developing a computer use model
DeepMind . Developing a computer use model . Google Blog, Oct 2025. URL https://blog.google/technology/google-deepmind/gemini-computer-use-model/. Accessed: October 22, 2025
2025
-
[8]
Mobile-bench: An evaluation benchmark for llm-based mobile agents
Shihan Deng, Weikai Xu, Hongda Sun, Wei Liu, Tao Tan, Liujianfeng Liujianfeng, Ang Li, Jian Luan, Bin Wang, Rui Yan, et al. Mobile-bench: An evaluation benchmark for llm-based mobile agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8813--8831, 2024
2024
-
[11]
Mobilegpt: Augmenting llm with human-like app memory for mobile task automation
Sunjae Lee, Junyoung Choi, Jungjae Lee, Munim Hasan Wasi, Hojun Choi, Steve Ko, Sangeun Oh, and Insik Shin. Mobilegpt: Augmenting llm with human-like app memory for mobile task automation. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pages 1119--1133, 2024
2024
-
[15]
Introducing openai o3 and o4-mini
Team OpenAI. Introducing openai o3 and o4-mini. https://openai. com/index/introducing-o3-and-o4-mini/, 2025
2025
-
[16]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1--22, 2023
2023
-
[18]
Androidinthewild: A large-scale dataset for android device control
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems, 36: 0 59708--59728, 2023
2023
-
[20]
Constructive memory: past and future
Daniel L Schacter. Constructive memory: past and future. Dialogues in clinical neuroscience, 14 0 (1): 0 7--18, 2012
2012
-
[21]
The cognitive neuroscience of constructive memory: Remembering the past and imagining the future
Daniel L Schacter and Donna Rose Addis. The cognitive neuroscience of constructive memory: Remembering the past and imagining the future. Philosophical Transactions of the Royal Society B: Biological Sciences, 362 0 (1481): 0 773, 2007
2007
-
[22]
Seed1.8 model card: Towards generalized real-world agency
Bytedance Seed. Seed1.8 model card: Towards generalized real-world agency. arXiv preprint, December 2025 a . Technical Report
2025
-
[23]
Ui-tars-1.5
ByteDance Seed. Ui-tars-1.5. https://seed-tars.com/1.5, 2025 b
2025
-
[24]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems, 36: 0 8634--8652, 2023
2023
-
[28]
Cognitive architectures for language agents
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents. Transactions on Machine Learning Research, 2023
2023
-
[29]
Fairy: Interactive mobile assistant to real-world tasks via lmm-based multi-agent
Jiazheng Sun, Te Yang, Jiayang Niu, Mingxuan Li, Yongyong Lu, Ruimeng Yang, and Xin Peng. Fairy: Interactive mobile assistant to real-world tasks via lmm-based multi-agent. arXiv e-prints, pages arXiv--2509, 2025
2025
-
[31]
Gelab-zero: An advanced mobile agent inference system, 2025
GELab Team. Gelab-zero: An advanced mobile agent inference system, 2025. URL https://github.com/stepfun-ai/gelab-zero
2025
-
[35]
Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration. Advances in Neural Information Processing Systems, 37: 0 2686--2710, 2024 a
2024
-
[38]
Autodroid: Llm-powered task automation in android
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. Autodroid: Llm-powered task automation in android. In Proceedings of the 30th annual international conference on Mobile computing and networking, pages 543--557, 2024
2024
-
[42]
Androidlab: Training and systematic benchmarking of android autonomous agents
Yifan Xu, Xiao Liu, Xueqiao Sun, Siyi Cheng, Hao Yu, Hanyu Lai, Shudan Zhang, Dan Zhang, Jie Tang, and Yuxiao Dong. Androidlab: Training and systematic benchmarking of android autonomous agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2144--2166, 2025 b
2025
-
[43]
Step-gui technical report, 2025
Haolong Yan, Jia Wang, Xin Huang, Yeqing Shen, Ziyang Meng, Zhimin Fan, Kaijun Tan, Jin Gao, Lieyu Shi, Mi Yang, Shiliang Yang, Zhirui Wang, Brian Li, Kang An, Chenyang Li, Lei Lei, Mengmeng Duan, Danxun Liang, Guodong Liu, Hang Cheng, Hao Wu, Jie Dong, Junhao Huang, Mei Chen, Renjie Yu, Shunshan Li, Xu Zhou, Yiting Dai, Yineng Deng, Yingdan Liang, Zelin ...
-
[47]
Appagent: Multimodal agents as smartphone users
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1--20, 2025
2025
-
[50]
Moba: multifaceted memory-enhanced adaptive planning for efficient mobile task automation
Zichen Zhu, Hao Tang, Yansi Li, Dingye Liu, Hongshen Xu, Kunyao Lan, Danyang Zhang, Yixuan Jiang, Hao Zhou, Chenrun Wang, et al. Moba: multifaceted memory-enhanced adaptive planning for efficient mobile task automation. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Lang...
2025
-
[51]
Transactions on Machine Learning Research , year=
Cognitive architectures for language agents , author=. Transactions on Machine Learning Research , year=
-
[52]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[53]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[54]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expel: Llm agents are experiential learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[55]
Proceedings of the AAAI conference on artificial intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[56]
, author=
MemGPT: towards LLMs as operating systems. , author=. 2023 , publisher=
2023
-
[57]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Memory os of ai agent , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[60]
arXiv preprint arXiv:2505.16067 , year=
How memory management impacts llm agents: An empirical study of experience-following behavior , author=. arXiv preprint arXiv:2505.16067 , year=
-
[61]
arXiv preprint arXiv:2505.19549 , year=
From Single to Multi-Granularity: Toward Long-Term Memory Association and Selection of Conversational Agents , author=. arXiv preprint arXiv:2505.19549 , year=
-
[62]
arXiv preprint arXiv:2507.22925 , year=
Hierarchical memory for high-efficiency long-term reasoning in llm agents , author=. arXiv preprint arXiv:2507.22925 , year=
-
[63]
arXiv preprint arXiv:2511.18423 , year=
General agentic memory via deep research , author=. arXiv preprint arXiv:2511.18423 , year=
-
[64]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory , author=. arXiv preprint arXiv:2511.20857 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
SimpleMem: Efficient Lifelong Memory for LLM Agents
SimpleMem: Efficient Lifelong Memory for LLM Agents , author=. arXiv preprint arXiv:2601.02553 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author=. arXiv preprint arXiv:2602.02474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents , author=. arXiv preprint arXiv:2604.12285 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
MemMachine: A Ground-Truth-Preserving Memory System for Personalized AI Agents
MemMachine: A ground-truth-preserving memory system for personalized AI agents , author=. arXiv preprint arXiv:2604.04853 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
HiGMem: A Hierarchical and LLM-Guided Memory System for Long-Term Conversational Agents
HiGMem: A Hierarchical and LLM-Guided Memory System for Long-Term Conversational Agents , author=. arXiv preprint arXiv:2604.18349 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
arXiv preprint arXiv:2602.14038 , year=
Choosing how to remember: Adaptive memory structures for llm agents , author=. arXiv preprint arXiv:2602.14038 , year=
-
[71]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Appagent: Multimodal agents as smartphone users , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[72]
Proceedings of the 30th annual international conference on Mobile computing and networking , pages=
Autodroid: Llm-powered task automation in android , author=. Proceedings of the 30th annual international conference on Mobile computing and networking , pages=
-
[73]
Proceedings of the 30th Annual International Conference on Mobile Computing and Networking , pages=
Mobilegpt: Augmenting llm with human-like app memory for mobile task automation , author=. Proceedings of the 30th Annual International Conference on Mobile Computing and Networking , pages=
-
[74]
MobA: multifaceted memory-enhanced adaptive planning for efficient mobile task automation , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations) , pages=
2025
-
[75]
arXiv preprint arXiv:2501.11733 , year=
Mobile-agent-e: Self-evolving mobile assistant for complex tasks , author=. arXiv preprint arXiv:2501.11733 , year=
-
[76]
arXiv e-prints , pages=
Fairy: Interactive Mobile Assistant to Real-world Tasks via LMM-based Multi-agent , author=. arXiv e-prints , pages=
-
[77]
arXiv preprint arXiv:2601.19199 , year=
MAGNET: Towards Adaptive GUI Agents with Memory-Driven Knowledge Evolution , author=. arXiv preprint arXiv:2601.19199 , year=
-
[78]
arXiv preprint arXiv:2602.05832 , year=
UI-Mem: Self-Evolving Experience Memory for Online Reinforcement Learning in Mobile GUI Agents , author=. arXiv preprint arXiv:2602.05832 , year=
-
[79]
arXiv preprint arXiv:2602.06075 , year=
MemGUI-Bench: Benchmarking Memory of Mobile GUI Agents in Dynamic Environments , author=. arXiv preprint arXiv:2602.06075 , year=
-
[80]
arXiv preprint arXiv:2603.10291 , year=
Hybrid Self-evolving Structured Memory for GUI Agents , author=. arXiv preprint arXiv:2603.10291 , year=
-
[81]
arXiv preprint arXiv:2601.17418 , year=
GraphPilot: GUI Task Automation with One-Step LLM Reasoning Powered by Knowledge Graph , author=. arXiv preprint arXiv:2601.17418 , year=
-
[82]
MGA: Memory-Driven GUI Agent for Observation-Centric Interaction
Mga: Memory-driven gui agent for observation-centric interaction , author=. arXiv preprint arXiv:2510.24168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[83]
arXiv preprint arXiv:2603.18429 , year=
AndroTMem: From Interaction Trajectories to Anchored Memory in Long-Horizon GUI Agents , author=. arXiv preprint arXiv:2603.18429 , year=
-
[84]
EchoTrail-GUI: Building Actionable Memory for GUI Agents via Critic-Guided Self-Exploration
EchoTrail-GUI: Building Actionable Memory for GUI Agents via Critic-Guided Self-Exploration , author=. arXiv preprint arXiv:2512.19396 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[85]
SkillDroid: Compile Once, Reuse Forever
SkillDroid: Compile Once, Reuse Forever , author=. arXiv preprint arXiv:2604.14872 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[86]
MobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive and MCP-Augmented Environments , author=. arXiv preprint arXiv:2512.19432 , year=
-
[87]
arXiv preprint arXiv:2512.22047 , year=
MAI-UI Technical Report: Real-World Centric Foundation GUI Agents , author=. arXiv preprint arXiv:2512.22047 , year=
-
[88]
Mobile-agent-v3. 5: Multi-platform fundamental gui agents , author=. arXiv preprint arXiv:2602.16855 , year=
-
[89]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Ui-tars: Pioneering automated gui interaction with native agents , author=. arXiv preprint arXiv:2501.12326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[90]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning , author=. arXiv preprint arXiv:2509.02544 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[91]
arXiv preprint arXiv:2508.10833 , year=
Ui-venus technical report: Building high-performance ui agents with rft , author=. arXiv preprint arXiv:2508.10833 , year=
-
[92]
2025 , url=
GELab-Zero: An Advanced Mobile Agent Inference System , author=. 2025 , url=
2025
-
[93]
https://openai
Introducing OpenAI o3 and o4-mini , author=. https://openai. com/index/introducing-o3-and-o4-mini/ , year=
-
[94]
arXiv preprint arXiv:2510.20286 , year=
UI-Ins: Enhancing GUI Grounding with Multi-Perspective Instruction-as-Reasoning , author=. arXiv preprint arXiv:2510.20286 , year=
-
[95]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Androidworld: A dynamic benchmarking environment for autonomous agents , author=. arXiv preprint arXiv:2405.14573 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[96]
Annual review of psychology , volume=
The cognitive neuroscience of working memory , author=. Annual review of psychology , volume=. 2015 , publisher=
2015
-
[97]
Annual review of neuroscience , volume=
An integrative theory of prefrontal cortex function , author=. Annual review of neuroscience , volume=. 2001 , publisher=
2001
-
[98]
Task set and prefrontal cortex , author=. Annu. Rev. Neurosci. , volume=. 2008 , publisher=
2008
-
[99]
Trends in cognitive sciences , volume=
Motivation of extended behaviors by anterior cingulate cortex , author=. Trends in cognitive sciences , volume=. 2012 , publisher=
2012
-
[100]
Journal of Neuroscience , volume=
Tracking progress toward a goal in corticostriatal ensembles , author=. Journal of Neuroscience , volume=. 2014 , publisher=
2014
-
[101]
Nature , volume=
Neural activity predicts individual differences in visual working memory capacity , author=. Nature , volume=. 2004 , publisher=
2004
-
[102]
Trends in cognitive sciences , volume=
The episodic buffer: a new component of working memory? , author=. Trends in cognitive sciences , volume=. 2000 , publisher=
2000
-
[103]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[104]
Advances in Neural Information Processing Systems , volume=
Androidinthewild: A large-scale dataset for android device control , author=. Advances in Neural Information Processing Systems , volume=
-
[105]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mobile-bench: An evaluation benchmark for llm-based mobile agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[106]
arXiv preprint arXiv:2511.09157 , year=
ProBench: Benchmarking GUI Agents with Accurate Process Information , author=. arXiv preprint arXiv:2511.09157 , year=
-
[107]
arXiv preprint arXiv:2501.01149 , year=
A3: Android agent arena for mobile gui agents , author=. arXiv preprint arXiv:2501.01149 , year=
-
[108]
NeurIPS 2024 Workshop on Open-World Agents , year=
Spa-bench: A comprehensive benchmark for smartphone agent evaluation , author=. NeurIPS 2024 Workshop on Open-World Agents , year=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.