EaDex: A Cross-Embodiment Dexterous Manipulation Framework from Low-Cost Demonstrations
Pith reviewed 2026-06-28 09:54 UTC · model grok-4.3
The pith
EaDex learns dexterous manipulation across robot hands from single-camera human demos via contact-based annealing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
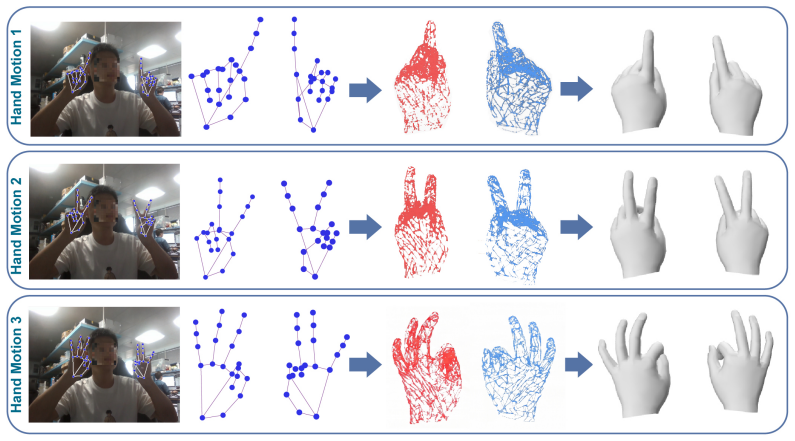
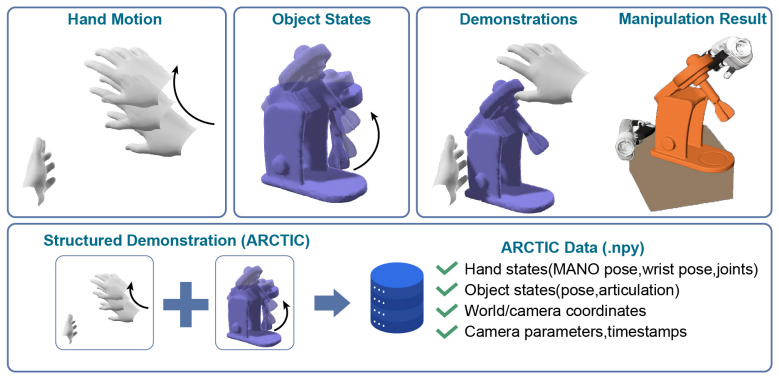
EaDex is a multi-embodiment dexterous manipulation learning framework that captures human hand motions using only a single RGB-D camera and constructs structured demonstration data through MANO-based hand modeling, data normalization, and motion retargeting; at the learning level it introduces a contact-reward-based dynamic demonstration annealing mechanism that guides early-stage exploration under demonstration and gradually transitions to autonomous optimization with accumulating contact rewards, achieving a 55.3% relative improvement over the baseline without demonstration annealing on three dexterous hands and three articulated object-opening tasks covering nine cross-embodiment settings
What carries the argument
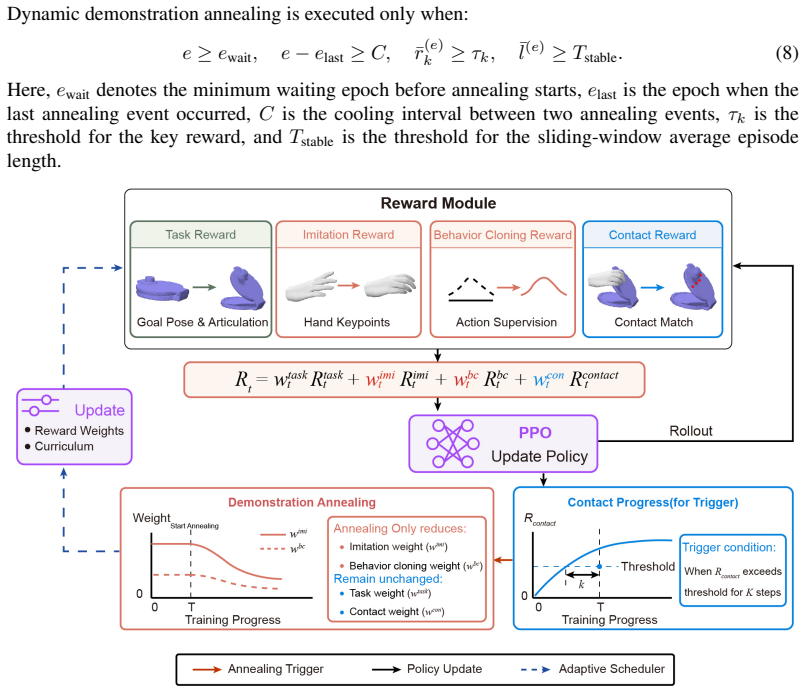
The contact-reward-based dynamic demonstration annealing mechanism, which starts training under demonstration guidance and reduces that guidance as contact rewards accumulate to enable autonomous optimization.
If this is right
- Demonstration data can be generated rapidly from low-cost camera captures, shortening overall training time.
- The same pipeline supports nine distinct cross-embodiment settings on three different dexterous hands and three object-opening tasks.
- The annealing strategy yields a 55.3 percent relative performance gain compared with training that lacks it.
- Both the low-cost data pipeline and the annealing approach are validated as effective for dexterous manipulation.
Where Pith is reading between the lines
- The same low-cost capture and retargeting steps could be applied to non-opening manipulation skills without major redesign.
- Contact-driven annealing might transfer to other imitation-plus-reinforcement setups where embodiment changes frequently.
- Lower data costs could shorten the time from lab prototype to varied real-world dexterous deployments.
- Testing the framework on tasks without clear contact events would reveal how far the reward signal generalizes.
Load-bearing premise
The contact reward definition supplies a reliable, unbiased signal for deciding when to reduce demonstration guidance without requiring per-embodiment tuning.
What would settle it
Training runs across the nine settings that remove the annealing schedule or alter the contact reward definition and produce no measurable gain over the non-annealed baseline.
Figures


read the original abstract
Dexterous manipulation learning has long been hindered by the high costs of data and training, as pure reinforcement learning typically requires large-scale interactive exploration and imitation learning depends on high-quality demonstrations that are expensive to collect. To address this problem, we propose EaDex, a multi-embodiment dexterous manipulation learning framework under low-cost demonstration conditions, which enables rapid generation of demonstration data and consequently reduces training time for efficient dexterous manipulation. At the data level, EaDex captures human hand motions using only a single RGB-D camera and constructs structured demonstration data through MANO-based hand modeling, data normalization, and motion retargeting. At the learning level, we introduce a contact-reward-based dynamic demonstration annealing mechanism, which guides early-stage exploration under demonstration and gradually transitions to autonomous optimization with accumulating contact rewards. Using our custom dataset, we evaluate EaDex on three dexterous hands and three articulated object-opening tasks, covering nine cross-embodiment manipulation settings, achieving a 55.3% relative improvement over the baseline without demonstration annealing. These results validate the effectiveness of the proposed low-cost demonstration pipeline and the dynamic demonstration annealing strategy for dexterous manipulation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EaDex, a cross-embodiment dexterous manipulation framework that generates low-cost demonstrations from a single RGB-D camera via MANO-based modeling, normalization, and retargeting, then uses a contact-reward-based dynamic demonstration annealing mechanism to guide early training before shifting to autonomous optimization. It evaluates the approach on three dexterous hands and three articulated object-opening tasks (nine settings total) and reports a 55.3% relative improvement over a baseline without annealing.
Significance. If the annealing mechanism proves general and the empirical gains hold under standard reporting, the low-cost data pipeline and embodiment-agnostic training strategy could meaningfully reduce data and compute barriers in dexterous manipulation. The multi-embodiment scope across nine settings is a strength worth building upon.
major comments (3)
- [Abstract] Abstract: the central claim of a 55.3% relative improvement supplies no baseline algorithm name or reference, no task-success definition, no trial count, no error bars, and no statistical test, rendering the headline result unverifiable from the provided information.
- [Learning level] Learning level (contact-reward annealing): no equation, pseudocode, normalization details, or threshold values are given for the contact reward or the annealing schedule. This is load-bearing for the claim that the mechanism requires no embodiment-specific tuning across the three hands, because contact detection or scaling could embed hand-specific biases.
- [Evaluation] Evaluation section: no ablation isolating the annealing contribution from the data pipeline is described, nor are full baseline implementations or hyperparameter settings reported, preventing assessment of whether the reported gain is attributable to the proposed mechanism.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named the three hands and three tasks rather than referring only to 'our custom dataset.'
Simulated Author's Rebuttal
We thank the referee for the constructive comments on improving the verifiability and technical detail of the manuscript. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 55.3% relative improvement supplies no baseline algorithm name or reference, no task-success definition, no trial count, no error bars, and no statistical test, rendering the headline result unverifiable from the provided information.
Authors: We agree that the abstract would benefit from additional context to make the headline result verifiable on its own. In the revised manuscript we will expand the abstract to name the baseline (without demonstration annealing), define task success, report trial counts, include error bars, and reference statistical tests. These details already appear in the evaluation section and will be highlighted in the abstract. revision: yes
-
Referee: [Learning level] Learning level (contact-reward annealing): no equation, pseudocode, normalization details, or threshold values are given for the contact reward or the annealing schedule. This is load-bearing for the claim that the mechanism requires no embodiment-specific tuning across the three hands, because contact detection or scaling could embed hand-specific biases.
Authors: We acknowledge that the current description lacks the mathematical and implementation details needed to substantiate the embodiment-agnostic claim. We will add the contact-reward equation, pseudocode for the dynamic annealing schedule, normalization procedures, and threshold values to the methods section. These additions will explicitly show that no hand-specific tuning is required. revision: yes
-
Referee: [Evaluation] Evaluation section: no ablation isolating the annealing contribution from the data pipeline is described, nor are full baseline implementations or hyperparameter settings reported, preventing assessment of whether the reported gain is attributable to the proposed mechanism.
Authors: We agree that an explicit ablation isolating the annealing mechanism and fuller reporting of baselines and hyperparameters would strengthen the evaluation. We will add the requested ablation study, baseline implementation details, and hyperparameter tables in the revised manuscript to allow clear attribution of the performance gains. revision: yes
Circularity Check
No significant circularity; empirical evaluation stands independent of inputs
full rationale
The paper presents EaDex as a framework with a data pipeline (RGB-D capture, MANO modeling, retargeting) and a contact-reward annealing mechanism, evaluated empirically on a custom dataset across nine cross-embodiment settings. The reported 55.3% relative improvement is stated as a measured outcome versus a baseline without annealing. No equations, parameter fits renamed as predictions, self-definitional reductions, or load-bearing self-citations appear in the provided text. The central claim rests on experimental results rather than any derivation that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MANO hand model plus normalization and retargeting preserves task-relevant motion information across embodiments
- ad hoc to paper Contact reward can be defined unambiguously and used to anneal demonstrations without embodiment-specific tuning
Reference graph
Works this paper leans on
- [2]
-
[3]
Y . Qin, B. Huang, Z.-H. Yin, H. Su, and X. Wang. Dexpoint: Generalizable point cloud rein- forcement learning for sim-to-real dexterous manipulation. InConference on Robot Learning, pages 594–605. PMLR, 2023
2023
-
[4]
T. Chen, J. Xu, and P. Agrawal. A system for general in-hand object re-orientation. InConfer- ence on robot learning, pages 297–307. PMLR, 2022
2022
- [5]
-
[6]
Zhang, Z
T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel. Deep imita- tion learning for complex manipulation tasks from virtual reality teleoperation. In2018 IEEE international conference on robotics and automation (ICRA), pages 5628–5635. Ieee, 2018
2018
-
[7]
Radosavovic, X
I. Radosavovic, X. Wang, L. Pinto, and J. Malik. State-only imitation learning for dexterous manipulation. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7865–7871. IEEE, 2021
2021
-
[8]
E. Johns. Coarse-to-fine imitation learning: Robot manipulation from a single demonstration. In2021 IEEE international conference on robotics and automation (ICRA), pages 4613–4619. IEEE, 2021
2021
-
[9]
L. P. Kaelbling, M. L. Littman, and A. W. Moore. Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996
1996
-
[10]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
A. Rajeswaran, V . Kumar, A. Gupta, G. Vezzani, J. Schulman, E. Todorov, and S. Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstra- tions.arXiv preprint arXiv:1709.10087, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
H. Zhu, A. Gupta, A. Rajeswaran, S. Levine, and V . Kumar. Dexterous manipulation with deep reinforcement learning: Efficient, general, and low-cost. In2019 International Conference on Robotics and Automation (ICRA), pages 3651–3657. IEEE, 2019
2019
-
[12]
Z. Fan, O. Taheri, D. Tzionas, M. Kocabas, M. Kaufmann, M. J. Black, and O. Hilliges. Arctic: A dataset for dexterous bimanual hand-object manipulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12943–12954, 2023
2023
-
[13]
X. Zhan, L. Yang, Y . Zhao, K. Mao, H. Xu, Z. Lin, K. Li, and C. Lu. Oakink2: A dataset of bimanual hands-object manipulation in complex task completion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 445–456, 2024
2024
- [14]
- [15]
-
[16]
T. Tao, M. K. Srirama, J. J. Liu, K. Shaw, and D. Pathak. Dexwild: Dexterous human interac- tions for in-the-wild robot policies.arXiv preprint arXiv:2505.07813, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, et al. Learning dexterous in-hand manipulation. The International Journal of Robotics Research, 39(1):3–20, 2020
2020
-
[18]
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik. In-hand object rotation via rapid motor adaptation. InConference on Robot Learning, pages 1722–1732. PMLR, 2023
2023
- [19]
-
[20]
H. Yuan, B. Zhou, Y . Fu, and Z. Lu. Cross-embodiment dexterous grasping with reinforce- ment learning. InInternational Conference on Learning Representations, volume 2025, pages 81413–81434, 2025
2025
-
[21]
T. Zhu, R. Wu, J. Hang, X. Lin, and Y . Sun. Toward human-like grasp: Functional grasp by dexterous robotic hand via object-hand semantic representation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):12521–12534, 2023
2023
-
[22]
Mandikal and K
P. Mandikal and K. Grauman. Learning dexterous grasping with object-centric visual affor- dances. In2021 IEEE international conference on robotics and automation (ICRA), pages 6169–6176. IEEE, 2021
2021
-
[23]
Zhang, S
H. Zhang, S. Christen, Z. Fan, O. Hilliges, and J. Song. Graspxl: Generating grasping motions for diverse objects at scale. InEuropean Conference on Computer Vision, pages 386–403. Springer, 2024
2024
-
[24]
K. Xu, Z. Hu, R. Doshi, A. Rovinsky, V . Kumar, A. Gupta, and S. Levine. Dexterous manipula- tion from images: Autonomous real-world rl via substep guidance. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5938–5945. IEEE, 2023
2023
-
[25]
C. Bao, H. Xu, Y . Qin, and X. Wang. Dexart: Benchmarking generalizable dexterous manip- ulation with articulated objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21190–21200, 2023
2023
-
[26]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [27]
-
[28]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos. InEuropean Conference on Computer Vision, pages 570–587. Springer, 2022
2022
-
[29]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022
2022
-
[30]
Y . Qin, H. Su, and X. Wang. From one hand to multiple hands: Imitation learning for dexterous manipulation from single-camera teleoperation.IEEE Robotics and Automation Letters, 7(4): 10873–10881, 2022
2022
-
[31]
X. Gao, K. Yao, F. Khadivar, and A. Billard. Enhancing dexterity in confined spaces: Real- time motion planning for multifingered in-hand manipulation.IEEE Robotics & Automation Magazine, 31(4):100–112, 2024. 10
2024
- [32]
-
[33]
Patel, S
A. Patel, S. L. Shield, S. Kazi, A. M. Johnson, and L. T. Biegler. Contact-implicit trajectory optimization using orthogonal collocation.IEEE Robotics and Automation Letters, 4(2):2242– 2249, 2019
2019
-
[34]
F. Yang, T. Power, S. A. Marinovic, S. Iba, R. S. Zarrin, and D. Berenson. Multi-finger manip- ulation via trajectory optimization with differentiable rolling and geometric constraints.IEEE Robotics and Automation Letters, 2025
2025
-
[35]
Zhang, D
M. Zhang, D. K. Jha, A. U. Raghunathan, and K. Hauser. Simultaneous trajectory optimiza- tion and contact selection for contact-rich manipulation with high-fidelity geometry.IEEE Transactions on Robotics, 2025
2025
-
[36]
B. Ai, S. Tian, H. Shi, Y . Wang, T. Pfaff, C. Tan, H. I. Christensen, H. Su, J. Wu, and Y . Li. A review of learning-based dynamics models for robotic manipulation.Science Robotics, 10 (106):eadt1497, 2025
2025
-
[37]
Mediapipe hands: On-device real-time hand tracking,
F. Zhang, V . Bazarevsky, A. Vakunov, A. Tkachenka, G. Sung, C.-L. Chang, and M. Grund- mann. Mediapipe hands: On-device real-time hand tracking.arXiv preprint arXiv:2006.10214, 2020
-
[38]
Embodied hands: Modeling and capturing hands and bodies together.arXiv preprint arXiv:2201.02610,
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: Modeling and capturing hands and bodies together.arXiv preprint arXiv:2201.02610, 2022
-
[39]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.