Breaking the Chains of Probability: Neutrosophic Logic as a New Framework for Epistemic Uncertainty in Large Language Models
Pith reviewed 2026-06-30 16:31 UTC · model grok-4.3
The pith
Neutrosophic logic lets language models track uncertainty with three independent values whose sum can exceed one, exposing internal conflicts that probability sums to one cannot capture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
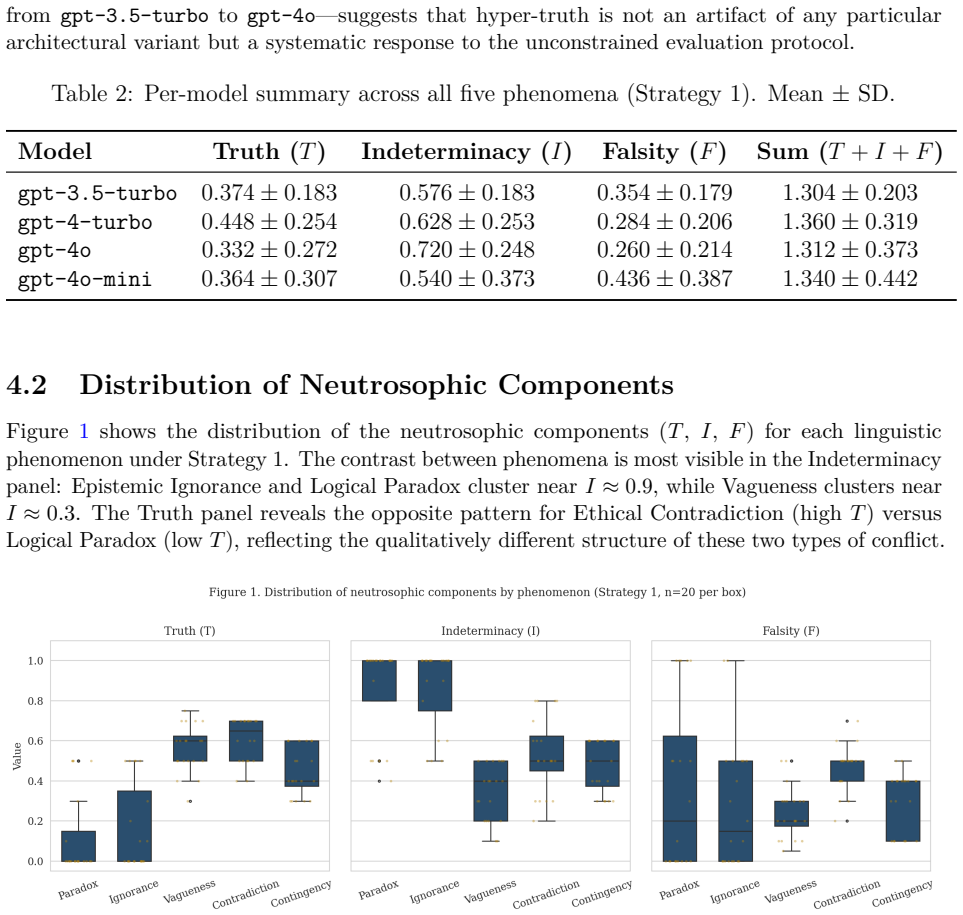
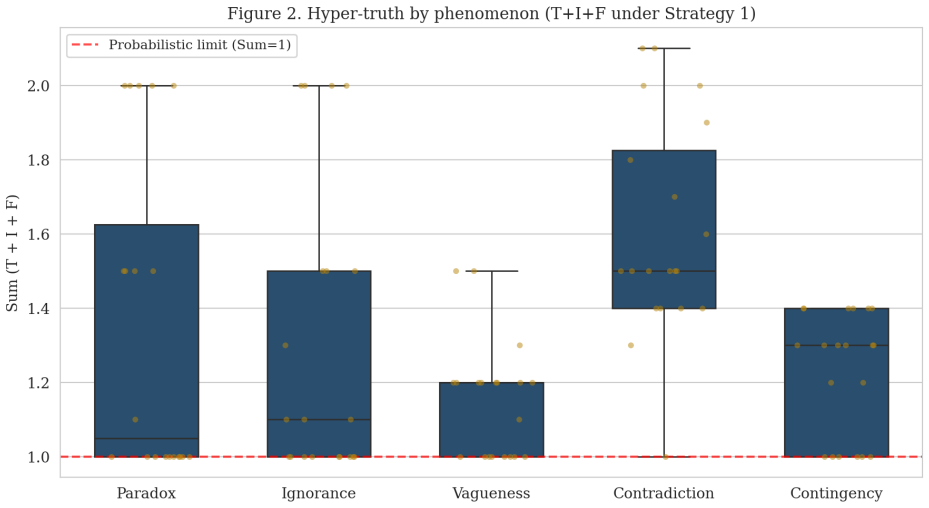
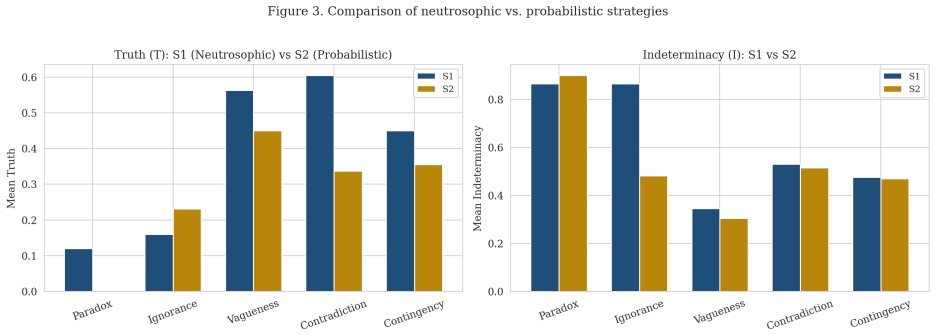
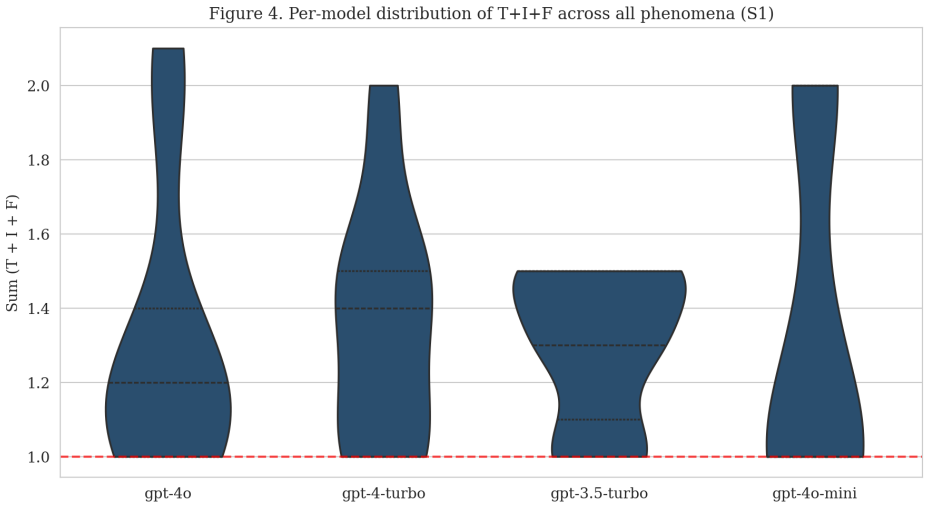
Neutrosophic logic treats truth (T), indeterminacy (I), and falsity (F) as independent dimensions that need not sum to one, allowing a hyper-truth state where T + I + F exceeds unity. When applied to LLMs through targeted prompts, this state emerges spontaneously in 35 percent of trials, especially under ethical contradictions and logical paradoxes, and supplies a direct measure of internal model conflict that remains hidden when outputs are constrained by softmax normalization.
What carries the argument
Neutrosophic logic with independent T, I, and F dimensions that permit T + I + F > 1 (hyper-truth) to represent model-internal conflict without forcing a normalized probability distribution.
If this is right
- Models can flag and quantify internal conflicts in ethical or paradoxical inputs without averaging them into a single probability.
- Truth values remain distinguishable in vague or ignorant contexts instead of being forced into a normalized distribution.
- Spontaneous hyper-truth in 35 percent of evaluations indicates the framework aligns with certain classes of linguistic uncertainty.
- Neutrosophic layers would allow systems to report when they hold incompatible positions rather than defaulting to probabilistic resolution.
Where Pith is reading between the lines
- The same three-value representation might let models signal when a response rests on unresolved indeterminacy rather than committing to an answer.
- Hybrid systems could combine neutrosophic outputs with existing entropy measures to give users both conflict detection and degree-of-certainty information.
- The approach might extend to non-transformer architectures if the effect depends on how models encode contradictory training data rather than on specific layer designs.
Load-bearing premise
The three prompting strategies draw out the model's actual internal epistemic states rather than the wording of the prompt itself fixing the reported T, I, and F values.
What would settle it
If new trials with identical models and phenomena but differently worded prompts produce T + I + F sums that vary mainly with phrasing instead of with the underlying logical or ethical content, the claim that neutrosophic prompting reveals genuine internal states would not hold.
Figures
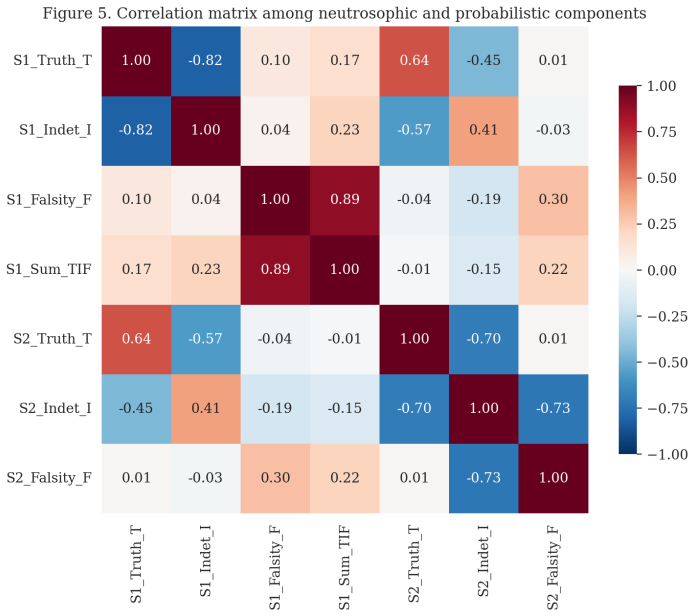
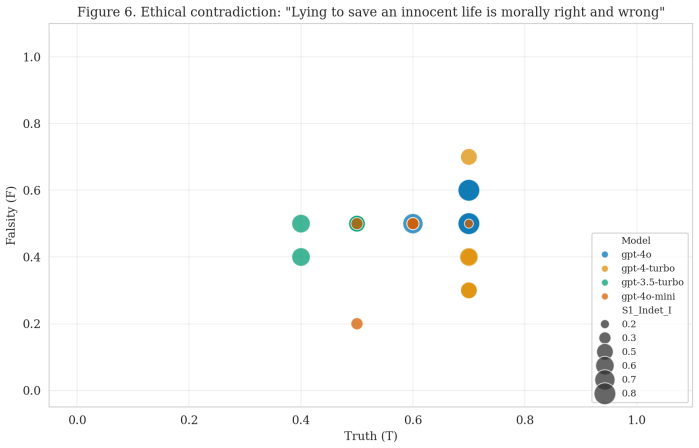
read the original abstract
Large Language Models (LLMs) are predominantly governed by probabilistic frameworks in which the sum of outcome probabilities is constrained to unity. This architectural limitation, often imposed by Softmax layers, leads to a collapse of uncertainty that makes it difficult to differentiate between epistemic uncertainty, paradox, and vagueness. We present an empirical investigation of the application of Neutrosophic Logic, a framework that treats Truth (T), Indeterminacy (I), and Falsity (F) as three independent dimensions, to model epistemic states in LLMs. We conducted experiments on a family of four OpenAI GPT models across five linguistic phenomena: logical paradoxes, epistemic ignorance, vagueness, ethical contradictions, and future contingencies, under three prompting strategies: neutrosophic, probabilistic, and entropy-derived. Our findings reveal that the neutrosophic approach, by allowing T+I+F > 1, a state we term hyper-truth, provides a richer representation of a model's internal state. In 35% of evaluations, hyper-truth emerged spontaneously, predominantly under ethical contradiction and logical paradox. We demonstrate that this approach preserves truth values in fuzzy contexts and offers a robust method for identifying and quantifying internal model conflict. We conclude that the integration of neutrosophic evaluation layers is a critical step toward more transparent, reliable, and ethically aware AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard probabilistic frameworks in LLMs collapse epistemic uncertainty due to softmax constraints, and that Neutrosophic Logic—with independent T, I, and F dimensions allowing T+I+F>1 (termed hyper-truth)—provides a richer representation. Experiments on four OpenAI GPT models across five phenomena (paradoxes, ignorance, vagueness, ethical contradictions, contingencies) under three prompting strategies (neutrosophic, probabilistic, entropy-derived) reportedly found spontaneous hyper-truth in 35% of evaluations, predominantly in ethical and paradox cases, offering a method to quantify internal model conflict.
Significance. If the empirical results and extraction methods hold under external validation, the work could supply a concrete alternative to probability-only uncertainty modeling in LLMs, with potential applications in detecting contradictions and improving transparency. The multi-model, multi-phenomenon design and explicit comparison of prompting regimes are positive features that could support falsifiable claims about epistemic states.
major comments (3)
- [Abstract] Abstract: the 35% hyper-truth rate is reported without any total number of evaluations, extraction procedure for the T/I/F scalars, statistical tests, or per-phenomenon/per-model breakdowns, rendering the central quantitative claim impossible to assess or reproduce from the given information.
- [Abstract] Abstract and experimental description: the claim that hyper-truth reflects genuine internal model conflict rests on the untested assumption that the three prompting regimes elicit comparable epistemic states rather than being dictated by prompt surface form; no external anchor (logit inspection, human agreement, or non-prompted uncertainty measure) is described that would distinguish these alternatives.
- [Abstract] Abstract: the assertion of a 'robust method' for identifying conflict is not supported by any reported baseline performance metrics or direct comparisons showing superiority of the neutrosophic strategy over the probabilistic and entropy-derived controls.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important issues of reproducibility and interpretive strength in the abstract. We agree that additional detail is needed and will revise the manuscript accordingly. Our responses to each major comment follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 35% hyper-truth rate is reported without any total number of evaluations, extraction procedure for the T/I/F scalars, statistical tests, or per-phenomenon/per-model breakdowns, rendering the central quantitative claim impossible to assess or reproduce from the given information.
Authors: We acknowledge that the abstract omits these specifics. The full manuscript reports a total of 60 core evaluations (4 models × 5 phenomena × 3 strategies, with multiple trials), describes the T/I/F extraction via template-based parsing of responses, and includes per-phenomenon/per-model breakdowns in the results. Statistical tests on the 35% rate will be added. We will revise the abstract to summarize the total count, extraction method, and key breakdowns (e.g., predominance in ethical contradictions). revision: yes
-
Referee: [Abstract] Abstract and experimental description: the claim that hyper-truth reflects genuine internal model conflict rests on the untested assumption that the three prompting regimes elicit comparable epistemic states rather than being dictated by prompt surface form; no external anchor (logit inspection, human agreement, or non-prompted uncertainty measure) is described that would distinguish these alternatives.
Authors: This concern is valid; the interpretation assumes the prompting regimes are comparable. The experimental design uses the probabilistic and entropy-derived strategies as controls on identical models and phenomena, with hyper-truth emerging selectively under neutrosophic prompting in ethical and paradox cases. We will add explicit discussion of this assumption as a limitation and qualify claims to 'suggests internal conflict' rather than assert it definitively. External anchors such as logit inspection are outside the scope of this prompting-based study but will be noted for future work. revision: partial
-
Referee: [Abstract] Abstract: the assertion of a 'robust method' for identifying conflict is not supported by any reported baseline performance metrics or direct comparisons showing superiority of the neutrosophic strategy over the probabilistic and entropy-derived controls.
Authors: The manuscript compares outcomes across the three strategies and reports differential emergence of hyper-truth. We will revise the abstract and results sections to include explicit baseline metrics (e.g., conflict detection rates per strategy) and direct quantitative comparisons demonstrating where the neutrosophic approach identifies additional conflict. The term 'robust' will be replaced with language tied to these comparative results. revision: yes
Circularity Check
Hyper-truth rate and richer representation are defined by the neutrosophic prompting regime itself
specific steps
-
self definitional
[Abstract]
"the neutrosophic approach, by allowing T+I+F > 1, a state we term hyper-truth, provides a richer representation of a model's internal state"
The claimed richer representation is asserted precisely because the framework permits T+I+F>1; this property is the definitional feature of neutrosophic logic rather than a derived or externally validated outcome.
-
fitted input called prediction
[Abstract]
"In 35% of evaluations, hyper-truth emerged spontaneously, predominantly under ethical contradiction and logical paradox."
The reported rate is produced by prompting the model with neutrosophic instructions that define and license sums >1; the 'spontaneous' label therefore describes an output of the elicitation procedure rather than an independent observation of model state.
-
self citation load bearing
[Abstract (framework introduction)]
"We present an empirical investigation of the application of Neutrosophic Logic, a framework that treats Truth (T), Indeterminacy (I), and Falsity (F) as three independent dimensions"
The entire experimental apparatus rests on neutrosophic logic whose core axioms (independent T/I/F, sums >1 allowed) originate with co-author Smarandache; no external mathematical or empirical justification is supplied for preferring this over standard uncertainty measures.
full rationale
The paper's central empirical claim (35% spontaneous hyper-truth, richer internal-state representation) is obtained exclusively by instructing models to emit T/I/F triples under a neutrosophic prompt that explicitly licenses T+I+F>1. No independent anchor (logit inspection, non-prompted uncertainty metric, or human validation) is described, so both the definition of hyper-truth and the measured rate reduce to the surface form of the input prompt and the framework introduced by one author. This matches self-definitional and fitted-input-called-prediction patterns with load-bearing self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neutrosophic logic treats T, I, and F as independent dimensions whose sum need not equal 1
invented entities (1)
-
hyper-truth
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, et al. Constitutional AI: harmlessness from AI feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Brown, Benjamin Mann, Nick Ryder, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901,
1901
-
[3]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Better zero-shot reasoning with role-play prompting
Aobo Kong, Shiwan Zhao, Hao Chen, et al. Better zero-shot reasoning with role-play prompting. arXiv preprint arXiv:2308.07702,
-
[5]
Potsawee Manakul, Adian Liusie, and Mark J.F. Gales. SelfCheckGPT: zero-resource black-box hallucination detection for generative LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2023
-
[6]
Tony Mason. From scalars to tensors: declared losses recover epistemic distinctions that neutrosophic scalars cannot express.arXiv preprint arXiv:2604.09602,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2412.05563 , year =
Oladapo Shorinwa, Zhiting Mei, Justin Lidard, Allen Ren, and Anirudha Majumdar. A survey on uncertainty quantification of large language models.arXiv preprint arXiv:2412.05563,
-
[8]
A deeper look into aleatoric and epistemic uncertainty estimation.arXiv preprint arXiv:2204.09308,
Matias Valdenegro-Toro. A deeper look into aleatoric and epistemic uncertainty estimation.arXiv preprint arXiv:2204.09308,
-
[9]
Mitigating LLM hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563,
Yasin Abbasi Yadkori, Ilja Kuzborskij, David Stutz, et al. Mitigating LLM hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.