Beyond Task Success: Behavioral and Representational Diagnostics for WAM and VLA
Pith reviewed 2026-06-28 17:19 UTC · model grok-4.3
The pith
WAMs improve object-level robot behavior and target selectivity over VLAs, but gains vary by architecture and raise inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
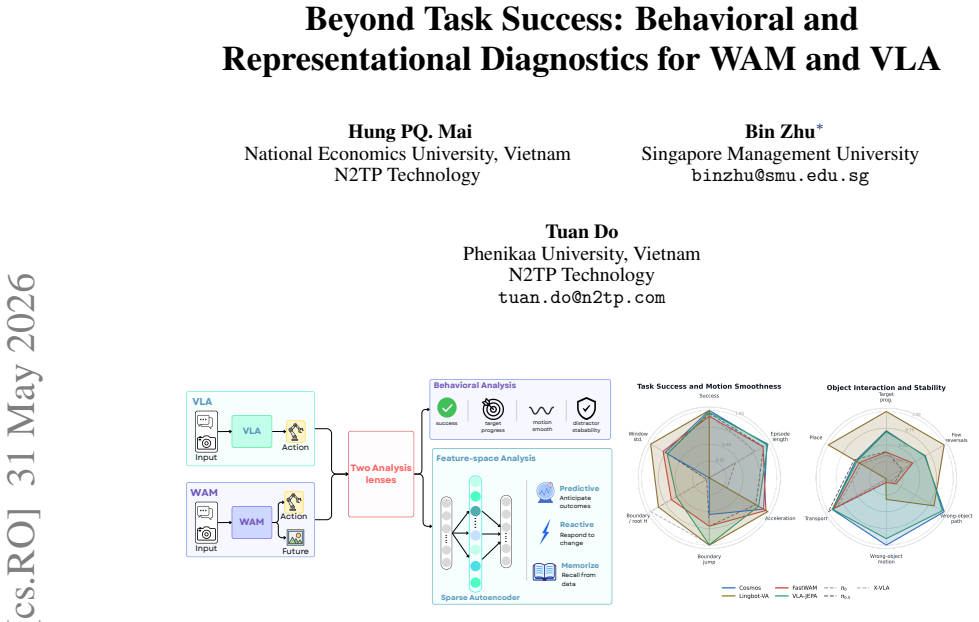
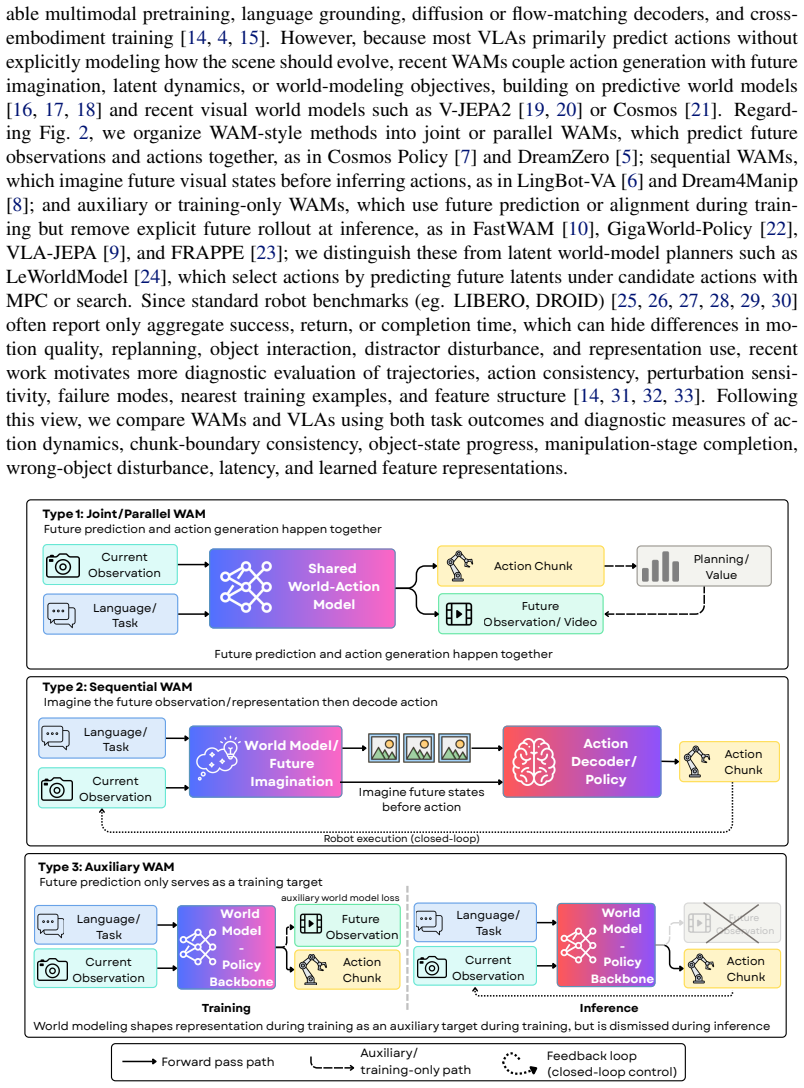
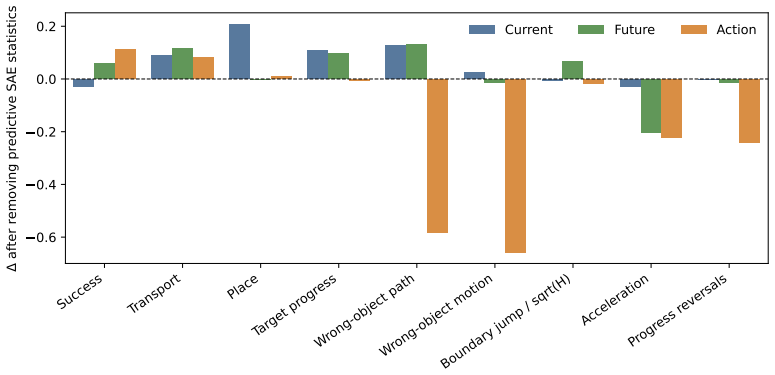
Success alone hides key differences: WAMs often improve object-level behavior and target selectivity, but their gains depend on architecture and incur higher inference cost. Sequential WAMs show the clearest predictive structure, while auxiliary and joint WAMs respectively compress or entangle future information.
What carries the argument
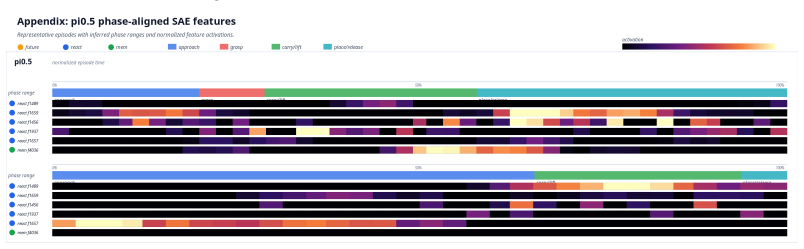
Model-agnostic diagnostic framework that pairs behavioral rollout analysis (action dynamics consistency, target-object progress, distractor disturbance, runtime cost) with sparse-autoencoder feature analysis that classifies representations as memorized, reactive, or predictive.
If this is right
- Sequential WAMs preserve the clearest future-oriented structure in their representations.
- Auxiliary WAMs tend to compress future information relative to direct prediction.
- Joint WAMs tend to entangle future information with current observations.
- WAM architectures improve object-level behavior and target selectivity compared with direct VLAs.
- All tested WAM variants incur higher inference cost than the corresponding VLAs.
Where Pith is reading between the lines
- Future WAM designs could prioritize sequential prediction to keep future representations behaviorally actionable while controlling compute cost.
- Policy evaluation suites should include the behavioral and representational diagnostics as standard checks rather than relying on success rate alone.
- The same diagnostic pair could be applied to test whether predictive representations improve robustness when object dynamics change mid-task.
Load-bearing premise
The chosen behavioral metrics and representation classifiers capture improvements that actually matter for control performance.
What would settle it
A head-to-head test in which a WAM and a VLA produce identical scores on action consistency, target progress, distractor resistance, and representation category yet still differ in final task success would falsify the claim that the diagnostics reveal control-relevant differences.
Figures



read the original abstract
Vision-language-action (VLA) policies and World-Action Models (WAM) represent two increasingly important paradigms for robotic manipulation. However, it remains unclear whether future prediction in WAMs leads to behaviorally meaningful improvements beyond final task success. In this paper, we ask whether WAMs merely add future prediction, or whether they change robot behavior and internal representations in ways that are actionable for control. We introduce a model-agnostic diagnostic framework that compares WAMs and VLAs through two complementary lenses: behavioral rollout analysis and sparse-autoencoder-based feature analysis. The behavioral protocol measures action dynamics consistency, target-object progress, distractor disturbance, and runtime cost. The feature-space protocol characterizes internal representations as memorized, reactive, or predictive, revealing whether models encode future-oriented structure. Across LIBERO and RoboTwin2.0, we evaluate 7 policies spanning direct VLAs and joint, sequential, and auxiliary WAMs. Our results show that success alone hides key differences: WAMs often improve object-level behavior and target selectivity, but their gains depend on architecture and incur higher inference cost. Sequential WAMs show the clearest predictive structure, while auxiliary and joint WAMs respectively compress or entangle future information. These findings suggest future directions for WAMs design to preserve behaviorally actionable future representations for efficient manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that task success rates alone obscure important differences between direct VLAs and three WAM variants (joint, sequential, auxiliary). It introduces a model-agnostic diagnostic framework consisting of a behavioral protocol (action-dynamics consistency, target-object progress, distractor disturbance, runtime cost) and a sparse-autoencoder feature protocol that classifies internal representations as memorized, reactive, or predictive. Experiments on LIBERO and RoboTwin2.0 across seven policies indicate that WAMs can improve object-level behavior and target selectivity in an architecture-dependent manner, that sequential WAMs exhibit the clearest predictive structure, and that auxiliary/joint variants respectively compress or entangle future information, albeit at higher inference cost.
Significance. If the two diagnostic protocols can be shown to track control-relevant quantities, the work supplies concrete, architecture-specific guidance for WAM design that goes beyond aggregate success rates. The explicit comparison of integration strategies and the use of sparse autoencoders to probe representational structure are potentially useful contributions to the VLA/WAM literature.
major comments (3)
- [Behavioral protocol (§3)] Behavioral protocol (abstract and §3): no correlation, ablation, or held-out validation is reported showing that action-dynamics consistency, target-object progress, or distractor disturbance scores predict downstream control quality, expert preference, or performance on unseen tasks. Without such evidence the claim that these metrics reveal 'behaviorally meaningful' and 'actionable for control' differences remains unanchored.
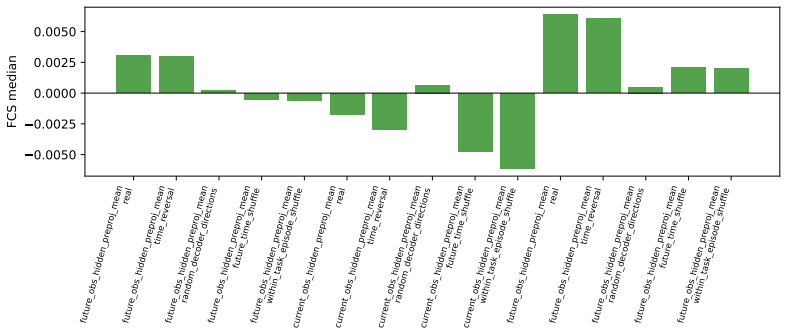
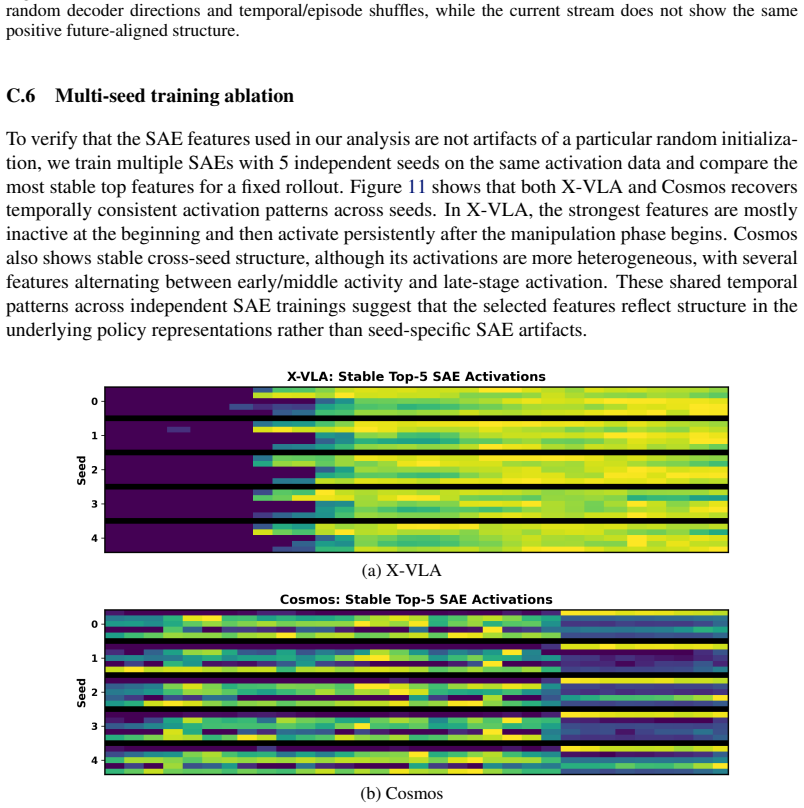
- [Feature-space protocol (§4)] Feature-space protocol (abstract and §4): the classification of representations into memorized/reactive/predictive categories via sparse autoencoders is presented without quantitative checks (e.g., reconstruction fidelity on future frames, causal intervention tests, or correlation with rollout metrics) that the categories correspond to control-relevant future information rather than dataset artifacts.
- [Results and discussion] Results interpretation (abstract): the statements that 'sequential WAMs show the clearest predictive structure' and that 'auxiliary and joint WAMs respectively compress or entangle future information' rest directly on the unvalidated protocols; if the protocols measure non-actionable quantities, these architecture-specific conclusions do not support design recommendations.
minor comments (2)
- [Methods] The abstract and methods should explicitly state the number of seeds, exact hyper-parameters of the sparse autoencoder, and the precise definition of each behavioral metric so that the protocols can be reproduced.
- [Behavioral protocol] Runtime cost is listed as a behavioral metric; it would be clearer to separate computational overhead from behavioral quality metrics in the presentation of results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the exploratory nature of the proposed diagnostics while acknowledging the need for stronger validation evidence.
read point-by-point responses
-
Referee: [Behavioral protocol (§3)] Behavioral protocol (abstract and §3): no correlation, ablation, or held-out validation is reported showing that action-dynamics consistency, target-object progress, or distractor disturbance scores predict downstream control quality, expert preference, or performance on unseen tasks. Without such evidence the claim that these metrics reveal 'behaviorally meaningful' and 'actionable for control' differences remains unanchored.
Authors: The behavioral metrics were designed from first principles of manipulation control to capture aspects such as action stability and target selectivity that success rates overlook. Experiments on LIBERO and RoboTwin2.0 demonstrate architecture-dependent patterns consistent with WAM design choices. We agree that explicit correlations or held-out ablations would provide stronger anchoring and will add a dedicated limitations subsection discussing validation strategies and potential extensions. revision: partial
-
Referee: [Feature-space protocol (§4)] Feature-space protocol (abstract and §4): the classification of representations into memorized/reactive/predictive categories via sparse autoencoders is presented without quantitative checks (e.g., reconstruction fidelity on future frames, causal intervention tests, or correlation with rollout metrics) that the categories correspond to control-relevant future information rather than dataset artifacts.
Authors: The SAE categorization relies on differential activation across temporal windows to distinguish feature types. While causal interventions and future-frame reconstruction checks are absent, the observed patterns align with both behavioral results and architectural priors. We will incorporate additional quantitative checks, such as future-frame reconstruction fidelity, into the revised feature analysis section. revision: partial
-
Referee: [Results and discussion] Results interpretation (abstract): the statements that 'sequential WAMs show the clearest predictive structure' and that 'auxiliary and joint WAMs respectively compress or entangle future information' rest directly on the unvalidated protocols; if the protocols measure non-actionable quantities, these architecture-specific conclusions do not support design recommendations.
Authors: These statements are presented as observations derived from the diagnostics rather than prescriptive design rules. We will revise the abstract and discussion to moderate the language, explicitly framing the findings as exploratory and noting that stronger validation is required before they inform concrete design choices. revision: yes
Circularity Check
No circularity: empirical protocols and external benchmarks
full rationale
The paper introduces behavioral and feature-space diagnostic protocols and applies them to evaluate existing VLA and WAM policies on LIBERO and RoboTwin2.0 benchmarks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All comparisons rest on independent external task success rates and model-agnostic analysis rather than quantities defined in terms of the paper's own outputs. The central claims therefore remain non-circular by the stated criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LIBERO and RoboTwin2.0 benchmarks are representative of real robotic manipulation challenges and suitable for measuring target selectivity and distractor effects.
- domain assumption Sparse autoencoder features can be meaningfully labeled as memorized, reactive, or predictive.
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[2]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky. π0: A Vision-Language-Action Flow Model for General Robot Control. InProceeding...
2025
-
[3]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, b. ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[4]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[5]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xi- ang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. J. Fan, and J. Jang. World action m...
2026
-
[6]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. In The F ourteenth International Conference on Learning Representations, 2026
2026
- [8]
-
[9]
J. Sun, W. Zhang, Z. Qi, S. Ren, Z. Liu, H. Zhu, G. Sun, X. Jin, and Z. Chen. Vla-jepa: Enhancing vision-language-action model with latent world model, 2026
2026
-
[10]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Zhang, Z
Z. Zhang, Z. Li, B. Rahmati, R. H. Yang, Y . Ma, A. Rasouli, S. Pakdamansavoji, Y . Wu, L. Zhang, T. Cao, F. Wen, X. Wang, X. Quan, and Y . Zhang. Do world action models generalize better than vlas? a robustness study, 2026. 10
2026
-
[12]
Huben, H
R. Huben, H. Cunningham, L. R. Smith, A. Ewart, and L. Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[13]
M. Lan, P. Torr, A. Meek, D. Krueger, and F. Barez. Sparse autoencoders reveal universal feature spaces across large language models, 2025
2025
-
[14]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
2024
-
[15]
Zheng, J
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, T. Wang, Y .-Q. Zhang, J. Liu, and X. Zhan. X-VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[16]
Ha and J
D. Ha and J. Schmidhuber. Recurrent world models facilitate policy evolution. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[17]
Bruce, M
J. Bruce, M. Dennis, A. Edwards, J. Parker-Holder, Y . J. Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, Y . Aytar, S. Bechtle, F. Behbahani, S. Chan, N. Heess, L. Gonzalez, S. Osindero, S. Ozair, S. Reed, J. Zhang, K. Zolna, J. Clune, N. De Freitas, S. Singh, and T. Rockt ¨aschel. Genie: generative interactive environments. InProceedings...
2024
-
[18]
Hafner, J
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
2025
-
[19]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. Robert Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas. V-jepa 2: Self- superv...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
L. Mur-Labadia, M. Muckley, A. Bar, M. Assran, K. Sinha, M. Rabbat, Y . LeCun, N. Ballas, and A. Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, M. Cao, P. Li, Q. Deng, W. Mei, X. Wang, X. Chen, X. Zhou, Y . Wang, Y . Chang, Y . Li, Y . Zhou, Y . Ye, Z. Liu, and Z. Zhu. Gigaworld-policy: An efficient action-centered world-action model.arXiv preprint arXiv:2603.17240, 2026
- [23]
-
[24]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end- to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. In5th Annual Conference on Robot Learning, 2021
2021
-
[26]
B. Liu, Y . Zhu, C. Gao, Y . Feng, qiang liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InThirty-seventh Conference on Neural Infor- mation Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[27]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
2025
-
[28]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Q. Liang, Z. Li, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[30]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid, B. Burgess-Limerick, B. Kim, B. Sch ¨olkopf,...
2024
-
[31]
Sparse Autoencoders Reveal Interpretable and Steerable Features in VLA Models
A. Swann, L. McGranahan, H. Buurmeijer, M. Kennedy III, and M. Schwager. Sparse autoencoders reveal interpretable and steerable features in vla models.arXiv preprint arXiv:2603.19183, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
J. Gao, S. Belkhale, S. Dasari, A. Balakrishna, D. Shah, and D. Sadigh. A taxonomy for evaluating generalist robot manipulation policies.IEEE Robotics and Automation Letters, 11 (3):3182–3189, 2026
2026
-
[33]
C. Agia, R. Sinha, J. Yang, Z. Cao, R. Antonova, M. Pavone, and J. Bohg. Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress. In8th Annual Conference on Robot Learning, 2024
2024
-
[34]
Black, M
K. Black, M. Y . Galliker, and S. Levine. Real-time execution of action chunking flow policies. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[35]
Gasparetto and V
A. Gasparetto and V . Zanotto. A new method for smooth trajectory planning of robot manipu- lators.Mechanism and Machine Theory, 42(4):455–471, 2007. ISSN 0094-114X
2007
-
[36]
Y . R. Wang, C. Ung, C. Tan, G. Tannert, J. Duan, J. Li, A. Le, R. Oswal, M. Grotz, W. Pumacay, Y . Deng, R. Krishna, D. Fox, and S. Srinivasa. Roboeval: Where robotic manipulation meets structured and scalable evaluation, 2026
2026
-
[37]
Buurmeijer, C
H. Buurmeijer, C. A. Alonso, A. Swann, and M. Pavone. Observing and controlling features in vision-language-action models, 2026
2026
-
[38]
M. A. Khan, N. Boskov, F. M. Anwar, and M. A. Khan. Controlling vision–language–action policies through sparse latent directions. InMechanistic Interpretability Workshop at NeurIPS 2025, 2025
2025
-
[39]
L. Gao, T. D. la Tour, H. Tillman, G. Goh, R. Troll, A. Radford, I. Sutskever, J. Leike, and J. Wu. Scaling and evaluating sparse autoencoders. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[40]
Cadene, S
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, D. Aubakirova, M. Shukor, J. Moss, A. Soare, Q. Lhoest, Q. Gallou´edec, and T. Wolf. Lerobot: An open-source library for end-to-end robot learning. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[41]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, Mojtaba, Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. R. Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas. V-jepa 2: Self-super...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.