Arithmetic Pedagogy for Language Models
Pith reviewed 2026-06-28 06:34 UTC · model grok-4.3
The pith
Serializing an Indonesian left-to-right arithmetic method into chain-of-thought text trains an 86-million-parameter model to exceed 80 percent accuracy on held-out problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
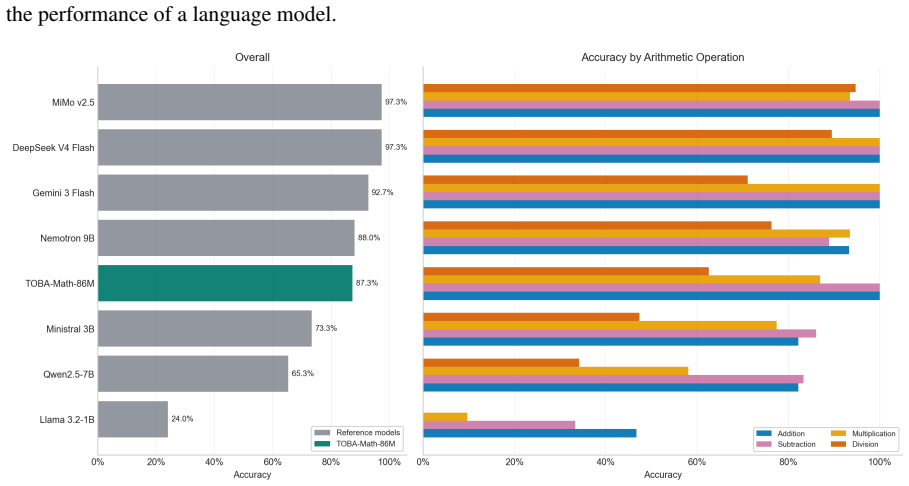
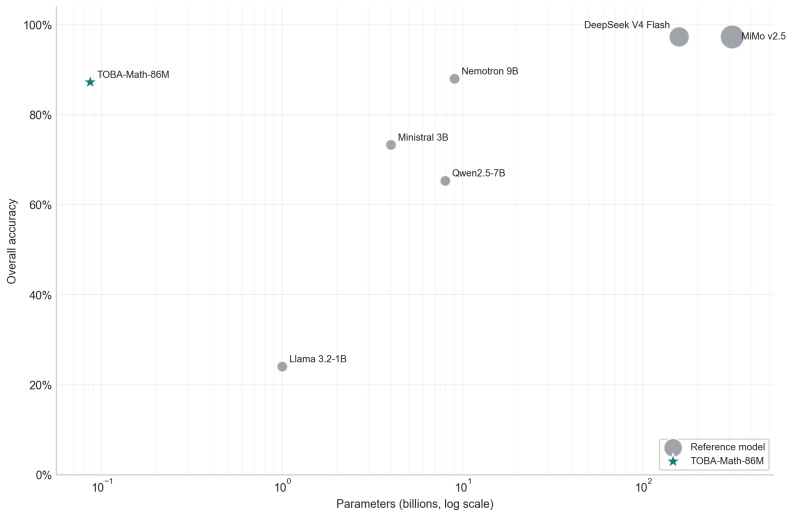
Operationalizing each arithmetic operation via the GASING left-to-right procedure and serializing its execution trace into natural-language chain-of-thought supervision allows a small GPT-2 model trained only on next-token prediction to internalize both a procedural pathway and an associative mental-arithmetic capacity, reaching over 80 percent accuracy on held-out problems and competitive performance against substantially larger models.
What carries the argument
The GASING method, a left-to-right arithmetic procedure whose execution trace is serialized into natural-language chain-of-thought supervision for next-token training.
If this is right
- Targeted pedagogical data alone suffices to produce strong arithmetic performance at small scale without reinforcement learning or reward models.
- The model develops an associative retrieval capacity that bypasses explicit step-by-step computation after initial procedural learning.
- Attention-masking and probing experiments confirm that chain-of-thought information shapes the model's internal computation graph.
- Economical arithmetic capability becomes attainable in models under 100 million parameters when training data follows human procedural order.
Where Pith is reading between the lines
- The same serialization approach could be tested on other ordered procedural domains such as basic logic or simple coding tasks where step order matches generation order.
- The shift from procedural to associative processing may generalize to other small-model training regimes that begin with explicit supervision and later allow direct retrieval.
- If the alignment between teaching procedure and model generation order proves decisive, curricula for additional skills could be redesigned to match that order rather than human reading order.
Load-bearing premise
The GASING left-to-right procedure aligns with the causal order of token generation, so its execution trace can be serialized into chain-of-thought text that transfers effectively during training.
What would settle it
Retraining the identical 86M model on the same arithmetic problems but without the GASING-derived chain-of-thought supervision and measuring accuracy below 50 percent on the same held-out set.
Figures
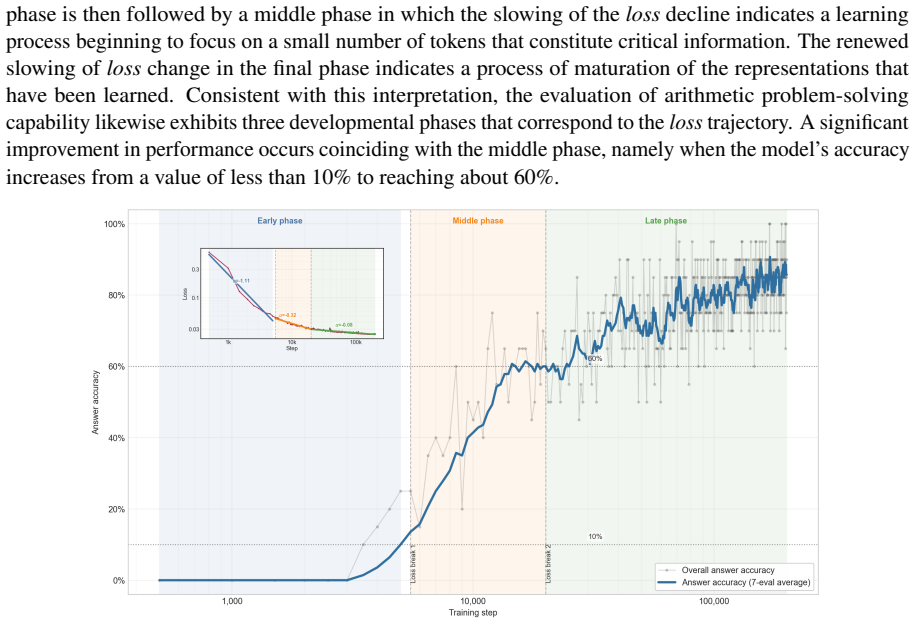
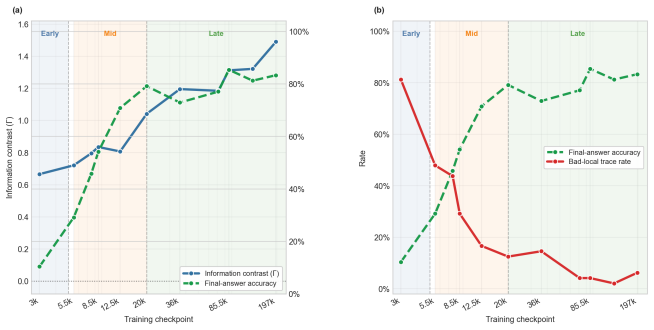
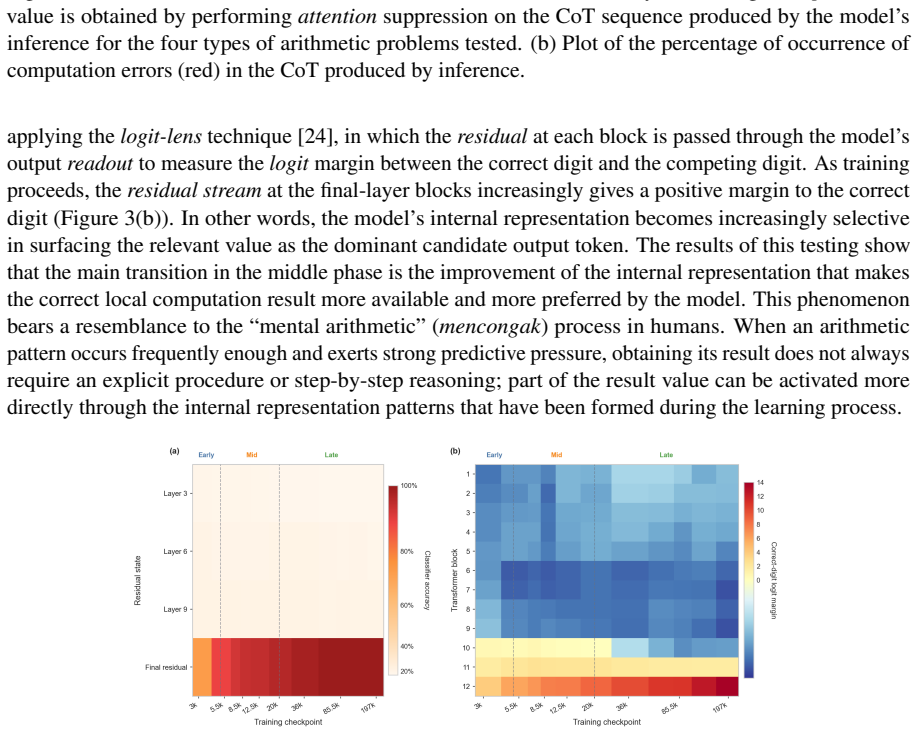
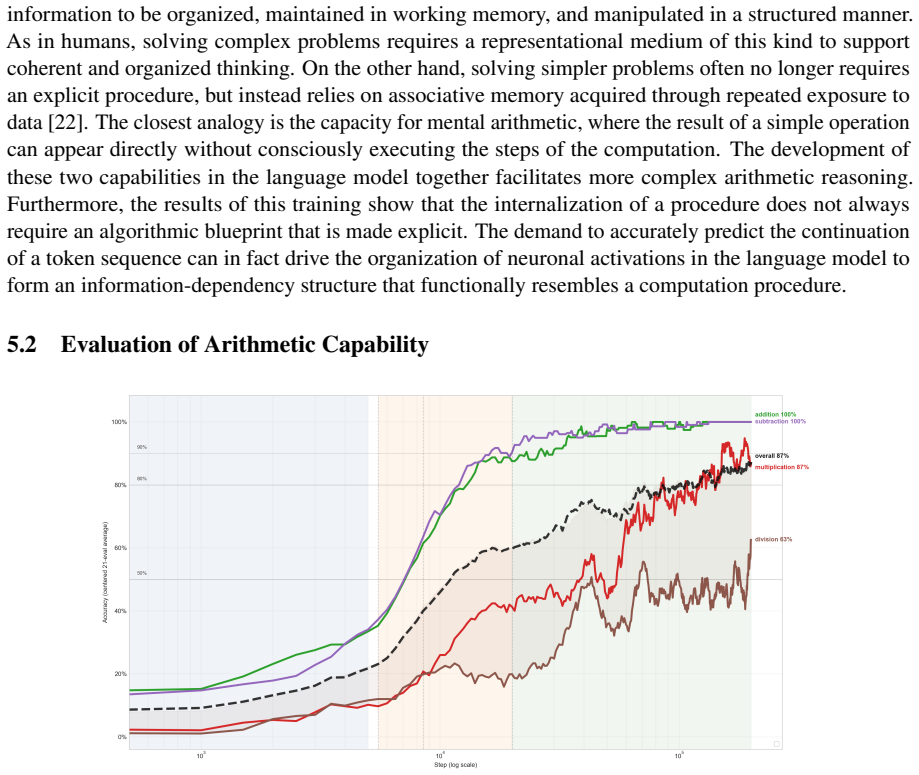
read the original abstract
We investigate whether methods of human mathematics pedagogy can guide the training of language models toward arithmetic reasoning. Building on the GASING method -- an Indonesian pedagogy that solves basic arithmetic through a left-to-right procedure aligned with the causal order of token generation -- we operationalize each operation as a computational procedure whose execution trace is serialized into natural-language Chain-of-Thought (CoT) supervision. A small GPT-2 decoder (86M parameters) with a syllabic-agglutinative TOBA tokenizer for Indonesian is trained from scratch on this data using only a next-token prediction objective, without reinforcement learning or reward-based optimization. Monitoring training reveals three distinct learning phases, and mechanistic analyses -- attention-masking interventions on the CoT information graph, residual-stream probing, and logit-lens inspection -- show that the model first internalizes a procedural pathway and subsequently develops an associative, ``mental-arithmetic'' capacity that retrieves intermediate results without explicit step-by-step computation. The trained model reaches over 80% accuracy on held-out problems and attains competitive performance against substantially larger language models, indicating that targeted, pedagogically grounded training can yield strong and economical arithmetic capability at small scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that serializing the GASING Indonesian left-to-right arithmetic pedagogy into natural-language CoT traces, then training an 86M-parameter GPT-2 decoder from scratch on next-token prediction, produces >80% accuracy on held-out arithmetic problems. It reports three distinct training phases and uses attention-masking interventions, residual-stream probing, and logit-lens analysis to argue that the model first learns a procedural pathway before shifting to associative retrieval of intermediate results. The work concludes that pedagogically grounded supervision yields strong, economical arithmetic capability at small scale without RL or reward modeling.
Significance. If the central result holds, the work shows that targeted CoT supervision derived from established human pedagogy can produce competitive arithmetic performance in an 86M model, outperforming expectations for its size and providing mechanistic evidence of a procedural-to-associative transition. The direct training runs on held-out data and the suite of intervention-based analyses constitute concrete strengths.
major comments (2)
- [Experimental setup and results] The manuscript reports no ablation comparing GASING-derived CoT to standard left-to-right CoT or to direct-answer targets on the same arithmetic distribution. Without this control, the claim that the specific pedagogical alignment (rather than generic step-by-step supervision) drives the >80% held-out accuracy cannot be isolated; this directly affects the load-bearing interpretation of the headline result.
- [Methods and evaluation] Details on data splits, problem generation procedure, exact baselines for the 'competitive performance against substantially larger models' claim, and error analysis by operation or difficulty are not provided. These omissions prevent verification that the reported accuracy figures fully support the phase-transition and mechanistic conclusions.
minor comments (2)
- Clarify the precise tokenization details of the syllabic-agglutinative TOBA tokenizer and how it interacts with the serialized CoT traces.
- Add explicit statements of the number of training examples, training steps per phase, and statistical significance of the accuracy figures.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each major point below and have revised the manuscript to improve clarity, completeness, and verifiability while preserving the core claims supported by the existing experiments and analyses.
read point-by-point responses
-
Referee: [Experimental setup and results] The manuscript reports no ablation comparing GASING-derived CoT to standard left-to-right CoT or to direct-answer targets on the same arithmetic distribution. Without this control, the claim that the specific pedagogical alignment (rather than generic step-by-step supervision) drives the >80% held-out accuracy cannot be isolated; this directly affects the load-bearing interpretation of the headline result.
Authors: We agree that a direct ablation would strengthen isolation of the GASING-specific left-to-right procedural alignment from generic step-by-step supervision. The manuscript does not report such an ablation, and our headline result is presented as the effectiveness of pedagogically grounded CoT rather than a claim of strict superiority over all alternative CoT formats. The mechanistic evidence (attention-masking on the CoT information graph and phase transitions) is tied to the structure of the GASING traces. In the revision we have added a dedicated limitations paragraph in Section 5 explicitly acknowledging this gap and identifying it as a priority for follow-up experiments. revision: partial
-
Referee: [Methods and evaluation] Details on data splits, problem generation procedure, exact baselines for the 'competitive performance against substantially larger models' claim, and error analysis by operation or difficulty are not provided. These omissions prevent verification that the reported accuracy figures fully support the phase-transition and mechanistic conclusions.
Authors: We thank the referee for highlighting these omissions. The revised manuscript expands the Methods section with: explicit data-split statistics (80/10/10 train/validation/test with no instance overlap), the precise problem-generation algorithm (random operand sampling with bounded difficulty per operation), the exact model sizes and reported accuracies used for the competitive-performance comparison, and a new appendix containing per-operation and per-difficulty error breakdowns. These additions directly support verification of the accuracy figures and the reported learning phases. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical training and held-out evaluation
full rationale
The paper's central results derive from training a GPT-2 model from scratch on next-token prediction using GASING-serialized CoT traces, followed by accuracy measurement on held-out arithmetic problems and mechanistic probes (attention masking, residual probing, logit lens). No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the >80% held-out accuracy and phase observations are outputs of the training run itself rather than re-expressions of inputs. The GASING alignment assumption is stated as a modeling choice but does not create a definitional loop. This is a standard empirical setup with independent falsifiability on held-out data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Next-token prediction on serialized GASING execution traces is sufficient for the model to internalize arithmetic procedures
Reference graph
Works this paper leans on
-
[1]
M., Gebru, T., McMillan-Major, A., & Shmitchell, S
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots.Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623
2021
- [2]
- [3]
-
[4]
Cobbe, K., et al. (2021). Training Verifiers to Solve Math Word Problems.arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [5]
-
[6]
Gunasekar, S., et al. (2023). Textbooks Are All You Need.arXiv:2306.11644
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [7]
-
[8]
Kojima, T., et al. (2022). Large Language Models are Zero-Shot Reasoners.arXiv:2205.11916
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
C., Mitchell, M., & Krakauer, J
Krakauer, D. C., Mitchell, M., & Krakauer, J. W. (2026). Large language models and emergence: a complex systems perspective.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 384(2320)
2026
- [10]
- [11]
-
[12]
Lightman, H., et al. (2023). Let’s Verify Step by Step.arXiv:2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
B., & Situngkir, H
Lumbantobing, A. B., & Situngkir, H. (2026). Tokenizations for Austronesian Language Models: study on languages in Indonesia Archipelago.BFI Working Paper Series
2026
-
[14]
Nanda, N., et al. (2023). Progress measures for grokking via mechanistic interpretability. arXiv:2301.05217
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Nye, M., et al. (2021). Show Your Work: Scratchpads for Intermediate Computation with Language Models.arXiv:2112.00114
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Power, A., et al. (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets.arXiv:2201.02177
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Radford, A., et al. (2019). Language Models are Unsupervised Multitask Learners.OpenAI
2019
- [18]
- [19]
-
[20]
Shao, Z., et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
B., & Surya, Y
Situngkir, H., Lumbantobing, A. B., & Surya, Y . (2026). Syllabic Agglutinative Tokenizations for Indonesian LLM: A Study from Gasing Literacy Learning System.BFI Working Paper Series. 17
2026
-
[22]
Situngkir, H., Siringo, K., & Lumbantobing, A. B. (2026). Adaptive Engram Memory System for Indonesian Language Model: Generative AI Based on TOBA LM for Batak and Minang Language. BFI Working Paper Series
2026
-
[23]
Vaswani, A., et al. (2017). Attention Is All You Need.arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [24]
-
[25]
Wei, J., et al. (2022a). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Wei, J., et al. (2022b). Emergent Abilities of Large Language Models.arXiv:2206.07682
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Yao, S., et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv:2305.10601. 18
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.