AGC-Bench: Measuring Artificial General Creativity
Pith reviewed 2026-07-03 21:23 UTC · model grok-4.3
The pith
Factor analysis of 83 LLMs on 78 creativity datasets recovers a single general 'c' factor explaining 81.5% of variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Applying factor analysis across 83 LLMs on the AGC-Bench datasets, the authors recover a single creativity factor 'c', analogous to the 'g' factor of general intelligence, that explains 81.5% of variance and is related to but separable from general knowledge and reasoning.
What carries the argument
The creativity factor 'c' extracted via factor analysis on standardized performance across the 78 datasets in AGC-Bench.
If this is right
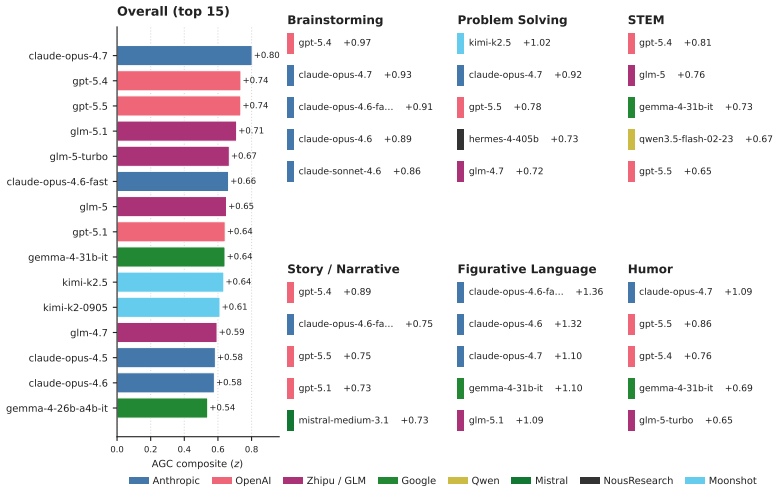
- Frontier LLMs rank highest on the leaderboard, with open models close behind.
- LLMs exhibit different creative strengths across domains such as writing versus scientific ideation.
- Prompting models to 'be creative' improves performance more than enabling reasoning.
- Top humans still outperform top LLMs on a matched subset of tasks.
Where Pith is reading between the lines
- Developers could prioritize training for the 'c' factor to improve creative outputs across domains.
- The benchmark could be extended to test whether the 'c' factor predicts real-world creative achievements in AI systems.
- If the factor holds, it suggests creativity in LLMs is more unified than previously thought, similar to intelligence research.
Load-bearing premise
The selected 78 datasets comprehensively and without bias measure a domain-general form of creativity.
What would settle it
Running factor analysis on a new set of 83 LLMs evaluated on a different collection of creativity tasks that yields no single factor explaining over 50% of variance would falsify the claim.
Figures
read the original abstract
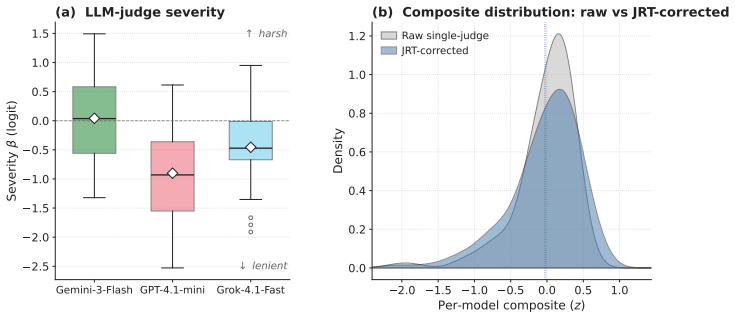
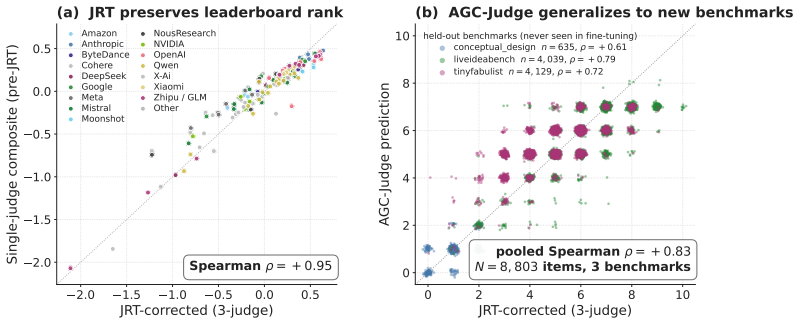
Creativity research has debated whether creativity is domain-specific (e.g., visual, writing, science), and if it is psychometrically separable from general intelligence. Both questions now apply to LLMs, but a unified benchmark of AI creativity remains elusive. We introduce AGC-Bench, an artificial general creativity benchmark built from a systematic review of the AI creativity literature (3,101 papers screened, 497 benchmarks identified), paired with an agentic harness that converts idiosyncratic codebases into HELM-standardized benchmarks. The first release covers 78 datasets spanning brainstorming, problem solving, STEM, narrative, figurative language, and humor. To address bias in LLM-as-judge, we apply Judge Response Theory -- a psychometric calibration of judge leniency/severity; we then fine-tune Qwen3-30B on the bias-corrected ratings of three frontier LLMs to produce AGC-Judge, an open-weight model that robustly scores new creativity benchmarks it was not trained on. Results reveal frontier models at the top of the AGC-Bench leaderboard, with open models close behind. LLMs show different creative strengths, ranking higher on some domains (e.g., writing) than others (e.g., scientific ideation). Extensive experiments yield three main findings. First, applying factor analysis across 83 LLMs, we recover a single creativity factor 'c', analogous to the 'g' factor of general intelligence, that explains 81.5% of variance, related to but separable from general knowledge/reasoning. Second, we show that prompting models to "be creative" boosts their performance far more than enabling reasoning, evidence that the benchmark tracks creativity over general ability. Third, on a human-matched subset, we find the top human still leads the top LLM on creativity. We release AGC-Bench with a public leaderboard, AGC-Judge, and human data as open infrastructure for measuring AI creativity at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AGC-Bench, a benchmark for artificial general creativity constructed via systematic literature review (3,101 papers screened, 497 benchmarks identified, yielding 78 datasets across domains like brainstorming, narrative, and STEM). It uses an agentic harness for standardization and AGC-Judge (fine-tuned on bias-corrected ratings via Judge Response Theory) for evaluation. Factor analysis across 83 LLMs recovers a single 'c' factor explaining 81.5% of variance, separable from general knowledge/reasoning; additional results cover prompting effects and human-LLM comparisons.
Significance. If the central claims hold, the work supplies open infrastructure (benchmark, leaderboard, AGC-Judge, human data) for scalable creativity evaluation in LLMs and identifies a domain-general 'c' factor analogous to the g-factor, with evidence that creativity prompting outperforms reasoning prompting. This could standardize measurement in a fragmented area and enable future studies on separability from intelligence.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: the manuscript states that 78 datasets were selected from 497 benchmarks identified in a review of 3,101 papers but provides no explicit inclusion/exclusion criteria, domain-balance analysis, or checks for correlated measurement artifacts (e.g., over-sampling of narrative/brainstorming tasks). This selection process is load-bearing for the claim that the recovered 'c' factor is domain-general rather than an artifact of task sampling bias.
- [Factor Analysis] Factor Analysis subsection (results): the single-factor solution explaining 81.5% variance is reported without specifying the extraction method (PCA vs. FA), rotation, number of factors tested, eigenvalue cutoff, or handling of missing values across the 78 datasets and 83 models. These details are required to evaluate whether the high first-factor loading supports a separable creativity construct or arises from implementation choices.
minor comments (2)
- [Abstract] Abstract: 'Judge Response Theory' is introduced without a one-sentence definition; adding a brief gloss would aid readers unfamiliar with the calibration technique.
- [Results] Results: domain-specific ranking differences (e.g., writing vs. scientific ideation) are described but lack a reference to the corresponding table or figure in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify opportunities to improve methodological transparency in the benchmark construction and factor analysis sections. We address each major comment below and have revised the manuscript accordingly to provide the requested details.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: the manuscript states that 78 datasets were selected from 497 benchmarks identified in a review of 3,101 papers but provides no explicit inclusion/exclusion criteria, domain-balance analysis, or checks for correlated measurement artifacts (e.g., over-sampling of narrative/brainstorming tasks). This selection process is load-bearing for the claim that the recovered 'c' factor is domain-general rather than an artifact of task sampling bias.
Authors: We agree that explicit documentation of the selection process is necessary to substantiate the domain-generality claim. In the revised manuscript, we have added a dedicated subsection to Benchmark Construction that details the inclusion criteria (e.g., requirement for empirical validation in prior work, minimum of three items per task, and coverage of at least one of six predefined domains), exclusion criteria (e.g., single-item tasks, non-English content, or benchmarks without human baselines), a quantitative domain-balance analysis (showing distribution across brainstorming, narrative, STEM, etc.), and post-selection checks for correlated artifacts including pairwise task similarity analysis and sensitivity tests removing over-represented domains. These additions confirm that the 'c' factor is not driven by sampling bias. revision: yes
-
Referee: [Factor Analysis] Factor Analysis subsection (results): the single-factor solution explaining 81.5% variance is reported without specifying the extraction method (PCA vs. FA), rotation, number of factors tested, eigenvalue cutoff, or handling of missing values across the 78 datasets and 83 models. These details are required to evaluate whether the high first-factor loading supports a separable creativity construct or arises from implementation choices.
Authors: We acknowledge the omission of these methodological specifics. The analysis used principal component analysis (PCA) as the extraction method (chosen for its suitability with continuous performance scores), with varimax rotation, testing solutions from 1 to 5 factors, retaining factors with eigenvalues greater than 1 (yielding a single dominant factor), and handling missing values via pairwise deletion given the sparse but structured missingness pattern across models and datasets. We have added a new paragraph in the Factor Analysis subsection with these details, the full scree plot, and a table of factor loadings to allow readers to assess the separability of the 'c' factor from general ability measures. revision: yes
Circularity Check
No significant circularity: 'c' factor extracted via standard factor analysis on assembled benchmark scores
full rationale
The paper's central derivation applies factor analysis to performance scores of 83 LLMs across 78 pre-existing datasets (selected via literature review) to extract a single 'c' factor explaining 81.5% variance. This is an empirical reduction of observed score covariances, not a self-definitional loop, fitted input renamed as prediction, or load-bearing self-citation. The benchmark assembly step cites external literature without invoking author-overlapping uniqueness theorems or ansatzes. No equations or steps reduce the target result to its inputs by construction; the factor is separable from knowledge/reasoning by the analysis itself. This matches the most common honest non-finding for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 15th International Conference on Computational Creativity , pages =
Is Temperature the Creativity Parameter of Large Language Models? , author =. Proceedings of the 15th International Conference on Computational Creativity , pages =. 2024 , address =. 2405.00492 , archivePrefix =
-
[2]
Evaluating
Ruan, Kai and Wang, Xuan and Hong, Jixiang and Wang, Peng and Liu, Yang and Sun, Hao , journal =. Evaluating. 2026 , doi =
2026
-
[3]
Is Creativity Domain Specific? , author =. The. 2010 , pages =
2010
-
[4]
The Journal of Creative Behavior , volume =
Generalization of Creativity Across Domains: Examination of the Method Effect Hypothesis , author =. The Journal of Creative Behavior , volume =. 2004 , doi =
2004
-
[5]
and Beghetto, Ronald A
Kaufman, James C. and Beghetto, Ronald A. , journal =. Beyond Big and Little: The. 2009 , doi =
2009
-
[6]
, journal =
Kaufman, James C. , journal =. Counting the Muses: Development of the. 2012 , doi =
2012
-
[7]
and Peterson, Jordan B
Carson, Shelley H. and Peterson, Jordan B. and Higgins, Daniel M. , journal =. Reliability, Validity, and Factor Structure of the. 2005 , doi =
2005
-
[8]
and Gredlein, Jeffrey M
Diedrich, Jennifer and Jauk, Emanuel and Silvia, Paul J. and Gredlein, Jeffrey M. and Neubauer, Aljoscha C. and Benedek, Mathias , journal =. Assessment of Real-Life Creativity: The. 2018 , doi =
2018
-
[9]
Learning and Individual Differences , volume =
Unscrambling Creativity Measurement: An Invitation to Better Formalize the Domain Generality-Specificity of Creativity with Psychometric Modeling , author =. Learning and Individual Differences , volume =. 2024 , doi =
2024
-
[10]
Creativity Research Journal , volume =
The Standard Definition of Creativity , author =. Creativity Research Journal , volume =. 2012 , doi =
2012
-
[11]
1996 , isbn =
Creativity in Context: Update to the Social Psychology of Creativity , author =. 1996 , isbn =
1996
-
[12]
, booktitle =
McGrew, Kevin S. , booktitle =. The
-
[13]
Journal of Intelligence , volume =
The Relationship between Intelligence and Divergent Thinking---A Meta-Analytic Update , author =. Journal of Intelligence , volume =. 2021 , doi =
2021
-
[14]
Journal of Intelligence , volume =
A Minimal Theory of Creative Ability , author =. Journal of Intelligence , volume =. 2021 , doi =
2021
-
[15]
Intelligence , volume =
The Relationship between Intelligence and Creativity: New Support for the Threshold Hypothesis by Means of Empirical Breakpoint Detection , author =. Intelligence , volume =. 2013 , doi =
2013
-
[16]
Stevenson, Claire and Smal, Iris and Baas, Matthijs and Grasman, Raoul and van der Maas, Han , booktitle =. Putting. 2022 , eprint =
2022
-
[17]
and Byrge, Christian and Gilde, Christian , journal =
Guzik, Erik E. and Byrge, Christian and Gilde, Christian , journal =. The Originality of Machines:. 2023 , doi =
2023
-
[18]
Scientific Reports , volume =
The Current State of Artificial Intelligence Generative Language Models Is More Creative than Humans on Divergent Thinking Tasks , author =. Scientific Reports , volume =. 2024 , doi =
2024
-
[19]
Scientific Reports , volume =
Divergent Creativity in Humans and Large Language Models , author =. Scientific Reports , volume =. 2026 , doi =
2026
-
[20]
A Confederacy of Models: A Comprehensive Evaluation of
G. A Confederacy of Models: A Comprehensive Evaluation of. Findings of the Association for Computational Linguistics:. 2023 , doi =
2023
-
[21]
Proceedings of the
Art or Artifice? Large Language Models and the False Promise of Creativity , author =. Proceedings of the. 2024 , doi =
2024
-
[22]
Do Androids Laugh at Electric Sheep? Humor ``Understanding'' Benchmarks from
Hessel, Jack and Marasovi. Do Androids Laugh at Electric Sheep? Humor ``Understanding'' Benchmarks from. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , doi =
2023
-
[23]
Narad, Reuben and Suresh, Siddharth and Chen, Jiayi and Dysart-Bricken, Pine S. L. and Mankoff, Bob and Nowak, Robert and Zhang, Jifan and Jain, Lalit , journal =. Which. 2025 , eprint =
2025
-
[24]
and Jain, Lalit K
Zhou, Kuan Lok and Chen, Jiayi and Suresh, Siddharth and Narad, Reuben and Rogers, Timothy T. and Jain, Lalit K. and Nowak, Robert D. and Mankoff, Bob and Zhang, Jifan , booktitle =. Bridging the Creativity Understanding Gap: Small-Scale Human Alignment Enables Expert-Level Humor Ranking in. 2025 , doi =
2025
-
[25]
2023 , doi =
Chakrabarty, Tuhin and Saakyan, Arkadiy and Winn, Olivia and Panagopoulou, Artemis and Yang, Yue and Apidianaki, Marianna and Muresan, Smaranda , booktitle =. 2023 , doi =
2023
-
[26]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =
Testing the Ability of Language Models to Interpret Figurative Language , author =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2022 , doi =
2022
-
[27]
Fang, Xinyu and Chen, Zhijian and Lan, Kai and Ma, Lixin and Ding, Shengyuan and Liang, Yingji and Zhao, Xiangyu and Wen, Farong and Zhang, Zicheng and Zhang, Guofeng and Duan, Haodong and Chen, Kai and Lin, Dahua , booktitle =. 2025 , month = oct, doi =. 2503.14478 , archivePrefix =
-
[28]
2023 , doi =
Jiang, Yifan and Ilievski, Filip and Ma, Kaixin and Sourati, Zhivar , booktitle =. 2023 , doi =
2023
-
[29]
2025 , eprint =
Hou, Zhaoyi Joey and Zhang, Bowei Alvin and Lu, Yining and Baghel, Bhiman Kumar and Brei, Anneliese and Lu, Ximing and Jiang, Meng and Brahman, Faeze and Chaturvedi, Snigdha and Chang, Haw-Shiuan and Khashabi, Daniel and Li, Xiang Lorraine , journal =. 2025 , eprint =
2025
-
[30]
2004 , publisher =
The Creative Mind: Myths and Mechanisms , author =. 2004 , publisher =
2004
-
[31]
Proceedings of the 16th International Conference on Computational Creativity , pages =
Transformational Creativity in Science: A Graphical Theory , author =. Proceedings of the 16th International Conference on Computational Creativity , pages =. 2025 , address =. 2504.18687 , archivePrefix =
-
[32]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Rethinking Creativity Evaluation: A Critical Analysis of Existing Creativity Evaluations , author =. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2026 , doi =
2026
-
[33]
arXiv preprint arXiv:2509.09702 , year =
Creativity Benchmark: A Benchmark for Marketing Creativity for Large Language Models , author =. arXiv preprint arXiv:2509.09702 , year =. 2509.09702 , archivePrefix =
-
[34]
Findings of the Association for Computational Linguistics:
Creative Preference Optimization , author =. Findings of the Association for Computational Linguistics:. 2025 , doi =
2025
-
[35]
and Pronchick, Jimmy and Panchanadikar, Ruchi and Fuge, Mark and van Hell, Janet G
Patterson, John D. and Pronchick, Jimmy and Panchanadikar, Ruchi and Fuge, Mark and van Hell, Janet G. and Miller, Scarlett R. and Johnson, Dan R. and Beaty, Roger E. , journal =. 2025 , doi =
2025
-
[36]
Anka Reuel, Amelia Hardy, Chandler Smith, Max Lam- parth, Malcolm Hardy, and Mykel J Kochenderfer
Polo, Felipe Maia and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail , booktitle =. 2024 , volume =. 2402.14992 , archivePrefix =
-
[37]
Reliable and Efficient Amortized Model-based Evaluation,
Reliable and Efficient Amortized Model-Based Evaluation , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , volume =. 2503.13335 , archivePrefix =
-
[38]
and Schulz, Eric , booktitle =
Kipnis, Alex and Voudouris, Konstantinos and Schulze Buschoff, Luca M. and Schulz, Eric , booktitle =. 2025 , url =. 2407.12844 , archivePrefix =
-
[39]
and McKenzie, Joanne E
Page, Matthew J. and McKenzie, Joanne E. and Bossuyt, Patrick M. and Boutron, Isabelle and Hoffmann, Tammy C. and Mulrow, Cynthia D. and Shamseer, Larissa and Tetzlaff, Jennifer M. and Akl, Elie A. and Brennan, Sue E. and Chou, Roger and Glanville, Julie and Grimshaw, Jeremy M. and Hr. The. 2021 , doi =
2021
-
[40]
Holistic Evaluation of Language Models
Holistic Evaluation of Language Models , author =. Transactions on Machine Learning Research , year =. 2211.09110 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
2024 , month = jul, publisher =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and. 2024 , month = jul, publisher =. doi:10.5281/zenodo.12608602 , url =
-
[42]
and Kaufman, James C
Johnson, Dan R. and Kaufman, James C. and Baker, Brendan S. and Patterson, John D. and Barbot, Baptiste and Green, Adam E. and van Hell, Janet and Kennedy, Evan and Sullivan, Grace F. and Taylor, Christa L. and Ward, Thomas and Beaty, Roger E. , journal =. Divergent Semantic Integration (. 2023 , doi =
2023
-
[43]
Transactions on Machine Learning Research , year =
Evaluating the Robustness of Analogical Reasoning in Large Language Models , author =. Transactions on Machine Learning Research , year =. 2411.14215 , archivePrefix =
-
[44]
Psychometrika , volume =
A Rationale and Test for the Number of Factors in Factor Analysis , author =. Psychometrika , volume =. 1965 , doi =
1965
-
[45]
2025 , eprint =
Zhang, Yiming and Diddee, Harshita and Holm, Susan and Liu, Hanchen and Liu, Xinyue and Samuel, Vinay and Wang, Barry and Ippolito, Daphne , booktitle =. 2025 , eprint =
2025
-
[46]
and Park, Hyeri , title =
Acar, Selcuk and Runco, Mark A. and Park, Hyeri , title =. Psychology of Aesthetics, Creativity, and the Arts , year =
-
[47]
Testing conditions and creative performance: Meta-analyses of the impact of time limits and instructions , journal =
Said-Metwaly, Sameh and Fern. Testing conditions and creative performance: Meta-analyses of the impact of time limits and instructions , journal =. 2020 , volume =
2020
-
[48]
On the Measure of Intelligence
On the Measure of Intelligence , author =. arXiv preprint arXiv:1911.01547 , year =. 1911.01547 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[49]
The Journal of Creative Behavior , year =
The language of creativity: Evidence from humans and large language models , author =. The Journal of Creative Behavior , year =
-
[50]
LLM Evaluators Recognize and Favor Their Own Generations
Panickssery, Arjun and Bowman, Samuel R. and Feng, Shi , booktitle =. 2024 , doi =. 2404.13076 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
and Zhang, Xiangliang , booktitle =
Ye, Jiayi and Wang, Yanbo and Huang, Yue and Chen, Dongping and Zhang, Qihui and Moniz, Nuno and Gao, Tian and Geyer, Werner and Huang, Chao and Chen, Pin-Yu and Chawla, Nitesh V. and Zhang, Xiangliang , booktitle =. Justice or Prejudice? Quantifying Biases in. 2025 , eprint =
2025
-
[52]
Assistant-Guided Mitigation of Teacher Preference Bias in
Liu, Zhuo and Li, Moxin and Deng, Xun and Wang, Qifan and Feng, Fuli , booktitle =. Assistant-Guided Mitigation of Teacher Preference Bias in. 2025 , address =. doi:10.18653/v1/2025.findings-emnlp.510 , eprint =
-
[53]
Jang, Myeongjun Erik and Silavong, Fran , booktitle =. 2025 , address =. doi:10.18653/v1/2025.emnlp-industry.82 , url =
-
[54]
Paraphrasing Evades Detectors of
Krishna, Kalpesh and Song, Yixiao and Karpinska, Marzena and Wieting, John and Iyyer, Mohit , booktitle =. Paraphrasing Evades Detectors of. 2023 , eprint =
2023
-
[55]
Communications of the ACM , volume =
Datasheets for Datasets , author =. Communications of the ACM , volume =. 2021 , doi =
2021
-
[56]
Nath, Surabhi S. and del Cuvillo y Schr. Pencils to Pixels: A Systematic Study of Creative Drawings across Children, Adults and. Proceedings of the 47th Annual Conference of the Cognitive Science Society , volume =. 2025 , address =. 2502.05999 , archivePrefix =
-
[57]
Psychology of Aesthetics, Creativity, and the Arts , volume =
Judge Response Theory? A Call to Upgrade Our Psychometrical Account of Creativity Judgments , author =. Psychology of Aesthetics, Creativity, and the Arts , volume =. 2019 , doi =
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.