AeroVerse-SatAgent: UAV-Satellite Collaborative Spatial Reasoning Inspired by the Dual Visual Pathway Theory of Cognitive Neuroscience
Pith reviewed 2026-07-01 06:16 UTC · model grok-4.3
The pith
SatAgent combines UAV and satellite views with explicit 3D geometry to enable more accurate spatial reasoning in urban settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
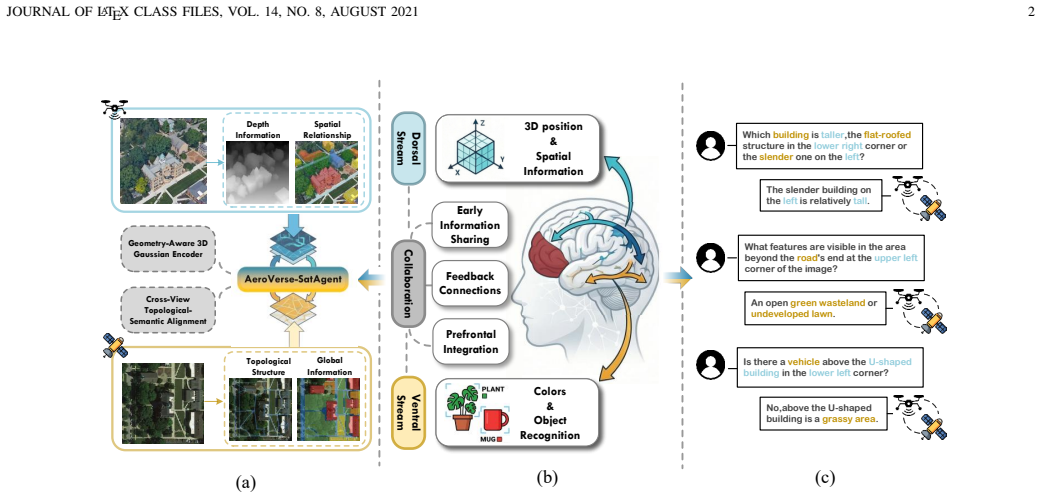
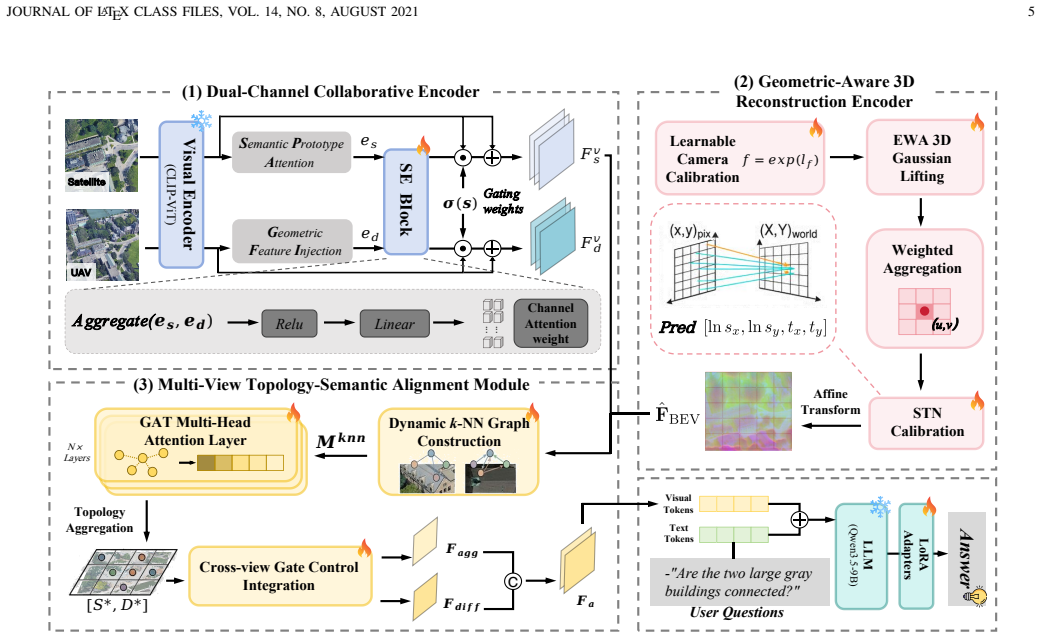
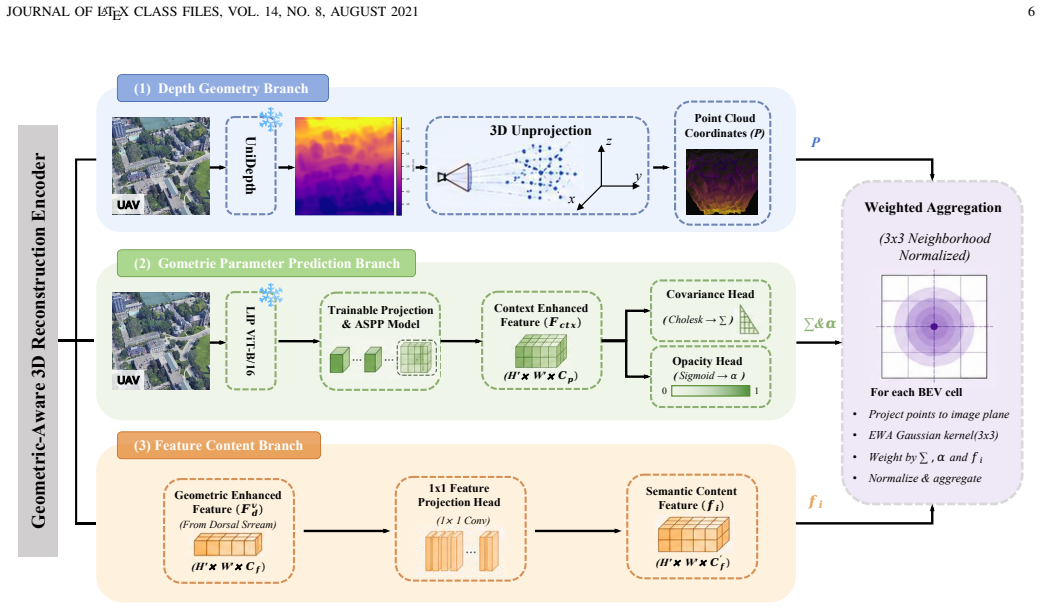
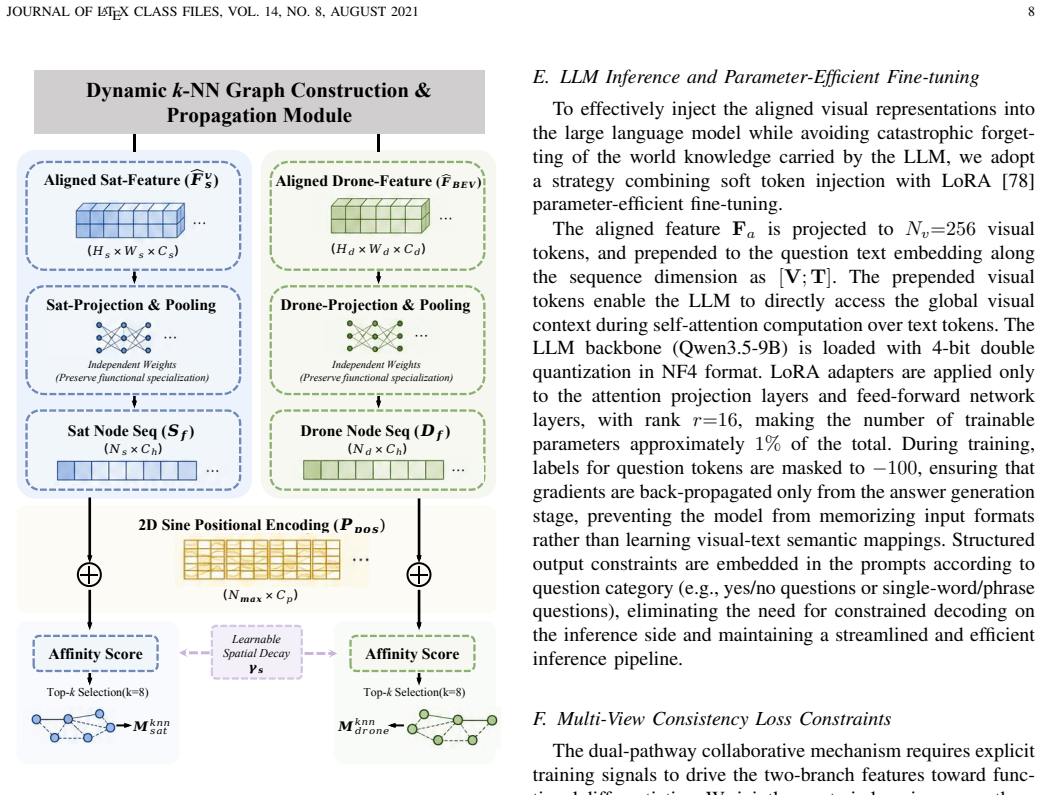
SatAgent jointly leverages satellite and UAV perspectives through a Geometric-Aware 3D Reconstruction Encoder that lifts 2D UAV features into explicit 3D spatial representations, a multi-view topology-semantic alignment module that integrates cross-view features in a unified BEV coordinate system, and a multi-view consistency loss that encourages viewpoint-invariant representations, resulting in improved performance on spatial reasoning tasks.
What carries the argument
The Geometric-Aware 3D Reconstruction Encoder that converts 2D UAV features into explicit 3D spatial representations, together with multi-view alignment across satellite and UAV inputs.
If this is right
- The model achieves 25.91 percent higher accuracy than general foundation models and 11.69 percent higher than specialized spatial reasoning models across tasks.
- Accuracy is particularly strong on complex geometric relationship reasoning.
- The multi-view consistency loss produces features that remain stable under changes in viewpoint and scale.
- Joint UAV-satellite processing reduces errors from occlusions and perspective distortions compared with single-view methods.
Where Pith is reading between the lines
- The same encoder and alignment structure could be adapted to other pairs of sensors, such as ground cameras paired with aerial views.
- Real-time deployment on UAVs would require checking whether the 3D reconstruction step runs at acceptable speeds on embedded hardware.
- Extending the dataset to rural or indoor scenes would test whether the performance pattern persists outside the original urban focus.
Load-bearing premise
The reported gains depend on the SatAgent-SR130K dataset capturing representative urban conditions and the improvements arising specifically from the new 3D encoder and alignment modules rather than from dataset choices or tuning.
What would settle it
Evaluating the model on an independent dataset with different city layouts, camera angles, or scale ranges and observing no accuracy advantage over baseline models would indicate the central claim does not hold.
Figures

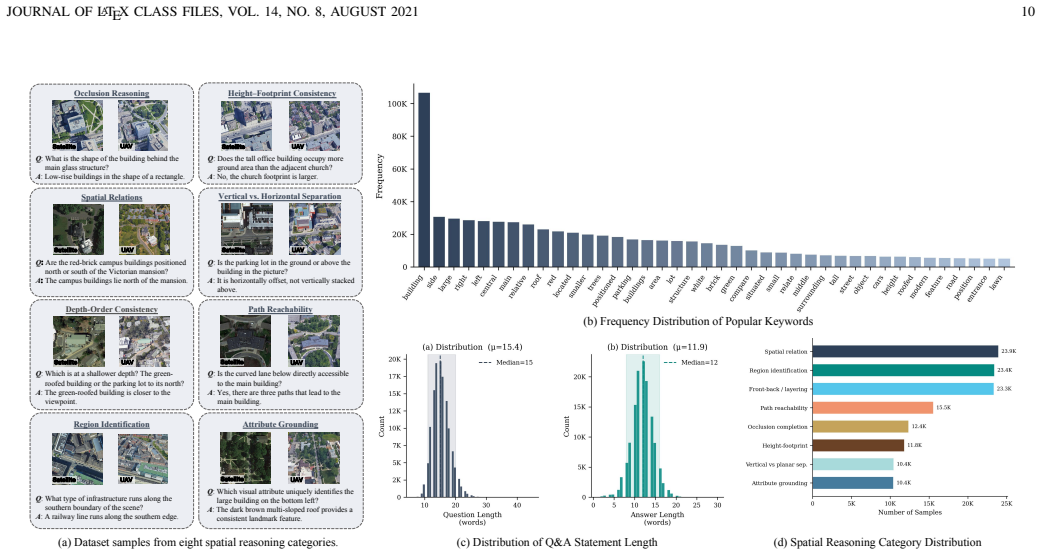
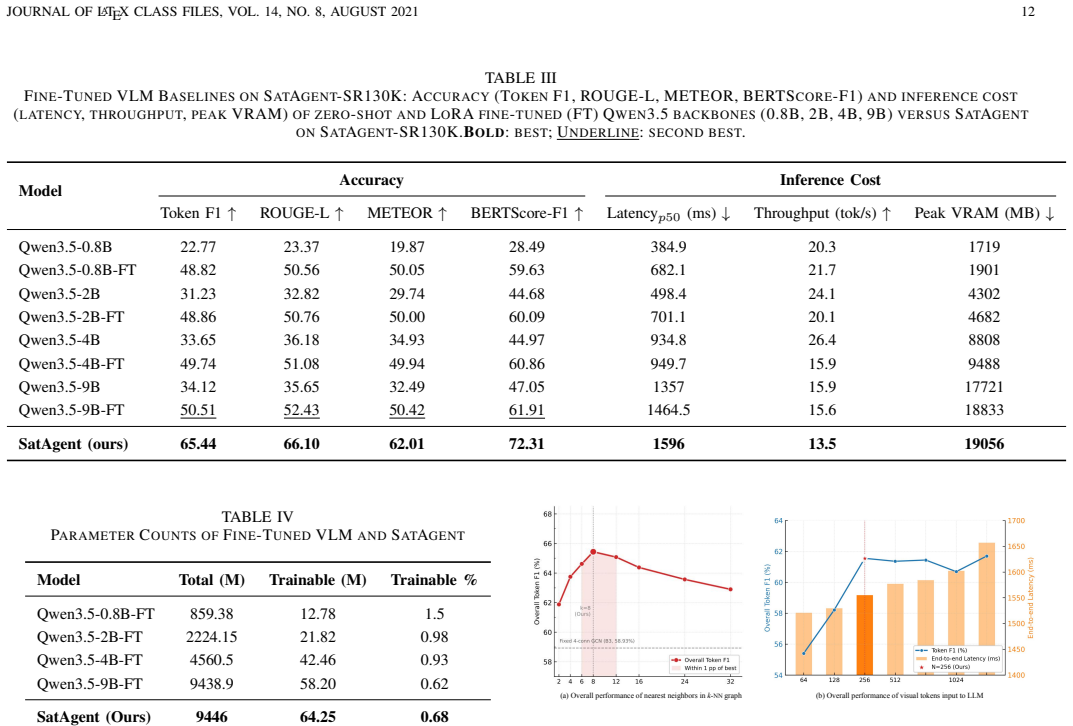
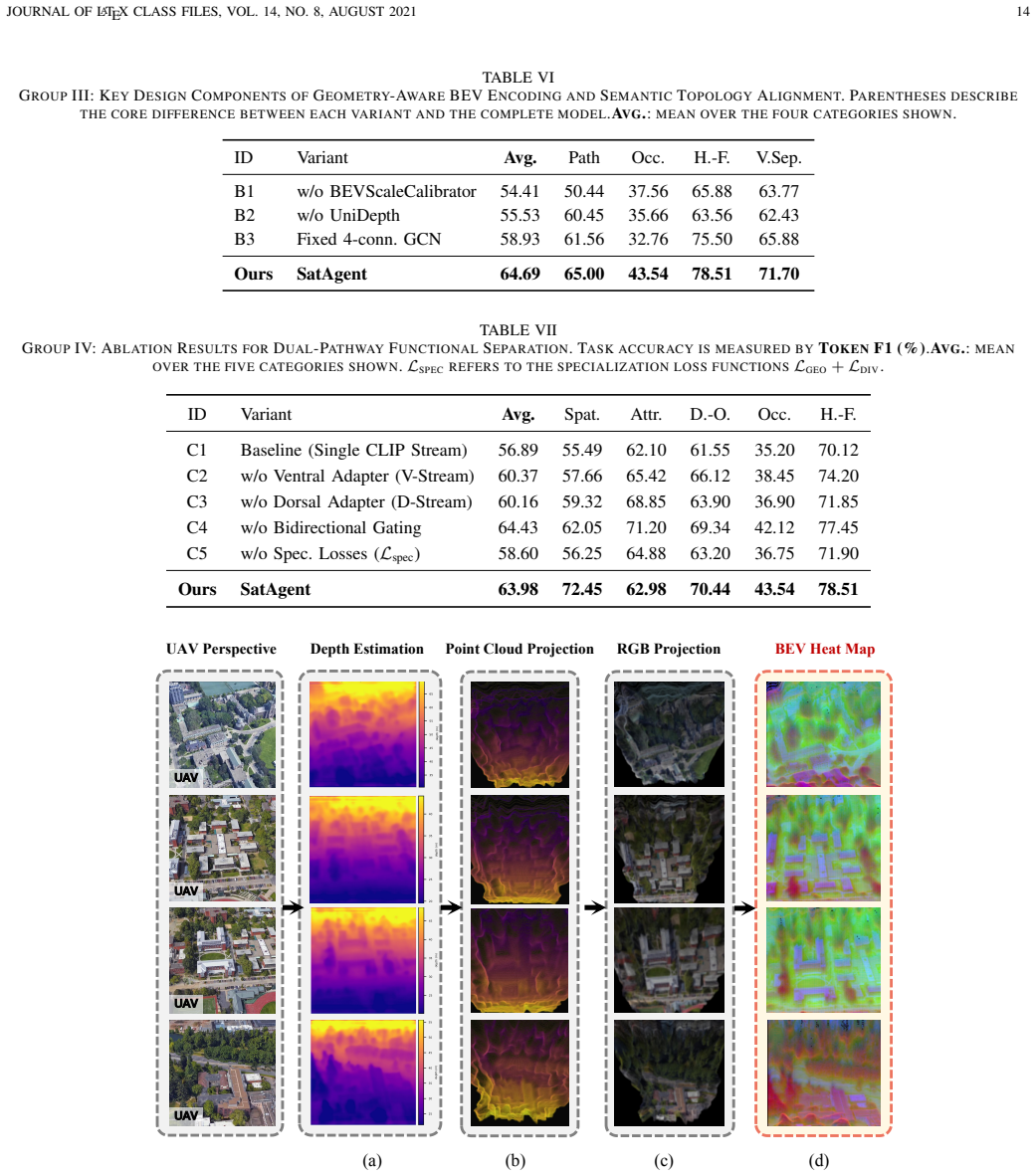
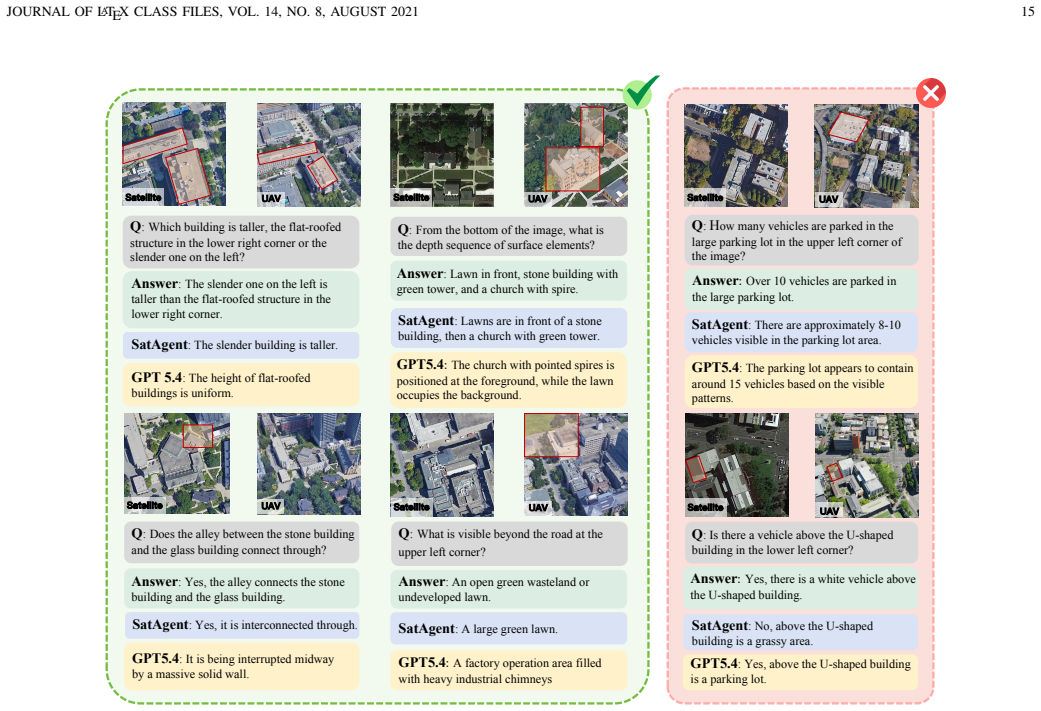

read the original abstract
With the rapid advancement of aerospace embodied intelligence, enabling Unmanned Aerial Vehicles (UAVs) to autonomously understand and reason about complex environments has become increasingly important. However, existing UAV-based spatial reasoning approaches face critical limitations: single-view perception renders them vulnerable to occlusions and perspective distortions, while most VLMs lack explicit geometric modeling, relying on semantic cues and yielding inconsistent reasoning under viewpoint and scale variations. To address these challenges, we propose SatAgent, a UAV-Satellite collaborative spatial reasoning model inspired by the dual-pathway mechanism of the human visual system. By jointly leveraging satellite and UAV perspectives, SatAgent enables robust, accurate reasoning in complex urban environments. We first introduce a Geometric-Aware 3D Reconstruction Encoder that elevates 2D UAV features into explicit 3D spatial representations. Next, we design a multi-view topology-semantic alignment module integrating cross-view features within a unified BEV coordinate system. We further introduce a multi-view consistency loss encouraging viewpoint-invariant representations. Finally, we construct SatAgent-SR130K, the first large-scale UAV-Satellite collaborative multi-view spatial reasoning dataset. Experiments show SatAgent outperforms state-of-the-art general-purpose foundation models and specialized spatial reasoning models by 25.91\% and 11.69\%, respectively, across diverse tasks, achieving particularly high accuracy in complex geometric relationship reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SatAgent, a UAV-satellite collaborative spatial reasoning model inspired by the dual visual pathway theory. It introduces a Geometric-Aware 3D Reconstruction Encoder to lift 2D UAV features into explicit 3D representations, a multi-view topology-semantic alignment module operating in a unified BEV coordinate system, and a multi-view consistency loss to promote viewpoint-invariant features. The authors also release the SatAgent-SR130K dataset for UAV-satellite multi-view spatial reasoning. The central claim is that SatAgent outperforms general-purpose foundation models by 25.91% and specialized spatial reasoning models by 11.69% across tasks, with strongest results on complex geometric relationship reasoning.
Significance. If the performance margins can be attributed to the proposed 3D encoder and cross-view alignment rather than dataset construction or training choices, the work would advance UAV embodied intelligence by providing an explicit geometric pathway that mitigates single-view occlusions and scale inconsistencies. The new collaborative dataset is a concrete enabling contribution for the community.
major comments (2)
- [Experiments] Experiments section: The headline gains of 25.91% and 11.69% are reported without ablation experiments that train the same backbone on SatAgent-SR130K while removing the Geometric-Aware 3D Reconstruction Encoder or the BEV alignment module. Without such controls it is impossible to determine whether the margins arise from the dual-pathway architecture or from the new dataset and task formulation.
- [Method] Method section (multi-view consistency loss): The loss is described only at a high level as encouraging viewpoint-invariant representations; its exact form (contrastive, regression, or otherwise), temperature, and relative weighting to the primary task loss are not specified, preventing assessment of whether it is load-bearing for the geometric reasoning accuracy.
minor comments (1)
- [Abstract] Abstract: Performance figures are stated without error bars, number of runs, or basic dataset statistics (train/val/test sizes, scene diversity), which is standard practice for empirical claims in computer vision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline gains of 25.91% and 11.69% are reported without ablation experiments that train the same backbone on SatAgent-SR130K while removing the Geometric-Aware 3D Reconstruction Encoder or the BEV alignment module. Without such controls it is impossible to determine whether the margins arise from the dual-pathway architecture or from the new dataset and task formulation.
Authors: We agree that the current experiments do not include the requested ablations on the same backbone and dataset. In the revised manuscript we will add these controls: training the identical backbone on SatAgent-SR130K after removing the Geometric-Aware 3D Reconstruction Encoder and, separately, after removing the BEV alignment module. The new results will be reported to isolate the contribution of each proposed component. revision: yes
-
Referee: [Method] Method section (multi-view consistency loss): The loss is described only at a high level as encouraging viewpoint-invariant representations; its exact form (contrastive, regression, or otherwise), temperature, and relative weighting to the primary task loss are not specified, preventing assessment of whether it is load-bearing for the geometric reasoning accuracy.
Authors: We acknowledge that the multi-view consistency loss is described at an insufficient level of detail. In the revision we will specify the exact loss formulation (including whether it is contrastive or regression-based), the temperature hyper-parameter if used, and the scalar weight applied relative to the primary task loss. revision: yes
Circularity Check
No circularity: new architecture and dataset presented without self-referential reductions
full rationale
The paper constructs SatAgent from scratch with a Geometric-Aware 3D Reconstruction Encoder, multi-view topology-semantic alignment module, and multi-view consistency loss, then evaluates on the newly introduced SatAgent-SR130K dataset. No equations, loss terms, or performance metrics are shown to reduce by construction to fitted parameters from the same data or to prior self-citations. The derivation chain consists of independent design choices and empirical reporting rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aeroverse-review: Comprehensive survey on aerial em- bodied vision-and-language navigation,
F. Yao, Y . Liu, W. Zhang, Z. Zhu, C. Li, N. Liu, P. Hu, Y . Yue, K. Wei, X. Heet al., “Aeroverse-review: Comprehensive survey on aerial em- bodied vision-and-language navigation,”The Innovation Informatics, vol. 1, no. 1, p. 100015, 2025
2025
-
[2]
Aeroverse: Uav-agent benchmark suite for simulating, pre-training, finetuning, and evaluating aerospace embodied foundation models,
F. Yao, Y . Yue, Y . Liu, Z. Wang, L. Jin, B. Zhao, J. Zhao, X. Sun, and K. Fu, “Aeroverse: Uav-agent benchmark suite for simulating, pre-training, finetuning, and evaluating aerospace embodied foundation models,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, pp. 1–18, 2026
2026
-
[3]
Navagent: Multi- scale urban street view fusion for uav embodied vision-and-language navigation,
Y . Liu, F. Yao, Y . Yue, G. Xu, X. Sun, and K. Fu, “Navagent: Multi- scale urban street view fusion for uav embodied vision-and-language navigation,”arXiv preprint arXiv:2411.08579, 2024
-
[4]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning,
J. Johnson, B. Hariharan, L. Van Der Maaten, L. Fei-Fei, C. Lawrence Zitnick, and R. Girshick, “Clevr: A diagnostic dataset for compositional language and elementary visual reasoning,” inPro- ceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2901–2910
2017
-
[5]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683
2018
-
[6]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Learning to Navigate in Complex Environments
P. Mirowski, R. Pascanu, F. Viola, H. Soyer, A. J. Ballard, A. Banino, M. Denil, R. Goroshin, L. Sifre, K. Kavukcuogluet al., “Learning to navigate in complex environments,”arXiv preprint arXiv:1611.03673, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, M. Deitke, K. Ehsani, D. Gordon, Y . Zhuet al., “Ai2-thor: An inter- active 3d environment for visual ai,”arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Knowledge-based embodied question answering,
S. Tan, M. Ge, D. Guo, H. Liu, and F. Sun, “Knowledge-based embodied question answering,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 11 948–11 960, 2023
2023
-
[10]
Depth and video segmentation based visual attention for embodied question answering,
H. Luo, G. Lin, Y . Yao, F. Liu, Z. Liu, and Z. Tang, “Depth and video segmentation based visual attention for embodied question answering,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 6807–6819, 2023
2023
-
[11]
3D Gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, vol. 42, no. 4, 2023
2023
-
[12]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” inComputer Vision – ECCV 2020, ser. Lecture Notes in Computer Science, vol. 12346. Springer, 2020, pp. 405– 421
2020
-
[13]
Unmanned aerial vehicle-neural radiance field (UA V-NeRF): Learning multiview drone three-dimensional reconstruction with neural radiance field,
L. Li, Y . Zhang, Z. Jiang, Z. Wang, L. Zhang, and H. Gao, “Unmanned aerial vehicle-neural radiance field (UA V-NeRF): Learning multiview drone three-dimensional reconstruction with neural radiance field,” Remote Sensing, vol. 16, no. 22, p. 4168, 2024
2024
-
[14]
Depth anything V2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything V2,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[15]
SkyScenes: A synthetic dataset for aerial scene understand- ing,
S. Khose, A. Pal, A. Agarwal, Deepanshi, J. Hoffman, and P. Chat- topadhyay, “SkyScenes: A synthetic dataset for aerial scene understand- ing,” inComputer Vision – ECCV 2024, ser. Lecture Notes in Computer Science, vol. 15137. Springer, 2024, pp. 19–35
2024
-
[16]
Semantic-driven autonomous visual navigation for unmanned aerial vehicles,
P. Yue, J. Xin, Y . Zhang, Y . Lu, and M. Shan, “Semantic-driven autonomous visual navigation for unmanned aerial vehicles,”IEEE Transactions on Industrial Electronics, vol. 71, no. 11, pp. 14 853– 14 863, 2024
2024
-
[17]
Vision-based navigation techniques for unmanned aerial vehicles: Review and challenges,
M. Y . Arafat, M. M. Alam, and S. Moh, “Vision-based navigation techniques for unmanned aerial vehicles: Review and challenges,” Drones, vol. 7, no. 2, p. 89, 2023
2023
-
[18]
Learning perception- aware agile flight in cluttered environments,
Y . Song, K. Shi, R. Penicka, and D. Scaramuzza, “Learning perception- aware agile flight in cluttered environments,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 1989–1995
2023
-
[19]
Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models,
M. Jia, Z. Qi, S. Zhang, W. Zhang, X. Yu, J. He, H. Wang, and L. Yi, “Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models,”arXiv preprint arXiv:2506.03135, 2025
-
[20]
Visual spatial reasoning,
F. Liu, G. Emerson, and N. Collier, “Visual spatial reasoning,”Trans- actions of the Association for Computational Linguistics, vol. 11, pp. 635–651, 2023
2023
-
[21]
Mind the gap: Benchmarking spatial reasoning in vision-language models,
I. Stogiannidis, S. McDonagh, and S. A. Tsaftaris, “Mind the gap: Benchmarking spatial reasoning in vision-language models,”arXiv preprint arXiv:2503.19707, 2025
-
[22]
Spatialrgpt: Grounded spatial reasoning in vision-language models,
A.-C. Cheng, H. Yin, Y . Fu, Q. Guo, R. Yang, J. Kautz, X. Wang, and S. Liu, “Spatialrgpt: Grounded spatial reasoning in vision-language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 135 062–135 093, 2024
2024
-
[23]
Accurate 3-dof camera geo-localization via ground-to-satellite image matching,
Y . Shi, X. Yu, L. Liu, D. Campbell, P. Koniusz, and H. Li, “Accurate 3-dof camera geo-localization via ground-to-satellite image matching,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 2682–2697, 2022
2022
-
[24]
arXiv preprint arXiv:2503.01773 , year=
S. Chen, T. Zhu, R. Zhou, J. Zhang, S. Gao, J. C. Niebles, M. Geva, J. He, J. Wu, and M. Li, “Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas,”arXiv preprint arXiv:2503.01773, 2025
-
[25]
Sphere: Unveiling spatial blind spots in vision- language models through hierarchical evaluation,
W. Zhang, W. E. Ng, L. Ma, Y . Wang, J. Zhao, A. Koenecke, B. Li, and W. Wanglu, “Sphere: Unveiling spatial blind spots in vision- language models through hierarchical evaluation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 11 591–11 609
2025
-
[26]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models,
J. Wang, Y . Ming, Z. Shi, V . Vineet, X. Wang, S. Li, and N. Joshi, “Is a picture worth a thousand words? delving into spatial reasoning for vision language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 75 392–75 421, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 17
2024
-
[27]
A neurological dissociation between perceiving objects and grasping them,
M. A. Goodale, A. D. Milner, L. S. Jakobson, and D. P. Carey, “A neurological dissociation between perceiving objects and grasping them,”Nature, vol. 349, no. 6305, pp. 154–156, 1991
1991
-
[28]
Separate visual pathways for perception and action,
M. A. Goodale and A. D. Milner, “Separate visual pathways for perception and action,”Trends in Neurosciences, vol. 15, no. 1, pp. 20–25, 1992
1992
-
[29]
Two cortical visual systems,
L. G. Ungerleider, “Two cortical visual systems,”Analysis of visual behavior, vol. 549, pp. chapter–18, 1982
1982
-
[30]
Towards natural language-guided drones: Geotext-1652 benchmark with spatial relation matching,
M. Chu, Z. Zheng, W. Ji, T. Wang, and T.-S. Chua, “Towards natural language-guided drones: Geotext-1652 benchmark with spatial relation matching,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 213–231
2024
-
[31]
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. [Online]. Available: https://arxiv.org/abs/2412.14171
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
ViewSpatial-Bench: Evaluating multi-perspective spatial localization in vision-language models,
R. Li, S. Li, L. Kong, X. Yang, and J. Liang, “ViewSpatial-Bench: Evaluating multi-perspective spatial localization in vision-language models,”arXiv preprint arXiv:2505.21500, 2025. [Online]. Available: https://arxiv.org/abs/2505.21500
-
[33]
MM- Spatial: Exploring 3D spatial understanding in multimodal LLMs,
E. Daxberger, N. Wenzel, D. Griffiths, H. Gang, J. Lazarow, G. Kohavi, K. Kang, M. Eichner, Y . Yang, A. Dehghan, and P. Grasch, “MM- Spatial: Exploring 3D spatial understanding in multimodal LLMs,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 7395–7408
2025
-
[34]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
S. Yang, R. Xu, Y . Xie, S. Yang, M. Li, J. Lin, C. Zhu, X. Chen, H. Duan, X. Yueet al., “MMSI-Bench: A benchmark for multi-image spatial intelligence,” inInternational Conference on Learning Representations, 2026. [Online]. Available: https: //arxiv.org/abs/2505.23764
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Urbench: A comprehensive benchmark for eval- uating large multimodal models in multi-view urban scenarios,
B. Zhou, H. Yang, D. Chen, J. Ye, T. Bai, J. Yu, S. Zhang, D. Lin, C. He, and W. Li, “Urbench: A comprehensive benchmark for eval- uating large multimodal models in multi-view urban scenarios,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[36]
All-angles bench: Can mllms answer different perspective questions well?
C.-H. Yeh, C. Wang, S. Tong, T.-Y . Cheng, Y . Zhai, Y . Chen, S. Gao, and Y . Ma, “All-angles bench: Can mllms answer different perspective questions well?” 2025
2025
-
[37]
AirCopBench: A benchmark for multi-drone collaborative embodied perception and reasoning,
J. Zha, Y . Fan, T. Zhang, G. Chen, Y . Chen, C. Gao, and X. Chen, “AirCopBench: A benchmark for multi-drone collaborative embodied perception and reasoning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 2, 2026, pp. 1507–1515
2026
-
[38]
CityCube: Benchmarking cross-view spatial reasoning on vision-language models in urban environments,
H. Xu, Y . Hu, Z. Zhu, C. Gao, Z. Wang, J. Rao, W. Lu, W. Li, Q. Yin, and Y . Li, “CityCube: Benchmarking cross-view spatial reasoning on vision-language models in urban environments,” arXiv preprint arXiv:2601.14339, 2026. [Online]. Available: https: //arxiv.org/abs/2601.14339
-
[39]
Open3dvqa: A benchmark for comprehensive spatial reasoning with multimodal large language model in open space,
W. Zhanget al., “Open3dvqa: A benchmark for comprehensive spatial reasoning with multimodal large language model in open space,” in Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM), 2025
2025
-
[40]
Uavreason: A unified, large-scale benchmark for multimodal aerial scene reasoning and generation,
o. Li, “Uavreason: A unified, large-scale benchmark for multimodal aerial scene reasoning and generation,” 2026
2026
-
[41]
D. Liu, Y . Zheng, J. Feng, G. Li, G. Shi, D. Li, and W. Dong, “Are VLMs lost between sky and space? LinkS 2Bench for UA V- satellite dynamic cross-view spatial intelligence,”arXiv preprint arXiv:2604.02020, 2026. [Online]. Available: https://arxiv.org/abs/ 2604.02020
-
[42]
Spatialladder: Progressive train- ing for spatial reasoning in vision-language models,
H. Li, D. Li, Z. Wang, Y . Yan, H. Wu, W. Zhang, Y . Shen, W. Lu, J. Xiao, and Y . Zhuang, “Spatialladder: Progressive train- ing for spatial reasoning in vision-language models,”arXiv preprint arXiv:2510.08531, 2025
-
[43]
Spatial- vilt: Enhancing visual spatial reasoning through multi-task learning,
C. M. Islam, O. Mamo, S. J. Chacko, X. Liu, and W. Yu, “Spatial- vilt: Enhancing visual spatial reasoning through multi-task learning,” inInternational Symposium on Visual Computing. Springer, 2025, pp. 47–58
2025
-
[44]
Sparkle: Mastering basic spatial capabilities in vision language models elicits generalization to spatial reasoning,
Y . Tang, A. Qu, Z. Wang, D. Zhuang, Z. Wu, W. Ma, S. Wang, Y . Zheng, Z. Zhao, and J. Zhao, “Sparkle: Mastering basic spatial capabilities in vision language models elicits generalization to spatial reasoning,”Findings of the Association for Computational Linguistics: EMNLP, vol. 2025, pp. 4083–4103, 2025
2025
-
[45]
Reasoning paths with reference objects elicit quantitative spatial reasoning in large vision-language models,
Y .-H. Liao, R. Mahmood, S. Fidler, and D. Acuna, “Reasoning paths with reference objects elicit quantitative spatial reasoning in large vision-language models,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 17 028– 17 047
2024
-
[46]
3D- LLM: Injecting the 3D world into large language models,
Y . Hong, H. Zhen, P. Chen, S. Zheng, Y . Du, Z. Chen, and C. Gan, “3D- LLM: Injecting the 3D world into large language models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[47]
LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D-awareness,
C. Zhu, T. Wang, W. Zhang, J. Pang, and X. Liu, “LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D-awareness,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[48]
ConceptGraphs: Open-vocabulary 3D scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, C. Gan, C. M. de Melo, J. B. Tenenbaum, A. Torralba, F. Shkurti, and L. Paull, “ConceptGraphs: Open-vocabulary 3D scene graphs for perception and planning,” inProceedings of the IEEE International Conference on Robotics and Automation (IC...
2024
-
[49]
Kosmos-2: Grounding multimodal large language models to the world,
Z. Peng, W. Wang, L. Dong, Y . Hao, S. Huang, S. Ma, and F. Wei, “Kosmos-2: Grounding multimodal large language models to the world,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[50]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
K. Chen, Z. Zhang, W. Zeng, R. Zhang, F. Zhu, and R. Zhao, “Shikra: Unleashing multimodal LLM’s referential dialogue magic,” arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Ferret: Refer and ground anything anywhere at any granularity,
H. You, H. Zhang, Z. Gan, X. Du, B. Zhang, Z. Wang, L. Cao, S.-F. Chang, and Y . Yang, “Ferret: Refer and ground anything anywhere at any granularity,” inInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[52]
RegionGPT: Towards region understanding vision language model,
Q. Guo, S. De Mello, H. Yin, W. Byeon, K. C. Cheung, Y . Yu, P. Luo, and S. Liu, “RegionGPT: Towards region understanding vision language model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 13 796– 13 806
2024
-
[53]
Osprey: Pixel understanding with visual instruction tuning,
Y . Yuan, W. Li, J. Liu, D. Tang, X. Luo, C. Qin, L. Zhang, and J. Zhu, “Osprey: Pixel understanding with visual instruction tuning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 28 202–28 211
2024
-
[54]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia, “Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 455–14 465
2024
-
[55]
Ucdnet: Multi-uav collaborative 3-d object detection network by reliable feature mapping,
P. Tian, Z. Wang, P. Chenget al., “Ucdnet: Multi-uav collaborative 3-d object detection network by reliable feature mapping,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–16, 2024
2024
-
[56]
Drones help drones: A col- laborative framework for multi-drone object trajectory prediction and beyond,
Z. Wang, P. Cheng, M. Chenet al., “Drones help drones: A col- laborative framework for multi-drone object trajectory prediction and beyond,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 64 604–64 628
2024
-
[57]
MANTIS: Interleaved multi-image instruction tuning,
D. Jiang, X. He, H. Zeng, C. Wei, M. W. Ku, Q. Liu, and W. Chen, “MANTIS: Interleaved multi-image instruction tuning,”Transactions on Machine Learning Research (TMLR), 2024
2024
-
[58]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
F. Li, R. Zhang, H. Zhang, Y . Zhang, B. Li, W. Li, Z. Ma, and C. Li, “LLaV A-NeXT-Interleave: Tackling multi-image, video, and 3D in large multimodal models,”arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Video-3D LLM: Learning position- aware video representation for 3D scene understanding,
D. Zheng, S. Huang, and L. Wang, “Video-3D LLM: Learning position- aware video representation for 3D scene understanding,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[60]
BEVFormer: Learning bird’s-eye-view representation from LiDAR- camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y . Qiao, and J. Dai, “BEVFormer: Learning bird’s-eye-view representation from LiDAR- camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, 2024
2024
-
[61]
RSVQA: Visual question answering for remote sensing data,
S. Lobry, D. Marcos, J. Murray, and D. Tuia, “RSVQA: Visual question answering for remote sensing data,” inIEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 12, 2020, pp. 8555–8566
2020
-
[62]
Rsvg: Exploring data and models for visual grounding on remote sensing data,
Y . Zhan, Z. Yuan, B. Xiong, J. Su, Q. Wang, J. Gui, R. Wang, K. Wang, and X. X. Zhu, “Rsvg: Exploring data and models for visual grounding on remote sensing data,” inISPRS Journal of Photogrammetry and Remote Sensing, vol. 196, 2023, pp. 89–101
2023
-
[63]
EarthVQA: Towards queryable earth via relational reasoning-based remote sensing visual question answering,
K. Wang, R. Wang, J. Zhao, J. Guo, B. Dang, Y . Zhang, and S. Xiang, “EarthVQA: Towards queryable earth via relational reasoning-based remote sensing visual question answering,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 6258–6266
2024
-
[64]
STAR: A first- ever dataset and a large-scale benchmark for scene graph generation in large-size satellite imagery,
Y . Li, J. Luo, Y . Zhang, Y . Tan, J.-G. Yu, and S. Bai, “STAR: A first- ever dataset and a large-scale benchmark for scene graph generation in large-size satellite imagery,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[65]
RemoteCLIP: A vision language foundation model for remote JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18 sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “RemoteCLIP: A vision language foundation model for remote JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18 sensing,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024
2021
-
[66]
GeoChat: Grounded large vision-language model for remote sensing,
K. Kuckreja, M. S. Danish, M. Naseer, A. Das, S. Khan, and F. S. Khan, “GeoChat: Grounded large vision-language model for remote sensing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 831–27 840
2024
-
[67]
Y . Zhan, B. Xiong, and Z. Yuan, “SkyEyeGPT: Unifying remote sensing vision-language tasks via instruction tuning with large language model,”arXiv preprint arXiv:2401.09712, 2024
-
[68]
University-1652: A multi-view multi- source benchmark for drone-based geo-localization,
Z. Zheng, Y . Wei, and Y . Yang, “University-1652: A multi-view multi- source benchmark for drone-based geo-localization,” inProceedings of the ACM International Conference on Multimedia, 2020, pp. 1395– 1403
2020
-
[69]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning (ICML), 2021, pp. 8748–8763
2021
-
[70]
Unidepth: Universal monocular metric depth estimation,
L. Piccinelli, Y .-H. Yang, C. Sakaridis, M. Seg `u, S. Li, L. Van Gool, and F. Yu, “Unidepth: Universal monocular metric depth estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 10 106–10 116
2024
-
[71]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7132–7141
2018
-
[72]
BEVFusion: Multi-task multi-sensor fusion with unified BEV repre- sentation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. Rus, and S. Han, “BEVFusion: Multi-task multi-sensor fusion with unified BEV repre- sentation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 5795–5805
2023
-
[73]
Ewa volume splatting,
M. Zwicker, H. Pfister, J. van Baar, and M. Gross, “Ewa volume splatting,” inProceedings of the 28th annual conference on Computer graphics and interactive techniques (SIGGRAPH), 2001, pp. 29–38
2001
-
[74]
Spatial transformer networks,
M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[75]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems (NeurIPS), 2017, pp. 5998–6008
2017
-
[76]
Graph attention networks,
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Li `o, and Y . Bengio, “Graph attention networks,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[77]
Gated Multimodal Units for Information Fusion
J. Arevalo, T. Solorio, M. Montes-y G ´omez, and F. A. Gonz ´alez, “Gated multimodal units for information fusion,”arXiv preprint arXiv:1702.01992, 2017. [Online]. Available: https://arxiv.org/abs/ 1702.01992
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[78]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” inAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2023
2023
-
[79]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[80]
Barlow twins: Self-supervised learning via redundancy reduction,
J. Zbontar, L. Jing, I. Misra, Y . LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” inInternational Conference on Machine Learning (ICML), 2021, pp. 12 310–12 320
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.