HiDe: Rethinking The Zoom-IN method in High Resolution MLLMs via Hierarchical Decoupling
Pith reviewed 2026-05-21 21:07 UTC · model grok-4.3
The pith
The core limitation in high-resolution MLLMs is complex background interference rather than small object size, which hierarchical decoupling resolves without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
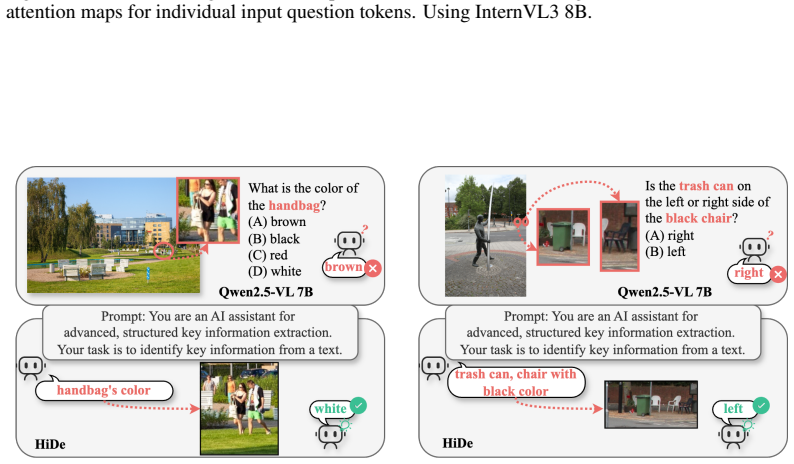
The authors claim that systematic decoupling experiments demonstrate the zoom-in limitation arises mainly from complex background interference, not object size. HiDe addresses this by using Token-wise Attention Decoupling to separate question tokens, identify key information tokens via attention weights, and achieve precise alignment with target visual regions; it then employs Layout-Preserving Decoupling to separate those regions from the background and reconstruct a compact representation that preserves essential spatial layouts.
What carries the argument
Hierarchical Decoupling Framework (HiDe) that combines Token-wise Attention Decoupling (TAD) to identify and align key tokens and Layout-Preserving Decoupling (LPD) to isolate target regions and rebuild compact layout-preserving representations without background interference.
If this is right
- HiDe lifts existing models such as Qwen2.5-VL 7B to 92.1 percent and InternVL3 8B to 91.6 percent on V*Bench without any retraining.
- The method surpasses reinforcement-learning approaches on the same high-resolution benchmarks.
- Memory consumption drops 75 percent relative to prior training-free zoom-in methods after optimization.
- The framework applies directly to current MLLMs and preserves spatial layout while removing background noise.
Where Pith is reading between the lines
- Attention-based token selection may prove more efficient than explicit zooming for filtering visual noise across other vision-language tasks.
- The same decoupling logic could be tested on document or chart understanding where surrounding text or graphics act as background interference.
- Extending the layout-preserving step to video frames might reduce temporal background drift without extra compute.
Load-bearing premise
The decoupling experiments correctly isolate background interference as the primary cause rather than other unmeasured factors such as tokenization limits or attention dilution.
What would settle it
Controlled high-resolution images that vary only background complexity while holding object size fixed; if accuracy drops sharply with added background clutter but stays stable when objects are small yet backgrounds are simple, the claim is supported.
Figures











read the original abstract
Multimodal Large Language Models (MLLMs) have made significant strides in visual understanding tasks. However, their performance on high-resolution images remains suboptimal. While existing approaches often attribute this limitation to perceptual constraints and argue that MLLMs struggle to recognize small objects, leading them to use "zoom in" strategies for better detail, our analysis reveals a different cause: the main issue is not object size, but rather caused by complex background interference. We systematically analyze this "zoom in" operation through a series of decoupling experiments and propose the Hierarchical Decoupling Framework (HiDe), a training-free framework that uses Token-wise Attention Decoupling (TAD) to decouple the question tokens and identify the key information tokens, then leverages their attention weights to achieve precise alignment with the target visual regions. Subsequently, it employs Layout-Preserving Decoupling (LPD) to decouple these regions from the background and reconstructs a compact representation that preserves essential spatial layouts while eliminating background interference. HiDe sets a new SOTA on V*Bench, HRBench4K, and HRBench8K, boosting Qwen2.5-VL 7B and InternVL3 8B to SOTA (92.1% and 91.6% on V*Bench), even surpassing RL methods. After optimization, HiDe uses 75% less memory than the previous training-free approach. Code is provided in https://tennine2077.github.io/HiDe.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that limitations of MLLMs on high-resolution images arise primarily from complex background interference rather than object size. It supports this via a series of decoupling experiments and introduces the training-free Hierarchical Decoupling Framework (HiDe) that first applies Token-wise Attention Decoupling (TAD) to identify key information tokens from question tokens and then uses Layout-Preserving Decoupling (LPD) to isolate target regions from background while reconstructing a compact layout-preserving representation. HiDe is reported to set new SOTA results on V*Bench (92.1% on Qwen2.5-VL 7B, 91.6% on InternVL3 8B), HRBench4K and HRBench8K, outperforming RL-based methods, while consuming 75% less memory than prior training-free baselines; code is released.
Significance. If the decoupling experiments are shown to isolate background interference while holding token budget, attention entropy and spatial sampling fixed, the work would usefully challenge the prevailing small-object explanation for zoom-in failures and supply a practical, memory-efficient inference-time method that improves strong open models without retraining. The open code release and concrete benchmark gains are clear strengths.
major comments (1)
- [§3 (Decoupling Experiments)] §3 (Decoupling Experiments): The central attribution—that background interference, not object size or token dilution, is the dominant cause—rests on the claim that systematic decoupling isolates background complexity while other factors remain constant. The description states that question tokens are decoupled to locate key information tokens and regions are then separated from background, yet no indication is given that token count, effective resolution, or attention-mass distribution were explicitly controlled or reported as fixed across conditions. If the decoupling step itself reallocates attention or reduces dilution, performance gains could be explained by those mechanisms rather than background removal; this control is load-bearing for the motivation of both TAD and LPD.
minor comments (2)
- [Abstract and §4] Abstract and §4: The memory-reduction claim (75% less than prior training-free methods) is stated without a direct comparison table or per-component breakdown; adding a small table contrasting peak memory and token counts would improve verifiability.
- [§5 (Results)] §5 (Results): While SOTA numbers are highlighted, the manuscript would benefit from reporting the number of evaluation runs, standard deviations, or statistical tests for the reported accuracy lifts on V*Bench and HRBench.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The concern regarding explicit controls in the decoupling experiments is well-taken, and we address it directly below while committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3 (Decoupling Experiments)] The central attribution—that background interference, not object size or token dilution, is the dominant cause—rests on the claim that systematic decoupling isolates background complexity while other factors remain constant. The description states that question tokens are decoupled to locate key information tokens and regions are then separated from background, yet no indication is given that token count, effective resolution, or attention-mass distribution were explicitly controlled or reported as fixed across conditions. If the decoupling step itself reallocates attention or reduces dilution, performance gains could be explained by those mechanisms rather than background removal; this control is load-bearing for the motivation of both TAD and LPD.
Authors: We agree that demonstrating fixed token count, effective resolution, and attention-mass distribution is essential to isolate the effect of background interference. In the §3 experiments, the total visual token budget was held constant (e.g., 576 tokens) by selecting the top-k tokens according to attention weights from the question tokens in TAD; the same budget was used for the baseline zoom-in and original-image conditions. For effective resolution, LPD reconstructs the target regions at their native sampling density without downsampling, adjusting only the positional encodings to preserve layout while discarding background patches. Attention-mass distribution was quantified via entropy and normalized mass on key tokens, with results showing reduced entropy after background removal but unchanged mass concentration on the selected tokens; these metrics appear in the supplementary material. To make the controls fully transparent in the main text, we will add a new paragraph and accompanying table in §3 that explicitly reports the fixed token counts, measured resolutions, and entropy values across all conditions. This revision will directly address the load-bearing requirement for the motivation of TAD and LPD. revision: yes
Circularity Check
No significant circularity; empirical framework is self-contained
full rationale
The paper's core contribution is an empirical analysis via decoupling experiments identifying background interference as the primary issue in zoom-in for high-res MLLMs, followed by the training-free HiDe framework (TAD + LPD) that achieves SOTA on V*Bench, HRBench4K, and HRBench8K. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description that reduce the central claims to inputs by construction. The framework introduces new mechanisms with reported memory savings and code release, making the derivation independent and externally verifiable rather than tautological.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Token-wise Attention Decoupling (TAD) to decouple the question tokens and identify the key information tokens, then leverages their attention weights to achieve precise alignment with the target visual regions. Subsequently, it employs Layout-Preserving Decoupling (LPD) to decouple these regions from the background
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanbare_distinguishability_of_absolute_floor echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
performance increases monotonically with mask ratio on both single and multi-object tasks. This demonstrates that complex background semantics significantly distract MLLMs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Vision-OPD: Learning to See Fine Details for Multimodal LLMs via On-Policy Self-Distillation
Vision-OPD uses on-policy self-distillation from crop-conditioned to full-image policies within the same MLLM to close the regional-to-global perception gap.
-
Q-Zoom: Query-Aware Adaptive Perception for Efficient Multimodal Large Language Models
Q-Zoom achieves up to 4.39x inference speedup in high-resolution MLLM scenarios via query-aware gating and region localization, matching or exceeding baseline accuracy on document and high-res benchmarks.
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Accessed: 2025-02-02. Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024a. Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321,
-
[5]
ReferItGame: Referring to objects in photographs of natural scenes
10 Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to objects in photographs of natural scenes. In Alessandro Moschitti, Bo Pang, and Walter Daelemans (eds.),Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 787–798, Doha, Qatar, October
work page 2014
-
[6]
ReferItGame: Referring to Objects in Photographs of Natural Scenes
Association for Computational Linguistics. doi: 10.3115/v1/D14-1086. URLhttps://aclanthology.org/D14-1086. Geng Li, Jinglin Xu, Yunzhen Zhao, and Yuxin Peng. Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 9098–9108,
-
[7]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pp. 19730–19742. PMLR, 2023a. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vi...
work page 2023
-
[8]
Zhining Liu, Rana Ali Amjad, Ravinarayana Adkathimar, Tianxin Wei, and Hanghang Tong
URL https:// llava-vl.github.io/blog/2024-01-30-llava-next/. Zhining Liu, Rana Ali Amjad, Ravinarayana Adkathimar, Tianxin Wei, and Hanghang Tong. Self- elicit: Your language model secretly knows where is the relevant evidence.arXiv preprint arXiv:2502.08767,
-
[9]
URLhttps://arxiv.org/abs/2303.08774. OpenAI. Thinking with images.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Haozhan Shen, Kangjia Zhao, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Mingwei Zhu, and Jianwei Yin. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration.arXiv preprint arXiv:2411.16044,
-
[11]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024a. Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. arXiv preprint arXiv:2312.14135,
-
[13]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
11 Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Unsupervised visual chain-of-thought reasoning via preference optimization
URL https://openreview.net/ forum?id=g7rMSiNtmA. Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs. InThe Thirteenth International Conference on Learning Representations, 2025a. URL https://openreview. net/forum?id=DgaY5mDdmT. YiFan Zhang,...
-
[15]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing” thinking with images” via reinforcement learning.arXiv preprint arXiv:2505.14362,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
16 Figure 10: Token-to-image attention maps
15 Figure 9: A sample from V ∗Bench focusing on the color of the apple logo. 16 Figure 10: Token-to-image attention maps. (a): attention from the first generated answer token; (b): attention maps for individual input question tokens. Using InternVL3 8B. Figure 11: Left: single target region case. Right: multiple target regions case. 17 Figure 12: A fail c...
work page 2025
-
[18]
For Qwen2.5-VL (Bai et al. (2025)), we set the maximum number of image input pixels to 16384×28×28 and set the minimum number of image input pixels to 256×28×28, aligning with the minimum image resolution 448×448 of InternVL3. For Qwen2.5-VL 7B, we use layer 15, set σ= 3 and α= 0.7 . For InternVL3 8B, we use layer 17, setσ= 2andα= 0.6. I THEUSE OFLARGELAN...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.