Smoother Action Chunking Flow Policy via Prior-Corrected Orthogonal Trust-Region Guidance
Pith reviewed 2026-06-30 13:23 UTC · model grok-4.3
The pith
Prior-corrected orthogonal trust-region guidance strengthens mid-step corrections and limits sideways perturbations in flow-matching robot policies.
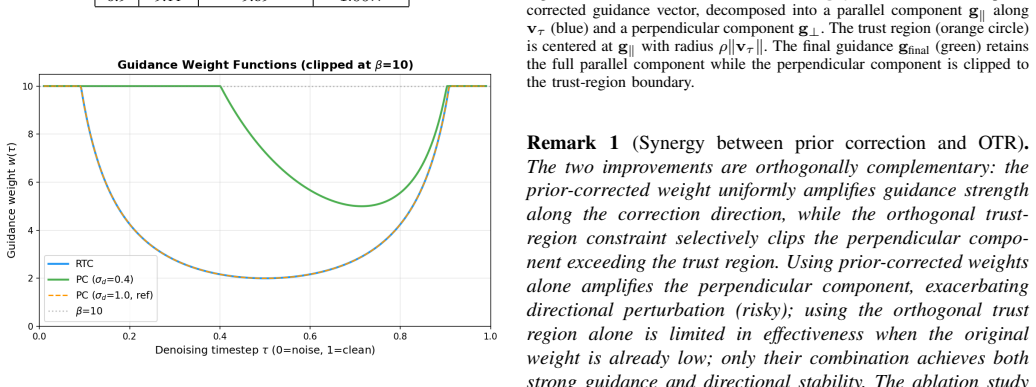
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
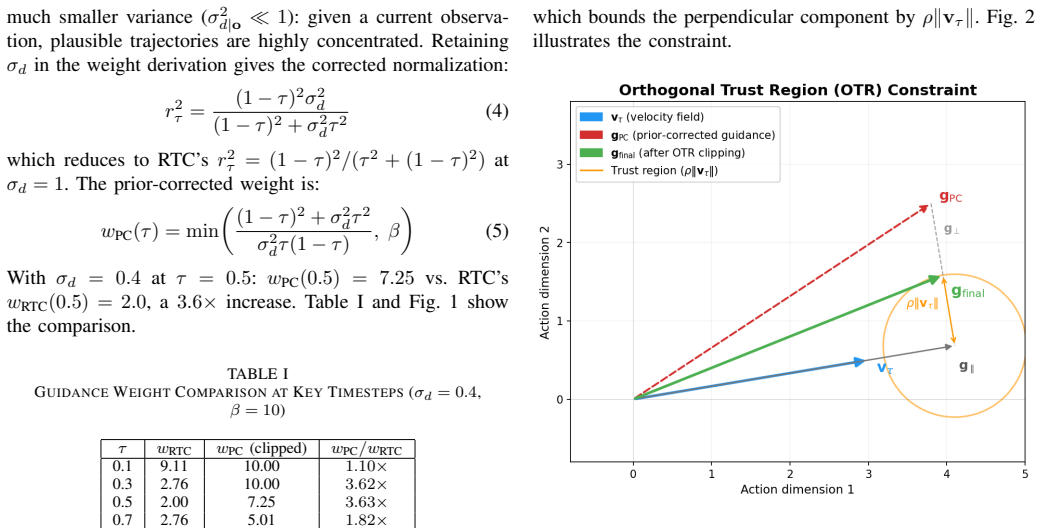
Incorporating a data-prior scale into the existing guidance weight produces stronger corrections at intermediate denoising steps, while decomposing the guidance vector into components parallel and perpendicular to the denoising velocity and constraining the perpendicular component inside a trust region removes transverse perturbations, together yielding smoother action transitions at chunk boundaries.
What carries the argument
POTR guidance, formed by scaling the RTC weight with data-prior σ_d and applying an orthogonal decomposition that limits the component of the correction vector perpendicular to the denoising velocity.
If this is right
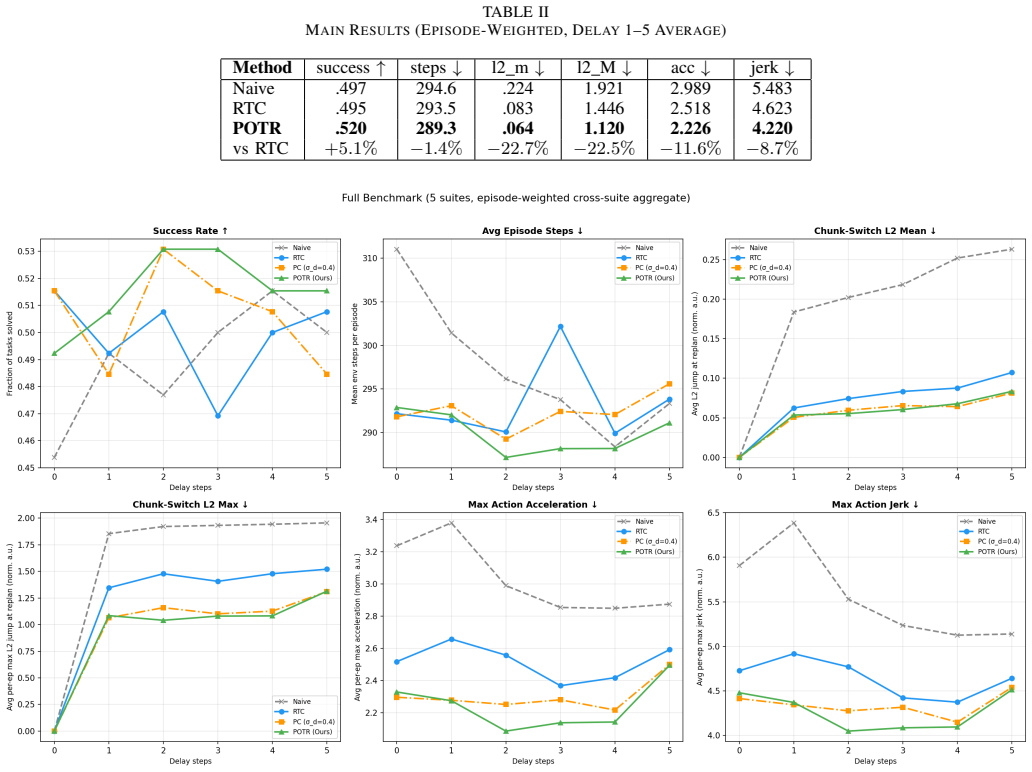
- On the LIBERO benchmark using the π0.5 policy, the method raises task success rate relative to prior guidance.
- Chunk-boundary discontinuity, acceleration, and jerk are lower than with the baseline correction method.
- The prior-corrected weight supplies the largest share of the continuity gain.
- Adding the orthogonal trust-region constraint supplies an additional stability improvement.
Where Pith is reading between the lines
- The same weighting and decomposition steps could be tested on flow models that generate sequences in other domains where chunk boundaries create artifacts.
- If boundary smoothness is reliably improved, longer action chunks may become usable without loss of closed-loop stability.
- The approach could be combined with different noise schedules to check whether the gains remain when the denoising trajectory itself changes.
Load-bearing premise
The chosen strength of the data-prior scale improves middle corrections without adding bias or instability to the overall denoising path, and the parallel-perpendicular split correctly isolates only the unwanted sideways effects.
What would settle it
An experiment that varies the data-prior scale across a range of values and records whether success rate falls or new instability appears at chunk boundaries, or that removes the perpendicular-component limit and measures whether boundary jerk then increases.
Figures
read the original abstract
Flow-matching robot policies commonly use action-chunking inference for efficient closed-loop control, but chunk boundaries can introduce discontinuous action transitions. Existing RTC guidance improves continuity by injecting correction signals during denoising, yet its weight schedule is weak at intermediate timesteps and its unconstrained correction direction may introduce transverse perturbations. We propose POTR, a **p**rior-corrected **o**rthogonal **t**rust-**r**egion guidance method. First, we incorporate a data-prior scale $\sigma_d$ into the RTC guidance weight, yielding stronger intermediate-time correction. Second, we decompose the guidance vector into components parallel and perpendicular to the denoising velocity, and constrain the perpendicular component within a trust region. On LIBERO with $\pi_{0.5}$, POTR improves success rate and consistently reduces chunk-boundary discontinuity, acceleration, and jerk compared with RTC. Ablations show that the prior-corrected weight provides the main correction gain, while the orthogonal trust region further improves stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes POTR (prior-corrected orthogonal trust-region guidance) to address discontinuous action transitions at chunk boundaries in flow-matching robot policies. Building on RTC guidance, it introduces a data-prior scale σ_d to strengthen intermediate-timestep corrections and decomposes the guidance vector into parallel and perpendicular components to the denoising velocity, constraining the perpendicular part via a trust region. On the LIBERO benchmark with π_{0.5}, the method is reported to improve success rate while reducing chunk-boundary discontinuity, acceleration, and jerk relative to RTC; ablations attribute the primary gain to the prior-corrected weight.
Significance. If the reported gains prove robust under statistical verification, the method could supply a practical, training-free refinement for continuity in closed-loop flow-based policies, a recurring practical issue in action chunking. The inclusion of an ablation study separating the contributions of σ_d and the trust-region component is a positive element. The work remains incremental on RTC and would benefit from stronger grounding of the new components.
major comments (3)
- [Abstract] Abstract: the central empirical claim (improved success rate and reduced jerk/acceleration on LIBERO) is stated without numerical values, error bars, number of seeds/trials, or statistical tests, preventing verification of the headline result.
- [Abstract] Abstract: no equation or derivation is supplied showing that the orthogonal decomposition (projection onto the velocity vector) commutes with the flow-matching ODE or that the trust-region radius can be chosen independently of σ_d without reintroducing transverse coupling through the score network.
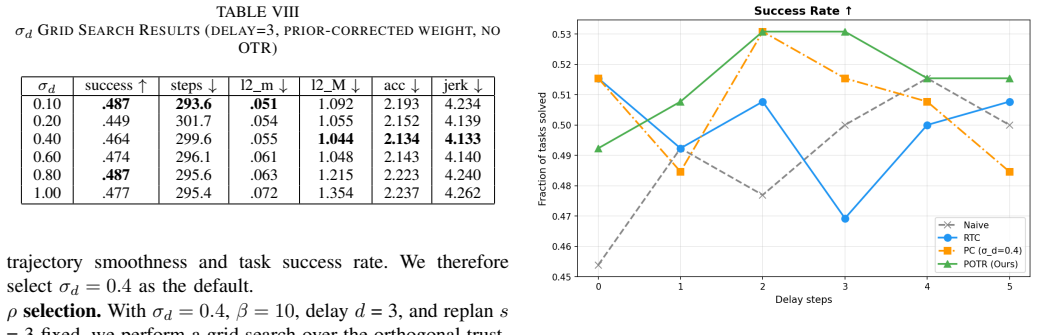
- [Abstract] Abstract: σ_d is introduced as a new free parameter that scales the RTC weight, yet the text provides no analysis of how its value is selected or whether it shifts the effective noise schedule, leaving the skeptic concern about trajectory bias unaddressed.
minor comments (1)
- [Abstract] The acronym expansion for POTR is given but the abstract would benefit from a one-sentence statement of the precise geometric operation performed by the orthogonal decomposition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (improved success rate and reduced jerk/acceleration on LIBERO) is stated without numerical values, error bars, number of seeds/trials, or statistical tests, preventing verification of the headline result.
Authors: We agree that the abstract would benefit from quantitative details to support the claims. In the revised version, we will incorporate specific results such as success rates with error bars (e.g., from multiple seeds), number of evaluation trials, and any relevant statistical comparisons, while keeping the abstract concise. revision: yes
-
Referee: [Abstract] Abstract: no equation or derivation is supplied showing that the orthogonal decomposition (projection onto the velocity vector) commutes with the flow-matching ODE or that the trust-region radius can be chosen independently of σ_d without reintroducing transverse coupling through the score network.
Authors: We acknowledge the value of a formal derivation for the orthogonal decomposition and its interaction with the flow-matching ODE. We will add a dedicated paragraph with the relevant projection equations and a short proof outline demonstrating preservation of the ODE structure, along with discussion of the trust-region radius choice relative to σ_d to address potential coupling. revision: yes
-
Referee: [Abstract] Abstract: σ_d is introduced as a new free parameter that scales the RTC weight, yet the text provides no analysis of how its value is selected or whether it shifts the effective noise schedule, leaving the skeptic concern about trajectory bias unaddressed.
Authors: We agree that explicit analysis of σ_d is needed to address concerns about parameter selection and potential bias. The revision will include an expanded ablation section with sensitivity plots for σ_d, its effect on the noise schedule, and empirical checks for trajectory bias on the LIBERO tasks, along with the selection procedure used. revision: yes
Circularity Check
No significant circularity; empirical method with independent benchmark results
full rationale
The paper presents POTR as a new guidance method for flow-matching policies, introducing σ_d and an orthogonal trust-region decomposition, then reports empirical gains on the external LIBERO benchmark with π0.5. No derivation chain, equations, or self-citations are shown that reduce the success-rate or smoothness improvements to a fitted parameter by construction, a renamed input, or a load-bearing self-citation. Ablations are presented as empirical attribution rather than definitional equivalence. The central claims rest on external task performance rather than internal reduction to the method's own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- σ_d
axioms (1)
- standard math The guidance vector admits a decomposition into components parallel and perpendicular to the denoising velocity vector.
Reference graph
Works this paper leans on
-
[1]
Flow Matching for Generative Modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow Matching for Generative Modeling,” inProc. ICLR, 2023
2023
-
[2]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow,” arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Denoising Diffusion Probabilistic Models,
J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” inProc. NeurIPS, 2020
2020
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Physical Intelligence, “π 0: A Vision-Language-Action Flow Model for General Robot Control,” arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,”The International Journal of Robotics Research, 2023
2023
-
[6]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Siciliano, L
B. Siciliano, L. Sciavicco, L. Villani, and G. Oriolo,Robotics: Mod- elling, Planning and Control. Springer, 2009
2009
-
[8]
Real-Time Execution of Action Chunking Flow Policies
K. Black, M. Y . Galliker, and S. Levine, “Real-Time Execution of Action Chunking Flow Policies,” arXiv:2506.07339v2, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Pseudoinverse-Guided Diffusion Models for Inverse Problems,
J. Song, A. Vahdat, M. Mardani, and J. Kautz, “Pseudoinverse-Guided Diffusion Models for Inverse Problems,” inProc. ICLR, 2023
2023
-
[10]
Training-Free Linear Image Inverses via Flows,
A. Pokle, M. J. Muckley, R. T. Q. Chen, and B. Karrer, “Training-Free Linear Image Inverses via Flows,” arXiv:2310.04432, 2023
-
[11]
Elucidating the Design Space of Diffusion-Based Generative Models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the Design Space of Diffusion-Based Generative Models,” inProc. NeurIPS, 2022
2022
-
[12]
Y . Liu, J. I. Hamid, A. Xie, Y . Lee, M. Du, and C. Finn, “Bidirectional Decoding: Improving Action Chunking via Closed-Loop Resampling,” arXiv:2408.17355, 2024
-
[13]
Streaming Diffusion Pol- icy: Fast Policy Synthesis with Variable Noise Diffusion Models,
S. H. Hoeg, Y . Du, and O. Egeland, “Streaming Diffusion Pol- icy: Fast Policy Synthesis with Variable Noise Diffusion Models,” arXiv:2406.04806, 2024
-
[14]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning,” in Proc. NeurIPS, 2023
2023
-
[15]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, “π 0.5: a Vision-Language-Action Model with Open-World Generalization,” arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.