Mixture of Debaters: Learn to Debate at Architectural Level in Multi-Agent Reasoning
Pith reviewed 2026-06-30 07:08 UTC · model grok-4.3
The pith
A single model can host dynamic debate among expert personas to outperform both single models and full multi-agent systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
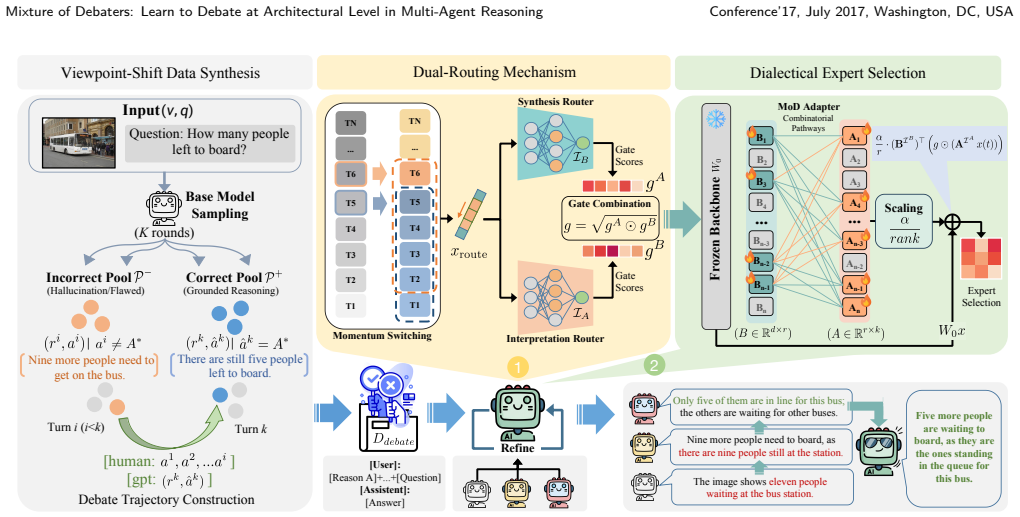
Mixture of Debaters (MoD) is a unified framework that enables dynamic self-debate within a single model by leveraging the Mixture-of-Experts paradigm. It solves three adaptation challenges for dialectical reasoning: dual-routing that decouples role allocation from process flow to decide when to debate versus synthesize, momentum switching that smooths token-level routing with local context to reduce expert-switch jitter, and unified self-debate that encapsulates diverse debating personas into lightweight expert modules, eliminating inter-agent communication while preserving behavioral diversity.
What carries the argument
Mixture of Debaters (MoD) framework adapting MoE via dual-routing, momentum switching, and unified self-debate to support intra-model dialectical reasoning.
If this is right
- Agent roles and coordination become dynamic at inference time instead of fixed at design time.
- Lightweight expert modules replace multiple full model instances, directly lowering compute and memory demands.
- Accuracy improves over both single-model baselines and standard multi-agent setups on multimodal tasks.
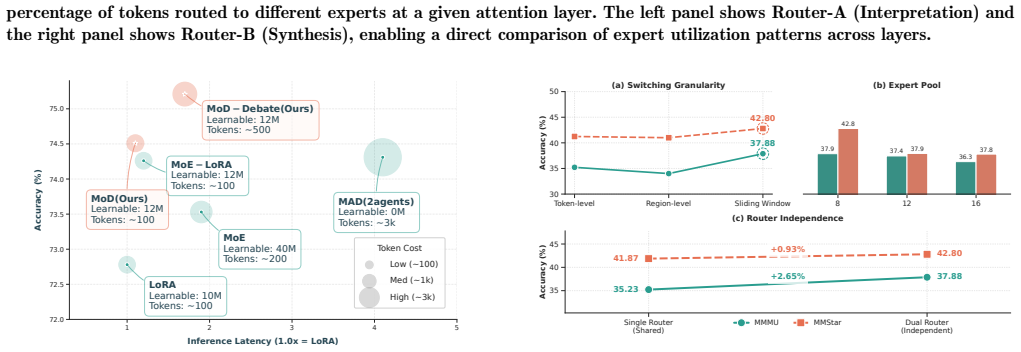
- Latency drops by a factor of 3.7 and token consumption drops by 87 percent while accuracy rises.
- Behavioral diversity is retained inside one model without any inter-agent messaging overhead.
Where Pith is reading between the lines
- The routing mechanisms could be tested on non-multimodal tasks such as pure text reasoning chains to check whether the efficiency gains transfer.
- Models trained with this architecture might allow debate-style reasoning at scales where running multiple separate agents is impractical.
- Similar intra-model routing could be applied to other collaborative patterns like multi-step planning or verification loops.
Load-bearing premise
Expert modules inside one model can successfully hold and switch among diverse debating personas without losing behavioral differences or requiring any communication between separate agents.
What would settle it
On the same multimodal benchmarks, MoD fails to exceed the accuracy of conventional multi-agent debate systems or uses more tokens or higher latency than those systems.
Figures


read the original abstract
Existing multi-agent debate frameworks suffer from two critical limitations: they rely on static architectures where agent roles and coordination patterns are fixed at design time, and they require instantiating multiple model copies, incurring substantial computational overhead. We propose Mixture of Debaters (MoD), a unified framework that enables dynamic self-debate within a single model by leveraging the Mixture-of-Experts paradigm. We address three key challenges in adapting MoE for dialectical reasoning: (1) dual-routing that decouples role allocation from process flow, dynamically determining when to debate versus when to synthesize; (2) momentum switching that smooths token-level routing with local context, reducing expert-switch jitter; and (3) unified self-debate that encapsulates diverse debating personas into lightweight expert modules, eliminating inter-agent communication while preserving behavioral diversity. Extensive experiments on multimodal benchmarks demonstrate that MoD outperforms both single-model baselines and conventional multi-agent systems, achieving superior accuracy with 3.7x lower latency and 87% reduction in token consumption.The source code can be accessed at https://github.com/YongLD/MoD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mixture of Debaters (MoD), an MoE-based architecture that enables dynamic self-debate inside a single model. It introduces dual-routing to separate role allocation from synthesis flow, momentum switching to stabilize token-level expert selection, and unified self-debate to embed multiple debating personas into lightweight experts, thereby avoiding the overhead of instantiating multiple agents. The central empirical claim is that MoD achieves higher accuracy than both single-model and conventional multi-agent baselines on multimodal benchmarks while delivering 3.7× lower latency and 87% token reduction.
Significance. If the empirical claims are substantiated with reproducible experiments, the work would be significant for efficient multi-agent reasoning: it offers a parameter-efficient route to role diversity without inter-agent communication or multiple model copies. The architectural mechanisms (dual-routing, momentum switching) are novel adaptations of MoE and could influence future designs of reasoning systems that require dialectical behavior.
major comments (3)
- [Abstract] Abstract: the performance claims (superior accuracy, 3.7× latency reduction, 87% token savings) are presented without any description of the multimodal benchmarks, the single-model or multi-agent baselines, dataset sizes, or statistical significance tests. This absence prevents assessment of whether the reported gains are load-bearing for the architectural contributions.
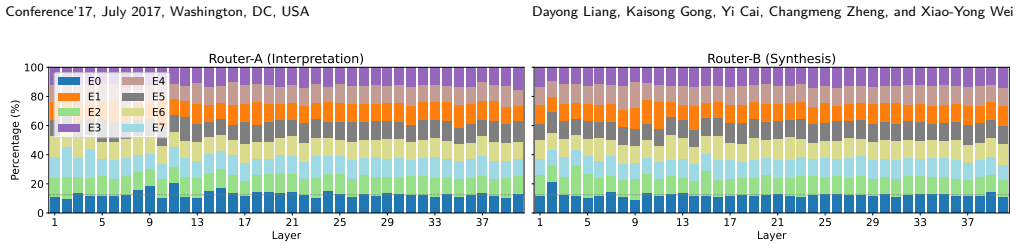
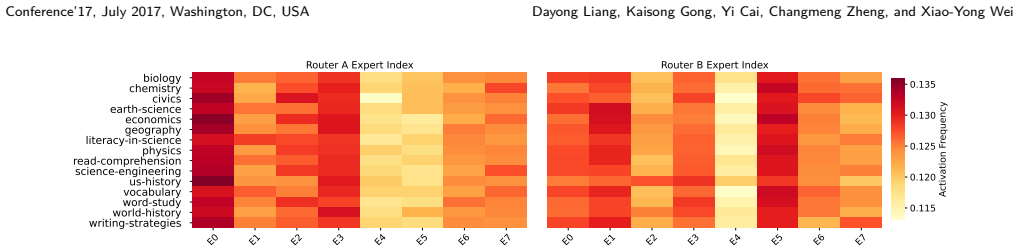
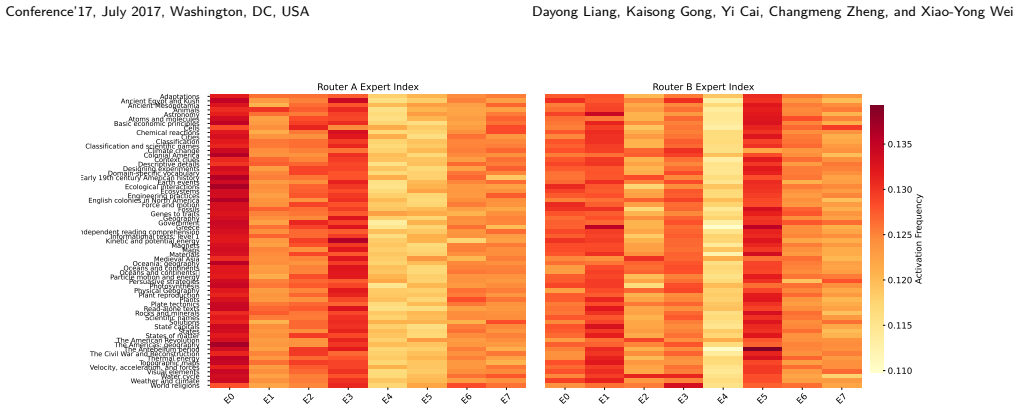
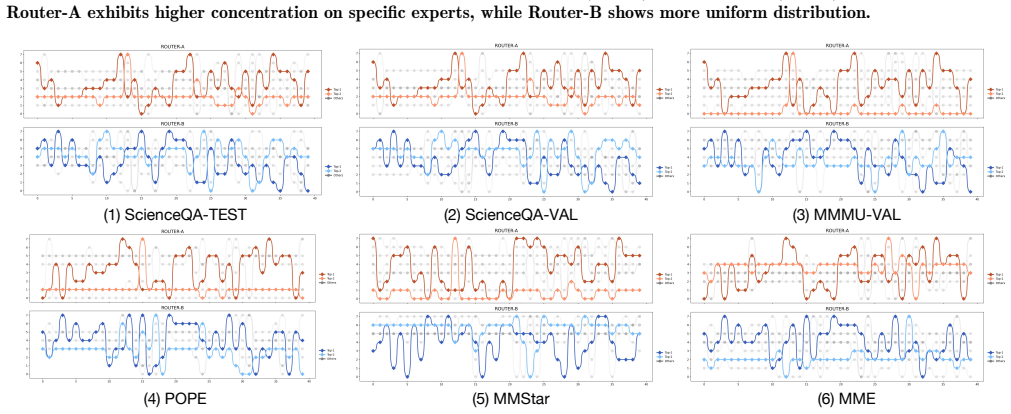
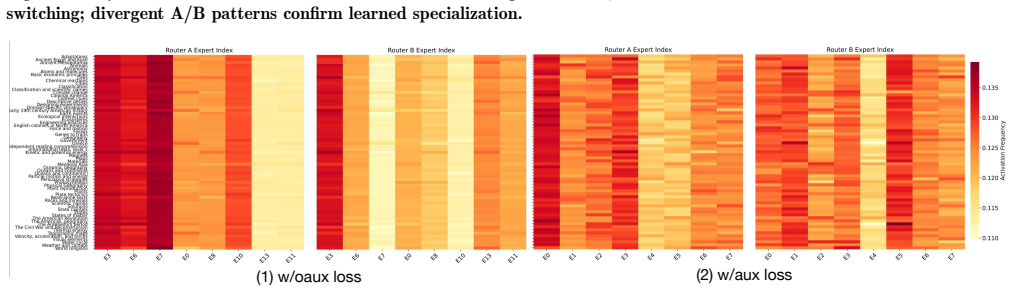
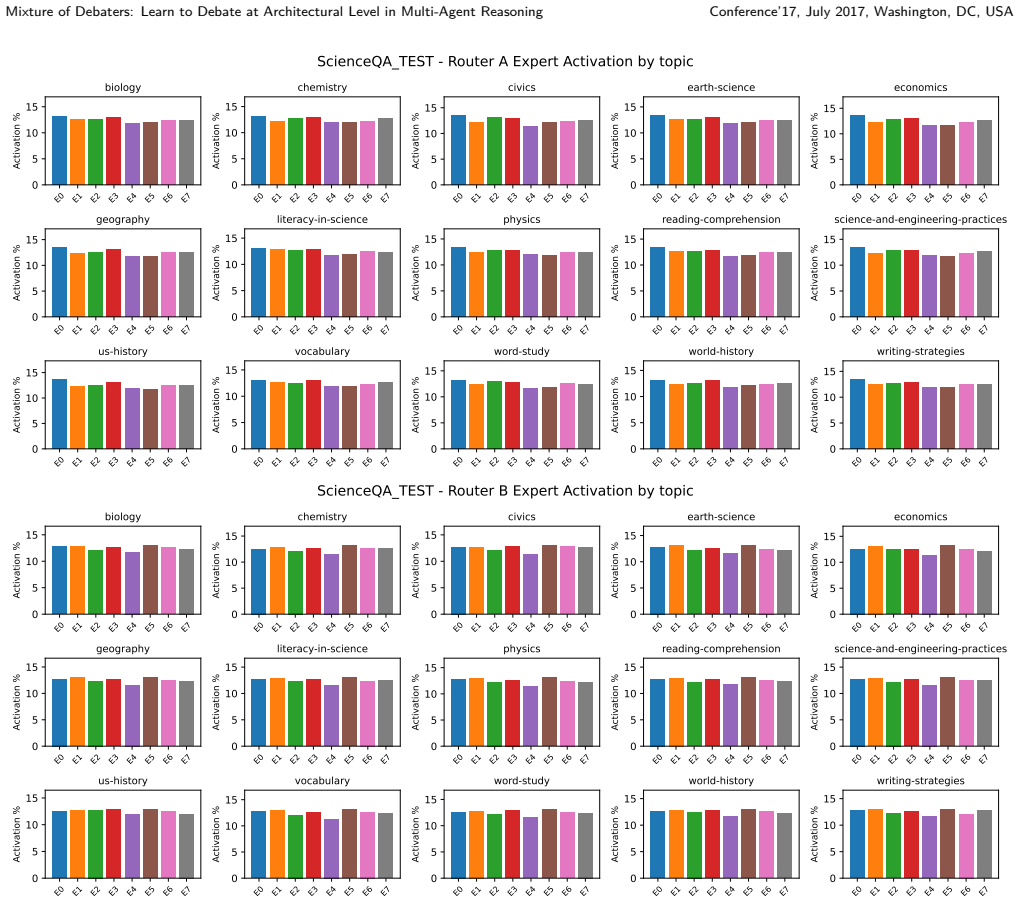
- [Abstract / §3 (unified self-debate)] The unified self-debate mechanism is asserted to preserve behavioral diversity among experts without inter-agent communication, yet no ablation, routing visualization, or diversity metric (e.g., expert activation histograms or response variance across roles) is referenced to demonstrate that specialization does not collapse. This assumption is central to the claim that MoD outperforms single-model MoE baselines.
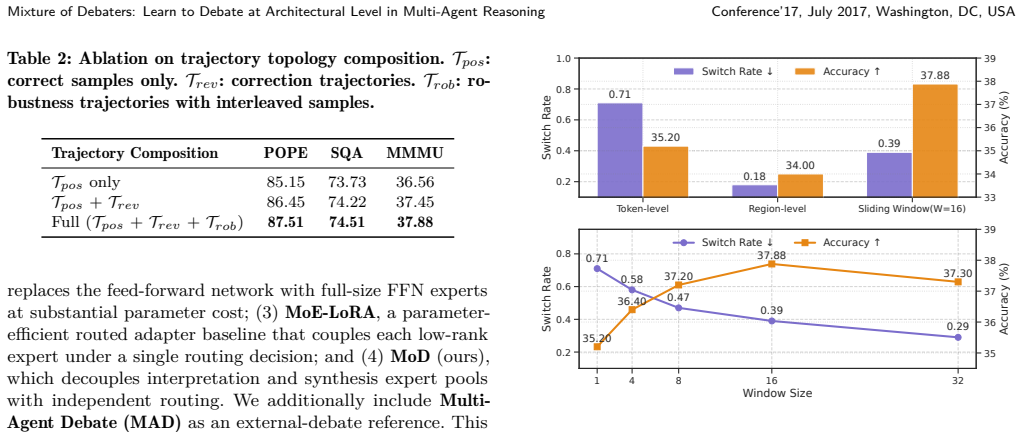
- [Abstract / §4] No equations or pseudocode are supplied for dual-routing or momentum switching; without these, it is impossible to verify that the mechanisms are distinct from standard MoE routing and that they actually decouple role allocation from process flow as claimed.
minor comments (1)
- [Abstract] The GitHub link is provided but no reproducibility checklist, hyperparameter tables, or seed information appears in the abstract.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight areas where the presentation of our work can be strengthened. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (superior accuracy, 3.7× latency reduction, 87% token savings) are presented without any description of the multimodal benchmarks, the single-model or multi-agent baselines, dataset sizes, or statistical significance tests. This absence prevents assessment of whether the reported gains are load-bearing for the architectural contributions.
Authors: We agree that the abstract lacks sufficient context for the empirical claims. In the revised manuscript, we will update the abstract to include brief descriptions of the multimodal benchmarks (e.g., MMMU and MathVista), the baselines compared (single-model MoE variants and multi-agent debate frameworks), and note that results include statistical significance via repeated runs with reported standard deviations in the main experiments section. revision: yes
-
Referee: [Abstract / §3 (unified self-debate)] The unified self-debate mechanism is asserted to preserve behavioral diversity among experts without inter-agent communication, yet no ablation, routing visualization, or diversity metric (e.g., expert activation histograms or response variance across roles) is referenced to demonstrate that specialization does not collapse. This assumption is central to the claim that MoD outperforms single-model MoE baselines.
Authors: Section 5 of the manuscript includes ablations on the unified self-debate and visualizations of expert routing that show distinct activation patterns for different debating roles. To better highlight this, we will add references to these analyses in the abstract and §3, along with a short description of the diversity metrics employed. revision: yes
-
Referee: [Abstract / §4] No equations or pseudocode are supplied for dual-routing or momentum switching; without these, it is impossible to verify that the mechanisms are distinct from standard MoE routing and that they actually decouple role allocation from process flow as claimed.
Authors: We will incorporate the formal equations and pseudocode for the dual-routing and momentum switching mechanisms into §4 of the revised manuscript. This will explicitly show how they extend standard MoE routing to achieve the claimed decoupling. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided manuscript text (abstract and description) introduces MoD as an architectural adaptation of MoE with three conceptual mechanisms (dual-routing, momentum switching, unified self-debate) but contains no equations, parameter-fitting steps, predictions of derived quantities, or self-citations that bear the central claim. Experimental superiority is asserted via benchmark results rather than any reduction of the architecture to its own inputs by construction. This matches the default expectation of a non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.129661, 2 (2023), 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Xiaohe Bo, Zeyu Zhang, Quanyu Dai, Xueyang Feng, Lei Wang, Rui Li, Xu Chen, and Ji-Rong Wen. 2024. Reflective multi-agent collaboration based on large language models.Advances in Neural Information Processing Systems37 (2024), 138595–138631
2024
-
[3]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. 2024. ShareGPT4V: Improving Large Multi-Modal Models with Better Captions. InEuropean Conference on Computer Vision. Springer Nature Switzerland, Cham, Switzerland, 370–387
2024
-
[4]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. 2024. Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems37 (2024), 27056–27087
2024
-
[5]
Tianlong Chen, Xuxi Chen, Xianzhi Du, Abdullah Rashwan, Fan Yang, Huizhong Chen, Zhangyang Wang, and Yeqing Li. 2023. AdamV-MoE: Adaptive Multi-Task Vision Mixture-of-Experts. InProceedings of the IEEE/CVF International Conference on Computer Vision. IEEE, Paris, France, 17346–17357
2023
- [6]
-
[7]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems36 (2023), 49250–49267
2023
-
[8]
Aniket Didolkar, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy Lillicrap, Danilo Jimenez Rezende, Yoshua Bengio, Michael C Mozer, and Sanjeev Arora. 2024. Metacognitive capabilities of llms: An exploration in mathematical problem solving.Advances in Neural Information Processing Systems37 (2024), 19783–19812
2024
- [9]
- [10]
-
[11]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. 2023. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models. arXiv:2306.13394 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Chongyang Gao, Kezhen Chen, Jinmeng Rao, Ruibo Liu, Baochen Sun, Yawen Zhang, Daiyi Peng, Xiaoyuan Guo, and V. S. Sub- rahmanian. 2025. MoLA: MoE LoRA with Layer-Wise Expert Allocation. InFindings of the Association for Computational Linguistics: NAACL 2025. Association for Computational Lin- guistics, Albuquerque, New Mexico, USA, 5097–5112
2025
-
[13]
Fung, and Heng Ji
Jiayi He, Hehai Lin, Qingyun Wang, Yi R. Fung, and Heng Ji
-
[14]
InFindings of the Association for Computational Linguistics: ACL 2025
Self-Correction Is More Than Refinement: A Learning Framework for Visual and Language Reasoning Tasks. InFindings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, Vienna, Austria, 6405– 6421
2025
-
[15]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mas- sive Multitask Language Understanding. arXiv:2009.03300 [cs.CY] Published as a conference paper at ICLR 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[17]
Wentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing Li. 2025. Removal of Hallucination on Hallucination: Debate-Augmented RAG. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Austria, 15839–15853
2025
-
[18]
Vu, Maanak Gupta, Mahmoud Ab- delsalam, and Manish Bhattarai
Pradip Kunwar, Minh N. Vu, Maanak Gupta, Mahmoud Ab- delsalam, and Manish Bhattarai. 2025. TT-LoRA MoE: Using Parameter-Efficient Fine-Tuning and Sparse Mixture-of-Experts. InProceedings of the International Conference for High Perfor- mance Computing, Networking, Storage and Analysis. Associa- tion for Computing Machinery, New York, NY, USA, 1332–1350
2025
-
[19]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Conference’17, July 2017, Washington, DC, USA Dayong Liang, Kaisong Gong, Yi Cai, Changmeng Zheng, and Xiao-Yong Wei Shazeer, and Zhifeng Chen. 2021. GShard: Scaling Giant Mod- els with Conditional Computation and Automatic Sharding. arXiv:2006.16668 ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [20]
-
[21]
Dawei Li, Zhen Tan, Peijia Qian, Yifan Li, Kumar Satvik Chaud- hary, Lijie Hu, and Jiayi Shen. 2025. SMoA: Improving Multi- Agent Large Language Models with Sparse Mixture-of-Agents. InPacific-Asia Conference on Knowledge Discovery and Data Mining. Springer Nature Singapore, Singapore, 54–65
2025
-
[22]
Haoran Li, Ziyi Su, Yun Xue, Zhiliang Tian, Yiping Song, and Minlie Huang. 2025. Advancing Collaborative Debates with Role Differentiation through Multi-Agent Reinforcement Learning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Austria...
2025
-
[23]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023. Evaluating Object Hallucination in Large Vision-Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 292–305
2023
- [24]
-
[25]
Dayong Liang, Xiao-Yong Wei, and Changmeng Zheng
-
[26]
Multi-Agent Undercover Gaming: Hallucination Re- moval via Counterfactual Test for Multimodal Reasoning. arXiv:2511.11182 [cs.CV]
-
[27]
Dayong Liang, Xiao-Yong Wei, and Changmeng Zheng. 2026. Multi-Agent Undercover Gaming: Hallucination Removal Through Counterfactual Test for Multimodal Reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. AAAI Press, Palo Alto, CA, USA, 6807–6815
2026
- [28]
-
[29]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. En- couraging Divergent Thinking in Large Language Models through Multi-Agent Debate. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Associa- tion for Computational Linguistics, Miami, Florida, USA...
2024
-
[30]
Bin Lin, Zhenyu Tang, Yang Ye, Jinfa Huang, Junwu Zhang, Yatian Pang, Peng Jin, Munan Ning, Jiebo Luo, and Li Yuan
-
[31]
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models. arXiv:2401.15947 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge. https://llava-vl.github. io/blog/2024-01-30-llava-next/
2024
-
[33]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction Tuning. arXiv:2304.08485 [cs.CV] NeurIPS 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [34]
-
[35]
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan
-
[36]
arXiv:2209.09513 [cs.CL] NeurIPS 2022
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. arXiv:2209.09513 [cs.CL] NeurIPS 2022
-
[37]
Ruotian Ma, Peisong Wang, Cheng Liu, Xingyan Liu, Jiaqi Chen, Bang Zhang, Xin Zhou, Nan Du, and Jia Li. 2025. S2R: Teaching LLMs to Self-Verify and Self-Correct via Reinforcement Learning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Au...
2025
-
[38]
Qi Peng, Jiatong Li, Sirui Huang, Yiyang Jiang, Kaisong Gong, Ronger Ding, Shijie Ye, Xiao-Yong Wei, Changmeng Zheng, and Qing Li. 2025. Aligning Clinical Needs and AI Capabilities: A Survey on LLMs for Medical Reasoning. TechRxiv preprint
2025
-
[39]
Seals and Valerie L
Spencer M. Seals and Valerie L. Shalin. 2024. Evaluating the Deductive Competence of Large Language Models. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Papers). Association for Computational Linguistics, Mexico City, Mexico, 8614–8630
2024
-
[40]
Tenenbaum, Anto- nio Torralba, Shuang Li, and Igor Mordatch
Vighnesh Subramaniam, Yilun Du, Joshua B. Tenenbaum, Anto- nio Torralba, Shuang Li, and Igor Mordatch. 2025. Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains. arXiv:2501.05707 [cs.LG]
- [41]
- [42]
- [43]
-
[44]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovi- cova, Alexandre Ramé, Morgane Rivière, et al. 2025. Gemma 3 technical report.arXiv preprint arXiv:2503.19786(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
-
[47]
Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[48]
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. 2024. Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al
-
[50]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain- of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[52]
Chung-En Johnny Yu, Brian Jalaian, and Nathaniel D Bastian
-
[53]
InProceedings of the AAAI Symposium Series, Vol
Mitigating Large Vision-Language Model Hallucination at Post-hoc via Multi-agent System. InProceedings of the AAAI Symposium Series, Vol. 4. 110–113
-
[54]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. 2024. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9556–9567
2024
-
[55]
Dacao Zhang, Kun Zhang, Shimao Chu, Le Wu, Xin Li, and Si Wei. 2025. More: A mixture of low-rank experts for adaptive multi- task learning. InFindings of the Association for Computational Linguistics: ACL 2025. 1311–1324
2025
-
[56]
Kaiyuan Zhang, Qian Liu, Luyang Zhang, Chaoqun Zheng, Shuaimin Li, Bing Xu, Muyun Yang, Xinxiao Qiao, and Wen- peng Lu. 2025. MADAWSD: Multi-Agent Debate Framework for Adversarial Word Sense Disambiguation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 22294–22313
2025
- [57]
-
[58]
2025.Learning Versatile Multimodal Rep- resentation for Knowledge Extraction and Reasoning
Changmeng Zheng. 2025.Learning Versatile Multimodal Rep- resentation for Knowledge Extraction and Reasoning. Ph.D. Dissertation. The Hong Kong Polytechnic University
2025
-
[59]
2026.Multimodal Knowledge Systems: Construction and Reasoning
Changmeng Zheng and Qing Li. 2026.Multimodal Knowledge Systems: Construction and Reasoning. Springer Nature
2026
-
[60]
Changmeng Zheng, Dayong Liang, Wengyu Zhang, Xiao-Yong Wei, Tat-Seng Chua, and Qing Li. 2024. A picture is worth a Mixture of Debaters: Learn to Debate at Architectural Level in Multi-Agent Reasoning Conference’17, July 2017, Washington, DC, USA graph: A blueprint debate paradigm for multimodal reasoning. InProceedings of the 32nd ACM International Confer...
2024
-
[61]
Xiaofeng Zhou, He-Yan Huang, and Lizi Liao. 2025. Debate, reflect, and distill: Multi-agent feedback with tree-structured preference optimization for efficient language model enhancement. InFindings of the Association for Computational Linguistics: ACL 2025. 9122–9137
2025
-
[62]
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al
-
[63]
Review the following responses from other assistants and determine your final answer
Mixture-of-experts with expert choice routing.Advances in Neural Information Processing Systems35 (2022), 7103–7114. A Algorithm Algorithm 1 presents the complete forward pass of a specific MoD layer, including dual-routing, Momentum Switching via sliding window, and gating score combination. Algorithm 1Mixture-of-Debaters Layer Forward Pass Require: Inpu...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.