Empowering GUI Agents via Autonomous Experience Exploration and Hindsight Experience Utilization for Task Planning
Pith reviewed 2026-06-26 03:47 UTC · model grok-4.3
The pith
Autonomous exploration and hindsight high-level synthesis lets 7B MLLMs outperform 32B models on GUI planning
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
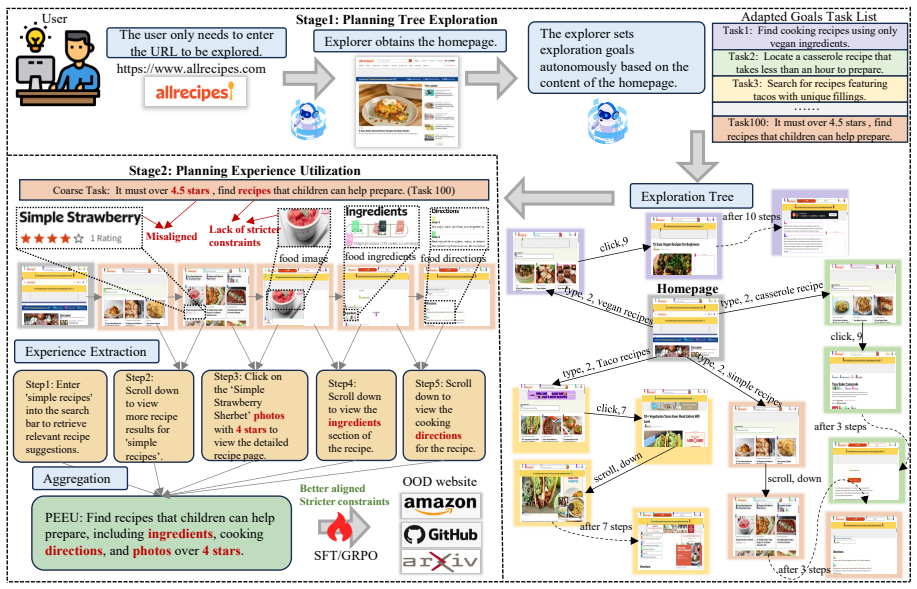
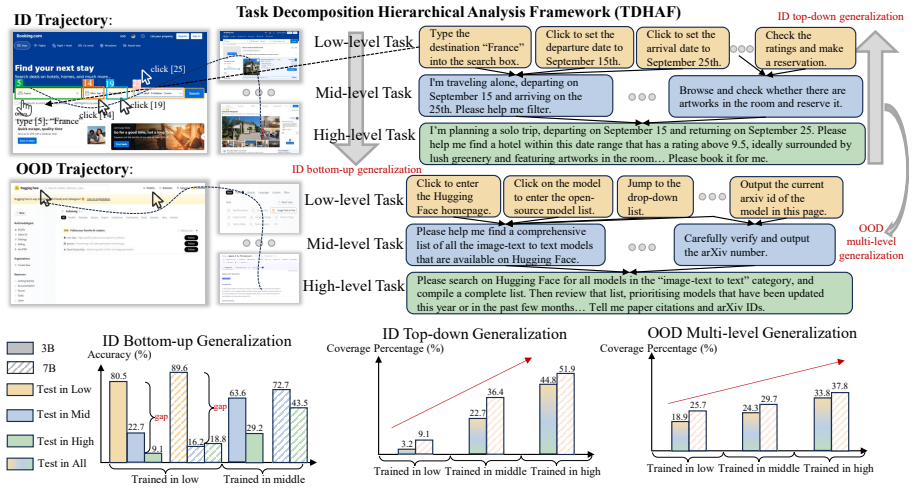
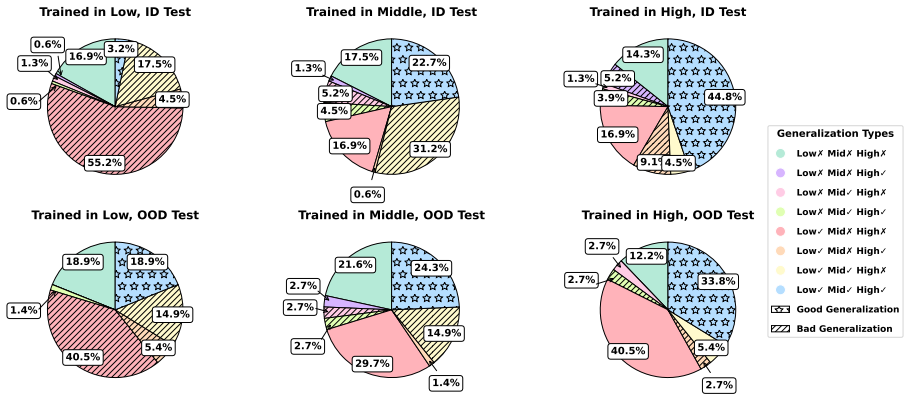
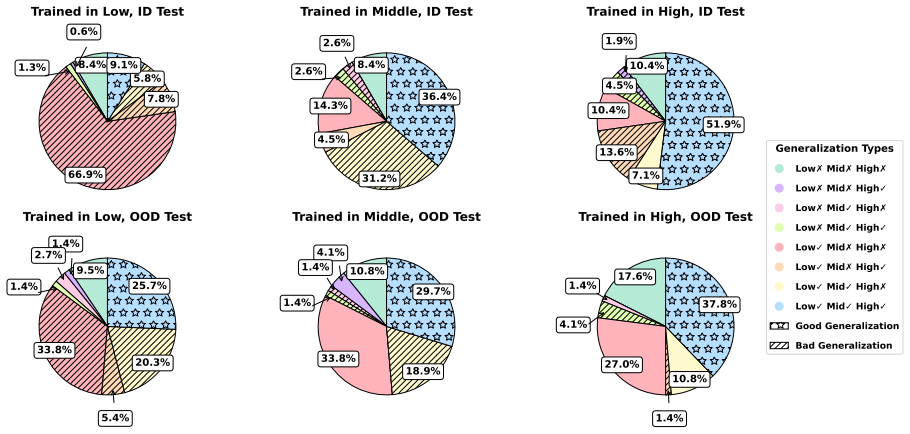
The PEEU method autonomously explores environments to discover experiences and utilizes hindsight to synthesize strictly aligned high-level training data, enabling small 7B MLLMs to achieve superior out-of-distribution task planning with 30.6 percent accuracy that exceeds the much larger Qwen2.5-VL-32B model; TDHAF analysis further shows that high-level task training yields stronger compositional generalization across granularities while low-level atomic skills alone do not guarantee high-level planning competence.
What carries the argument
The PEEU method (planning experience exploration and utilization), which combines autonomous environment exploration for experience discovery with hindsight experience utilization to generate high-level training data.
If this is right
- Mastering low-level atomic skills does not guarantee high-level planning competence.
- High-level task training yields stronger out-of-distribution generalization than training at lower granularities.
- Small MLLMs can surpass much larger models on real-world GUI benchmarks when trained with hindsight high-level tasks.
- Constructing hindsight high-level tasks is crucial for out-of-distribution planning abilities of small MLLMs.
Where Pith is reading between the lines
- The same exploration-plus-hindsight pattern could transfer to non-web GUI environments or robotic control tasks that require long-horizon decomposition.
- Combining PEEU data synthesis with existing reinforcement learning loops might further reduce the need for human-labeled demonstrations.
- Applying the method to models below 7B parameters would test whether the performance lift scales down or saturates.
Load-bearing premise
Autonomously exploring environments and synthesizing hindsight experience produces strictly aligned high-level training data that improves cross-website generalization in small MLLMs.
What would settle it
A controlled experiment in which models trained solely on low-level atomic tasks achieve accuracy on unseen websites equal to or higher than models trained with the synthesized high-level hindsight data.
Figures

read the original abstract
Multimodal web agents can assist humans in operating repetitive GUI tasks, where effective task planning is essential for decomposing complex tasks into executable actions. While small open source MLLMs are cost efficient and privacy preserving compared with commercial large models, they suffer from weak planning and limited cross website generalization. To address these limitations, we introduce the planning experience exploration and utilization (PEEU) method, which autonomously explores environments to discover experiences and utilizes hindsight experience to synthesize strictly aligned, high level training data. To quantitatively analyze the generalization behaviors driving this performance, we propose the task decomposition hierarchical analysis framework (TDHAF) to systematically study compositional generalization across three task granularities: low, middle and high levels. Our analysis reveals that mastering low level atomic skills does not guarantee high level planning competence, while high level task training yields stronger OOD generalization. Experiments on real world benchmarks demonstrate PEEU's superior effectiveness: our 7B model achieves 30.6% accuracy, outperforming the much larger Qwen2.5-VL-32B model. These demonstrate constructing hindsight high level tasks and leveraging experiences is crucial for OOD planning abilities of small MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PEEU method, which uses autonomous environment exploration and hindsight experience utilization to synthesize strictly aligned high-level training data for small MLLMs in GUI task planning. It proposes the TDHAF framework to analyze compositional generalization across low-, middle-, and high-level task granularities, finding that low-level skill mastery does not ensure high-level planning competence while high-level training improves OOD generalization. Experiments on real-world benchmarks report that a 7B model reaches 30.6% accuracy, outperforming Qwen2.5-VL-32B, concluding that hindsight high-level task construction is crucial for OOD planning in small MLLMs.
Significance. If the experimental claims and alignment validation hold, the work would be significant for demonstrating that targeted synthesis of high-level tasks via hindsight can close the planning gap for efficient, open-source small MLLMs in web agents, reducing reliance on larger proprietary models while providing a framework (TDHAF) for dissecting generalization at different granularities.
major comments (3)
- [Abstract] Abstract: The central performance claim (7B model at 30.6% accuracy outperforming Qwen2.5-VL-32B) and the TDHAF conclusion that high-level task training drives OOD gains are load-bearing but rest on synthesized data being 'strictly aligned'; no quantitative validation (e.g., consistency metrics, human evaluation of decomposition fidelity, or error rates on cross-website tasks) is described to confirm that hindsight synthesis avoids low-level leakage or semantic misalignment.
- [Abstract] Abstract (experimental results paragraph): The headline accuracy and comparison are presented without any mention of experimental protocol, baselines, error bars, dataset splits, number of websites/tasks, or verification that the autonomously explored data matches intended high-level semantics; this prevents assessment of whether the reported OOD gains follow from the method.
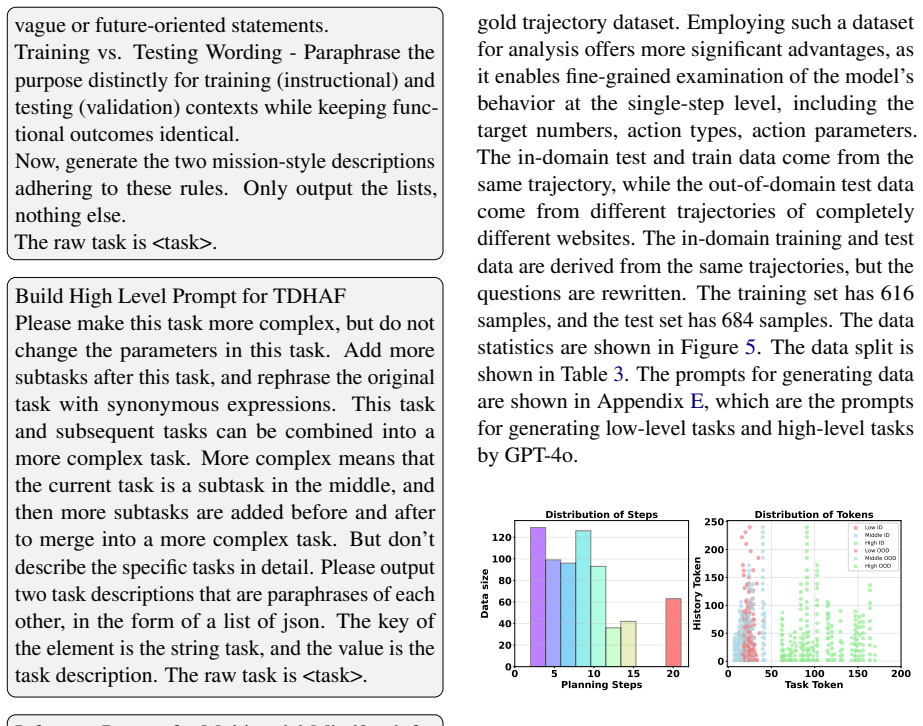
- [Abstract] Abstract (TDHAF description): The claim that 'mastering low level atomic skills does not guarantee high level planning competence' while 'high level task training yields stronger OOD generalization' is presented as a key insight, yet the analysis framework itself is only named without details on how the three granularity levels are operationalized or how the synthesized data is partitioned for the study.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract would benefit from additional details to better contextualize the claims. We will revise the abstract in the next version while preserving its length constraints. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim (7B model at 30.6% accuracy outperforming Qwen2.5-VL-32B) and the TDHAF conclusion that high-level task training drives OOD gains are load-bearing but rest on synthesized data being 'strictly aligned'; no quantitative validation (e.g., consistency metrics, human evaluation of decomposition fidelity, or error rates on cross-website tasks) is described to confirm that hindsight synthesis avoids low-level leakage or semantic misalignment.
Authors: We agree that the abstract does not describe quantitative validation of alignment. The main text details the hindsight synthesis mechanism but does not report the specific metrics suggested (e.g., human evaluation scores or consistency rates). We will revise the manuscript to add such validation and update the abstract to reference the alignment checks. revision: yes
-
Referee: [Abstract] Abstract (experimental results paragraph): The headline accuracy and comparison are presented without any mention of experimental protocol, baselines, error bars, dataset splits, number of websites/tasks, or verification that the autonomously explored data matches intended high-level semantics; this prevents assessment of whether the reported OOD gains follow from the method.
Authors: The abstract summarizes results at a high level. Full details on the protocol, baselines, error bars (from multiple runs), dataset splits, number of websites and tasks, and semantic verification are provided in the Experiments section. We will revise the abstract to include a brief mention of the evaluation scale and protocol. revision: yes
-
Referee: [Abstract] Abstract (TDHAF description): The claim that 'mastering low level atomic skills does not guarantee high level planning competence' while 'high level task training yields stronger OOD generalization' is presented as a key insight, yet the analysis framework itself is only named without details on how the three granularity levels are operationalized or how the synthesized data is partitioned for the study.
Authors: The TDHAF framework and its operationalization of the three granularity levels, along with data partitioning, are described in the main text. We will revise the abstract to add a short clause summarizing how the levels are defined. revision: yes
Circularity Check
No circularity; empirical method and benchmark results are self-contained.
full rationale
The paper describes an empirical pipeline (PEEU for autonomous exploration and hindsight synthesis of high-level tasks, plus TDHAF for analyzing task granularities) whose central claims rest on reported benchmark accuracies (e.g., 7B model at 30.6%). No equations, parameter-fitting steps, self-definitional loops, or load-bearing self-citations appear in the abstract or described claims. The performance and generalization conclusions are presented as outcomes of experiments rather than reductions to inputs by construction. This matches the default case of a non-circular empirical ML paper whose results are externally falsifiable via replication on the cited benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2507.02592 , year=
WebSailor: Navigating Super-human Reasoning for Web Agent , author=. arXiv preprint arXiv:2507.02592 , year=
-
[2]
arXiv preprint arXiv:2507.15061 , year=
Webshaper: Agentically data synthesizing via information-seeking formalization , author=. arXiv preprint arXiv:2507.15061 , year=
-
[3]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Unlocking the future: Exploring look-ahead planning mechanistic interpretability in large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[4]
arXiv preprint arXiv:2508.05748 , year=
WebWatcher: Breaking New Frontiers of Vision-Language Deep Research Agent , author=. arXiv preprint arXiv:2508.05748 , year=
-
[5]
arXiv preprint arXiv:2507.06229 , year=
Agent kb: Leveraging cross-domain experience for agentic problem solving , author=. arXiv preprint arXiv:2507.06229 , year=
-
[6]
Preprint , year=
Memento: Fine-tuning llm agents without fine-tuning llms , author=. Preprint , year=
-
[7]
Second Conference on Language Modeling , year=
Scaling Web Agent Training through Automatic Data Generation and Fine-grained Evaluation , author=. Second Conference on Language Modeling , year=
-
[8]
arXiv preprint arXiv:2503.21620 , year=
UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning , author=. arXiv preprint arXiv:2503.21620 , year=
-
[9]
arXiv preprint arXiv:2504.10458 , year=
Gui-r1: A generalist r1-style vision-language action model for gui agents , author=. arXiv preprint arXiv:2504.10458 , year=
-
[10]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
A survey of webagents: Towards next-generation ai agents for web automation with large foundation models , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[11]
arXiv preprint arXiv:2504.13865 , year=
A survey on (m) llm-based gui agents , author=. arXiv preprint arXiv:2504.13865 , year=
-
[12]
arXiv preprint arXiv:2411.04890 , year=
Gui agents with foundation models: A comprehensive survey , author=. arXiv preprint arXiv:2411.04890 , year=
-
[13]
arXiv preprint arXiv:2505.19683 , year=
Large language models for planning: A comprehensive and systematic survey , author=. arXiv preprint arXiv:2505.19683 , year=
-
[14]
arXiv preprint arXiv:2505.04921 , year=
Perception, reason, think, and plan: A survey on large multimodal reasoning models , author=. arXiv preprint arXiv:2505.04921 , year=
-
[15]
arXiv preprint arXiv:2502.11221 , year=
Plangenllms: A modern survey of llm planning capabilities , author=. arXiv preprint arXiv:2502.11221 , year=
-
[16]
arXiv preprint arXiv:2401.13919 , year=
Webvoyager: Building an end-to-end web agent with large multimodal models , author=. arXiv preprint arXiv:2401.13919 , year=
-
[17]
arXiv preprint arXiv:2506.02153 , year=
Small Language Models are the Future of Agentic AI , author=. arXiv preprint arXiv:2506.02153 , year=
-
[18]
Google AI , volume=
Welcome to the era of experience , author=. Google AI , volume=
-
[19]
arXiv preprint arXiv:2508.19005 , year=
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark , author=. arXiv preprint arXiv:2508.19005 , year=
-
[20]
arXiv preprint arXiv:2509.02547 , year=
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey , author=. arXiv preprint arXiv:2509.02547 , year=
-
[21]
arXiv preprint arXiv:2411.06559 , year=
Is your llm secretly a world model of the internet? model-based planning for web agents , author=. arXiv preprint arXiv:2411.06559 , year=
-
[22]
arXiv preprint arXiv:2501.13896 , year=
Gui-bee: Align gui action grounding to novel environments via autonomous exploration , author=. arXiv preprint arXiv:2501.13896 , year=
-
[23]
International Conference on Learning Representations (ICLR) , year=
React: Synergizing reasoning and acting in language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[24]
Forty-first International Conference on Machine Learning , year=
GPT-4V(ision) is a Generalist Web Agent, if Grounded , author=. Forty-first International Conference on Machine Learning , year=
-
[25]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Mind2Web: Towards a Generalist Agent for the Web , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[26]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A Troublemaker with Contagious Jailbreak Makes Chaos in Honest Towns , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
arXiv preprint arXiv:2403.13372 , year=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. arXiv preprint arXiv:2403.13372 , year=
-
[28]
EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework , author =
-
[29]
arXiv preprint arXiv:2506.18959 , year=
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents , author=. arXiv preprint arXiv:2506.18959 , year=
-
[30]
arXiv preprint arXiv:2507.09477 , year=
Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs , author=. arXiv preprint arXiv:2507.09477 , year=
-
[31]
Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents, 2025 , author=. URL https://arxiv. org/abs/2505.15810 , volume=
arXiv 2025
-
[32]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[33]
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
Reimers, Nils and Gurevych, Iryna. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. 2020
2020
-
[34]
arXiv preprint arXiv:2505.19406 , year=
Unveiling the Compositional Ability Gap in Vision-Language Reasoning Model , author=. arXiv preprint arXiv:2505.19406 , year=
-
[35]
2013 , publisher=
The architecture of cognition , author=. 2013 , publisher=
2013
-
[36]
Proceedings: Case-based reasoning workshop , pages=
Some psychological results on case-based reasoning , author=. Proceedings: Case-based reasoning workshop , pages=. 1989 , organization=
1989
-
[37]
arXiv preprint arXiv:2502.06776 , year=
InSTA: Towards Internet-Scale Training For Agents , author=. arXiv preprint arXiv:2502.06776 , year=
-
[38]
arXiv preprint arXiv:2409.07429 , year=
Agent workflow memory , author=. arXiv preprint arXiv:2409.07429 , year=
-
[39]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[40]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[41]
2024 , month = mar, day =
Anthropic , title =. 2024 , month = mar, day =
2024
-
[42]
arXiv preprint arXiv:2508.06433 , year=
Memp: Exploring agent procedural memory , author=. arXiv preprint arXiv:2508.06433 , year=
-
[43]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Gui agents: A survey , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[44]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Agent-rewardbench: Towards a unified benchmark for reward modeling across perception, planning, and safety in real-world multimodal agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[45]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Rag-rewardbench: Benchmarking reward models in retrieval augmented generation for preference alignment , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[46]
arXiv preprint arXiv:2510.18596 , year=
Cuarewardbench: A benchmark for evaluating reward models on computer-using agent , author=. arXiv preprint arXiv:2510.18596 , year=
-
[47]
arXiv preprint arXiv:2501.10893 , year=
Learn-by-interact: A data-centric framework for self-adaptive agents in realistic environments , author=. arXiv preprint arXiv:2501.10893 , year=
-
[48]
Forty-second International Conference on Machine Learning , year=
Proposer-agent-evaluator (pae): Autonomous skill discovery for foundation model internet agents , author=. Forty-second International Conference on Machine Learning , year=
-
[49]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
arXiv preprint arXiv:2512.13564 , year=
Memory in the age of ai agents , author=. arXiv preprint arXiv:2512.13564 , year=
-
[51]
arXiv preprint arXiv:2602.08234 , year=
Skillrl: Evolving agents via recursive skill-augmented reinforcement learning , author=. arXiv preprint arXiv:2602.08234 , year=
-
[52]
arXiv preprint arXiv:2606.12191 , year=
Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application , author=. arXiv preprint arXiv:2606.12191 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.