Healthcare LLM Benchmarks Are Only as Good as Their Explicit Assumptions
Pith reviewed 2026-05-22 03:36 UTC · model grok-4.3
The pith
The evaluation-deployment gap in healthcare LLMs stems from implicit assumptions about user behavior that benchmarks alone cannot reveal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
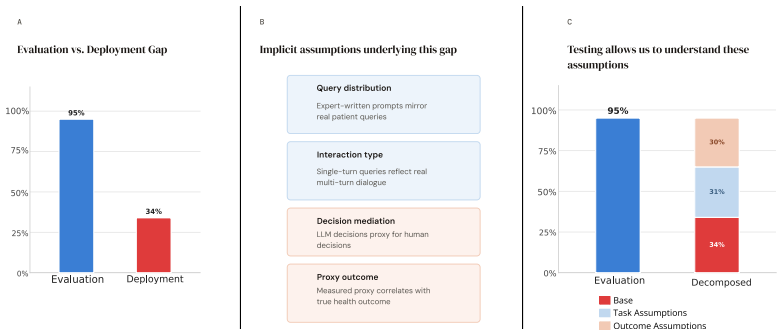
The evaluation-deployment gap arises not because of poorly designed benchmarks, but from implicit assumptions about how users interact with models that cannot be surfaced from benchmarks alone. Assumptions divide into task assumptions, testable from conversation data, and outcome assumptions, which require outcome data and behavioral studies. Retrospective analysis of a healthcare RCT shows the gap naturally separates into task and outcome gaps of roughly equal size. BenchmarkCards document the assumptions and staged evaluation systematically tests them.
What carries the argument
The two-category classification of assumptions into task (testable from conversation data alone) and outcome (requiring outcome data and behavioral studies), which separates the sources of the evaluation-deployment gap and enables BenchmarkCards and staged evaluation.
If this is right
- BenchmarkCards would make both task and outcome assumptions explicit for any new healthcare LLM evaluation.
- Staged evaluation would allow teams to measure and close the task gap first, then address the outcome gap through targeted studies.
- The roughly equal split between task and outcome gaps observed in the RCT reanalysis would recur across other deployments if the framework holds.
- Outcome assumptions would need direct testing with real user behavior data rather than proxy metrics from benchmarks.
Where Pith is reading between the lines
- Teams building healthcare LLMs might need to embed simple user-behavior simulations into early benchmark stages to anticipate outcome gaps.
- The same task-versus-outcome split could be applied to evaluate LLMs in legal or financial settings where human interpretation also drives results.
- Regulatory bodies could require BenchmarkCards as part of safety submissions to ensure outcome assumptions are stated before approval.
- Future work could test whether closing the outcome gap requires changes to model interfaces rather than to the model itself.
Load-bearing premise
That outcome assumptions depending on human behavior can be systematically isolated and tested through staged evaluation and behavioral studies separate from benchmark data.
What would settle it
A reanalysis of several additional healthcare RCTs in which the outcome gap either cannot be isolated or accounts for far less than half the total performance drop would undermine the separation claim.
Figures
read the original abstract
Benchmarks are necessary for healthcare evaluation, but are not sufficient for predicting deployment performance. Our position is that the evaluation--deployment gap arises not because of poorly designed benchmarks, but from implicit assumptions about how users interact with models that cannot be surfaced from benchmarks alone. To make this precise, we propose a classification of assumptions into two categories: task, which can be tested from conversation data alone, and outcome, which requires outcome data and behavioral studies for testing. Critically, outcome assumptions depend on human behavior, something that even well-designed benchmarks cannot directly observe. To demonstrate the operationality of this framework, we retrospectively analyze a healthcare RCT as a case study and find that the gap naturally separates into task and outcome gaps of roughly equal size. To address this, we make two contributions: first, we propose BenchmarkCards, an artifact that documents assumptions, and second, we propose staged evaluation, a procedure that systematically tests assumptions and evaluates performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the evaluation-deployment gap for healthcare LLMs arises from implicit assumptions about user-model interactions that benchmarks alone cannot surface, rather than from inadequate benchmark design. It distinguishes task assumptions (testable via conversation data) from outcome assumptions (requiring outcome data and behavioral studies due to dependence on human behavior). A retrospective reanalysis of a healthcare RCT is used to show that this gap separates into task and outcome components of roughly equal magnitude. The authors propose BenchmarkCards as an artifact to document assumptions explicitly and a staged evaluation procedure to test them systematically before deployment.
Significance. If the framework and case-study separation hold, the work could encourage more assumption-transparent benchmarking practices in healthcare AI, helping practitioners anticipate real-world performance shortfalls that current benchmarks miss. The grounding in external RCT data rather than self-referential fitting is a positive feature, as is the attempt to operationalize the distinction between task and outcome gaps. However, the proposals for BenchmarkCards and staged evaluation receive only conceptual treatment, so the primary significance at present is in reframing the problem rather than in delivering immediately usable tools.
major comments (2)
- [RCT case study / retrospective analysis] The central demonstration that the evaluation-deployment gap 'naturally separates into task and outcome gaps of roughly equal size' rests on the retrospective RCT case study. The manuscript does not supply explicit quantitative definitions or measurable quantities for partitioning the data: for example, it is unclear how task-gap size would be computed from conversation logs (e.g., intent-extraction accuracy) versus outcome-gap size (e.g., downstream clinical metric differences after human mediation). Absent such definitions, alternative attributions of the same observations could alter or eliminate the equal-magnitude finding, weakening the evidence that outcome assumptions require separate behavioral testing.
- [Contributions / BenchmarkCards and staged evaluation] The descriptions of BenchmarkCards and the staged evaluation procedure remain high-level and lack concrete templates, worked examples, or pilot results. Because these artifacts are presented as the practical response to the identified gaps, the absence of even minimal operational detail makes it difficult to evaluate whether they can be implemented without introducing new untested assumptions.
minor comments (2)
- [Introduction] Clarify early in the introduction whether 'task assumptions' and 'outcome assumptions' are intended as exhaustive categories or whether hybrid cases are acknowledged.
- [Case study] Add a short table or figure summarizing the RCT reanalysis metrics (e.g., before/after gap sizes) to make the equal-magnitude claim easier to inspect.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. The feedback identifies opportunities to strengthen the quantitative grounding of the RCT case study and to add operational detail to the proposed artifacts. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [RCT case study / retrospective analysis] The central demonstration that the evaluation-deployment gap 'naturally separates into task and outcome gaps of roughly equal size' rests on the retrospective RCT case study. The manuscript does not supply explicit quantitative definitions or measurable quantities for partitioning the data: for example, it is unclear how task-gap size would be computed from conversation logs (e.g., intent-extraction accuracy) versus outcome-gap size (e.g., downstream clinical metric differences after human mediation). Absent such definitions, alternative attributions of the same observations could alter or eliminate the equal-magnitude finding, weakening the evidence that outcome assumptions require separate behavioral testing.
Authors: We agree that the current presentation would be strengthened by explicit quantitative definitions. In the revision we will define the task gap as the discrepancy between benchmark-predicted performance and observed metrics from RCT conversation logs (e.g., intent recognition accuracy or action prediction F1). The outcome gap will be defined as the residual difference in downstream clinical metrics after subtracting the task-level discrepancy, isolating effects attributable to unmodeled human behavior. We will also include a brief discussion of how alternative partitionings were considered and why the data support the reported separation. These additions will make the equal-magnitude claim more testable and address concerns about alternative attributions. revision: yes
-
Referee: [Contributions / BenchmarkCards and staged evaluation] The descriptions of BenchmarkCards and the staged evaluation procedure remain high-level and lack concrete templates, worked examples, or pilot results. Because these artifacts are presented as the practical response to the identified gaps, the absence of even minimal operational detail makes it difficult to evaluate whether they can be implemented without introducing new untested assumptions.
Authors: We acknowledge that the proposals are currently conceptual. In the revised manuscript we will supply a concrete BenchmarkCards template with fields for task assumptions, outcome assumptions, data sources for testing each, and an example populated using the RCT case. For staged evaluation we will add a worked example that walks through sequential testing of assumptions using conversation logs followed by outcome data. These additions will illustrate implementation steps while noting any assumptions that remain. Full empirical pilots lie beyond the scope of this position paper but can be pursued in follow-up work. revision: yes
Circularity Check
Framework grounded in external RCT data with no self-referential reductions or fitted predictions
full rationale
The paper's central claim—that the evaluation-deployment gap separates into task and outcome components of roughly equal size—is demonstrated via retrospective analysis of an independent healthcare RCT case study rather than any internal fitting, self-defined parameters, or load-bearing self-citations. No equations or derivations reduce the classification of assumptions or the proposed BenchmarkCards/staged evaluation procedure to inputs defined by the authors' prior work. The framework draws on external data for its empirical demonstration, making the derivation self-contained against external benchmarks and yielding only minor (non-load-bearing) circularity risk at most.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Assumptions underlying benchmarks can be partitioned into task assumptions observable from conversation data and outcome assumptions requiring behavioral studies
Reference graph
Works this paper leans on
-
[1]
Ahmed Alaa, Thomas Hartvigsen, Niloufar Golchini, Shiladitya Dutta, Frances Dean, Inioluwa Deb- orah Raji, and Travis Zack. Medical large language model benchmarks should prioritize construct validity.arXiv preprint arXiv:2503.10694,
-
[2]
Alexandra Chouldechova, Chad Atalla, Solon Barocas, A Feder Cooper, Emily Corvi, P Alex Dow, Jean Garcia-Gathright, Nicholas Pangakis, Stefanie Reed, Emily Sheng, et al. A shared standard for valid measurement of generative ai systems’ capabilities, risks, and impacts.arXiv preprint arXiv:2412.01934,
-
[3]
Fatemeh Dehghani, Roya Dehghani, Yazdan Naderzadeh Ardebili, and Shahryar Rahnamayan. Large language models in legal systems: A survey.Humanities and Social Sciences Communications, 12 (1):1977,
work page 1977
-
[4]
Evalcards: A framework for standardized evaluation reporting.arXiv preprint arXiv:2511.21695,
Ruchira Dhar, Danae Sanchez Villegas, Antonia Karamolegkou, Alice Schiavone, Yifei Yuan, Xinyi Chen, Jiaang Li, Stella Frank, Laura De Grazia, Monorama Swain, et al. Evalcards: A framework for standardized evaluation reporting.arXiv preprint arXiv:2511.21695,
-
[5]
Evaluation gaps in machine learning practice
Ben Hutchinson, Negar Rostamzadeh, Christina Greer, Katherine Heller, and Vinodkumar Prab- hakaran. Evaluation gaps in machine learning practice. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 1859–1876,
work page 2022
-
[6]
Abigail Z Jacobs and Hanna Wallach. Measurement and fairness. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 375–385,
work page 2021
-
[7]
Charlotte Li, Nick Hagar, Sachita Nishal, Jeremy Gilbert, and Nick Diakopoulos. Towards eco- logically valid llm benchmarks: Understanding and designing domain-centered evaluations for journalism practitioners.arXiv preprint arXiv:2511.05501, 2025a. Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. Large language models in finance: A survey. InProceeding...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Yubo Li, Xiaobin Shen, Xinyu Yao, Xueying Ding, Yidi Miao, Ramayya Krishnan, and Rema Padman. Beyond single-turn: A survey on multi-turn interactions with large language models. arXiv preprint arXiv:2504.04717, 2025b. Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, and Ludwig Schmidt. Are we learning yet? a meta review of evaluation failures across machi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Categorizing Variants of Goodhart's Law
David Manheim and Scott Garrabrant. Categorizing variants of goodhart’s law.arXiv preprint arXiv:1803.04585,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ai and the everything in the whole wide world benchmark.arXiv preprint arXiv:2111.15366,
11 Inioluwa Deborah Raji, Emily M Bender, Amandalynne Paullada, Emily Denton, and Alex Hanna. Ai and the everything in the whole wide world benchmark.arXiv preprint arXiv:2111.15366,
-
[11]
Hanna Wallach, Meera Desai, Nicholas Pangakis, A Feder Cooper, Angelina Wang, Solon Barocas, Alexandra Chouldechova, Chad Atalla, Su Lin Blodgett, Emily Corvi, et al. Evaluating generative ai systems is a social science measurement challenge.arXiv preprint arXiv:2411.10939,
-
[12]
Xiang Zheng, Han Li, Wenjie Luo, Weiqi Zhai, Yiyuan Li, Chuanmiao Yan, Tianyi Tang, Yubo Ma, Kexin Yang, Dayiheng Liu, et al. Clinconsensus: A consensus-based benchmark for evaluating chinese medical llms across difficulty levels.arXiv preprint arXiv:2603.02097,
-
[13]
12 Table 3: BenchmarkCard (left, filled once by benchmark designers) and practitioner deployment assessment (right, filled per deployment context) for Hager et al. [2024], where the benchmark is licensing exams and deployment is clinicians from MIMIC IV [Johnson et al., 2023]. Question Assumption Answer Holds at deployment? What is the intended use case? ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.