Scaffold Effects on GAIA: A Controlled Comparison
Pith reviewed 2026-06-27 18:25 UTC · model grok-4.3
The pith
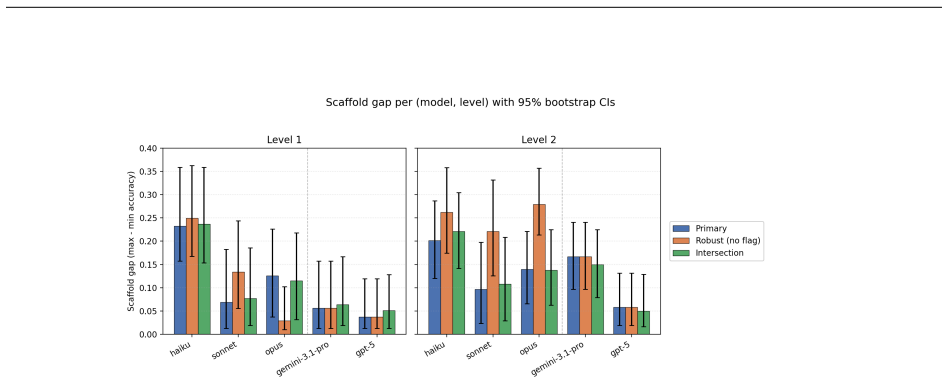
Scaffold choice shifts measured accuracy on GAIA by up to 28 percentage points for the same model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
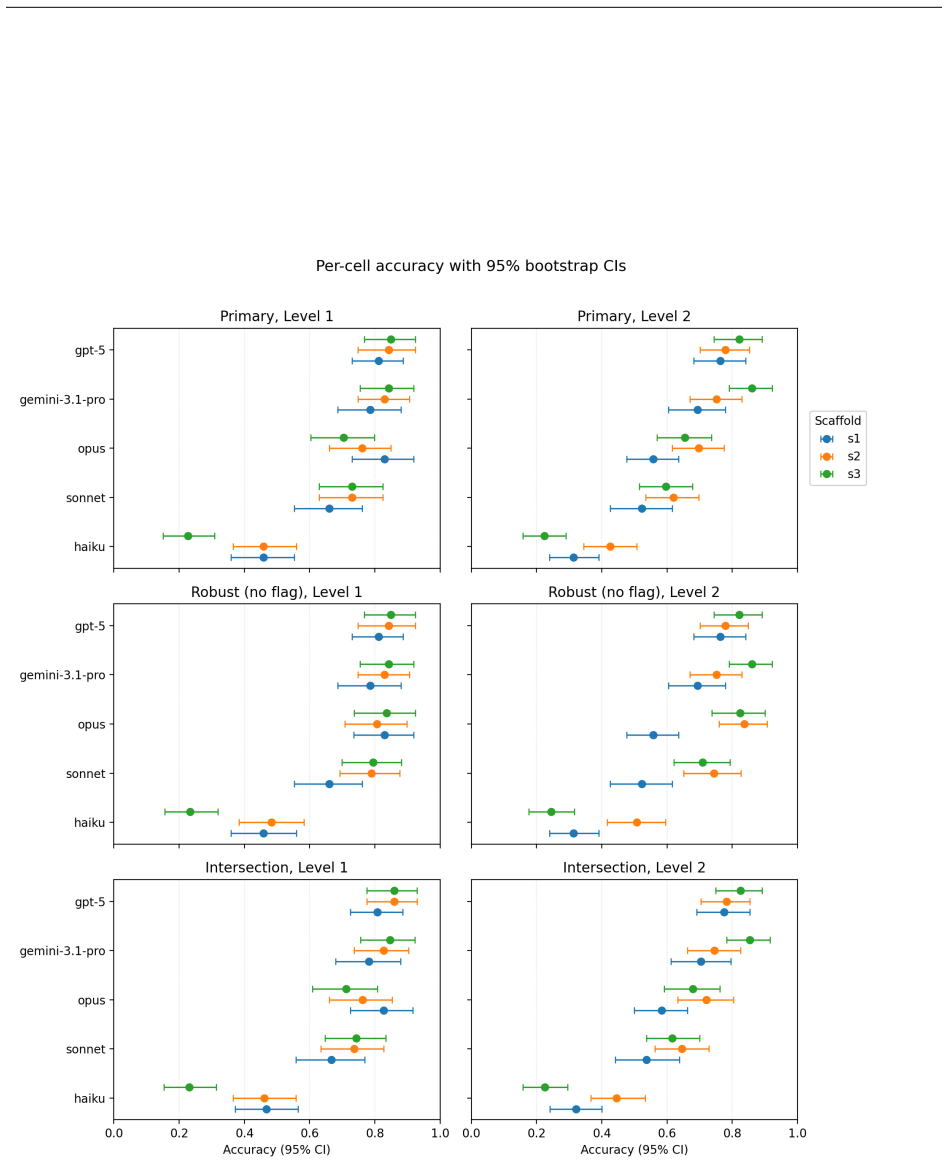
The paper establishes through a pre-registered controlled comparison that scaffold choice alone moves measured accuracy by as much as 28 percentage points within a single model on GAIA validation Levels 1 and 2. It confirms that scaffold variation produces gaps of at least 10 points but rejects the prediction that more capable models are less scaffold-sensitive; instead, effects vary significantly by model in every slice, with the most capable Anthropic model gaining the most from structured scaffolds at the harder level. The multi-agent advantage over ReAct at Level 2 holds only within the Anthropic family, the predicted planner-executor advantage on file-reading tasks is falsified, and str
What carries the argument
Controlled comparison of three scaffolds (ReAct, Planner-Actor-Rater multi-agent design, and planner-then-executor) across fixed tasks and models on GAIA Levels 1 and 2.
If this is right
- Single-scaffold capability numbers are conditional estimates rather than pure measures of model ability.
- The elicitation gap between model potential and observed performance is not guaranteed to shrink as models improve.
- Model family rather than capability tier determines sensitivity to structured scaffolds at harder task levels.
- Multi-agent scaffolds show an advantage over ReAct at Level 2 only within the Anthropic model family.
- Planner-then-executor does not deliver the predicted advantage on file-reading tasks.
Where Pith is reading between the lines
- Agent evaluations may need to report results across multiple scaffolds to isolate model contributions from scaffold contributions.
- Benchmarks could incorporate scaffold randomization or standardization to reduce conflation in reported scores.
- Error recovery patterns suggest specific scaffold design features worth testing in isolation on other benchmarks.
Load-bearing premise
The three scaffolds were implemented without systematic bias in tool-use patterns, error recovery logic, or prompt engineering that would favor one scaffold over another when tasks and models are held fixed.
What would settle it
A replication study that implements the identical three scaffolds on the same GAIA tasks and models but measures accuracy gaps below 10 points in every dataset slice.
Figures
read the original abstract
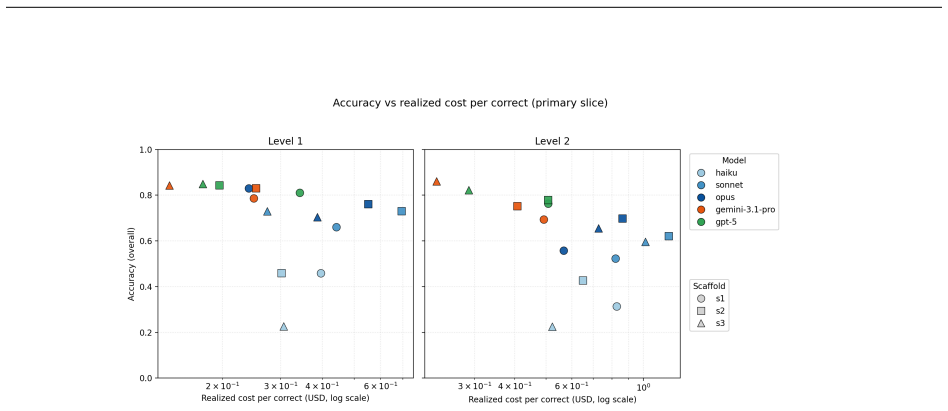
Published agent capability scores conflate what a model can do with what its scaffold lets it do, and the magnitude of this elicitation gap is not well characterized under controlled conditions. This study executes a pre-registered controlled comparison of three scaffolds (ReAct, a Planner-Actor-Rater multi-agent design, and planner-then-executor) across five models from three providers (Claude Opus 4.7, Sonnet 4.6, Haiku 4.5; Gemini 3.1 Pro Preview; GPT-5.5) on GAIA validation Levels 1 and 2, holding tasks and conditions fixed, with three attempts per question. Scaffold choice alone moves measured accuracy by as much as 28 percentage points within a single model (Opus, Level 2, robust slice), confirming the pre-registered hypothesis that scaffold variation produces gaps of at least 10 points. The pre-registered prediction that more capable models would be less scaffold-sensitive is rejected in direction: scaffold effects vary significantly by model in every dataset slice, but the most capable Anthropic model gains the most from structured scaffolds at the harder level, and tier-scaling holds only at Level 1 under the robust slice. The multi-agent advantage over ReAct at Level 2 appears within the Anthropic family but not for the cross-provider models, making model family rather than capability tier the conditioning variable, and the predicted planner-executor advantage on file-reading tasks is falsified. Structured scaffolds make fewer tool calls yet recover more often from mid-trajectory errors at the harder level, and a single cell (Gemini with planner-then-executor) is the cheapest at both levels and the most accurate at Level 2. These results indicate that single-scaffold capability numbers are scaffold-conditional estimates and that the elicitation gap is not guaranteed to shrink as models improve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a pre-registered controlled experiment comparing three scaffolds (ReAct, Planner-Actor-Rater, planner-then-executor) on GAIA validation Levels 1 and 2 across five models. It claims scaffold choice alone produces accuracy differences up to 28 percentage points (Opus, Level 2, robust slice), that the elicitation gap does not reliably shrink with model capability, that model family rather than tier conditions the multi-agent advantage, and that structured scaffolds recover from errors more effectively while using fewer tool calls.
Significance. If the controlled measurements hold after addressing implementation-equivalence concerns, the work supplies direct evidence that published agent scores are scaffold-conditional and quantifies the elicitation gap under fixed tasks. The pre-registration and fixed-task design are strengths that reduce post-hoc flexibility.
major comments (3)
- [Abstract / Methods] Abstract and methods: the 28pp claim and the rejection of the pre-registered model-capability hypothesis rest on the assumption that the three scaffolds were implemented with matched prompt specificity, tool-calling rules, and error-recovery logic. No section supplies the prompt templates, length statistics, or decision rules used for each scaffold, leaving open the possibility that engineering effort differences drive the observed gaps rather than architectural structure.
- [Results] Results (all slices): the abstract states that scaffold effects vary significantly by model and that tier-scaling holds only at Level 1 under the robust slice, yet supplies no error bars, exact sample sizes per cell, or statistical tests for the 28pp difference or the model-family interaction. These omissions are load-bearing for the central claim that scaffold variation produces gaps of at least 10 points.
- [Discussion] Discussion: the claim that structured scaffolds recover more often from mid-trajectory errors is presented without a breakdown of error types or recovery rates per scaffold-model pair; without this, it is unclear whether the advantage is architectural or an artifact of differing recovery heuristics.
minor comments (1)
- [Abstract] The abstract refers to 'robust slice' without defining the exclusion criteria in the provided text; a brief definition or reference to the pre-registration would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments point-by-point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods: the 28pp claim and the rejection of the pre-registered model-capability hypothesis rest on the assumption that the three scaffolds were implemented with matched prompt specificity, tool-calling rules, and error-recovery logic. No section supplies the prompt templates, length statistics, or decision rules used for each scaffold, leaving open the possibility that engineering effort differences drive the observed gaps rather than architectural structure.
Authors: We agree that providing the prompt templates, length statistics, and decision rules is essential to substantiate that the observed differences arise from architectural structure rather than implementation details. In the revised manuscript, we will include these in a new appendix, along with a description of how prompt specificity and error-recovery logic were matched across scaffolds per the pre-registration protocol. This will allow readers to assess equivalence directly. revision: yes
-
Referee: [Results] Results (all slices): the abstract states that scaffold effects vary significantly by model and that tier-scaling holds only at Level 1 under the robust slice, yet supplies no error bars, exact sample sizes per cell, or statistical tests for the 28pp difference or the model-family interaction. These omissions are load-bearing for the central claim that scaffold variation produces gaps of at least 10 points.
Authors: We acknowledge the need for statistical rigor in presenting the results. The sample sizes are determined by the GAIA validation sets (53 questions at Level 1, 86 at Level 2) with three attempts per question. In the revision, we will add error bars to all reported accuracies, specify the exact n per cell, and include appropriate statistical tests (such as pairwise proportion tests or interaction terms in a logistic model) for the 28 percentage point difference and the model-family interactions. These additions will be made to the results section and figures. revision: yes
-
Referee: [Discussion] Discussion: the claim that structured scaffolds recover more often from mid-trajectory errors is presented without a breakdown of error types or recovery rates per scaffold-model pair; without this, it is unclear whether the advantage is architectural or an artifact of differing recovery heuristics.
Authors: We will revise the discussion to include a detailed breakdown of error types (categorized as planning, execution, or recovery failures) and the corresponding recovery rates for each scaffold-model combination. This analysis supports the architectural advantage claim and will be presented in a new table to clarify that the differences are not due to heuristic variations alone. revision: yes
Circularity Check
No circularity; direct empirical measurements only
full rationale
The paper performs a controlled empirical comparison of three scaffolds across models and GAIA tasks, reporting measured accuracy differences (e.g., up to 28pp gaps) from direct runs with fixed tasks and three attempts per question. No equations, derivations, parameter fitting, or self-citations appear in the abstract or described methods; results are not reduced to quantities defined by the authors' prior work or by construction. The pre-registered hypotheses are tested against external benchmark data rather than being tautological. This is a standard self-contained empirical study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GAIA validation Levels 1 and 2 tasks remain fixed and representative when used to isolate scaffold effects
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2412.08653. David Gringras. Safety under scaffolding: How evaluation conditions shape measured safety,
-
[2]
Safety Under Scaffolding: How Evaluation Conditions Shape Measured Safety
URL https://arxiv.org/abs/2603.10044. David Gringras and Misha Salahshoor. Frontier lag: A bibliometric audit of capability misrepresentation in academic ai evaluation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Frontier Lag: A Bibliometric Audit of Capability Misrepresentation in Academic AI Evaluation
URLhttps://arxiv.org/abs/2605.04135. Sayash Kapoor, Peter Kirgis, Andrew Schwartz, Stephan Rabanser, J. J. Allaire, Rishi Bommasani, Harry Coppock, Magda Dubois, Gillian K Hadfield, Andrew B. Hall, Sara Hooker, Seth Lazar, Steve Newman, Dimitris Papailiopoulos, Shoshannah Tekofsky, Helen Toner, Cozmin Ududec, and Arvind Narayanan. Open-world evaluations f...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://arxiv.org/abs/2503.14499. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents
-
[5]
AgentBench: Evaluating LLMs as Agents
URLhttps://arxiv.org/abs/2308.03688. Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
GAIA: a benchmark for General AI Assistants
URLhttps://arxiv.org/abs/2311.12983. Franck Ndzomga. Efficient benchmarking of ai agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Govind Pimpale, Axel Højmark, Jérémy Scheurer, and Marius Hobbhahn
URLhttps://arxiv.org/abs/2603.23749. Govind Pimpale, Axel Højmark, Jérémy Scheurer, and Marius Hobbhahn. Forecasting frontier language model agent capabilities,
-
[8]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar
URLhttps://arxiv.org/abs/2502.15850. Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters
-
[9]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
URLhttps://arxiv.org/abs/2408.03314. Jason Starace. How much does scaffold choice change measured capability? a pre-registered controlled comparison on gaia, May
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://doi.org/10.17605/OSF.IO/SP576. Pre-registration. Open Science Framework. UK AI Security Institute. Inspect: A framework for large language model evaluations, 2024a. URL https://inspect.aisi.org.uk/. Open-source Python framework. Source:https://github.com/ UKGovernmentBEIS/inspect_ai. UK AI Security Institute. Inspect evals: A repository of comm...
-
[11]
ReAct: Synergizing Reasoning and Acting in Language Models
URLhttps://arxiv.org/abs/2210.03629. 13 A Inspect AI Gemini provider patch When using Gemini 3 Pro with both Gemini’s nativeweb_search(which resolves togoogle_search) and function tools (bash,python,text_editor), Inspect AI 0.3.217 raised a pre-flightValueErrorread- ing "Gemini does not yet support native web search or code execution concurrently with oth...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
witnesses
Sorted ascending by realized. The Anthropic L2 cluster shows the largest deltas, driven byprovider_serialization_bugunits that paid token cost without completing. model scaffold cpc realized cpc happy-path delta gemini-3.1-pro s3 0.229 0.229 0.000 gpt-5 s3 0.288 0.288 0.000 gemini-3.1-pro s2 0.407 0.407 0.000 gemini-3.1-pro s1 0.491 0.491 0.000 gpt-5 s1 0...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.