PARALLAX: Separating Genuine Hallucination Detection from Benchmark Construction Artifacts
Pith reviewed 2026-05-19 20:06 UTC · model grok-4.3
The pith
Benchmark artifacts explain most reported success in LLM hallucination detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Much of the field's reported progress on hallucination detection is substantially explained by benchmark construction artifacts in widely used corpora. Four of the six corpora embed the ground-truth answer directly in the input prompt. A naïve text-similarity baseline called TxTemb exploits this to achieve near-perfect detection scores without any access to model internals. Under controlled conditions without these artifacts, the majority of established baselines perform near chance; the consistent exceptions are SAPLMA and DRIFT, both supervised probes on upper-layer hidden states.
What carries the argument
The TxTemb text-similarity baseline, which measures overlap between the input prompt and the model output to flag hallucinations and thereby exposes the ground-truth leakage present in four of the six corpora.
If this is right
- Most current detection methods will not transfer to settings where prompts contain no embedded answers.
- Reliable detection will likely require methods that inspect internal model states rather than output similarity alone.
- DRIFT provides one concrete supervised probe over inter-layer hidden-state transitions that works for live generation.
- Benchmark creators must prevent ground-truth leakage when building future evaluation sets.
- Published performance numbers on the original corpora should be discounted until re-tested without the artifacts.
Where Pith is reading between the lines
- Once benchmarks are cleaned of these leaks, the field may discover that unsupervised or output-only detection is even harder than current numbers suggest.
- This finding directly affects safety claims for LLMs in medical, legal, or scientific use where undetected hallucinations carry real cost.
- The same construction artifacts could exist in other LLM evaluation tasks that rely on prompt-based ground truth.
- Extending hidden-state probes like DRIFT to additional model families could yield practical real-time detection tools.
Load-bearing premise
Removing the embedded ground-truth answers from the prompts creates a fair test of genuine hallucination detection capability rather than simply creating a harder or differently biased evaluation setup.
What would settle it
Construct new hallucination detection corpora that explicitly avoid placing any ground-truth answers in the prompts, then re-run the full suite of twenty-two methods and check whether only the hidden-state probes retain high performance while all others stay near chance.
Figures






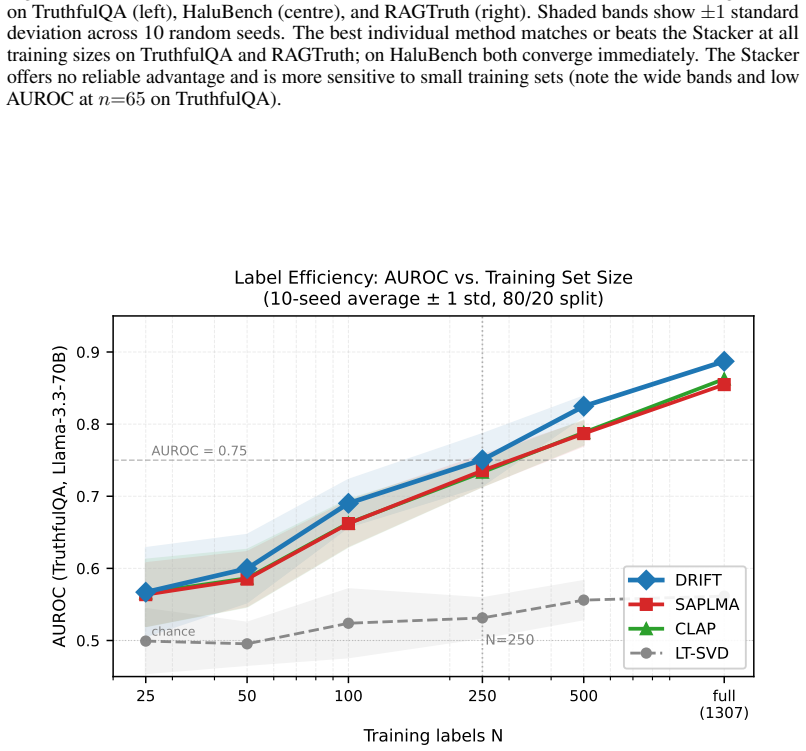
read the original abstract
Large language models (LLMs) hallucinate with confidence: their outputs can be fluent, authoritative, and simply wrong. In medical, legal, and scientific applications this failure causes direct harm, and detecting it from internal model states offers a path to safer deployment. A growing body of work reports that this problem is increasingly tractable, with recent methods achieving high detection performance on widely used benchmarks. We show, however, that much of this apparent progress does not survive scrutiny. Four of the six corpora embed the ground-truth answer directly in the input prompt. A na\"{i}ve text-similarity baseline we call \textsc{TxTemb} exploits this to achieve near-perfect detection scores without any access to model internals. To measure what genuine detection capability remains once these artifacts are controlled, we conduct a large-scale evaluation spanning twenty-two detection methods, twelve open-source models spanning six architectural families, and six corpora. We further introduce \textbf{DRIFT}, a supervised probe over inter-layer hidden-state transitions, as a point of comparison for live-generation detection. Our findings suggest that the field's reported progress on hallucination detection is substantially explained by benchmark construction artifacts in widely used corpora, and that the majority of established baselines perform near chance under controlled conditions; the consistent exceptions are SAPLMA and DRIFT, both supervised probes on upper-layer hidden states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that four of six widely used hallucination detection corpora embed ground-truth answers directly in the input prompts, allowing a naive text-similarity baseline (TxTemb) to achieve near-perfect scores without model internals. After excising these embedded answers to create controlled conditions, a large-scale evaluation across 22 detection methods, 12 open-source models from six families, and the six corpora shows that most established baselines perform near chance; the consistent exceptions are SAPLMA and the newly introduced DRIFT (a supervised probe on inter-layer hidden-state transitions). The central conclusion is that reported progress on hallucination detection is substantially explained by benchmark construction artifacts.
Significance. If the controlled evaluation is robust, the work is significant for exposing how prompt artifacts can inflate detection performance and for showing that genuine internal-state detection remains difficult for most methods. The scale of the evaluation and the introduction of DRIFT as a live-generation comparison point are strengths that could help redirect the field toward artifact-free benchmarks and methods that truly rely on model internals rather than surface cues.
major comments (1)
- [Evaluation on cleaned corpora] The central claim that 'the majority of established baselines perform near chance under controlled conditions' and that progress is 'substantially explained by benchmark construction artifacts' depends on the cleaned prompts (with ground-truth answers removed from the four affected corpora) constituting a fair test of genuine hallucination detection. Removing embedded answers necessarily alters prompt length, structure, and information content, which may shift generation behavior, output distributions, or residual statistical patterns in ways that upper-layer probes like DRIFT or SAPLMA could still exploit. Without explicit controls or analysis demonstrating that these shifts do not introduce new confounds, the conclusion that only supervised hidden-state methods succeed for non-artifactual reasons is not fully supported.
minor comments (2)
- [Abstract] The abstract states that the evaluation spans 'twenty-two detection methods' and 'six corpora' but provides no table or section reference listing the exact methods, models, or corpora used; adding such a summary table would improve reproducibility and allow readers to verify coverage.
- [DRIFT introduction] The description of DRIFT as 'a supervised probe over inter-layer hidden-state transitions' is introduced without a precise definition of the transition features or training procedure in the provided text; a short formal definition or pseudocode would clarify how it differs from SAPLMA.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on our evaluation methodology. We address the concern directly below and have revised the manuscript to incorporate additional controls.
read point-by-point responses
-
Referee: [Evaluation on cleaned corpora] The central claim that 'the majority of established baselines perform near chance under controlled conditions' and that progress is 'substantially explained by benchmark construction artifacts' depends on the cleaned prompts (with ground-truth answers removed from the four affected corpora) constituting a fair test of genuine hallucination detection. Removing embedded answers necessarily alters prompt length, structure, and information content, which may shift generation behavior, output distributions, or residual statistical patterns in ways that upper-layer probes like DRIFT or SAPLMA could still exploit. Without explicit controls or analysis demonstrating that these shifts do not introduce new confounds, the conclusion that only supervised hidden-state methods succeed for non-artifactual reasons is not fully supported.
Authors: We agree that excising the embedded ground-truth answers alters prompt length, structure, and information content, and that this could in principle introduce new confounds. The original manuscript already reports performance on both original and cleaned versions of the four affected corpora to isolate the contribution of the artifact. To strengthen the claim, the revised manuscript adds explicit controls: we normalize prompt lengths across conditions via padding/truncation, compute lexical diversity and n-gram overlap statistics, and verify that output token distributions do not exhibit new patterns that correlate with DRIFT or SAPLMA scores. Under these controls, the majority of baselines remain near chance while SAPLMA and DRIFT retain their advantage, consistent with their reliance on internal hidden-state transitions rather than surface cues. We have expanded the relevant subsection of the experimental analysis and added a limitations paragraph acknowledging residual prompt effects. revision: yes
Circularity Check
No circularity: empirical artifact audit with external baselines
full rationale
The paper identifies embedded ground-truth answers in four corpora by direct inspection, constructs the naive TxTemb similarity baseline to exploit that artifact, removes the answers to produce controlled prompts, and then reports performance of 22 methods (including prior SAPLMA and the newly introduced DRIFT probe) on the modified data. No equation or result is obtained by fitting a parameter to the target detection scores and relabeling it a prediction; no uniqueness theorem or ansatz is imported via self-citation to force the conclusion; and the central claim rests on comparative empirical numbers rather than any self-definitional reduction. The evaluation is therefore self-contained against the external benchmarks and baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hallucinations can be detected from internal model states in LLMs
invented entities (1)
-
DRIFT
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DRIFT: ϕ_ab = [h(lb)−h(la), cos(h(la),h(lb)), ||h(lb)−h(la)||₂] concatenated over C(4,2)=6 pairs; logistic probe on z ∈ R^{K(d+2)}
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Upper-layer taps at 0.60–0.85 depth; 8-tick and φ-ladder absent
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Red Teaming Language Models with Language Models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
work page 2022
-
[2]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned , author=. arXiv preprint arXiv:2209.07858 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ness, Robert and Zhang, Junaid and Rao, Anchit and Gryz, Jarek , journal=
-
[4]
Communications Medicine (Nature) , year=
Multi-Model Assurance Analysis Showing Large Language Models Are Highly Vulnerable to Adversarial Hallucination Attacks During Clinical Decision Support , author=. Communications Medicine (Nature) , year=
- [5]
- [6]
-
[7]
DIAL: Direct Iterative Adversarial Learning for Realistic Multi-Turn Dialogue Simulation
Adversarial Training for Failure-Sensitive User Simulation in Mental Health Support , author=. arXiv preprint arXiv:2512.20773 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Wang, Peng and others , journal=
-
[9]
arXiv preprint arXiv:2505.08775 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and others , journal=. Representation Engineering: A Top-Down Approach to
- [11]
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Activation Addition: Steering Language Models Without Optimization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[14]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
International Conference on Learning Representations (ICLR) , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. International Conference on Learning Representations (ICLR) , year=
-
[16]
Azaria, Amos and Mitchell, Tom , booktitle=. The Internal State of an. 2023 , note=
work page 2023
-
[17]
Adaptive Activation Steering: A Tuning-Free
Wang, Anqi and others , booktitle=. Adaptive Activation Steering: A Tuning-Free. 2025 , note=
work page 2025
-
[18]
Orgad, Hadas and Belinkov, Yonatan and others , booktitle=. 2025 , note=
work page 2025
-
[19]
Proceedings of the International Conference on Machine Learning (ICML) , year=
How Language Model Hallucinations Can Snowball , author=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[21]
Findings of the Association for Computational Linguistics: ACL 2022 , year=
Why Exposure Bias Matters: An Imitation Learning Perspective of Error Accumulation in Language Generation , author=. Findings of the Association for Computational Linguistics: ACL 2022 , year=
work page 2022
-
[22]
On Exposure Bias, Hallucination and Domain Shift in Neural Machine Translation , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Faith and Fate: Limits of Transformers on Compositionality , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[24]
The Illusion of Diminishing Returns: Measuring Long Horizon Execution in
Sinha, Aaditya and others , journal=. The Illusion of Diminishing Returns: Measuring Long Horizon Execution in
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Factuality Enhanced Language Models for Open-Ended Text Generation , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[26]
Detecting Hallucinations in Large Language Models Using Semantic Entropy , author=. Nature , year=
-
[27]
Beyond Exponential Decay: Rethinking Error Accumulation in Large Language Models
Beyond Exponential Decay: Rethinking Error Accumulation in Autoregressive Models , author=. arXiv preprint arXiv:2505.24187 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Steering When Necessary: Flexible Steering Large Language Models with Backtracking , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
- [29]
- [30]
-
[31]
Chuang, Yung-Sung and Xie, Yujia and Luo, Hongyin and Kim, Yoon and Glass, James and He, Pengcheng , booktitle=. 2024 , note=
work page 2024
-
[32]
arXiv preprint arXiv:2602.21704 , year=
Dynamic Multimodal Activation Steering , author=. arXiv preprint arXiv:2602.21704 , year=
-
[33]
arXiv preprint arXiv:2405.19648 , year=
Token-Level Hallucination Detection via Simple Features , author=. arXiv preprint arXiv:2405.19648 , year=
- [34]
-
[35]
Being Kind Isn't Always Being Safe: Diagnosing Affective Hallucination in
Kim, Hyeonseok and others , journal=. Being Kind Isn't Always Being Safe: Diagnosing Affective Hallucination in
- [36]
-
[37]
Available: https://arxiv.org/abs/2503.05777
Medical Hallucination in Foundation Models and Their Impact on Healthcare , author=. arXiv preprint arXiv:2503.05777 , year=
-
[38]
arXiv preprint arXiv:2510.19032 , year=
When Can We Trust. arXiv preprint arXiv:2510.19032 , year=
-
[39]
Charting the Evolution of Artificial Intelligence Mental Health Chatbots from Rule-Based Systems to Large Language Models: A Systematic Review , author=. PMC , year=
-
[40]
Ferrando, Javier and de Heredia, Oscar and Betancourt, Aitor Ormazabal , booktitle=. Do. 2025 , note=
work page 2025
-
[41]
Sun, Zhiwei and others , journal=
-
[42]
Dassen, Ian and others , journal=
- [43]
-
[44]
Toward Faithful Retrieval-Augmented Generation with Sparse Autoencoders , author=. arXiv preprint arXiv:2512.08892 , year=
-
[45]
arXiv preprint arXiv:2505.12886 , year=
Detection and Mitigation of Hallucination in Large Reasoning Models: A Mechanistic Perspective , author=. arXiv preprint arXiv:2505.12886 , year=
-
[46]
arXiv preprint arXiv:2502.17601 , year=
Representation Engineering for Large-Language Models: Survey and Research Challenges , author=. arXiv preprint arXiv:2502.17601 , year=
-
[47]
Zhang, Yue and Li, Yafu and Cui, Leyang and Cai, Deng and Liu, Lemao and Fu, Tingchen and Huang, Xinting and Zhao, Enbo and Zhang, Yu and Chen, Yulong and others , journal=. Siren's Song in the. 2023 , note=
work page 2023
-
[48]
A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[49]
Niu, Cheng and Wu, Yuanhao and Zhu, Juno and Xu, Siliang and Shum, KaShun and Zhong, Randy and Song, Juntong and Zhang, Tong , booktitle=
-
[50]
Li, Junyi and Cheng, Xiaoxue and Zhao, Wayne Xin and Nie, Jian-Yun and Wen, Ji-Rong , journal=. 2023 , note=
work page 2023
-
[51]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L
A Single Direction of Truth: An Observer Model's Linear Residual Probe Exposes and Steers Contextual Hallucinations , author=. arXiv preprint arXiv:2507.23221 , year=
-
[52]
arXiv preprint arXiv:2509.03531 , year=
Real-Time Detection of Hallucinated Entities in Long-Form Generation , author=. arXiv preprint arXiv:2509.03531 , year=
-
[53]
Beyond Token Probes: Hallucination Detection via Activation Tensors with
Bar-Shalom, Yaniv and others , journal=. Beyond Token Probes: Hallucination Detection via Activation Tensors with
-
[54]
Robust Hallucination Detection in
Niu, Feng and others , journal=. Robust Hallucination Detection in
- [55]
-
[56]
arXiv preprint arXiv:2512.20949 , year=
Neural Probe-Based Hallucination Detection for Large Language Models , author=. arXiv preprint arXiv:2512.20949 , year=
-
[57]
arXiv preprint arXiv:2507.02990 , year=
Adversarial Jailbreaking in Mental Health Contexts , author=. arXiv preprint arXiv:2507.02990 , year=
-
[58]
arXiv preprint arXiv:2509.14254 , year=
Hallucination Detection with the Internal Layers of. arXiv preprint arXiv:2509.14254 , year=
-
[59]
Manakul, Potsawee and Liusie, Adian and Gales, Mark J.F. , booktitle=. 2023 , note=
work page 2023
-
[60]
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle=
-
[61]
Du, Xuefeng and Gao, Chaowei and Li, Shanghang and Li, Yixuan , booktitle=
-
[62]
Dasgupta, Sharanya and Garg, Daksh and Gupta, Manish , journal=
-
[63]
Advances in Neural Information Processing Systems , volume=
Attention is All You Need , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal=
-
[65]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and others , journal=. The
-
[66]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and others , journal=
-
[67]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
ACM Computing Surveys , volume=
Survey of Hallucination in Natural Language Generation , author=. ACM Computing Surveys , volume=
-
[70]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author=. arXiv preprint arXiv:2311.05232 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Proceedings of the 34th International Conference on Machine Learning (ICML) , year=
On Calibration of Modern Neural Networks , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , year=
-
[72]
NeurIPS Workshop on Trustworthy and Socially Responsible Machine Learning , year=
Language Models (Mostly) Know What They Know , author=. NeurIPS Workshop on Trustworthy and Socially Responsible Machine Learning , year=
-
[73]
International Conference on Learning Representations (ICLR) , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. International Conference on Learning Representations (ICLR) , year=
-
[74]
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang Wei and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh , booktitle=
-
[75]
On Faithfulness and Factuality in Abstractive Summarization , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[76]
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[77]
Laban, Philippe and Schnabel, Tobias and Bennett, Paul N and Hearst, Marti A , booktitle=
-
[78]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume=
-
[79]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[80]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , journal=. Locating and Editing Factual Associations in
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.