Expander Sparse Autoencoders: Parameter-Efficient Dictionaries for Mechanistic Interpretability
Pith reviewed 2026-07-03 17:17 UTC · model grok-4.3
The pith
Expander SAEs reduce learned decoder values by 293 times while recovering 84 percent of dense cross-entropy loss on Qwen2.5-3B.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
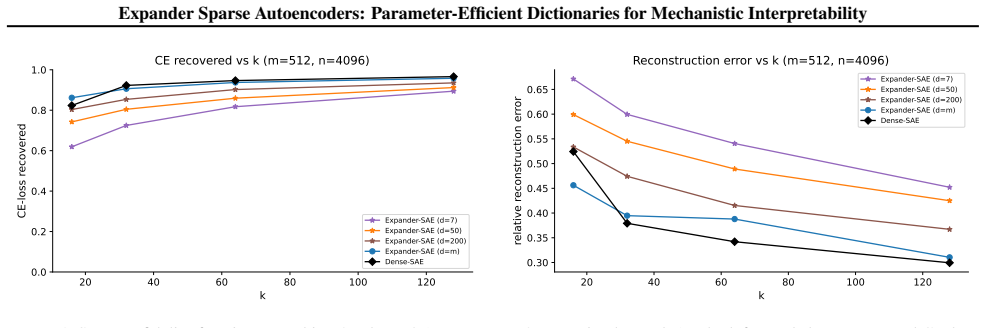
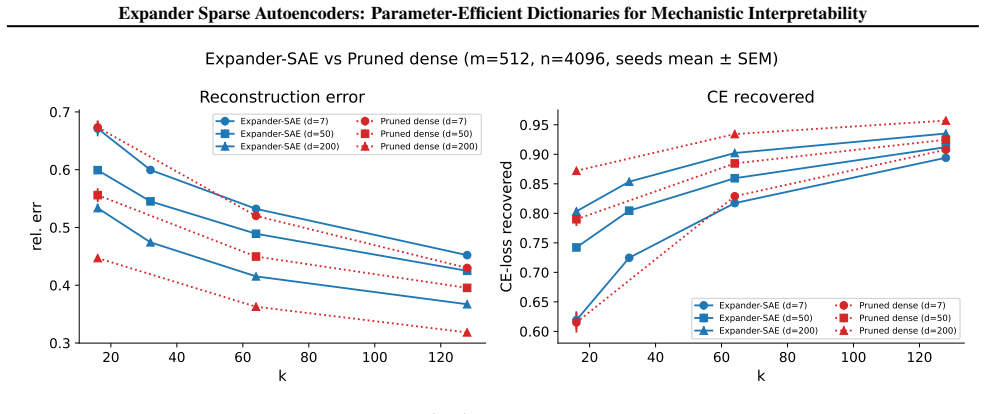
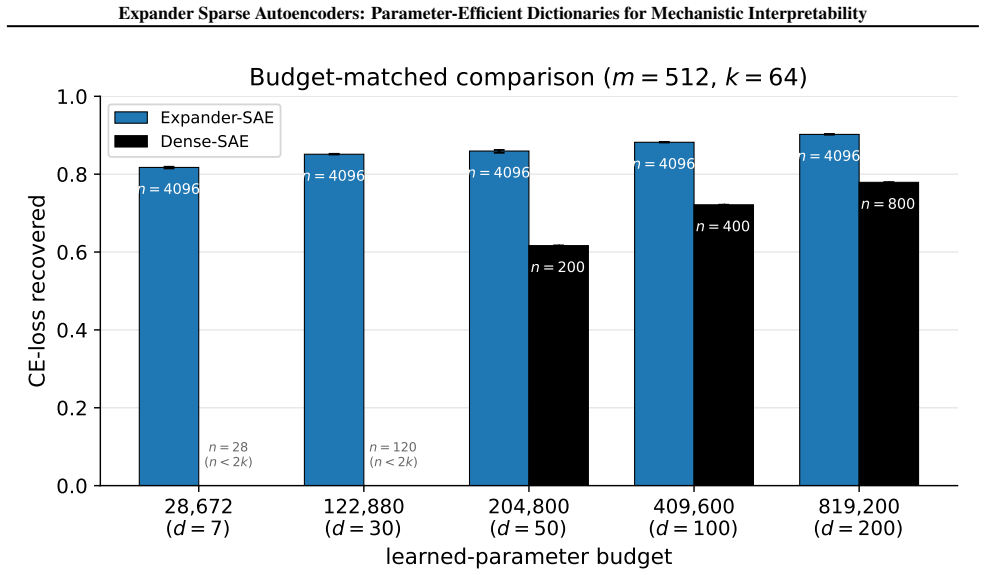
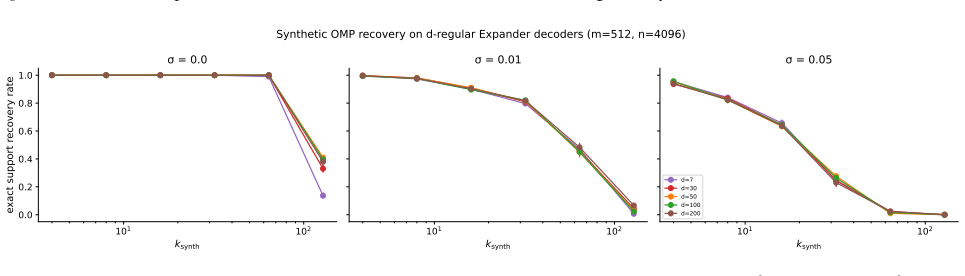
Expander SAEs supported on left-d-regular expander masks learn only dn decoder values instead of mn, and at d=7 on Qwen2.5-3B achieve 293 times fewer values while retaining 84 percent of dense CE-loss recovered. Control experiments attribute the storage-fidelity gain to the sparse diverse support structure induced by the expander mask rather than the sheer reduction in parameters. Expansion and column flatness are shown to be sufficient for identifiability of noiseless k-sparse codes, with complementary conditions guaranteeing exact support recovery by OMP.
What carries the argument
The left-d-regular expander mask that restricts decoder and encoder support, reducing storage to dn values and converting the OMP correlation step into an O(dn) gather-and-reduce operation.
If this is right
- Storage cost for overcomplete dictionaries scales linearly with d instead of m.
- The matching-pursuit correlation step in OMP becomes an O(dn) operation.
- Varying d traces a tunable storage-fidelity curve across model scales.
- Theoretical identifiability holds when the mask satisfies expansion and column flatness.
- Encoder amortisation accounts for part of any remaining gap versus dense decoders at matched parameter count.
Where Pith is reading between the lines
- The same expander construction could be applied to other dictionary-learning objectives that rely on overcomplete bases.
- If expander structure is the key driver, deterministic constructions such as Ramanujan graphs might further improve the frontier.
- The reduction in decoder storage could make feature dictionaries with millions of entries practical on current hardware.
- Connections to compressed-sensing recovery guarantees suggest that expander SAEs may inherit robustness properties from that literature.
Load-bearing premise
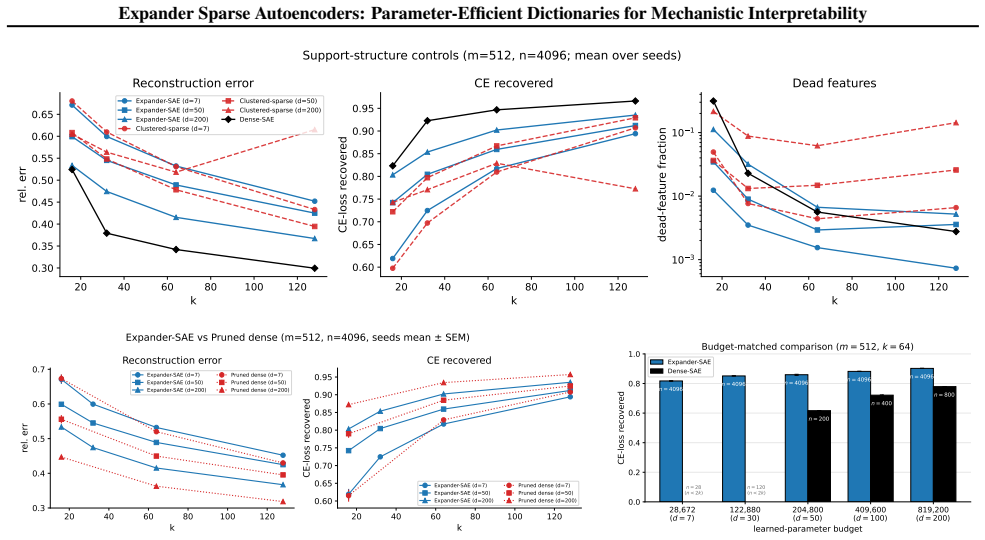
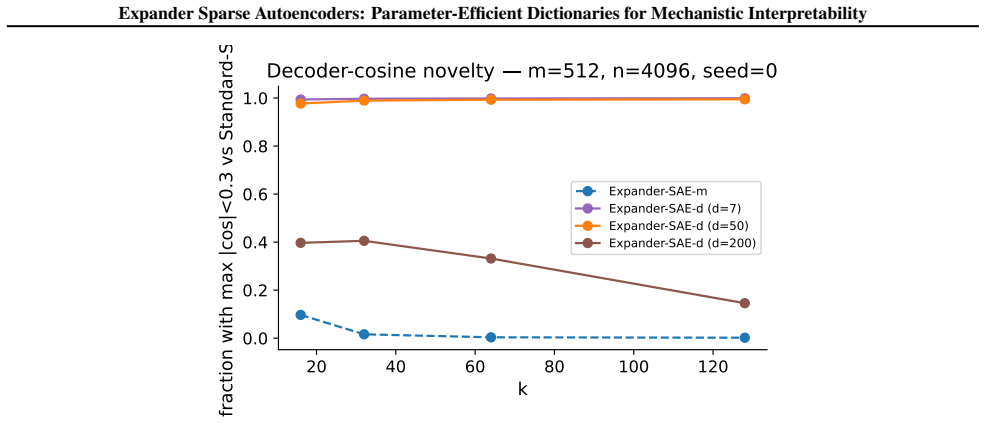
The storage-fidelity improvement is produced by the expander mask's sparse and diverse support structure rather than by the reduction in learned decoder values alone.
What would settle it
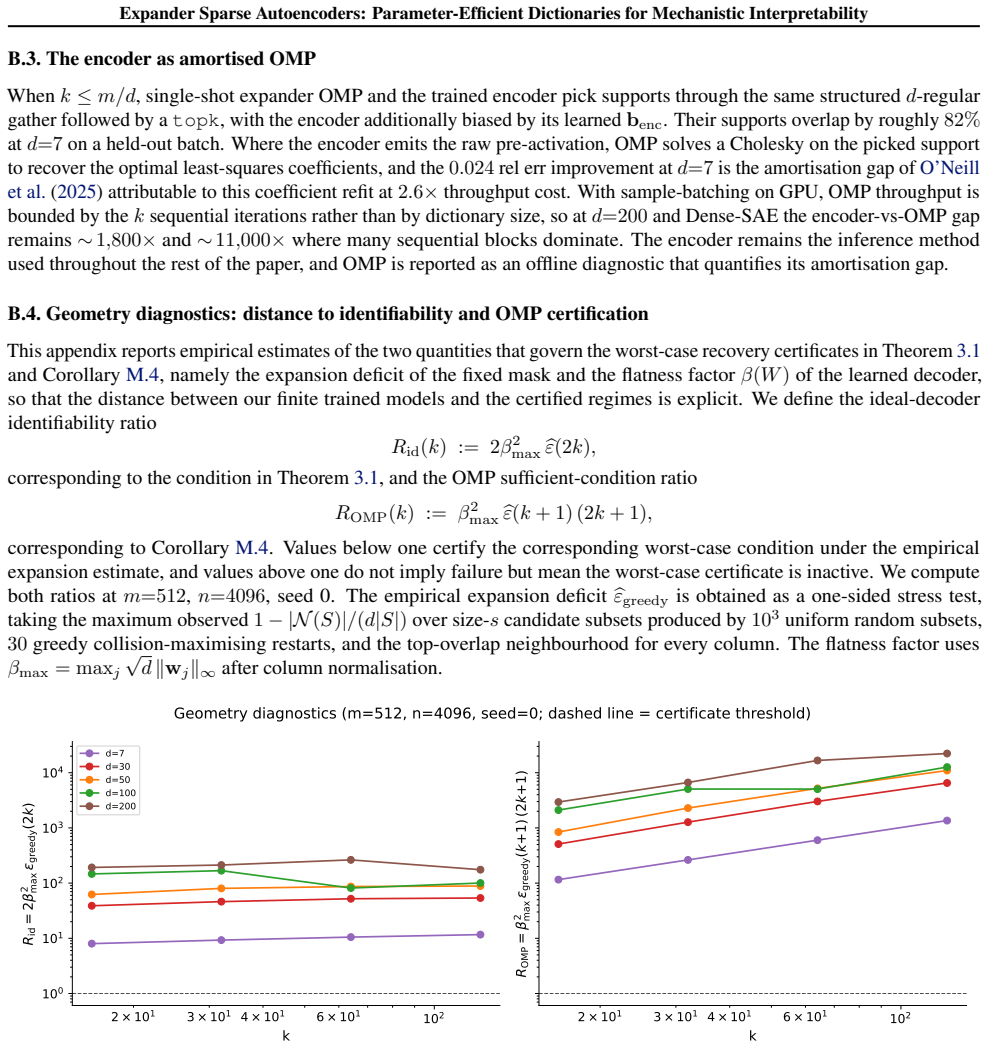
A control run in which a random d-regular mask with the same number of nonzeros per column matches the expander mask's fidelity at identical parameter count would show that expansion is not required.
Figures
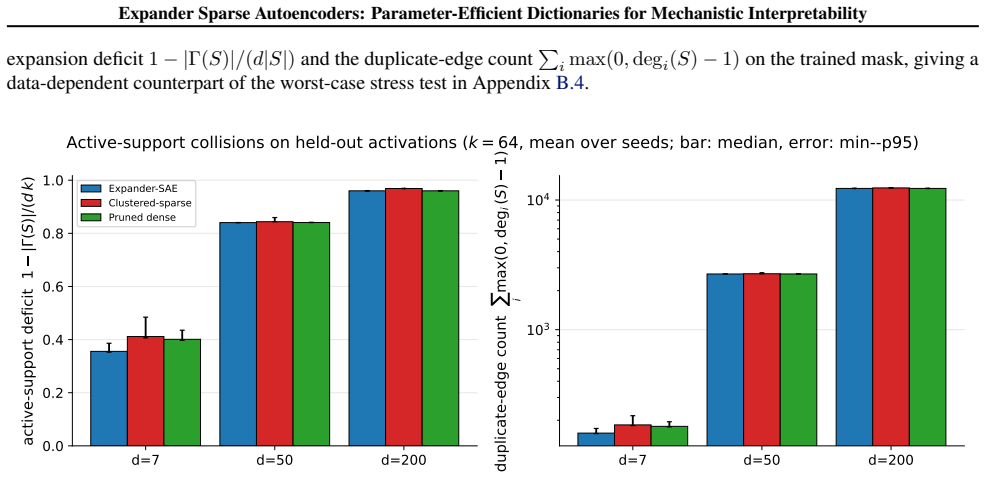
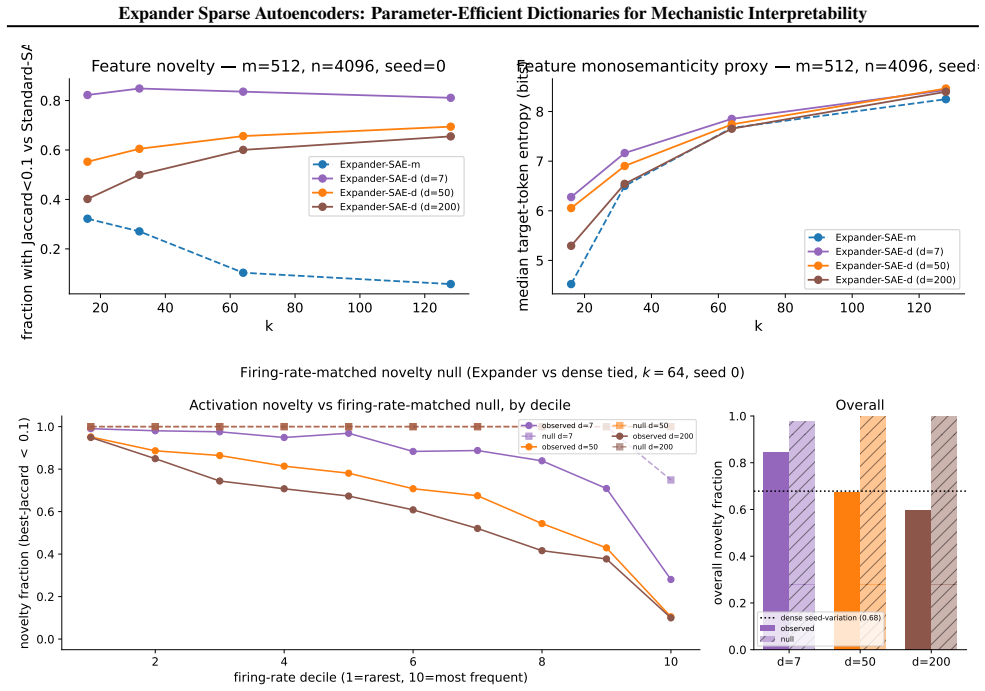
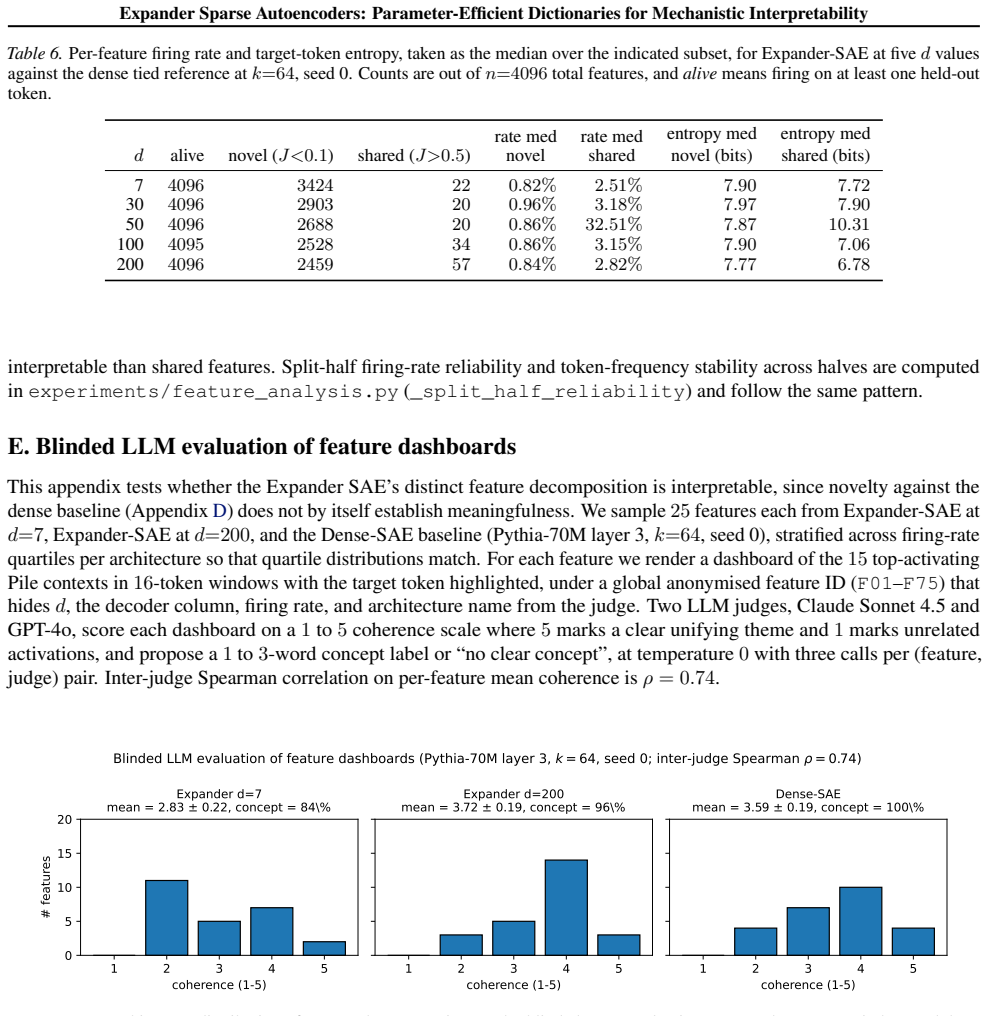
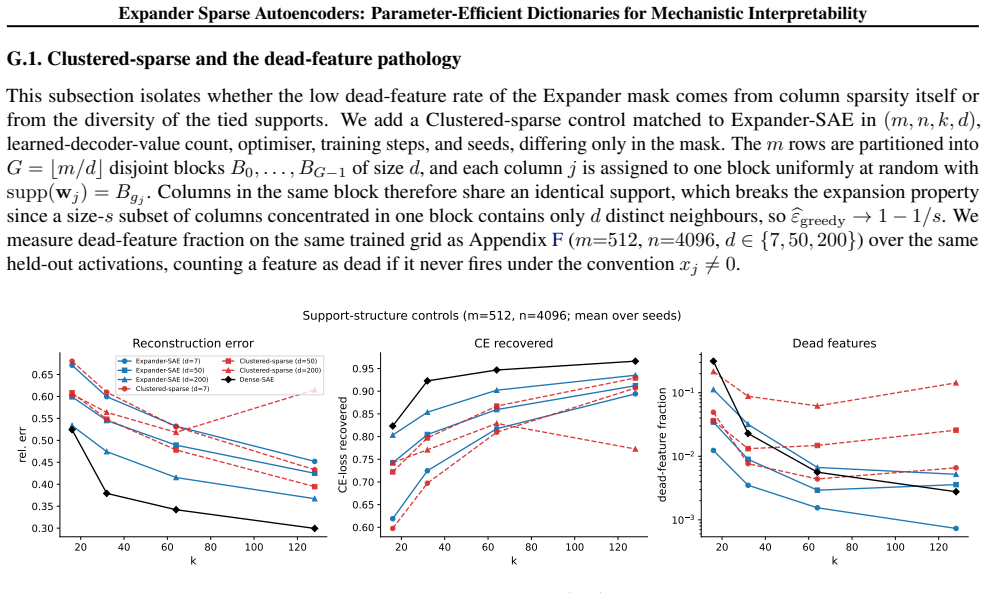
read the original abstract
Sparse autoencoders (SAEs) decompose internal activations of neural networks into sparse linear combinations of learned features by fitting an overcomplete dictionary $\mathbf{W}\in\mathbb{R}^{m\times n}$ with $m<n$, and inferring a sparse code $\mathbf{x}\in\mathbb{R}^n$ from $\mathbf{h}\approx\mathbf{W}\mathbf{x}$. This inference problem closely resembles the canonical setup of compressed sensing, but dense decoders requires $O(mn)$ learned values, which becomes costly at large feature counts. We introduce Expander SAEs: TopK SAEs whose decoder and tied encoder are supported on a left-$d$-regular expander mask with $d\ll m$, learning only $dn$ decoder values while keeping the sparse-coding problem $(m,n,k)$ fixed. The same structure reduces storage and turns the matching-pursuit correlation step $\mathbf{W}^\top \mathbf{r}$ in OMP into an $O(dn)$ gather-and-reduce operation. Our experiments show that across Pythia-70M/160M, Qwen2.5-3B, and Llama-3.2-1B residual-stream activations, varying $d$ traces a consistent storage--fidelity frontier, and that at the most compressed modern-LM setting, Qwen2.5-3B with $d=7$ uses $293\times$ fewer learned decoder values than the full dense decoder while retaining $84$% of dense CE-loss recovered. Control experiments show that the improved storage--fidelity tradeoff is driven by sparse, diverse decoder support structure rather than by fewer learned decoder values, and that when sparse and dense decoders are compared at matched parameter count, part of the remaining gap comes from encoder amortisation. On the theoretical side, we show that expansion and column flatness are sufficient for identifiability of noiseless $k$-sparse codes, and we derive complementary sufficient conditions under which OMP recovers the support exactly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Expander SAEs as TopK SAEs whose decoder (and tied encoder) are supported on a left-d-regular expander mask, reducing learned decoder parameters from O(mn) to dn while fixing the (m,n,k) sparse-coding problem. Experiments across Pythia, Qwen2.5-3B, and Llama models trace a storage-fidelity frontier, with the Qwen2.5-3B d=7 setting claiming 293× fewer decoder values at 84% of dense CE-loss recovery. Control experiments are presented to attribute gains to the expander-induced sparse diverse support rather than parameter count alone. Theory supplies sufficient conditions (expansion + column flatness) for noiseless k-sparse identifiability and exact OMP support recovery.
Significance. If the control experiments convincingly isolate the expander structure, the work offers a practical route to scale SAEs for mechanistic interpretability with substantially lower storage and OMP inference cost. The consistent frontier across four model families and the derivation of identifiability/OMP conditions from standard expander-graph properties are strengths. The explicit parameter reduction and the attempt to separate mask structure from mere sparsity count add value for large-scale dictionary learning.
major comments (2)
- [Control experiments (abstract and Experiments section)] Control experiments (abstract and Experiments section): The central empirical claim that the storage-fidelity improvement is driven by the expander mask's sparse, diverse decoder support (rather than reduction to dn learned values) rests on these controls. The provided description does not specify whether the baselines include matched-optimization random d-regular masks, identical training schedules, or other ablations that would rule out differences in effective capacity or optimization trajectory; without such detail the attribution remains vulnerable to the alternative explanations noted in the stress-test.
- [Theory section] Theoretical results (Theory section): The identifiability and exact OMP recovery theorems assume noiseless k-sparse codes. The empirical claims concern learned representations from noisy neural activations; the manuscript does not provide a quantitative bridge (e.g., robustness bounds or noise-model analysis) showing that the expansion/flatness conditions remain predictive in the learned noisy regime that the storage-fidelity results actually use.
minor comments (2)
- [Abstract] The abstract states that 'part of the remaining gap comes from encoder amortisation' when sparse and dense decoders are compared at matched parameter count; a brief parenthetical or footnote clarifying the amortisation mechanism would improve readability.
- [Methods] Notation for the left-d-regular expander mask construction and the column-flatness condition could be accompanied by a small illustrative diagram or pseudocode in the methods to aid readers outside graph theory.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the paper's significance. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Control experiments (abstract and Experiments section): The central empirical claim that the storage-fidelity improvement is driven by the expander mask's sparse, diverse decoder support (rather than reduction to dn learned values) rests on these controls. The provided description does not specify whether the baselines include matched-optimization random d-regular masks, identical training schedules, or other ablations that would rule out differences in effective capacity or optimization trajectory; without such detail the attribution remains vulnerable to the alternative explanations noted in the stress-test.
Authors: We agree that the control experiments section requires additional detail to fully substantiate the attribution to the expander structure. In the revised manuscript we will expand the description to state that random d-regular mask baselines were trained with identical optimization schedules, learning rates, batch sizes, and initialization procedures as the expander masks. We will also report additional ablations that enforce matched parameter counts using random sparse supports of comparable density but without the expansion property. These clarifications should address concerns about effective capacity and optimization trajectory differences. revision: yes
-
Referee: Theoretical results (Theory section): The identifiability and exact OMP recovery theorems assume noiseless k-sparse codes. The empirical claims concern learned representations from noisy neural activations; the manuscript does not provide a quantitative bridge (e.g., robustness bounds or noise-model analysis) showing that the expansion/flatness conditions remain predictive in the learned noisy regime that the storage-fidelity results actually use.
Authors: The theorems are deliberately stated for the noiseless case to obtain clean sufficient conditions derived from standard expander-graph properties. We acknowledge that the manuscript provides no quantitative robustness bounds or explicit noise-model analysis connecting these conditions to the noisy regime of learned neural activations. In revision we will add a short discussion paragraph in the Theory section noting this gap, explaining that the noiseless results supply intuition for why expander structure aids recovery, and identifying extension to noisy settings as future work. No new quantitative bridge will be derived. revision: partial
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper defines the expander mask via standard left-d-regular expander graph properties drawn from external graph theory, then reports empirical storage-fidelity results on real LM activations together with control experiments that compare against reduced-parameter baselines. Neither the identifiability theorem (expansion + column flatness sufficient for noiseless k-sparse recovery) nor the reported performance numbers (e.g., 293× parameter reduction at 84 % CE recovery) are obtained by fitting a parameter to a subset of the target data and then relabeling that fit as a prediction. No self-citation chain is invoked to justify the core construction or to forbid alternatives; the theoretical conditions are stated as sufficient rather than as a uniqueness result imported from the authors' prior work. The derivation chain therefore remains self-contained against external benchmarks and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- d
axioms (1)
- domain assumption Expansion and column flatness of the left-d-regular expander mask are sufficient for identifiability of noiseless k-sparse codes.
Reference graph
Works this paper leans on
-
[1]
Deeply-sparse signal representations (DS 2P)
Demba Ba. Deeply-sparse signal representations (DS 2P). arXiv:1807.01958,
-
[2]
Automatica49(11), 3222–3233 (2013)
doi: 10.1016/j. acha.2010.07.001. Thomas Blumensath and Mike E. Davies. Gradient pursuits. IEEE Transactions on Signal Processing, 56(6):2370– 2382,
work page doi:10.1016/j 2010
-
[3]
BatchTopK sparse autoencoders.arXiv:2412.06410,
Bart Bussmann, Patrick Leask, and Neel Nanda. BatchTopK sparse autoencoders.arXiv:2412.06410,
-
[4]
Matryoshka sparse autoencoders
Bart Bussmann et al. Matryoshka sparse autoencoders. arXiv:2503.17547,
-
[5]
arXiv preprint arXiv:2506.03093 , year=
Victor Costa, Thomas Fel, Ekdeep Singh Lubana, Ba- hareh Tolooshams, and Demba Ba. From flat to hier- archical: Matching pursuit for sparse representations. arXiv:2506.03093,
-
[6]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
8 Expander Sparse Autoencoders: Parameter-Efficient Dictionaries for Mechanistic Interpretability Hoagy Cunningham et al. Sparse autoencoders find highly interpretable features in language models. arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Donoho and Jared Tanner
David L. Donoho and Jared Tanner. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal process- ing.Philosophical Transactions of the Royal Society A, 367(1906):4273–4293,
1906
-
[8]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao et al. The pile: An 800GB dataset of diverse text for language modeling.arXiv:2101.00027,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Scaling and evaluating sparse autoencoders
Leo Gao et al. Scaling and evaluating sparse autoencoders. arXiv:2406.04093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Aaron Grattafiori et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Superposition is compressed sensing
David Klindt et al. Superposition is compressed sensing. arXiv:2503.01824,
-
[12]
Rodrigo Mendoza-Smith and Jared Tanner. Expander ℓ0- decoding.arXiv:1508.01256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A robust parallel algorithm for combinatorial compressed sensing
Rodrigo Mendoza-Smith and Jared Tanner. Robust expander ℓ0-decoding.arXiv:1704.09012,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Anish Mudide et al. Switch sparse autoencoders. arXiv:2410.08201,
-
[15]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Senthooran Rajamanoharan et al. Gated sparse autoencoders. InNeural Information Processing Systems (NeurIPS), 2024a. Senthooran Rajamanoharan et al. JumpReLU sparse autoen- coders.arXiv:2407.14435, 2024b. Adly Templeton et al. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet.Transformer Circuits Thread,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
An Yang et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Mini-batches are drawn with shuffle=True, drop_last=True , and the loader cycles throughD train untilTsteps are completed
with β1 = 0.9, β2 = 0.999, ϵ= 10 −8, and a single-period cosine learning-rate schedule overT= 5000steps, ηt = 10−5 + 1 2 3·10 −4 −10 −5 1 + cos(πt/T) .(14) Gradients are clipped to global ℓ2 norm 1.0. Mini-batches are drawn with shuffle=True, drop_last=True , and the loader cycles throughD train untilTsteps are completed. Dead-feature resampling.Following...
2023
-
[18]
(4) on the same held-out activations, and we report per-sample relative reconstruction error averaged over activations and seeds
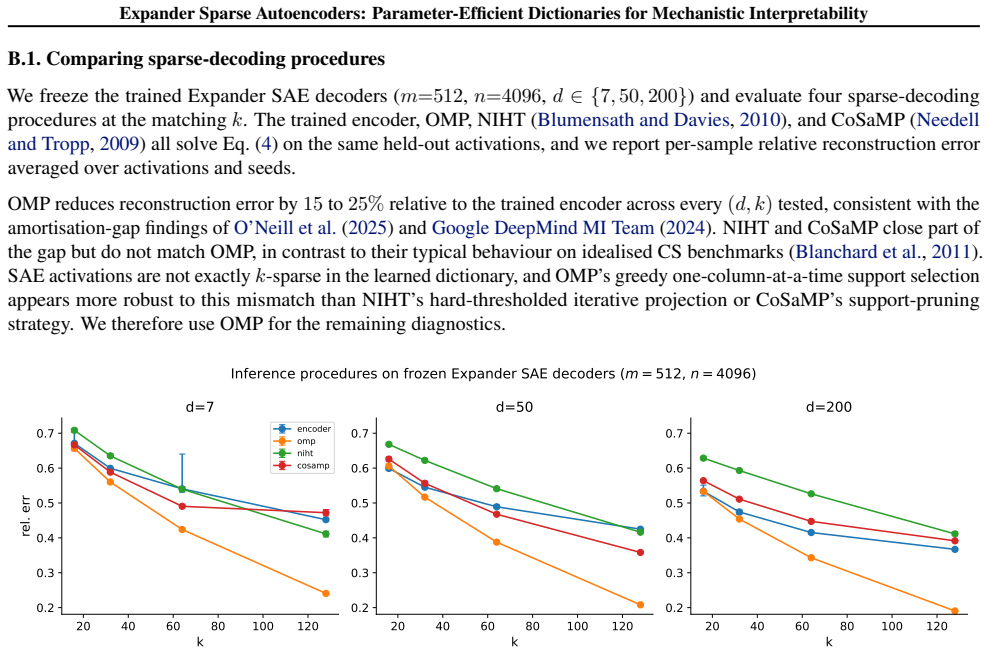
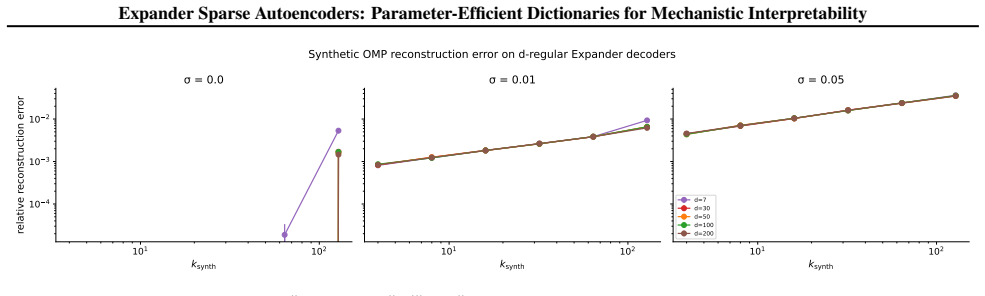
all solve Eq. (4) on the same held-out activations, and we report per-sample relative reconstruction error averaged over activations and seeds. OMP reduces reconstruction error by 15 to 25% relative to the trained encoder across every (d, k) tested, consistent with the amortisation-gap findings of O’Neill et al. (2025) and Google DeepMind MI Team (2024). ...
2025
-
[19]
L controls the number of columns added to the active set per outer iteration, withL=1 recovering iterative OMP and L=64 collapsing to single-shot decoding
Table 5.Block-size L sweep for the Cholesky-refit + Triton-correlation + structured-Gram OMP variant atd=7 (m=512, n=4096, k=64, A10G, bf16, B=1024, seed 0). L controls the number of columns added to the active set per outer iteration, withL=1 recovering iterative OMP and L=64 collapsing to single-shot decoding. The final column compares each row to the s...
2025
-
[20]
A value of 1 means the reconstruction matches the clean model’s CE,0 means it is no better than zero-ablation, and negative values mean it is worse than zero-ablation
CE-loss recovered is computed by replacing the layer-ℓ residual stream of the language model with the SAE reconstruction and measuring next-token cross-entropy on held-out sequences, CE recovered = CEzero −CE recon CEzero −CE clean ,(17) where CEclean is the cross-entropy of the unmodified language model, CEzero replaces the activation by the all-zero vec...
2048
-
[21]
has one of three seeds diverge during training (rel err 1.13, included in the reported mean); without that seed the rel err mean is0.704and CE rec is0.854. Expander-SAE Dense-SAE (fulln) Matched-n ′ Dense-SAE Layer metricd=7d=30d=102n=16,384n ′=240n ′=816 12 rel err0.764 0.703 0.681 0.489 0.608 0.556 CE rec0.828 0.894 0.919 0.983 0.906 0.945 24 rel err0.6...
2009
-
[22]
Therefore sX r=1 brar ≤εd sX r=1 r(ar −a r+1) =εd sX r=1 ar
By summation by parts, sX r=1 brar = sX r=1 Cr(ar −a r+1). Therefore sX r=1 brar ≤εd sX r=1 r(ar −a r+1) =εd sX r=1 ar. M.2. Flatness bounds learned weighted cancellations The previous subsection treats M as a combinatorial object and ignores the values of W. This subsection extracts the two consequences of the flatness factor that the main proof needs, b...
2009
-
[23]
The second corollary moves from existential identifiability to a constructive recovery guarantee. The classical analysis of Tropp (2004) certifies OMP exact recovery whenever the cumulative coherence satisfiesµ1(k;W) +µ 1(k−1;W)<1 , and we show that the prefix collision bound of Lemma M.1 controlsµ 1(s;W)in our setting. Corollary M.4(A sufficient cumulati...
2004
-
[24]
Taking the maximum over j and T gives the cumulative-coherence bound, and the final statement follows from the standard OMP sufficient conditionµ 1(k;W) +µ 1(k−1;W)<1(Tropp, 2004)
SinceP ℓ∈T cjℓ is bounded by this collision count, X ℓ∈T |⟨wj,w ℓ⟩| ≤β 2ε(s+ 1). Taking the maximum over j and T gives the cumulative-coherence bound, and the final statement follows from the standard OMP sufficient conditionµ 1(k;W) +µ 1(k−1;W)<1(Tropp, 2004). The third corollary upgrades identifiability to a quantitative stability statement. Under the a...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.