MotionVLA: Injecting Geometric Motion into Vision-Language-Action Model
Pith reviewed 2026-06-27 19:23 UTC · model grok-4.3
The pith
Vision-language-action models improve robot control by remembering motion trajectories instead of raw past frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
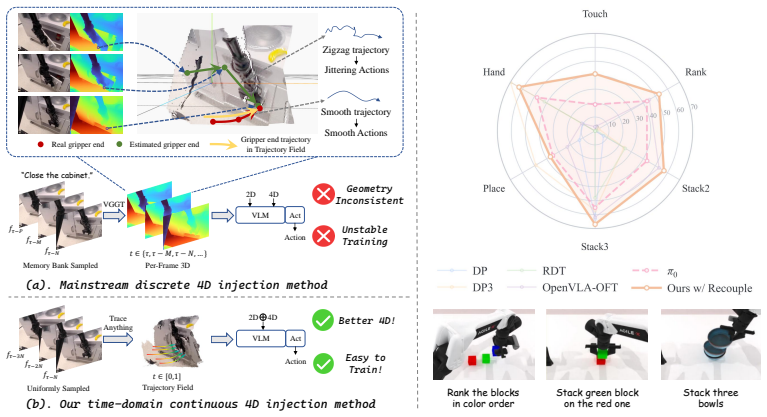
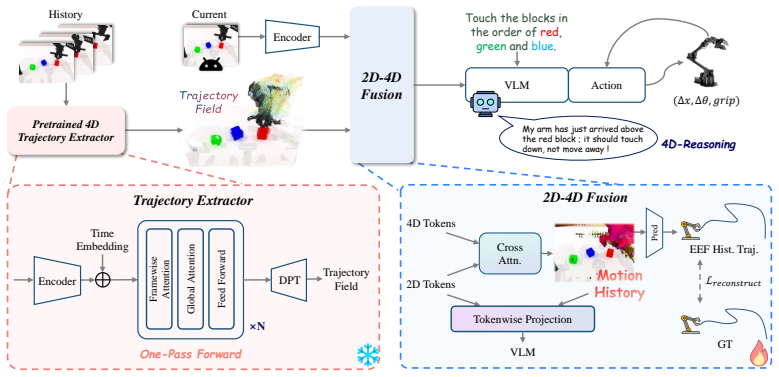
MotionVLA converts a short past-only video window into compact, time-continuous trajectory-field tokens that represent recent observations as physically coherent motion evidence rather than independent frames. Current visual tokens query this history to retrieve task-relevant motion information, which is recoupled into the VLA stream under trajectory-grounded supervision. This produces better long-horizon manipulation with smoother and more direct action sequences than simply supplying additional 4D context.
What carries the argument
The motion-history interface that converts recent video observations into trajectory-field tokens which visual tokens can query for motion-consistent control signals.
If this is right
- Long-horizon tasks become more reliable because motion evidence stays consistent across steps.
- Action generation avoids fragmentation by retrieving motion links directly from the token stream.
- Real-robot rollouts exhibit smoother paths without separate post-processing for continuity.
- VLA memory design shifts from accumulating raw 4D data to exposing queryable motion evidence.
Where Pith is reading between the lines
- The same token conversion could be tested on non-manipulation sequences where temporal coherence matters, such as navigation.
- If trajectory tokens scale, other memory-heavy models might replace frame buffers with motion-derived representations.
- Extending the window length while keeping tokens compact might reveal a practical limit on how much past motion can be compressed without loss.
Load-bearing premise
Short video windows can be turned into trajectory-field tokens that remain physically coherent and free of geometric drift when the model queries them.
What would settle it
A controlled test showing that replacing standard history frames with these trajectory-field tokens produces no gain or increases drift and instability on the same long-horizon manipulation benchmarks.
Figures

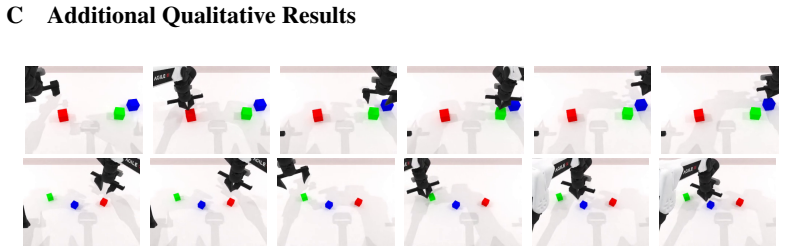

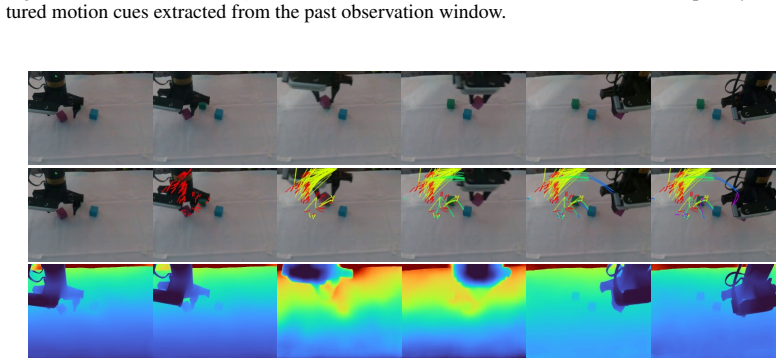

read the original abstract
Vision-language-action (VLA) models increasingly condition robot policies on history, depth, or 4D features to resolve ambiguity in long-horizon manipulation. However, more spatiotemporal evidence is not necessarily better: when the injected evidence is not motion-consistent, it can introduce geometric drift, fragmented temporal cues, and unstable action generation. This raises a simple question: should a VLA remember past frames, or remember the motion that connects them? We introduce MotionVLA, a motion-history interface that converts a short past-only video window into compact, time-continuous trajectory-field tokens. Instead of treating history as a sparse set of ndependently lifted frames, MotionVLA represents recent observations as physically coherent motion evidence. Current visual tokens query this history to retrieve task-relevant motion information, which is then recoupled into the VLA stream under trajectory-grounded supervision. Experiments across simulation benchmarks and preliminary real-robot rollouts show that MotionVLA improves long-horizon manipulation while producing smoother and more direct executions. These results suggest that effective VLA memory is not just about providing more 4D context, but about exposing motion-consistent evidence that is usable for control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MotionVLA, a motion-history interface for vision-language-action (VLA) models. It converts a short past-only video window into compact, time-continuous trajectory-field tokens that represent physically coherent motion evidence. Current visual tokens query this history to retrieve task-relevant motion information, which is recoupled into the VLA stream under trajectory-grounded supervision. Experiments across simulation benchmarks and preliminary real-robot rollouts demonstrate improvements in long-horizon manipulation along with smoother and more direct executions, suggesting that effective VLA memory requires motion-consistent evidence rather than simply more 4D context.
Significance. If the empirical results hold under detailed scrutiny, the work provides a concrete demonstration that the form of injected history matters for VLA stability and performance. By showing measurable gains from trajectory-field tokens over standard history conditioning, it offers a falsifiable test of the premise that motion-consistent evidence reduces geometric drift and fragmented cues, which could inform future designs of memory mechanisms in robot policies.
minor comments (2)
- Abstract: 'ndependently' appears to be a typographical error and should read 'independently'.
- The abstract states that experiments show improvements but does not specify the exact metrics, baselines, or statistical details used to quantify 'smoother and more direct executions'; adding these would strengthen the presentation even if the full methods section contains them.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and the recommendation of minor revision. The report correctly identifies the central claim that motion-consistent trajectory-field tokens provide more usable history for VLA policies than additional raw spatiotemporal context. No major comments were listed in the report, so we have no point-by-point rebuttals to provide at this stage.
Circularity Check
No significant circularity
full rationale
The paper introduces MotionVLA as an empirical architecture that converts short video windows into trajectory-field tokens and reports measurable gains on simulation benchmarks plus real-robot rollouts. No derivation chain, equations, or first-principles claims are present in the provided text that reduce to fitted inputs, self-definitions, or self-citation load-bearing premises. The central suggestion—that motion-consistent evidence improves control—is framed as a testable empirical outcome rather than a tautological restatement of inputs. This matches the default expectation of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Mem- oryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Zhang, Y
J. Zhang, Y . Chen, Y . Xu, Z. Huang, Y . Zhou, Y .-J. Yuan, X. Cai, G. Huang, X. Quan, H. Xu, et al. 4d-vla: Spatiotemporal vision-language-action pretraining with cross-scene calibration. Advances in Neural Information Processing Systems, 38:33914–33937, 2026
2026
- [3]
-
[4]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A visionlanguage-action flow model for general robot control, 2024a.URL https://arxiv.org/abs/2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[12]
Zheng, Y
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum ´e III, A. Kolobov, F. Huang, and J. Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representations, volume 2025, pages 54277– 54296, 2025
2025
-
[13]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
- [16]
-
[17]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [19]
-
[20]
D. Li, Y . Zhang, M. Cao, D. Liu, W. Xie, T. Hui, L. Lin, Z. Xie, and Y . Li. Towards long- horizon vision-language-action system: Reasoning, acting and memory. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6839–6848, 2025
2025
-
[21]
G. Wu, T. Yi, J. Fang, L. Xie, X. Zhang, W. Wei, W. Liu, Q. Tian, and X. Wang. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20310–20320, 2024
2024
- [22]
-
[23]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023
2023
-
[25]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai. Bevformer: learning bird’s- eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020–2036, 2024
2020
-
[26]
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, et al. Planning- oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[27]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[28]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[29]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He. Vq-vla: Improving vision-language- action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11089–11099, 2025. 10
2025
-
[31]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge. Advances in Neural Information Processing Systems, 38:24195–24228, 2026
2026
-
[32]
Zhang, G
S. Zhang, G. Wu, Z. Xie, X. Wang, B. Feng, and W. Liu. Dynamic 2d gaussians: Geometrically accurate radiance fields for dynamic objects. InProceedings of the 33rd ACM International Conference on Multimedia, pages 8144–8153, 2025
2025
-
[33]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[34]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
C. Li, J. Wen, Y . Peng, Y . Peng, and Y . Zhu. Pointvla: Injecting the 3d world into vision- language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026
2026
-
[37]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[38]
Cheng, H
A.-C. Cheng, H. Yin, Y . Fu, Q. Guo, R. Yang, J. Kautz, X. Wang, and S. Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models.Advances in Neural Information Processing Systems, 37:135062–135093, 2024
2024
-
[39]
Z. Fan, J. Zhang, R. Li, J. Zhang, R. Chen, H. Hu, K. Wang, H. Qu, S. Zhou, D. Wang, et al. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction.arXiv preprint arXiv:2505.20279, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
S. Zhou, A. Vilesov, X. He, Z. Wan, S. Zhang, A. Nagachandra, D. Chang, D. Chen, X. E. Wang, and A. Kadambi. Vlm4d: Towards spatiotemporal awareness in vision language models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8600–8612, 2025
2025
-
[41]
H. Zhou and G. H. Lee. Uni4d-llm: A unified spatiotemporal-aware vlm for 4d understanding and generation.arXiv preprint arXiv:2509.23828, 2025
-
[42]
W. Li, R. Zhou, J. Zhou, Y . Song, J. Herter, M. Qin, G. Huang, and H. Pfister. 4d langsplat: 4d language gaussian splatting via multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22001–22011, 2025
2025
-
[43]
S. Wang, Y . Liu, T. Wang, Y . Li, and X. Zhang. Exploring object-centric temporal modeling for efficient multi-view 3d object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 3621–3631, 2023
2023
- [44]
- [45]
-
[46]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. 11
2025
- [47]
-
[48]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
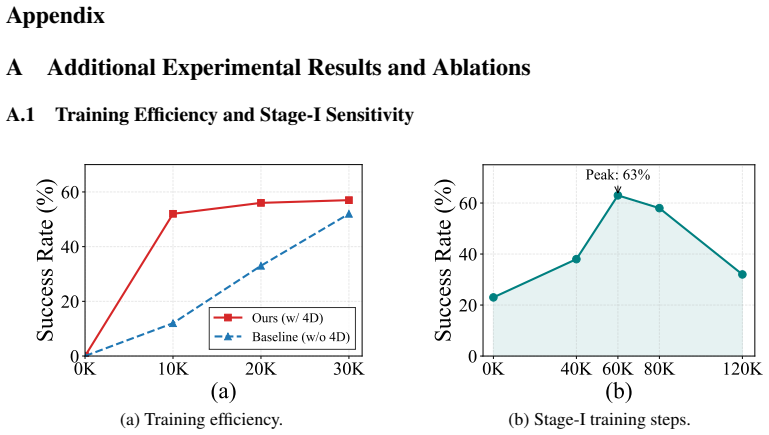
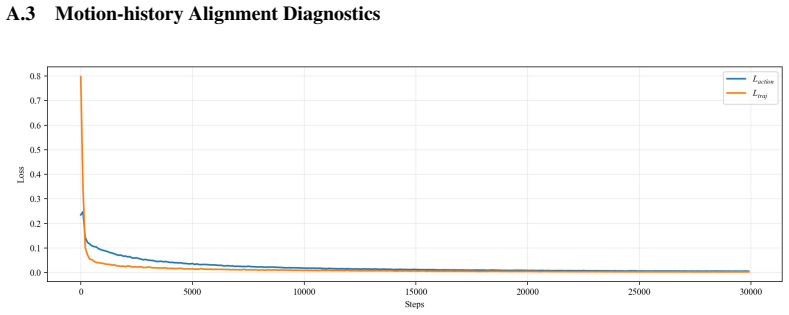
J. Bjorck, F. Casta˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 12 Appendix A Additional Experimental Results and Ablations A.1 Training Efficiency and Stage-I Sensitivity /uni00000013/uni0000002e/uni00000014/...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.