DocOS: Towards Proactive Document-Guided Actions in GUI Agents
Pith reviewed 2026-05-20 11:09 UTC · model grok-4.3
The pith
GUI agents can handle uncommon tasks by searching for and using online documentation to guide their actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that progress in GUI agents for long-tailed tasks is limited by difficulties in locating relevant documentation during proactive searches and in grounding those instructions into accurate executable actions, and that document-guided interaction offers a key way to create self-evolving agents in changing environments.
What carries the argument
The Proactive Document-Guided Action paradigm, which allows agents to autonomously search for, comprehend, and execute instructions from online documentation, evaluated using the DocOS benchmark in fully interactive web environments.
If this is right
- GUI agents will be able to manage tasks requiring specific procedural knowledge by accessing external sources.
- Advances will require better methods for information retrieval and precise action mapping from text.
- Self-evolving agents become possible in dynamic settings through continuous document use.
- This shifts away from pure trial-and-error exploration toward informed decision making.
Where Pith is reading between the lines
- This could enable agents to work with newly released software by finding updated manuals online.
- Similar methods might help other AI systems that need to perform actions based on external knowledge.
- Integrating this with search engines could create more robust interactive assistants.
Load-bearing premise
Relevant and accurate documentation is available online for long-tailed tasks, and agents can find it and convert the instructions into correct actions without errors or loss of context.
What would settle it
If agents fail to complete DocOS tasks even when provided with the exact relevant documentation in advance, this would show that the grounding step does not work reliably.
Figures






















read the original abstract
While Graphical User Interface (GUI) agents have shown promising performance in automated device interaction, they primarily depend on static parametric knowledge from pre-training or instruction tuning. This reliance fundamentally limits their ability to handle long-tailed tasks that require explicit procedural knowledge absent from model parameters, often forcing agents to resort to inefficient and brittle trial-and-error exploration. To mitigate this limitation, we introduce \textbf{Proactive Document-Guided Action} for GUI agents in dynamic, open-web environments, a novel paradigm that mirrors human problem-solving by enabling agents to autonomously search for relevant documentation to resolve long-tailed tasks. To evaluate agents' capability in this paradigm, we propose \textbf{DocOS}, a benchmark designed to assess document-guided problem solving in fully interactive environments. DocOS requires agents to autonomously navigate a web browser, locate relevant online documentation, comprehend procedural instructions, and faithfully ground them into executable GUI actions. Extensive experiments reveal that progress is strictly constrained by dual bottlenecks: agents struggle to reliably locate relevant information during proactive search and frequently fail to faithfully ground retrieved instructions into precise actions, pointing toward document-guided interaction as a crucial pathway for enabling self-evolving GUI agents in dynamic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Proactive Document-Guided Action as a paradigm for GUI agents operating in dynamic open-web environments. It proposes the DocOS benchmark, which requires agents to autonomously navigate browsers, locate relevant online documentation for long-tailed tasks, comprehend procedural instructions, and ground them into precise executable GUI actions. Experiments identify two primary bottlenecks—unreliable proactive search for information and failures in faithfully translating retrieved instructions into actions—and conclude that document-guided interaction is a crucial pathway for self-evolving GUI agents.
Significance. If the empirical findings hold under closer scrutiny, the work provides a concrete benchmark and diagnostic for limitations in current GUI agents that rely solely on parametric knowledge or trial-and-error. By framing document search and grounding as central challenges, it opens a research direction that could improve adaptability on tasks absent from training data, with potential value for reproducible evaluation in interactive agent settings.
major comments (1)
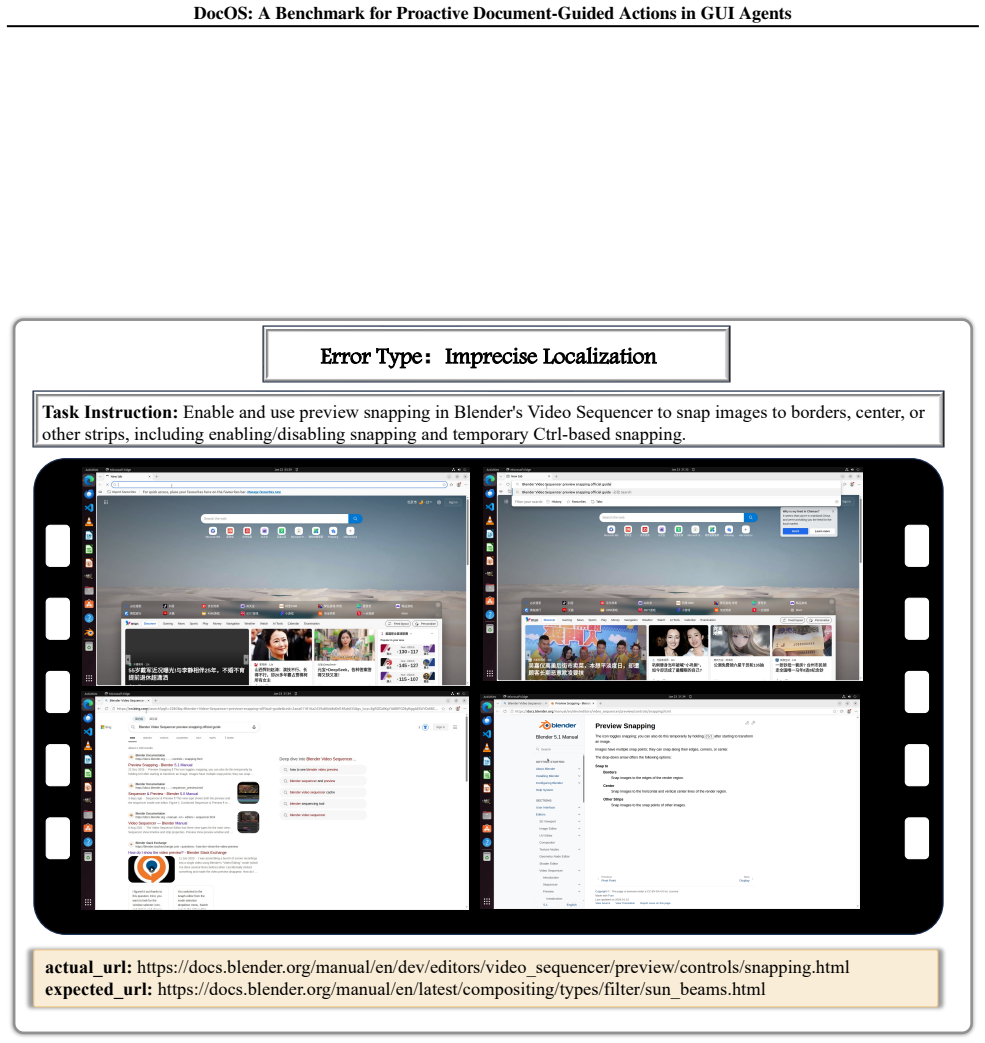
- [Benchmark construction] Benchmark construction and task selection (likely §3): The claim that progress is 'strictly constrained by dual bottlenecks' in proactive search and instruction grounding is load-bearing on the premise that accurate, sufficiently detailed, and relevant online documentation exists for the chosen long-tailed tasks and can be directly mapped to executable actions. The manuscript does not appear to describe a verification step confirming document availability, completeness, or lack of ambiguity for each task; without this, search failures may reflect data absence rather than agent capability, weakening the interpretation that document-guided interaction is the key enabling pathway.
minor comments (1)
- [Abstract] Abstract and experimental reporting: The abstract states that 'extensive experiments reveal' the bottlenecks but provides no quantitative metrics, baseline comparisons, or error breakdowns; adding a concise summary of key performance numbers and failure categorizations would improve clarity without altering the core contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the significance of DocOS. We address the single major comment below and have revised the manuscript to strengthen the benchmark description.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction and task selection (likely §3): The claim that progress is 'strictly constrained by dual bottlenecks' in proactive search and instruction grounding is load-bearing on the premise that accurate, sufficiently detailed, and relevant online documentation exists for the chosen long-tailed tasks and can be directly mapped to executable actions. The manuscript does not appear to describe a verification step confirming document availability, completeness, or lack of ambiguity for each task; without this, search failures may reflect data absence rather than agent capability, weakening the interpretation that document-guided interaction is the key enabling pathway.
Authors: We agree that an explicit description of the verification process is necessary to support the interpretation of the dual bottlenecks. In the revised manuscript, we have added Section 3.2 (Task Curation and Documentation Verification) that details the following procedure: (1) We first identified long-tailed tasks from real-world usage logs and forums that are unlikely to be covered in model pre-training data. (2) For each candidate task, two authors independently searched for official or authoritative online documentation (e.g., vendor support pages, step-by-step tutorials). (3) We verified that the retrieved documents contain accurate, sufficiently detailed procedural instructions that can be unambiguously mapped to a finite sequence of GUI actions (clicks, typing, navigation) without requiring external knowledge or trial-and-error. Tasks lacking such documentation or containing irresolvable ambiguities were excluded from the final benchmark. This verification step ensures that observed agent failures in proactive search and instruction grounding are attributable to model limitations rather than missing or inadequate source material, thereby reinforcing our claim that document-guided interaction is a crucial pathway. revision: yes
Circularity Check
Empirical benchmark proposal with no derivations or self-referential reductions
full rationale
The paper introduces the DocOS benchmark and Proactive Document-Guided Action paradigm for GUI agents, then reports experimental results on agent performance in search and grounding tasks. No equations, parameter fitting, or mathematical derivations are present. Conclusions about dual bottlenecks follow directly from observed empirical failures on the new benchmark tasks rather than reducing to any self-definition, fitted input renamed as prediction, or load-bearing self-citation chain. The work is self-contained as an empirical evaluation of a proposed interaction paradigm against external agent baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GUI agents can improve on long-tailed tasks by retrieving and grounding external procedural documentation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize the interaction ... as a Partially Observable Markov Decision Process (POMDP) ... Proactive Knowledge Retrieval ... Document-Grounded Execution
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive experiments reveal that progress is strictly constrained by dual bottlenecks: agents struggle to reliably locate relevant information during proactive search and frequently fail to faithfully ground retrieved instructions into precise actions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
European Conference on Computer Vision , pages=
Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[2]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
arXiv preprint arXiv:2404.05955 , year=
Visualwebbench: How far have multimodal llms evolved in web page understanding and grounding? , author=. arXiv preprint arXiv:2404.05955 , year=
-
[5]
VideoGUI: A Benchmark for GUI Automation from Instructional Videos , author=. NeurIPS , year=
-
[7]
ScreenSpot: Multidimensional resource discovery for distributed applications in smart spaces , author=. Proceedings of the 5th Annual International Conference on Mobile and Ubiquitous Systems: Computing, Networking, and Services , pages=
-
[8]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Crab: Cross-environment agent benchmark for multimodal language model agents , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[9]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , booktitle =
Shunyu Yao and Howard Chen and John Yang and Karthik Narasimhan , editor =. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , booktitle =. 2022 , timestamp =
work page 2022
-
[10]
Mind2Web: Towards a Generalist Agent for the Web , author=. 2023 , eprint=
work page 2023
-
[11]
Luyuan Wang and Yongyu Deng and Yiwei Zha and Guodong Mao and Qinmin Wang and Tianchen Min and Wei Chen and Shoufa Chen , title =. CoRR , volume =. 2024 , doi =. 2406.08184 , timestamp =
-
[12]
AppAgent: Multimodal Agents as Smartphone Users , author=. 2023 , eprint=
work page 2023
-
[14]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Gui agents: A survey , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[15]
National Science Review , volume=
A survey on multimodal large language models , author=. National Science Review , volume=. 2024 , publisher=
work page 2024
-
[16]
The Twelfth International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. The Twelfth International Conference on Learning Representations , year=
-
[17]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Retrieval-augmented GUI Agents with Generative Guidelines , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[20]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
- [22]
-
[25]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction , author=
-
[27]
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[28]
Introducing Claude Sonnet 4.5 , author=. 2025 , month=sep, day=
work page 2025
-
[29]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents , author=. 2024 , eprint=
work page 2024
- [30]
-
[31]
OpenCUA: Open Foundations for Computer-Use Agents , author=. 2025 , eprint=
work page 2025
-
[32]
CogAgent: A Visual Language Model for GUI Agents , author=. 2024 , eprint=
work page 2024
-
[33]
OS-Copilot: Towards Generalist Computer Agents with Self-Improvement , author=. 2024 , eprint=
work page 2024
-
[34]
Android in the Wild: A Large-Scale Dataset for Android Device Control , author=. 2023 , eprint=
work page 2023
-
[35]
Kaixin Li and Meng Ziyang and Hongzhan Lin and Ziyang Luo and Yuchen Tian and Jing Ma and Zhiyong Huang and Tat-Seng Chua , booktitle=. ScreenSpot-Pro:
-
[36]
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows? , author=. 2024 , eprint=
work page 2024
-
[39]
TongUI: Internet-Scale Trajectories from Multimodal Web Tutorials for Generalized GUI Agents , author=. 2025 , eprint=
work page 2025
-
[49]
Zhenyu Li and Xuefeng Bai and YUNFEI LONG and Kehai Chen and Yaoyin Zhang and Xuchen Wei and Juntao Li and Min Zhang , booktitle=. 2026 , //url=
work page 2026
-
[50]
Qwen3-vl technical report, 2025
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page 2025
-
[51]
Bu, W., Wu, Y., Yu, Q., Gao, M., Miao, B., Zhang, Z., Pan, K., Li, Y., Li, M., Ji, W., et al. What limits virtual agent application? omnibench: A scalable multi-dimensional benchmark for essential virtual agent capabilities. arXiv preprint arXiv:2506.08933, 2025
-
[52]
Cao, R., Lei, F., Wu, H., Chen, J., Fu, Y., Gao, H., Xiong, X., Zhang, H., Mao, Y., Hu, W., Xie, T., Xu, H., Zhang, D., Wang, S., Sun, R., Yin, P., Xiong, C., Ni, A., Liu, Q., Zhong, V., Chen, L., Yu, K., and Yu, T. Spider2-v: How far are multimodal agents from automating data science and engineering workflows?, 2024
work page 2024
-
[53]
Chen, A., Lou, L., Chen, K., Bai, X., Xiang, Y., Yang, M., Zhao, T., and Zhang, M. Benchmarking LLM s for translating classical C hinese poetry: Evaluating adequacy, fluency, and elegance. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ ...
-
[54]
Gui-world: A video benchmark and dataset for multimodal gui-oriented understanding
Chen, D., Huang, Y., Wu, S., Tang, J., Chen, L., Bai, Y., He, Z., Wang, C., Zhou, H., Li, Y., et al. Gui-world: A video benchmark and dataset for multimodal gui-oriented understanding. arXiv preprint arXiv:2406.10819, 2024
-
[55]
Mind2web: Towards a generalist agent for the web, 2023
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., and Su, Y. Mind2web: Towards a generalist agent for the web, 2023
work page 2023
-
[56]
Fu, T., Su, A., Zhao, C., Wang, H., Wu, M., Yu, Z., Hu, F., Shi, M., Dong, W., Wang, J., Chen, Y., Yu, R., Peng, S., Li, M., Huang, N., Wei, H., Yu, J., Xin, Y., Zhao, X., Gu, K., Jiang, P., Zhou, S., and Wang, S. Mano technical report, 2025
work page 2025
-
[57]
Gou, B., Huang, Z., Ning, Y., Gu, Y., Lin, M., Yu, B., Kopanev, A., Qi, W., Shu, Y., Wu, J., Song, C. H., Gutierrez, B. J., Li, Y., Liao, Z., Moussa, H. N., ZHANG, T., Xie, J., Xue, T., Chen, S., Zheng, B., Zhang, K., Cai, Z., Rozgic, V., Ziyadi, M., Sun, H., and Su, Y. Mind2web 2: Evaluating agentic search with agent-as-a-judge. In The Thirty-ninth Annua...
work page 2025
-
[58]
Cogagent: A visual language model for gui agents, 2024
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Zhang, Y., Li, J., Xu, B., Dong, Y., Ding, M., and Tang, J. Cogagent: A visual language model for gui agents, 2024
work page 2024
-
[59]
Screenspot: Multidimensional resource discovery for distributed applications in smart spaces
Jurmu, M., Boring, S., and Riekki, J. Screenspot: Multidimensional resource discovery for distributed applications in smart spaces. In Proceedings of the 5th Annual International Conference on Mobile and Ubiquitous Systems: Computing, Networking, and Services, pp.\ 1--9, 2008
work page 2008
-
[60]
Kapoor, R., Butala, Y. P., Russak, M., Koh, J. Y., Kamble, K., AlShikh, W., and Salakhutdinov, R. Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web. In European Conference on Computer Vision, pp.\ 161--178. Springer, 2024
work page 2024
-
[61]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Koh, J. Y., Lo, R., Jang, L., Duvvur, V., Lim, M. C., Huang, P.-Y., Neubig, G., Zhou, S., Salakhutdinov, R., and Fried, D. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. arXiv preprint arXiv:2401.13649, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Screenspot-pro: GUI grounding for professional high-resolution computer use
Li, K., Ziyang, M., Lin, H., Luo, Z., Tian, Y., Ma, J., Huang, Z., and Chua, T.-S. Screenspot-pro: GUI grounding for professional high-resolution computer use. In Workshop on Reasoning and Planning for Large Language Models, 2025
work page 2025
-
[63]
End-to-end speech translation with adversarial training
Li, X., Kehai, C., Zhao, T., and Yang, M. End-to-end speech translation with adversarial training. In Wu, H., Cherry, C., Huang, L., He, Z., Liberman, M., Cross, J., and Liu, Y. (eds.), Proceedings of the First Workshop on Automatic Simultaneous Translation, pp.\ 10--14, Seattle, Washington, July 2020. Association for Computational Linguistics. doi:10.186...
-
[64]
XIFB ench: Evaluating large language models on multilingual instruction following
Li, Z., Bai, X., LONG, Y., Chen, K., Zhang, Y., Wei, X., Li, J., and Zhang, M. XIFB ench: Evaluating large language models on multilingual instruction following. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026
work page 2026
-
[65]
Tool learning via inference-time scaling and cycle verifier
Liang, X., Xie, W., Li, J., Wang, W., Chen, Y., Chen, K., and Zhang, M. Tool learning via inference-time scaling and cycle verifier. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 24658--24671, Vienna, Austria, July 2025. Association for Computational Linguistics....
-
[66]
Q., Li, L., Gao, D., Wu, Q., Yan, M., Yang, Z., Wang, L., and Shou, M
Lin, K. Q., Li, L., Gao, D., Wu, Q., Yan, M., Yang, Z., Wang, L., and Shou, M. Z. Videogui: A benchmark for gui automation from instructional videos. In NeurIPS, 2024
work page 2024
-
[67]
Liu, X., Qin, B., Liang, D., Dong, G., Lai, H., Zhang, H., Zhao, H., Iong, I. L., Sun, J., Wang, J., et al. Autoglm: Autonomous foundation agents for guis. arXiv preprint arXiv:2411.00820, 2024
-
[68]
Towards conversational recommendation over multi-type dialogs
Liu, Z., Wang, H., Niu, Z.-Y., Wu, H., Che, W., and Liu, T. Towards conversational recommendation over multi-type dialogs. In Jurafsky, D., Chai, J., Schluter, N., and Tetreault, J. (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 1036--1049, Online, July 2020. Association for Computational Linguistics....
-
[69]
D u R ec D ial 2.0: A bilingual parallel corpus for conversational recommendation
Liu, Z., Wang, H., Niu, Z.-Y., Wu, H., and Che, W. D u R ec D ial 2.0: A bilingual parallel corpus for conversational recommendation. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 4335--4347, Online and Punta Cana, Dominican Republic, November ...
-
[70]
Where to go for the holidays: Towards mixed-type dialogs for clarification of user goals
Liu, Z., Xu, J., Lei, Z., Wang, H., Niu, Z.-Y., and Wu, H. Where to go for the holidays: Towards mixed-type dialogs for clarification of user goals. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1024--1034, Dublin, Ireland, May ...
-
[71]
A survey on the feedback mechanism of llm-based ai agents
Liu, Z., Bai, X., Chen, K., Chen, X., Li, X., Xiang, Y., Liu, J., Li, H.-D., Wang, Y., Nie, L., and Zhang, M. A survey on the feedback mechanism of llm-based ai agents. In Kwok, J. (ed.), Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25 , pp.\ 10582--10592. International Joint Conferences on Artificial I...
-
[72]
Lu, Y., Yu, Q., Wang, H., Liu, Z., Su, W., Liu, Y., Guo, Y., Liang, M., Wang, Y., and Wang, H. T rans B ench: Breaking barriers for transferable graphical user interface agents in dynamic digital environments. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 12464--...
-
[73]
Nguyen, D., Chen, J., Wang, Y., Wu, G., Park, N., Hu, Z., Lyu, H., Wu, J., Aponte, R., Xia, Y., et al. Gui agents: A survey. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 22522--22538, 2025
work page 2025
-
[74]
WebCanvas: Benchmarking Web Agents in Online Environments
Pan, Y., Kong, D., Zhou, S., Cui, C., Leng, Y., Jiang, B., Liu, H., Shang, Y., Zhou, S., Wu, T., et al. Webcanvas: Benchmarking web agents in online environments. arXiv preprint arXiv:2406.12373, 2024
work page internal anchor Pith review arXiv 2024
-
[75]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Qin, Y., Ye, Y., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y., Huang, S., et al. Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Android in the wild: A large-scale dataset for android device control, 2023
Rawles, C., Li, A., Rodriguez, D., Riva, O., and Lillicrap, T. Android in the wild: A large-scale dataset for android device control, 2023
work page 2023
-
[77]
M id M ed: Towards mixed-type dialogues for medical consultation
Shi, X., Liu, Z., Wang, C., Leng, H., Xue, K., Zhang, X., and Zhang, S. M id M ed: Towards mixed-type dialogues for medical consultation. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8145--8157, Toronto, Canada, July 2023. Assoc...
-
[78]
Wang, L., Deng, Y., Zha, Y., Mao, G., Wang, Q., Min, T., Chen, W., and Chen, S. Mobileagentbench: An efficient and user-friendly benchmark for mobile LLM agents. CoRR, abs/2406.08184, 2024 a . doi:10.48550/ARXIV.2406.08184
-
[79]
Gui agents with foundation models: A comprehensive survey
Wang, S., Liu, W., Chen, J., Zhou, Y., Gan, W., Zeng, X., Che, Y., Yu, S., Hao, X., Shao, K., et al. Gui agents with foundation models: A comprehensive survey. arXiv preprint arXiv:2411.04890, 2024 b
-
[80]
Wang, X., Wang, B., Lu, D., Yang, J., Xie, T., Wang, J., Deng, J., Guo, X., Xu, Y., Wu, C. H., Shen, Z., Li, Z., Li, R., Li, X., Chen, J., Zheng, B., Li, P., Lei, F., Cao, R., Fu, Y., Shin, D., Shin, M., Hu, J., Wang, Y., Chen, J., Ye, Y., Zhang, D., Du, D., Hu, H., Chen, H., Zhou, Z., Yao, H., Chen, Z., Gu, Q., Wang, Y., Wang, H., Yang, D., Zhong, V., Su...
work page 2025
-
[81]
Os-copilot: Towards generalist computer agents with self-improvement, 2024 a
Wu, Z., Han, C., Ding, Z., Weng, Z., Liu, Z., Yao, S., Yu, T., and Kong, L. Os-copilot: Towards generalist computer agents with self-improvement, 2024 a
work page 2024
-
[82]
Wu, Z., Wu, Z., Xu, F., Wang, Y., Sun, Q., Jia, C., Cheng, K., Ding, Z., Chen, L., Liang, P. P., and Qiao, Y. Os-atlas: A foundation action model for generalist gui agents, 2024 b
work page 2024
-
[83]
GUI -explorer: Autonomous exploration and mining of transition-aware knowledge for GUI agent
Xie, B., Shao, R., Chen, G., Zhou, K., Li, Y., Liu, J., Zhang, M., and Nie, L. GUI -explorer: Autonomous exploration and mining of transition-aware knowledge for GUI agent. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ ...
-
[84]
J., Cheng, Z., Shin, D., Lei, F., et al
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T. J., Cheng, Z., Shin, D., Lei, F., et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37: 0 52040--52094, 2024
work page 2024
-
[85]
Xu, R., Ma, K., Yu, W., Zhang, H., Ho, J. C., Yang, C., and Yu, D. Retrieval-augmented gui agents with generative guidelines. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 17877--17886, 2025 a
work page 2025
-
[86]
Crab: Cross-environment agent benchmark for multimodal language model agents
Xu, T., Chen, L., Wu, D.-J., Chen, Y., Zhang, Z., Yao, X., Xie, Z., Chen, Y., Liu, S., Qian, B., et al. Crab: Cross-environment agent benchmark for multimodal language model agents. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 21607--21647, 2025 b
work page 2025
-
[87]
Aguvis: Unified pure vision agents for autonomous gui interaction
Xu, Y., Wang, Z., Wang, J., Lu, D., Xie, T., Saha, A., Sahoo, D., Yu, T., and Xiong, C. Aguvis: Unified pure vision agents for autonomous gui interaction. In Forty-second International Conference on Machine Learning
-
[88]
Step-gui technical report.arXiv preprint arXiv:2512.15431, 2025
Yan, H., Wang, J., Huang, X., Shen, Y., Meng, Z., Fan, Z., Tan, K., Gao, J., Shi, L., Yang, M., et al. Step-gui technical report. arXiv preprint arXiv:2512.15431, 2025
-
[89]
Webshop: Towards scalable real-world web interaction with grounded language agents
Yao, S., Chen, H., Yang, J., and Narasimhan, K. Webshop: Towards scalable real-world web interaction with grounded language agents. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orlea...
work page 2022
-
[90]
Mobile-Agent-v3: Fundamental Agents for GUI Automation
Ye, J., Zhang, X., Xu, H., Liu, H., Wang, J., Zhu, Z., Zheng, Z., Gao, F., Cao, J., Lu, Z., et al. Mobile-agent-v3: Fundamental agents for gui automation. arXiv preprint arXiv:2508.15144, 2025
work page internal anchor Pith review arXiv 2025
-
[91]
A survey on multimodal large language models
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., and Chen, E. A survey on multimodal large language models. National Science Review, 11 0 (12): 0 nwae403, 2024
work page 2024
-
[92]
Tongui: Internet-scale trajectories from multimodal web tutorials for generalized gui agents, 2025
Zhang, B., Shang, Z., Gao, Z., Zhang, W., Xie, R., Ma, X., Yuan, T., Wu, X., Zhu, S.-C., and Li, Q. Tongui: Internet-scale trajectories from multimodal web tutorials for generalized gui agents, 2025
work page 2025
-
[93]
Appagent: Multimodal agents as smartphone users, 2023
Zhang, C., Yang, Z., Liu, J., Han, Y., Chen, X., Huang, Z., Fu, B., and Yu, G. Appagent: Multimodal agents as smartphone users, 2023
work page 2023
-
[94]
Zhou, H., Zhang, X., Tong, P., Zhang, J., Chen, L., Kong, Q., Cai, C., Liu, C., Wang, Y., Zhou, J., et al. Mai-ui technical report: Real-world centric foundation gui agents. arXiv preprint arXiv:2512.22047, 2025
-
[95]
F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., et al
Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., et al. Webarena: A realistic web environment for building autonomous agents. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.