NoPA: Non-Parametric Online 3D Scene Graph Generation
Pith reviewed 2026-07-02 14:33 UTC · model grok-4.3
The pith
NoPA represents each object as a non-parametric distribution to retain geometric detail in real-time 3D scene graph generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
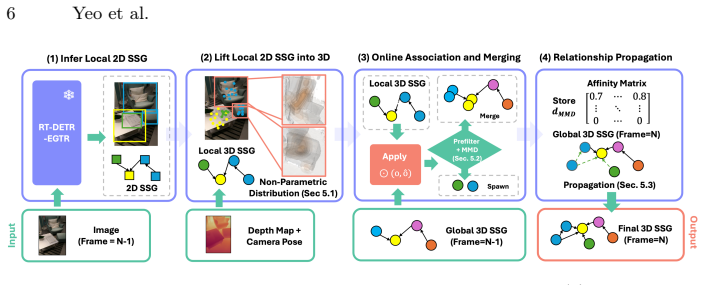
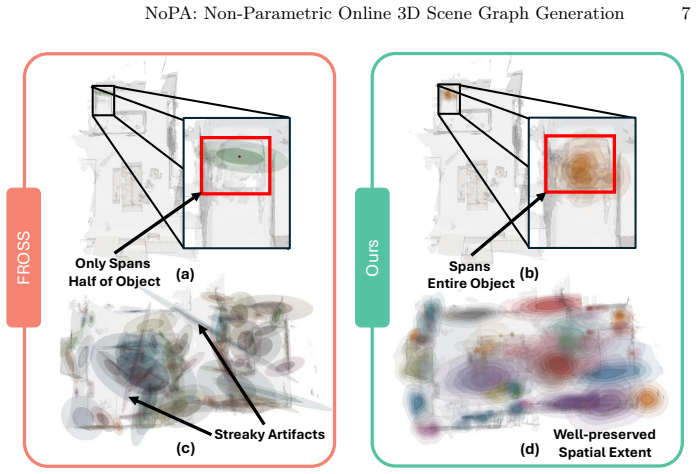
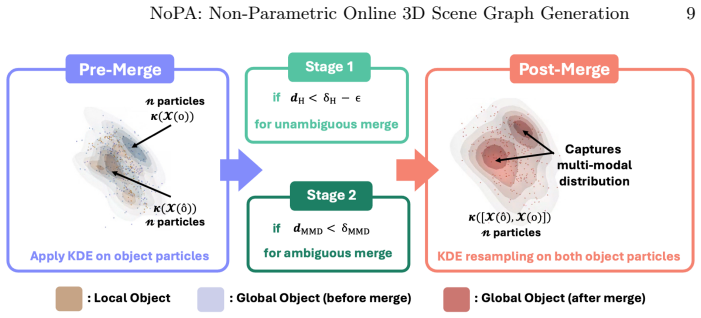
The paper claims that representing each object as a separate non-parametric distribution retains 3D geometric information while preserving real-time inference of the parametric Gaussian formulation. To build upon this, a tailored merging strategy leverages maximum mean discrepancy on kernel density estimates to enable robust merging of object candidates during online exploration while minimizing added computational complexity by maintaining a fixed particle set per object. Furthermore, relationships between objects with high affinity are propagated to rectify the relation loss caused by misclassified objects.
What carries the argument
Non-parametric distribution for each object maintained via a fixed particle set, with merging performed using maximum mean discrepancy on kernel density estimates.
If this is right
- Retains 3D geometric detail compared to single Gaussian approximations.
- Enables robust merging of object candidates in online settings.
- Preserves real-time inference speed.
- Rectifies relation losses through affinity-based propagation.
- Outperforms current methods in 3D scene graph generation tasks.
Where Pith is reading between the lines
- This representation could be applied to other real-time mapping problems where balancing detail and speed is critical.
- The fixed particle approach might integrate with existing particle-based filters in robotics.
- Improved scene graphs could lead to better performance in robotic navigation and interaction tasks.
Load-bearing premise
A fixed particle set per object can retain sufficient geometric detail for accurate merging and relation propagation without increasing computational cost beyond real-time limits.
What would settle it
Running the method on a dataset with complex object geometries and measuring whether merging accuracy drops or inference time exceeds real-time thresholds compared to Gaussian baselines.
Figures

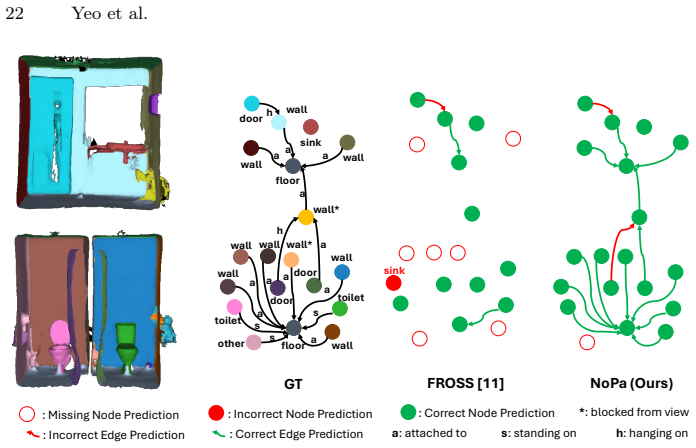

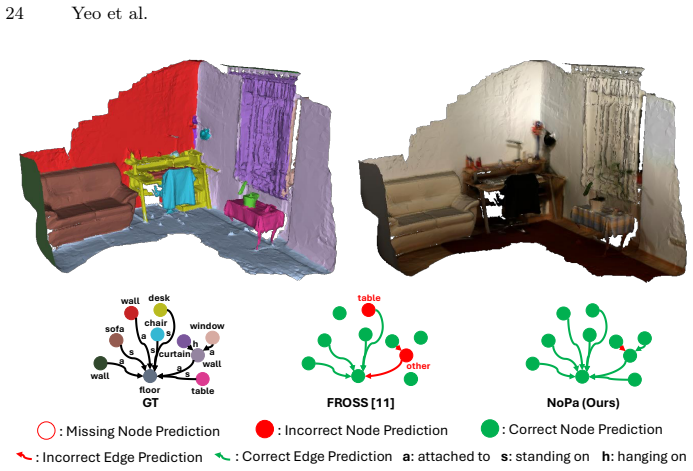

read the original abstract
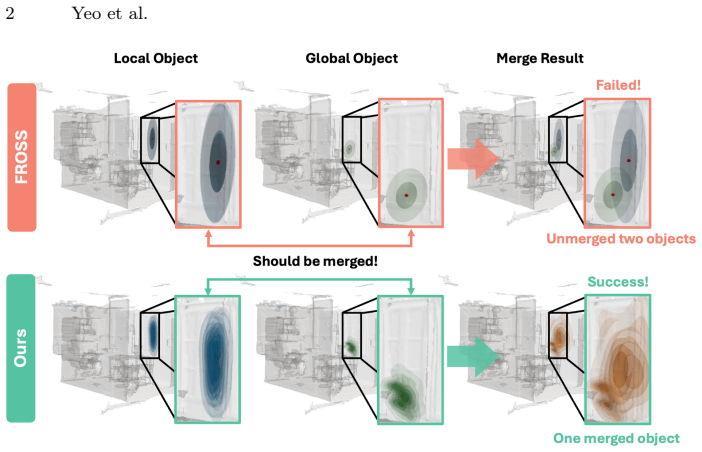
Classic 3D scene graph generation approaches fail to work in real-time due to the heavy computational cost of environment mapping and the need to generate intermediate point-cloud representations. To alleviate this issue, a recent work eschews point clouds in favor of a lightweight Gaussian distribution for each object. This approximation drastically speeds up inference and enables real-time 3D scene graph generation. However, the representation has two key weaknesses. \textbf{1)} Each object is approximated by a single 3D Gaussian, which causes a severe loss of 3D geometric detail. \textbf{2)} The discrepancy between this approximation and the true object geometry exacerbates the inaccurate merging of object candidates during online inference. To address these issues, we propose \textbf{NoPA}, which represents each object as a separate non-parametric distribution. This formulation retains 3D geometric information while preserving real-time inference of the parametric Gaussian formulation. To build upon our novel object representation, we propose a tailored merging strategy to recover coherent object instances. Specifically, we leverage maximum mean discrepancy on kernel density estimates to enable robust merging of object candidates during online exploration while minimizing added computational complexity. The key is to maintain a fixed particle set per object. Furthermore, to rectify the relation loss caused by misclassified objects, NoPA propagates relationships between objects with high affinity. Experiments show that NoPA substantially outperforms current methods without sacrificing real-time inference speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NoPA for online 3D scene graph generation. It replaces single-Gaussian object representations with non-parametric distributions maintained via a fixed particle set per object, introduces a merging strategy based on maximum mean discrepancy computed on kernel density estimates, and adds relationship propagation to correct for misclassified objects. The abstract asserts that this retains geometric detail, enables robust online merging, and yields substantial outperformance over prior methods while preserving real-time inference speed.
Significance. If the performance and runtime claims are substantiated by rigorous experiments, the work would address a key limitation in real-time 3D scene understanding by improving geometric fidelity without incurring the cost of full point-cloud mapping, with relevance to robotics and augmented reality applications.
major comments (2)
- [Abstract] Abstract: the assertion that 'Experiments show that NoPA substantially outperforms current methods without sacrificing real-time inference speed' is unsupported by any quantitative results, baselines, metrics, error bars, or experimental details, so the central performance claim cannot be evaluated.
- [Abstract] Abstract (paragraph on tailored merging strategy): the claim that a fixed particle set simultaneously retains geometric detail, supports robust MMD-on-KDE merging, and preserves real-time speed without new approximation errors or computational blowup is stated without any complexity analysis, particle-count justification, or empirical validation of the assumption.
minor comments (1)
- [Abstract] The method description remains at a high level; concrete details on particle initialization, kernel selection, MMD implementation, and the exact affinity measure used for relationship propagation would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We address each major comment point by point below and propose revisions where the abstract can be strengthened without altering the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments show that NoPA substantially outperforms current methods without sacrificing real-time inference speed' is unsupported by any quantitative results, baselines, metrics, error bars, or experimental details, so the central performance claim cannot be evaluated.
Authors: The referee is correct that the abstract itself contains no numerical results. The full experimental section provides quantitative comparisons against baselines on standard metrics, runtime measurements confirming real-time performance, and supporting details. To make the central claim evaluable from the abstract alone, we will revise the abstract to incorporate key quantitative highlights (e.g., mAP improvements and FPS) drawn directly from the experiments. revision: yes
-
Referee: [Abstract] Abstract (paragraph on tailored merging strategy): the claim that a fixed particle set simultaneously retains geometric detail, supports robust MMD-on-KDE merging, and preserves real-time speed without new approximation errors or computational blowup is stated without any complexity analysis, particle-count justification, or empirical validation of the assumption.
Authors: The abstract summarizes the design choice; the complexity analysis (O(1) per merge due to fixed particle count), justification for the chosen particle number, and empirical validation against full point-cloud and Gaussian baselines appear in the Method and Experiments sections. We agree the abstract would be clearer with a brief reference to these elements and will revise it to include a short statement on the fixed particle count and its complexity implications. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes a methodological contribution for real-time 3D scene graph generation by replacing single-Gaussian object representations with non-parametric particle-based distributions and introducing an MMD-on-KDE merging strategy. No equations, derivations, or first-principles results are present that reduce any claimed prediction or uniqueness to a fitted parameter or self-citation chain defined by the authors' own prior work. The abstract and description explicitly contrast the new approach against an external recent work on Gaussians, and the core claims (retained geometric detail, robust merging, real-time speed) are presented as engineering choices rather than mathematical reductions. This is the common case of an applied CV method whose validity rests on empirical results rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF international conference on computer vision
Armeni, I., He, Z.Y., Gwak, J., Zamir, A.R., Fischer, M., Malik, J., Savarese, S.: 3d scene graph: A structure for unified semantics, 3d space, and camera. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5664–5673 (2019)
2019
-
[2]
Articulated 3D scene graphs for open-world mobile manipulation.arXiv preprint arXiv:2602.16356, 2026
Buechner, M., Roefer, A., Engelbracht, T., Welschehold, T., Bauer, Z., Blum, H., Pollefeys, M., Valada, A.: Articulated 3d scene graphs for open-world mobile ma- nipulation. arXiv preprint arXiv:2602.16356 (2026)
-
[3]
In: Eu- ropean Conference on Computer Vision (2020),https://doi.org/10.1007/978- 3-030-58452-8_241
Çelen,A.,Han,G.,Schindler,K.,Gool,L.V.,Armeni,I.,Obukhov,A.,Wang,X.:I- design: Personalized LLM interior designer. In: Bue, A.D., Canton, C., Pont-Tuset, J., Tommasi, T. (eds.) Computer Vision - ECCV 2024 Workshops - Milan, Italy, September 29-October 4, 2024, Proceedings, Part II. Lecture Notes in Computer Science, vol. 15624, pp. 217–234. Springer (2024...
-
[4]
Chang, Y., Ballotta, L., Carlone, L.: D-lite: Navigation-oriented compression of 3d scene graphs for multi-robot collaboration. IEEE Robotics Autom. Lett.8(11), 7527–7534 (2023).https://doi.org/10.1109/LRA.2023.3320011
-
[5]
In: IEEE International Conference on Computer Vision (ICCV) (2021)
Dhamo, H., Manhardt, F., Navab, N., Tombari, F.: Graph-to-3d: End-to-end gen- eration and manipulation of 3d scenes using scene graphs. In: IEEE International Conference on Computer Vision (ICCV) (2021)
2021
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Feng, M., Hou, H., Zhang, L., Wu, Z., Guo, Y., Mian, A.: 3d spatial multimodal knowledge accumulation for scene graph prediction in point cloud. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9182–9191 (2023)
2023
-
[7]
Fischer, T., Porzi, L., Bulò, S.R., Pollefeys, M., Kontschieder, P.: Multi-level neural scene graphs for dynamic urban environments. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16- 22, 2024. pp. 21125–21135. IEEE (2024).https://doi.org/10.1109/CVPR52733. 2024.01996
-
[8]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Greve, E., Büchner, M., Vödisch, N., Burgard, W., Valada, A.: Collaborative dy- namic 3d scene graphs for automated driving pp. 11118–11124 (2024).https: //doi.org/10.1109/ICRA57147.2024.10610112
-
[9]
In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA)
Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K.M., Sen, B., Agarwal, A., Rivera, C., Paul, W., Ellis, K., Chellappa, R., et al.: Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning. In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 5021–5028. IEEE (2024)
2024
-
[10]
In: MICCAI
Guo, D., Lin, M., Pei, J., Tang, H., Jin, Y., Heng, P.A.: Tri-modal confluence with temporal dynamics for scene graph generation in operating rooms. In: MICCAI. Springer (2024) 16 Yeo et al
2024
-
[11]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2025)
Hou, H.Y., Lee, C.Y., Sonogashira, M., Kawanishi, Y.: FROSS: Faster-than-Real- Time Online 3D Semantic Scene Graph Generation from RGB-D Images. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2025)
2025
- [12]
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Im, J., Nam, J., Park, N., Lee, H., Park, S.: Egtr: Extracting graph from trans- former for scene graph generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 24229–24238 (June 2024)
2024
-
[14]
Kim, U.H., Park, J.M., Song, T.J., Kim, J.H.: 3d-scene-graph: A sparse and seman- ticrepresentationofphysicalenvironmentsforintelligentagents.IEEECybernetics (2019)
2019
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4015–4026 (2023)
2023
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2024)
Koch, S., Vaskevicius, N., Colosi, M., Hermosilla, P., Ropinski, T.: Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2024)
2024
-
[17]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Koch, S., Wald, J., Colosi, M., Vaskevicius, N., Hermosilla, P., Tombari, F., Ropin- ski, T.: Relationfield: Relate anything in radiance fields. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lee, S., Lee, G.H.: Diet-gs: Diffusion prior and event stream-assisted motion de- blurring 3d gaussian splatting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21739–21749 (2025)
2025
-
[19]
arXiv preprint arXiv:2601.23159 (2026)
Lee, S., Lee, G.H.: Segment any events with language. arXiv preprint arXiv:2601.23159 (2026)
-
[20]
arXiv preprint arXiv:2404.02157 (2024)
Lee, S., Zhao, Y., Lee, G.H.: Segment any 3d object with language. arXiv preprint arXiv:2404.02157 (2024)
-
[21]
In: International Conference on Learning Representations (ICLR) (2024)
Lin, C., Mu, Y.: Instructscene: Instruction-driven 3d indoor scene synthesis with semantic graph prior. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Liu, Y., Li, X., Zhang, Y., Qi, L., Li, X., Wang, W., Li, C., Li, X., Yang, M.H.: Controllable 3d outdoor scene generation via scene graphs. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 28052– 28062 (October 2025)
2025
-
[23]
Nyffeler, J., Tombari, F., Barath, D.: Hierarchical 3d scene graphs construction outdoors.In:ProceedingsoftheIEEE/CVFInternationalConferenceonComputer Vision (ICCV). pp. 26817–26826 (October 2025)
2025
-
[24]
Özsoy, E., Czempiel, T., Holm, F., Pellegrini, C., Navab, N.: LABRAD-OR: lightweight memory scene graphs for accurate bimodal reasoning in dynamic op- erating rooms. In: Greenspan, H., Madabhushi, A., Mousavi, P., Salcudean, S.E., Duncan, J., Syeda-Mahmood, T.F., Taylor, R.H. (eds.) Medical Image Comput- ing and Computer Assisted Intervention - MICCAI 202...
-
[25]
In: Wang, L., Dou, Q., Fletcher, P., Spei- del, S., Li, S
Özsoy, E., Örnek, E., Eck, U., Czempiel, T., Tombari, F., Navab, N.: 4d-or: Seman- tic scene graphs for or domain modeling. In: Wang, L., Dou, Q., Fletcher, P., Spei- del, S., Li, S. (eds.) Medical Image Computing and Computer Assisted Intervention – MICCAI 2022 - 25th International Conference, Proceedings. pp. 475–485. Lecture Notes in Computer Science (...
-
[26]
In: 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids)
Seiwald, P., Wu, S.C., Sygulla, F., Berninger, T.F.C., Staufenberg, N.S., Sattler, M.F., Neuburger, N., Rixen, D., Tombari, F.: Lola v1.1 – an upgrade in hardware and software design for dynamic multi-contact locomotion. In: 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids). IEEE (2021). https://doi.org/10.1109/humanoids47582.2021.9555790
-
[27]
IEEE Access10, 11574–11583 (2022).https: //doi.org/10.1109/ACCESS.2022.3145465
Sonogashira, M., Iiyama, M., Kawanishi, Y.: Towards open-set scene graph gen- eration with unknown objects. IEEE Access10, 11574–11583 (2022).https: //doi.org/10.1109/ACCESS.2022.3145465
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wald, J., Dhamo, H., Navab, N., Tombari, F.: Learning 3d semantic scene graphs from 3d indoor reconstructions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3961–3970 (2020)
2020
-
[29]
International Journal of Computer Vision130(3), 630–651 (2022)
Wald, J., Navab, N., Tombari, F.: Learning 3d semantic scene graphs with instance embeddings. International Journal of Computer Vision130(3), 630–651 (2022)
2022
-
[30]
arXiv preprint arXiv:2512.12622 (2025)
Wang, Z., Lee, S., Dai, G., Lee, G.H.: D3d-vlp: Dynamic 3d vision-language- planning model for embodied grounding and navigation. arXiv preprint arXiv:2512.12622 (2025)
-
[31]
arXiv preprint arXiv:2505.11383 (2025)
Wang, Z., Lee, S., Lee, G.H.: Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and-language navigation. arXiv preprint arXiv:2505.11383 (2025)
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Cheng, B., Zhao, L., Xu, D., Tang, Y., Sheng, L.: Vl-sat: Visual-linguistic semantics assisted training for 3d semantic scene graph prediction in point cloud. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21560–21569 (2023)
2023
-
[33]
Robotics: Science and Systems (2024)
Werby, A., Huang, C., Büchner, M., Valada, A., Burgard, W.: Hierarchical open- vocabulary 3d scene graphs for language-grounded robot navigation. Robotics: Science and Systems (2024)
2024
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, S.C., Tateno, K., Navab, N., Tombari, F.: Incremental 3d semantic scene graph prediction from rgb sequences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5064–5074 (2023)
2023
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, S.C., Wald, J., Tateno, K., Navab, N., Tombari, F.: Scenegraphfusion: In- cremental 3d scene graph prediction from rgb-d sequences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7515– 7525 (2021)
2021
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, Z., Lu, K., Zhang, C., Qi, J., Jiang, H., Ma, R., Yin, S., Xu, Y., Xing, M., Xiao, Z., et al.: Mmgdreamer: Mixed-modality graph for geometry-controllable 3d indoor scene generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 9391–9399 (2025)
2025
-
[37]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV)
Yeo, Q.X., Li, Y., Lee, G.H.: Statistical confidence rescoring for robust 3d scene graph generation from multi-view images. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV). pp. 24999–25008 (October 2025)
2025
-
[38]
Yin, H., Wei, H., Xu, X., Guo, W., Zhou, J., Lu, J.: Gc-vln: Instruction as graph constraints for training-free vision-and-language navigation. arXiv preprint arXiv:2509.10454 (2025) 18 Yeo et al
-
[39]
In: The Thirty-eighth Annual Confer- ence on Neural Information Processing Systems (2024),https://openreview.net/ forum?id=HmCmxbCpp2
Yin, H., Xu, X., Wu, Z., Zhou, J., Lu, J.: SG-nav: Online 3d scene graph prompting for LLM-based zero-shot object navigation. In: The Thirty-eighth Annual Confer- ence on Neural Information Processing Systems (2024),https://openreview.net/ forum?id=HmCmxbCpp2
2024
-
[40]
Zhai, G., Örnek, E.P., Chen, D.Z., Liao, R., Di, Y., Navab, N., Tombari, F., Busam, B.: Echoscene: Indoor scene generation via information echo over scene graph dif- fusion. In: Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XXI. p. 167–184. Springer- Verlag, Berlin, Heidelberg (2024).h...
-
[41]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023), https://openreview.net/forum?id=1SF2tiopYJ
Zhai, G., Örnek, E.P., Wu, S.C., Di, Y., Tombari, F., Navab, N., Busam, B.: Commonscenes: Generating commonsense 3d indoor scenes with scene graphs. In: Thirty-seventh Conference on Neural Information Processing Systems (2023), https://openreview.net/forum?id=1SF2tiopYJ
2023
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, C., Yu, J., Song, Y., Cai, W.: Exploiting edge-oriented reasoning for 3d point-based scene graph analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9705–9715 (2021)
2021
-
[43]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Zhang, C., Delitzas, A., Wang, F., Zhang, R., Ji, X., Pollefeys, M., Engelmann, F.: Open-vocabulary functional 3d scene graphs for real-world indoor spaces. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[44]
Zhang, Y., Qian, D., Li, D., Pan, Y., Chen, Y., Liang, Z., Zhang, Z., Liu, Y., Mei, J., Fu, M., Ye, Y., Liang, Z., Shan, Y., Du, D.: Graphad: Interaction scene graph for end-to-end autonomous driving. In: Kwok, J. (ed.) Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25. pp. 2422–2430. International Joint ...
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: Detrs beat yolos on real-time object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16965–16974 (June 2024) NoPA: Non-Parametric Online 3D Scene Graph Generation 19 NoPA: Non-Parametric Online 3D Scene Graph Generation Su...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.