The Illusion of Reasoning: Exposing Evasive Data Contamination in LLMs via Zero-CoT Truncation
Pith reviewed 2026-05-22 08:02 UTC · model grok-4.3
The pith
Truncating chain-of-thought reasoning exposes hidden memorization from contaminated training data in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
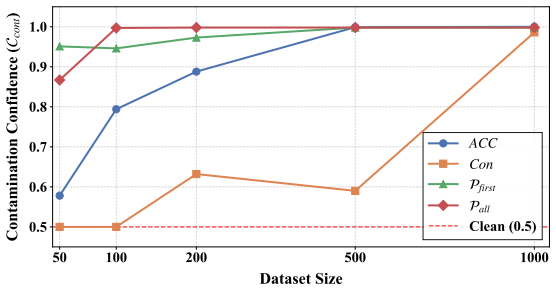
A model's generated reasoning steps actively mask its underlying memorization. The Zero-CoT Probe detects both direct and evasive contamination by truncating the entire Chain-of-Thought process and comparing zero-CoT accuracy on the original benchmark against an isomorphically perturbed reference dataset. The resulting performance gap isolates memorization effects, and a new Contamination Confidence metric quantifies both the likelihood and severity of the leakage.
What carries the argument
Zero-CoT Probe (ZCP), which removes all chain-of-thought tokens and contrasts zero-shot performance on the original benchmark with performance on an isomorphically perturbed reference set to isolate shortcut memorization.
Load-bearing premise
An isomorphically perturbed copy of the benchmark stays free of contamination and keeps the same difficulty and statistical distribution as the original.
What would settle it
A model known to have been trained only on clean data produces nearly identical zero-CoT accuracy on the original benchmark and its perturbed counterpart, while a deliberately contaminated model shows no measurable gap.
Figures




read the original abstract
Large language models (LLMs) have demonstrated impressive reasoning abilities across a wide range of tasks, but data contamination undermines the objective evaluation of these capabilities. This problem is further exacerbated by malicious model publishers who use evasive, or indirect, contamination strategies, such as paraphrasing benchmark data to evade existing detection methods and artificially boost leaderboard performance. Current approaches struggle to reliably detect such stealthy contamination. In this work, we uncover a critical phenomenon: a model's generated reasoning steps actively mask its underlying memorization. Inspired by this, we propose the Zero-CoT Probe (ZCP), a novel black-box detection method that deliberately truncates the entire Chain-of-Thought (CoT) process to expose latent shortcut mappings. To further isolate memorization from the model's intrinsic problem-solving capabilities, ZCP compares the model's zero-CoT performance on the original benchmark against an isomorphically perturbed reference dataset. Furthermore, we introduce Contamination Confidence, a metric that quantifies both the likelihood and severity of contamination, moving beyond simple binary classifications. Extensive experiments on both previously identified contaminated models and specially fine-tuned contaminated models demonstrate that ZCP robustly detects both direct and evasive data contamination. The code for ZCP is accessible at https://github.com/Yifan-Lan/zero-cot-probe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs' generated reasoning steps can mask underlying memorization from data contamination, including evasive strategies such as paraphrasing. It introduces the Zero-CoT Probe (ZCP), which truncates the full Chain-of-Thought process and detects contamination by comparing zero-CoT performance on the original benchmark against an isomorphically perturbed reference dataset; it also defines a Contamination Confidence metric. Experiments on previously identified contaminated models and specially fine-tuned ones are said to show robust detection of both direct and evasive contamination.
Significance. If the central isolation claim holds after proper controls, ZCP would offer a practical black-box tool for identifying stealthy contamination that evades existing detectors, strengthening the validity of LLM benchmark evaluations. The core idea of deliberately truncating CoT to surface latent shortcuts is a targeted and potentially useful contribution.
major comments (2)
- [§3] §3 (method description): the paper provides no concrete details on how the isomorphically perturbed reference datasets are constructed (perturbation rules, surface-statistic preservation, or isomorphism criteria). Without these, it is impossible to verify that observed performance gaps isolate memorization rather than perturbation-induced difficulty or distribution shifts, which directly undermines the central claim.
- [§4] §4 (experiments): no statistical controls, human difficulty ratings, or results on clean models are reported to confirm that the perturbed sets preserve task difficulty and distribution. The abstract's claim that gaps 'isolate memorization' therefore rests on an untested assumption; this is load-bearing for the detection results on both known and fine-tuned contaminated models.
minor comments (2)
- [Abstract] The abstract and method sections use 'isomorphically perturbed' without a precise operational definition or example; adding one would improve clarity.
- Figure or table captions describing the perturbed datasets should explicitly state the perturbation procedure and any equivalence checks performed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of clarity and validation that we address below. We have revised the manuscript to strengthen the presentation of the method and experimental controls.
read point-by-point responses
-
Referee: [§3] §3 (method description): the paper provides no concrete details on how the isomorphically perturbed reference datasets are constructed (perturbation rules, surface-statistic preservation, or isomorphism criteria). Without these, it is impossible to verify that observed performance gaps isolate memorization rather than perturbation-induced difficulty or distribution shifts, which directly undermines the central claim.
Authors: We agree that explicit details on dataset construction are necessary for reproducibility and to support the isolation claim. In the revised manuscript we have expanded Section 3 with a dedicated subsection that specifies the perturbation procedure: problems are paraphrased by replacing surface lexical items and syntactic frames while preserving the underlying logical structure, variable bindings, and answer format (ensuring isomorphism). Surface statistics are controlled by matching sentence length, token-frequency histograms, and parse-tree depth distributions between original and perturbed versions. These rules are now stated with pseudocode and concrete examples drawn from the benchmarks used. revision: yes
-
Referee: [§4] §4 (experiments): no statistical controls, human difficulty ratings, or results on clean models are reported to confirm that the perturbed sets preserve task difficulty and distribution. The abstract's claim that gaps 'isolate memorization' therefore rests on an untested assumption; this is load-bearing for the detection results on both known and fine-tuned contaminated models.
Authors: We accept that additional validation strengthens the central claim. The revised Section 4 now reports (i) zero-CoT results on three clean models (Llama-2-7B, Mistral-7B, and a randomly initialized transformer) showing negligible performance gaps between original and perturbed sets, (ii) paired t-tests and effect-size calculations confirming that gaps in contaminated models are statistically significant (p < 0.01) while gaps in clean models are not, and (iii) an analysis of model confidence and answer consistency that serves as a proxy for preserved task difficulty. A full human difficulty rating study was not feasible within the revision timeline; we therefore rely on the statistical and clean-model controls above, which directly test the assumption that perturbations do not systematically alter difficulty. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The ZCP method measures an empirical performance gap between zero-CoT on the original benchmark and an isomorphically perturbed reference set. This is a direct observational comparison rather than a fitted parameter renamed as a prediction or a self-definitional loop. The abstract presents the perturbed set as an external control constructed to isolate memorization, with no indication that perturbation rules or thresholds are tuned on the same test models in a way that forces the detection signal by construction. No self-citation chains, uniqueness theorems, or ansatz smuggling are referenced as load-bearing. The central claim remains an empirical detection procedure whose validity rests on external validation experiments rather than reducing to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Isomorphic perturbations preserve task semantics and difficulty while removing surface-level memorization cues.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.02823 , year=
Evading data contamination detection for language models is (too) easy , author=. arXiv preprint arXiv:2402.02823 , year=
-
[2]
Proceedings of the 16th International Natural Language Generation Conference , pages=
Preventing generation of verbatim memorization in language models gives a false sense of privacy , author=. Proceedings of the 16th International Natural Language Generation Conference , pages=
-
[3]
arXiv preprint arXiv:2306.07899 , year=
Artificial artificial artificial intelligence: Crowd workers widely use large language models for text production tasks , author=. arXiv preprint arXiv:2306.07899 , year=
-
[4]
arXiv preprint arXiv:2507.10532 , year=
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination , author=. arXiv preprint arXiv:2507.10532 , year=
-
[5]
The Eleventh International Conference on Learning Representations , year=
Quantifying Memorization Across Neural Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[6]
Avi Schwarzschild and Zhili Feng and Pratyush Maini and Zachary Chase Lipton and J Zico Kolter , booktitle=. Rethinking. 2025 , url=
work page 2025
-
[7]
Generalization or memorization: Data contamination and trustworthy evaluation for large language models , author=. arXiv preprint arXiv:2402.15938 , year=
-
[8]
Rethinking benchmark and contamination for language models with rephrased samples , author=. arXiv preprint arXiv:2311.04850 , year=
-
[9]
arXiv preprint arXiv:2308.08493 , year=
Time travel in llms: Tracing data contamination in large language models , author=. arXiv preprint arXiv:2308.08493 , year=
-
[10]
The Twelfth International Conference on Learning Representations , year=
Proving test set contamination in black-box language models , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
Detecting Pretraining Data from Large Language Models
Detecting pretraining data from large language models , author=. arXiv preprint arXiv:2310.16789 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
work page 2020
-
[13]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2502.14425 , year=
A survey on data contamination for large language models , author=. arXiv preprint arXiv:2502.14425 , year=
-
[15]
Benchmark Data Contamination of Large Language Models: A Survey
Benchmark data contamination of large language models: A survey , author=. arXiv preprint arXiv:2406.04244 , year=
work page internal anchor Pith review arXiv
-
[16]
generalization: Quantifying data leakage in NLP performance evaluation , author=
Memorization vs. generalization: Quantifying data leakage in NLP performance evaluation , author=. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
-
[17]
30th USENIX security symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX security symposium (USENIX Security 21) , pages=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Membership inference attacks against language models via neighbourhood comparison , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
work page 2023
-
[19]
Investigating data contamination in modern benchmarks for large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[20]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The Fourteenth International Conference on Learning Representations , year=
Is it Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effort , author=. The Fourteenth International Conference on Learning Representations , year=
-
[22]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[23]
Automatic Chain of Thought Prompting in Large Language Models
Automatic chain of thought prompting in large language models , author=. arXiv preprint arXiv:2210.03493 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[26]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
work page 2024
-
[28]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[29]
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
work page 2024
-
[30]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks
Mireshghallah, Fatemehsadat and Goyal, Kartik and Uniyal, Archit and Berg-Kirkpatrick, Taylor and Shokri, Reza. Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.570
-
[36]
arXiv preprint arXiv:2406.04197 , year=
DICE: Detecting In-distribution Contamination in LLM's Fine-tuning Phase for Math Reasoning , author=. arXiv preprint arXiv:2406.04197 , year=
-
[37]
Detect-Pretrain-Code-Contamination , year =
Weijia Shi , howpublished =. Detect-Pretrain-Code-Contamination , year =
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Journal of Mathematical Psychology , volume=
Rejection odds and rejection ratios: A proposal for statistical practice in testing hypotheses , author=. Journal of Mathematical Psychology , volume=. 2016 , publisher=
work page 2016
-
[40]
The American Statistician , volume=
Calibration of values for testing precise null hypotheses , author=. The American Statistician , volume=. 2001 , publisher=
work page 2001
-
[41]
The probable error of a mean , author=. Biometrika , pages=. 1908 , publisher=
work page 1908
-
[42]
Note on the sampling error of the difference between correlated proportions or percentages , author=. Psychometrika , volume=. 1947 , publisher=
work page 1947
-
[43]
Breakthroughs in statistics: Methodology and distribution , pages=
Bootstrap methods: another look at the jackknife , author=. Breakthroughs in statistics: Methodology and distribution , pages=. 1992 , publisher=
work page 1992
-
[44]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Does data contamination detection work (well) for llms? a survey and evaluation on detection assumptions , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[45]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Advances in Neural Information Processing Systems , volume=
A careful examination of large language model performance on grade school arithmetic , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Bofei Gao and Feifan Song and Zhe Yang and Zefan Cai and Yibo Miao and Qingxiu Dong and Lei Li and Chenghao Ma and Liang Chen and Runxin Xu and Zhengyang Tang and Benyou Wang and Daoguang Zan and Shanghaoran Quan and Ge Zhang and Lei Sha and Yichang Zhang and Xuancheng Ren and Tianyu Liu and Baobao Chang , booktitle=. Omni-. 2025 , url=
work page 2025
-
[48]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
- [49]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.