Mind the Heads: Topological Representation Alignment for Multimodal LLMs
Pith reviewed 2026-06-26 08:45 UTC · model grok-4.3
The pith
Aligning the least-aligned attention heads via local topology matching improves MLLM vision performance and reduces hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
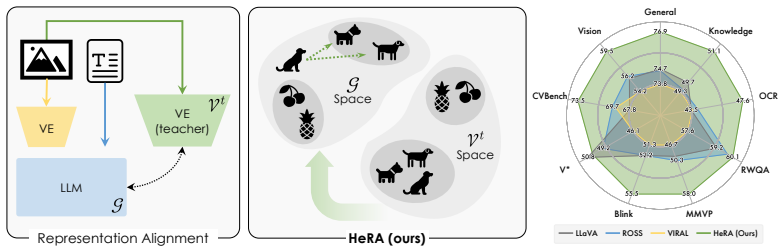
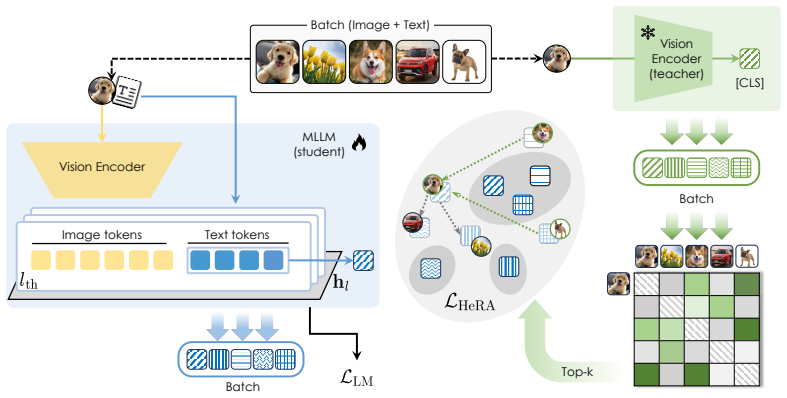
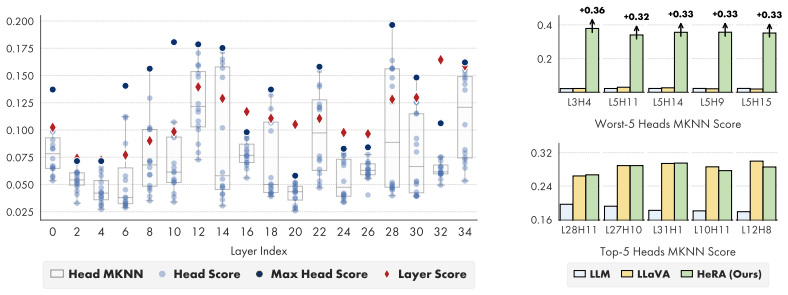
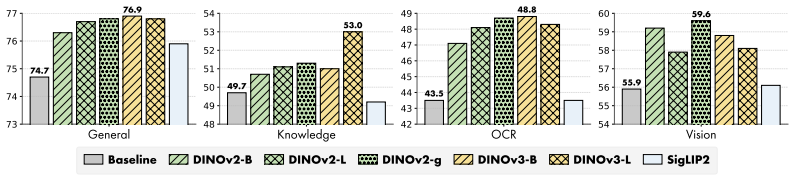
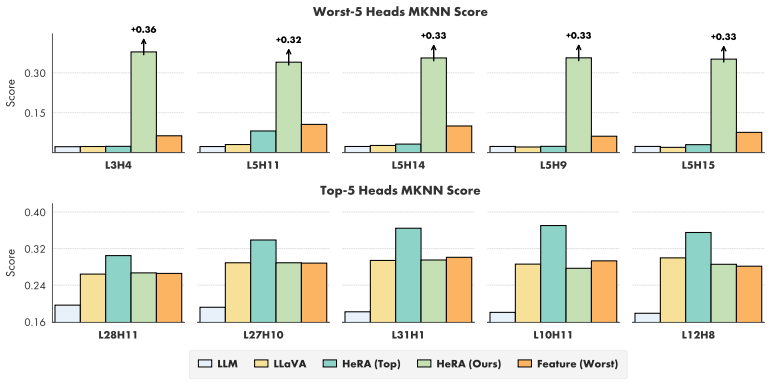
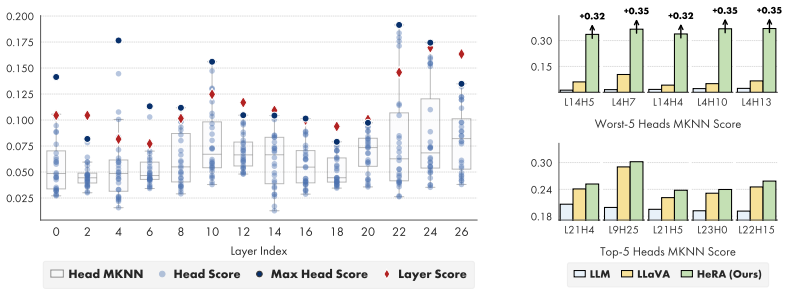
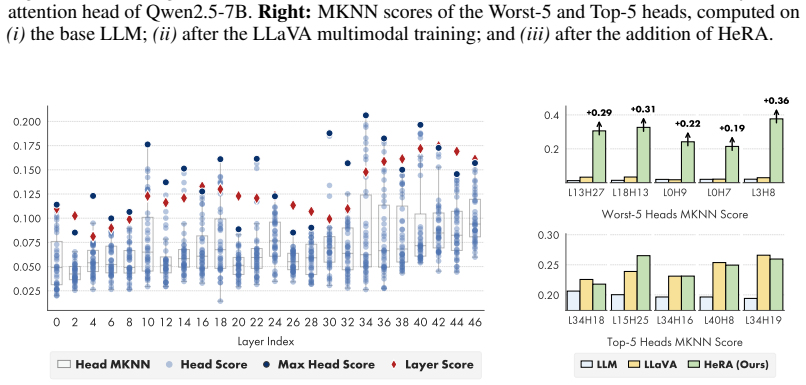
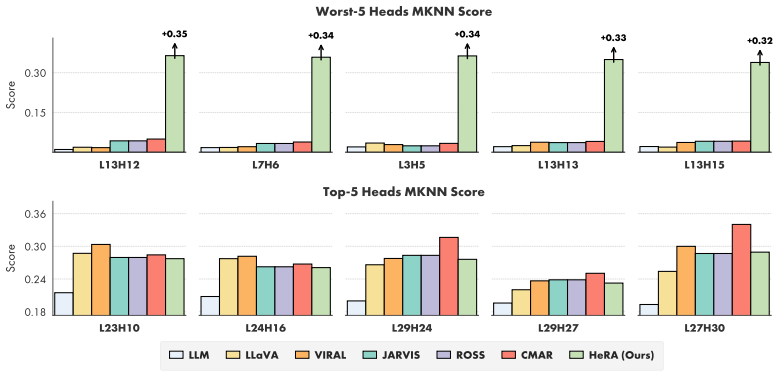
Head-Wise Representation Alignment (HeRA) measures how well each attention head preserves local neighborhood relationships using the Mutual K-Nearest Neighbor metric, selects the heads with the lowest scores, and applies a contrastive loss during multimodal training to enforce matching neighborhood structure with the vision encoder. Experiments across several MLLMs and 18 benchmarks show that this targeted head alignment raises accuracy on challenging vision tasks and lowers visual hallucinations by decreasing over-reliance on linguistic priors.
What carries the argument
Mutual K-Nearest Neighbor (MKNN) metric used both to score head alignment and to define the contrastive objective that preserves local neighborhood topology across modalities.
If this is right
- Targeting the least aligned heads produces larger gains than targeting already well-aligned heads.
- The method reduces visual hallucinations by limiting the model's dependence on language priors.
- Performance improvements hold across multiple MLLM architectures on 18 different benchmarks.
- The head-specific alignment can be added to existing multimodal training without altering model architecture.
Where Pith is reading between the lines
- Head-level topological alignment could be tested in other cross-modal combinations such as vision-audio or language-audio models.
- Tracking alignment scores during training might allow dynamic selection of which heads to regularize at different stages.
- If mismatches at specific heads cause hallucinations, then similar targeted fixes could address other failure modes like factual errors.
Load-bearing premise
That preserving local neighborhood topology through MKNN matching in the least-aligned heads is the main driver of gains rather than other training details such as loss weighting or which heads are chosen.
What would settle it
A controlled experiment that applies the same contrastive loss to the most-aligned heads or to randomly chosen heads and still matches or exceeds the reported gains on the same vision benchmarks would falsify the claim that least-aligned heads are critical.
Figures
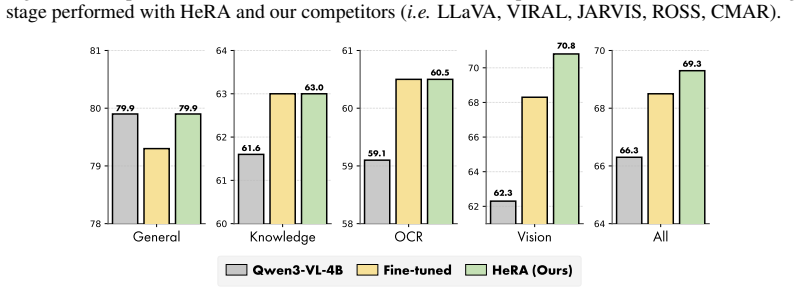
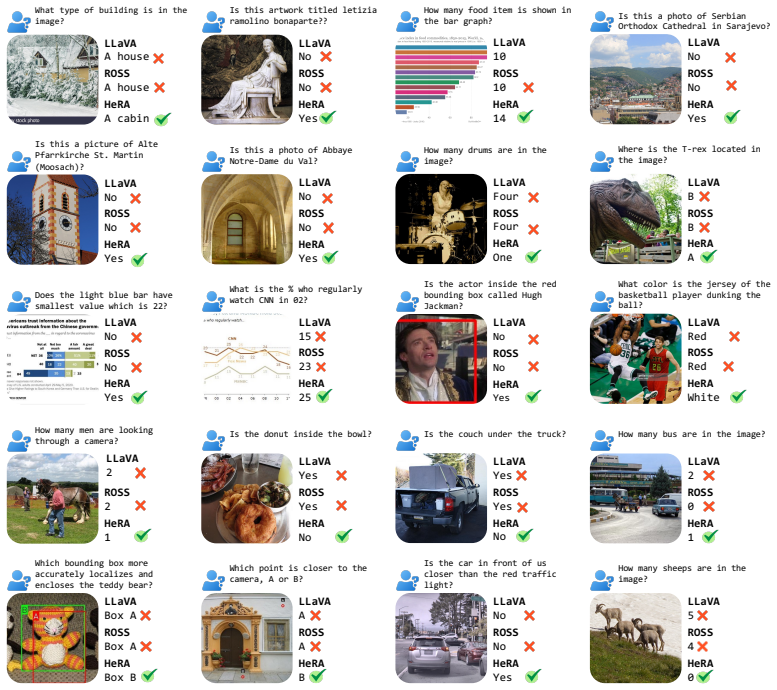

read the original abstract
Representation alignment has emerged as an effective approach to improve Multimodal Large Language Models (MLLMs) by regularizing their internal representations toward those of an external vision encoder. However, existing methods typically align a fixed layer of the language backbone, overlooking the fine-grained structure of Transformer models. In this work, we propose Head-Wise Representation Alignment (HeRA), a method that enforces cross-modal alignment at the level of individual attention heads. Our approach is grounded in the Platonic Representation Hypothesis, focusing on preserving the topological structure of representations (i.e., their local neighborhood relationships) across modalities. Following the Mutual K-Nearest Neighbor (MKNN) alignment metric, we introduce a contrastive objective that acts as a differentiable proxy for matching local structures. HeRA applies this objective during multimodal training to specific attention heads in the LLM, selected by their alignment score according to the MKNN metric. Counterintuitively, we find that aligning the least aligned heads yields the largest gains. Extensive evaluations across multiple MLLMs and 18 benchmarks demonstrate that HeRA consistently improves performance on challenging vision-centric tasks and serves as an effective regularizer against visual hallucinations by naturally curbing the over-reliance on linguistic priors. Our code is publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Head-Wise Representation Alignment (HeRA) for Multimodal LLMs. It selects attention heads by their MKNN alignment score, applies a contrastive loss that serves as a differentiable proxy for preserving local neighborhood topology across modalities, and reports that aligning the least-aligned heads produces the largest gains. The method is evaluated on multiple MLLMs across 18 benchmarks, with claimed improvements on vision-centric tasks and reduced visual hallucinations; code is released.
Significance. If the results hold after the requested controls, the work would demonstrate that per-head topological alignment can outperform conventional layer-wise approaches and act as a regularizer against linguistic priors. The public code release and multi-model, multi-benchmark evaluation are positive factors for verifiability.
major comments (3)
- [§3.2 and §4] §3.2 (MKNN contrastive objective) and §4 (experimental results): the central claim that MKNN topology preservation is the operative mechanism requires an ablation that applies an equivalent-magnitude contrastive loss to the same least-aligned heads without the MKNN term. The current results do not isolate whether gains arise from the topological proxy, the selection heuristic, or loss weighting.
- [§4] §4 (head selection and evaluation): the exact threshold or number of heads chosen by the MKNN score is not stated, nor are statistical significance tests or confidence intervals reported for the gains across the 18 benchmarks. These omissions are load-bearing for assessing whether the counter-intuitive finding (least-aligned heads yield largest gains) is robust.
- [§4] §4 (baselines): the experimental setup does not clarify whether the reported baselines include recent head-wise or layer-wise alignment methods that also target internal representations; without this, the relative contribution of HeRA cannot be fully evaluated.
minor comments (2)
- [Abstract and §3] The abstract and method section could explicitly state the typical number of heads aligned and the value of the contrastive loss weight used in the reported experiments.
- [Figure 2 / results tables] Figure 2 or the corresponding results table would benefit from error bars or per-benchmark variance to support the claim of consistent gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the experimental validation and clarity.
read point-by-point responses
-
Referee: [§3.2 and §4] §3.2 (MKNN contrastive objective) and §4 (experimental results): the central claim that MKNN topology preservation is the operative mechanism requires an ablation that applies an equivalent-magnitude contrastive loss to the same least-aligned heads without the MKNN term. The current results do not isolate whether gains arise from the topological proxy, the selection heuristic, or loss weighting.
Authors: We agree that an ablation isolating the MKNN term is necessary to substantiate the topological mechanism. In the revision we will add this control: a standard contrastive loss (InfoNCE without neighborhood matching) applied to the identical set of least-aligned heads at equivalent magnitude, allowing direct comparison of whether the MKNN-based topological proxy drives the gains beyond selection or weighting effects. revision: yes
-
Referee: [§4] §4 (head selection and evaluation): the exact threshold or number of heads chosen by the MKNN score is not stated, nor are statistical significance tests or confidence intervals reported for the gains across the 18 benchmarks. These omissions are load-bearing for assessing whether the counter-intuitive finding (least-aligned heads yield largest gains) is robust.
Authors: We will explicitly state the MKNN-score threshold and resulting number of heads selected in §4. We will also add paired statistical significance tests and 95% confidence intervals for all reported gains across the 18 benchmarks to demonstrate robustness of the least-aligned-heads result. revision: yes
-
Referee: [§4] §4 (baselines): the experimental setup does not clarify whether the reported baselines include recent head-wise or layer-wise alignment methods that also target internal representations; without this, the relative contribution of HeRA cannot be fully evaluated.
Authors: The current baselines follow the standard layer-wise alignment protocols cited in the manuscript. We will add an explicit clarification of the exact baseline implementations and, where feasible within compute limits, include additional comparisons against recent head-wise representation alignment methods in the revised §4. revision: partial
Circularity Check
No significant circularity: empirical gains from new MKNN objective do not reduce to fitted inputs or self-citations
full rationale
The paper defines HeRA as a new contrastive objective using the MKNN metric to align selected attention heads during training, then reports empirical performance on 18 external benchmarks. No equation shows a 'prediction' that equals a fitted parameter by construction, nor does the central claim (largest gains from least-aligned heads) reduce to the selection rule itself. The Platonic Representation Hypothesis is invoked as grounding but is not a self-citation chain that forbids alternatives or forces the result. The method remains falsifiable on held-out tasks without the reported gains being tautological.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of heads to align
- contrastive loss weight
axioms (1)
- domain assumption Platonic Representation Hypothesis: representations of different modalities share topological structure (local neighborhood relationships)
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Davide Caffagni, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Pier Luigi Dovesi, Shaghayegh Roohi, Mark Granroth-Wilding, and Rita Cucchiara. Seeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models.arXiv preprint arXiv:2512.15885, 2025
-
[3]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality, 2023
2023
-
[4]
Scaling Language-Free Visual Represen- tation Learning
David Fan, Shengbang Tong, Jiachen Zhu, Koustuv Sinha, Zhuang Liu, Xinlei Chen, Michael Rabbat, Nicolas Ballas, Yann LeCun, Amir Bar, et al. Scaling Language-Free Visual Represen- tation Learning. InICCV, 2025
2025
-
[5]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
BLINK: Multimodal Large Language Models Can See But Not Perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. BLINK: Multimodal Large Language Models Can See But Not Perceive. InECCV, 2024
2024
-
[7]
Cross-Modal Alignment Regularization: Enhanc- ing Language Models with Vision Model Representations
Yulu Gan, Kaiya Ivy Zhao, and Phillip Isola. Cross-Modal Alignment Regularization: Enhanc- ing Language Models with Vision Model Representations. InICLR Workshops, 2025
2025
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Revisiting the Platonic Representation Hypothesis: An Aristotelian View
Fabian Gröger, Shuo Wen, and Maria Brbi´c. Revisiting the Platonic Representation Hypothesis: An Aristotelian View. InICML, 2026
2026
-
[10]
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models. InCVPR, 2024
2024
-
[11]
VizWiz Grand Challenge: Answering Visual Questions From Blind People
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. VizWiz Grand Challenge: Answering Visual Questions From Blind People. InCVPR, 2018
2018
-
[12]
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering
Drew A Hudson and Christopher D Manning. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. InCVPR, 2019
2019
-
[13]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The Platonic Representation Hypothesis. InICML, 2024
2024
-
[14]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InECCV, 2016. 10
2016
-
[15]
REPA-E: Unlocking V AE for End-to-End Tuning with Latent Diffusion Transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. REPA-E: Unlocking V AE for End-to-End Tuning with Latent Diffusion Transformers. InICCV, 2025
2025
-
[16]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. SEED- Bench: Benchmarking Multimodal LLMs with Generative Comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating Object Hallucination in Large Vision-Language Models. InEMNLP, 2023
2023
-
[18]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In ECCV, 2014
2014
-
[19]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved Baselines with Visual Instruction Tuning. InCVPR, 2024
2024
-
[20]
MMBench: Is Your Multi-modal Model an All-around Player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. MMBench: Is Your Multi-modal Model an All-around Player? InECCV, 2024
2024
-
[21]
OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models.Sci China Inf Sci, 67(12):220102, 2024
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models.Sci China Inf Sci, 67(12):220102, 2024
2024
-
[22]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts. InICLR, 2024
2024
-
[23]
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. InNeurIPS, 2022
2022
-
[24]
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. InACL, 2022
2022
-
[25]
Causal Head Gating: A Framework for Interpreting Roles of Attention Heads in Transformers
Andrew Joohun Nam, Henry Conklin, Yukang Yang, Thomas L Griffiths, Jonathan D Cohen, and Sarah-Jane Leslie. Causal Head Gating: A Framework for Interpreting Roles of Attention Heads in Transformers. InNeurIPS, 2025
2025
-
[26]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-Context Learning and Induction Heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation Learning with Contrastive Predictive Coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
DINOv2: Learning Robust Visual Features without Supervision.TMLR, pages 1–31, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning Robust Visual Features without Supervision.TMLR, pages 1–31, 2024
2024
-
[29]
Qwen Team. Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Qwen3.5: Towards Native Multimodal Agents, 2026
Qwen Team. Qwen3.5: Towards Native Multimodal Agents, 2026
2026
-
[31]
Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S. Khan. GLaMM: Pixel Grounding Large Multimodal Model. InCVPR, 2024
2024
-
[32]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. DINOv3. arXiv preprint arXiv:2508.10104, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Towards VQA Models That Can Read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA Models That Can Read. InCVPR, 2019
2019
-
[34]
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs. InNeurIPS, 2024
2024
-
[35]
Shengbang Tong, David Fan, John Nguyen, Ellis Brown, Gaoyue Zhou, Shengyi Qian, Boyang Zheng, Théophane Vallaeys, Junlin Han, Rob Fergus, et al. Beyond Language Modeling: An Exploration of Multimodal Pretraining.arXiv preprint arXiv:2603.03276, 2026
-
[36]
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs. InCVPR, 2024
2024
-
[37]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Reconstructive Visual Instruction Tuning
Haochen Wang, Anlin Zheng, Yucheng Zhao, Tiancai Wang, Zheng Ge, Xiangyu Zhang, and Zhaoxiang Zhang. Reconstructive Visual Instruction Tuning. InICLR, 2025
2025
-
[39]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, et al. AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation.arXiv preprint arXiv:2311.07397, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small. InICLR, 2023
2023
-
[41]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
FineVision: Open Data Is All You Need
Luis Wiedmann, Orr Zohar, Amir Mahla, Xiaohan Wang, Rui Li, Thibaud Frere, Leandro von Werra, Aritra Roy Gosthipaty, and Andrés Marafioti. FineVision: Open Data Is All You Need. arXiv preprint arXiv:2510.17269, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs
Penghao Wu and Saining Xie. V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs. InCVPR, 2024
2024
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Heeji Yoon, Jaewoo Jung, Junwan Kim, Hyungyu Choi, Heeseong Shin, Sangbeom Lim, Honggyu An, Chaehyun Kim, Jisang Han, Donghyun Kim, et al. Visual Representation Alignment for Multimodal Large Language Models.arXiv preprint arXiv:2509.07979, 2025
-
[46]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. InICLR, 2025
2025
-
[47]
MMMU: A Massive Multi-discipline Multi- modal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. MMMU: A Massive Multi-discipline Multi- modal Understanding and Reasoning Benchmark for Expert AGI. InCVPR, 2024
2024
-
[48]
Answer only with Yes or No. Use exactly one word. Do not use commas, periods, or symbols
Zihao Yue, Liang Zhang, and Qin Jin. Less is More: Mitigating Multimodal Hallucination from an EOS Decision Perspective. InACL, 2024. 12 A Additional Implementation Details Training Details.Following the two-stage training recipe of LLaV A-1.5 [19], in the first stage, we train only the projector proj, a two-layer MLP, using 558k image-caption pairs, whil...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.