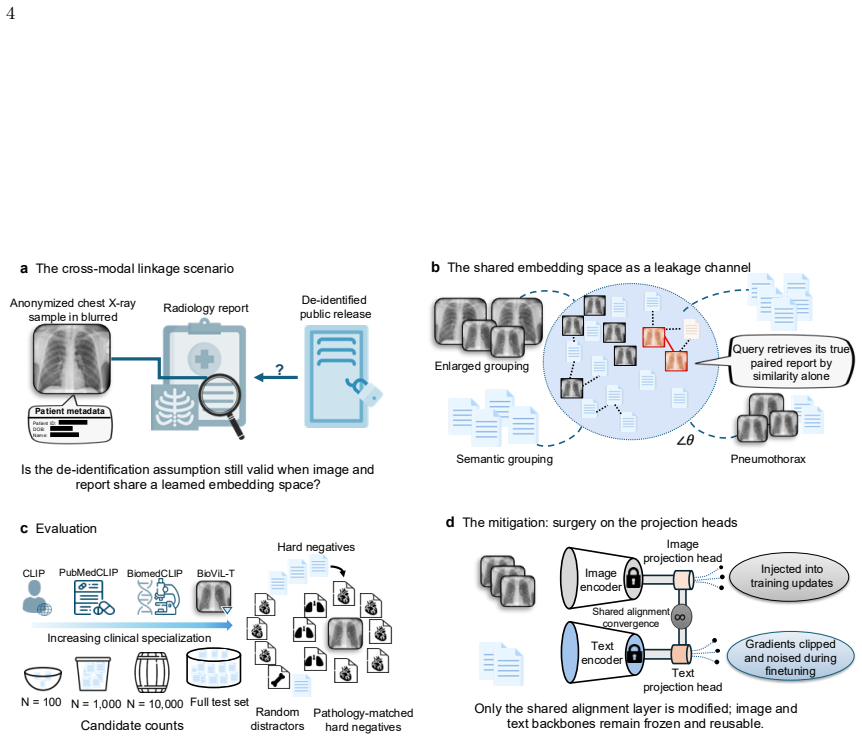
Cross-modal linkage risk in clinical vision-language models
Pith reviewed 2026-06-28 15:25 UTC · model grok-4.3
The pith
Vision-language models for chest X-rays can recover the matching radiology report for a given image using cosine similarity alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
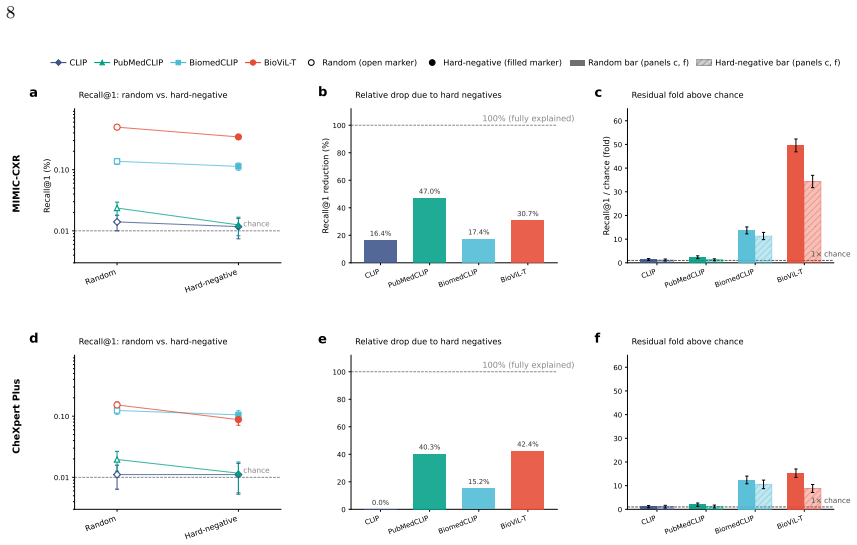
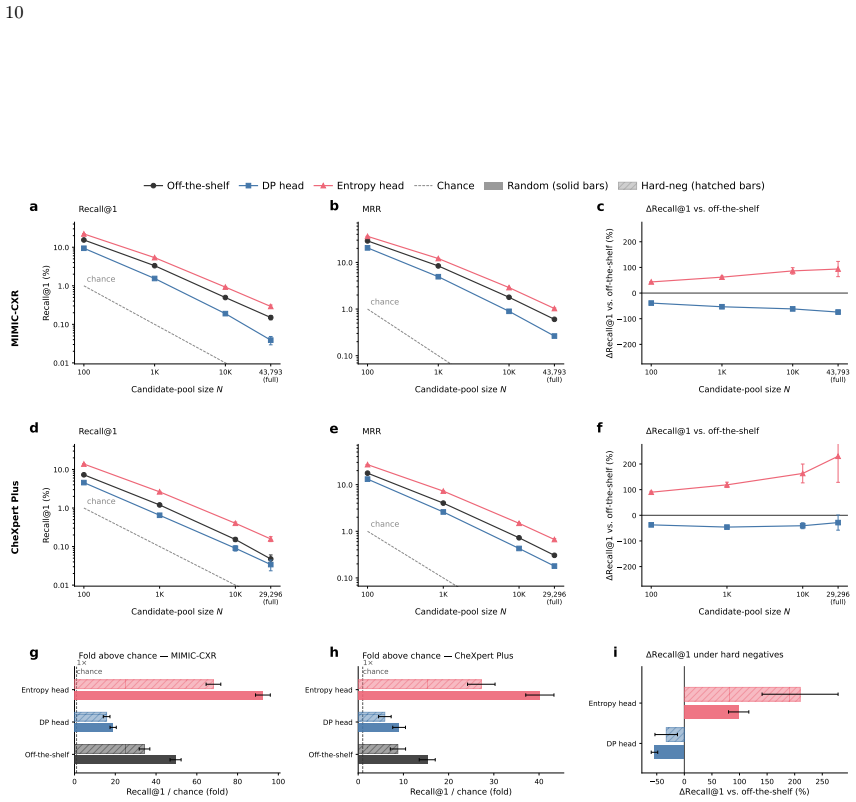
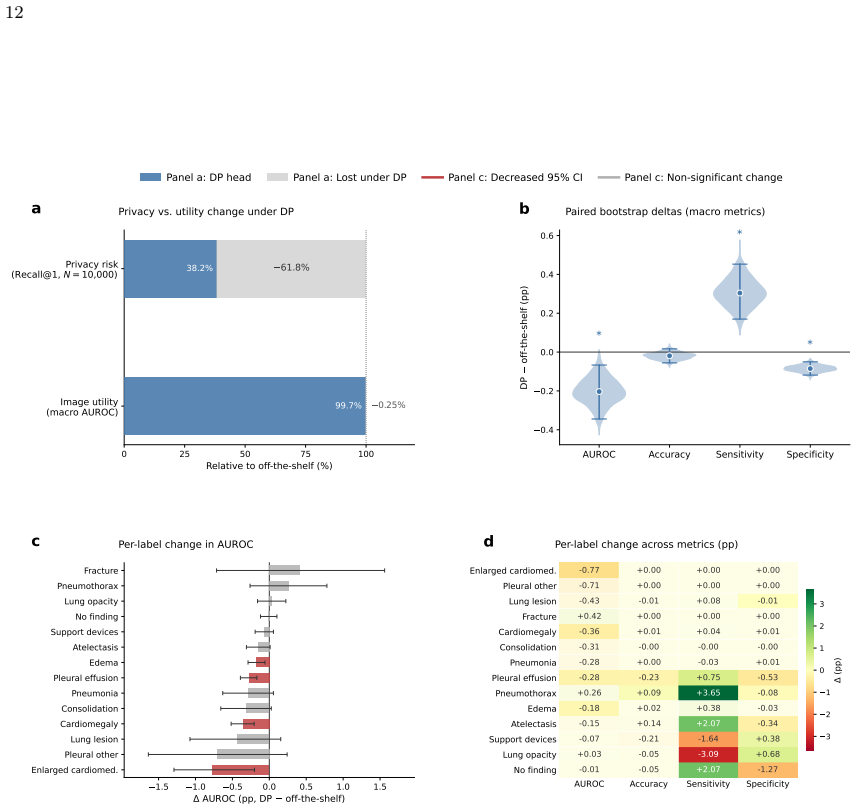
VLMs trained on paired chest radiographs and radiology reports learn a shared embedding space that preserves instance-level image-report correspondence. This allows an image to be re-linked to its original report via cosine similarity even when the two are deliberately kept separate after acquisition. The effect strengthens with clinical specialization, persists under pathology-matched hard negatives, and can be reduced by freezing the encoders and applying differentially private optimization solely to the projection heads that define the alignment layer.
What carries the argument
The projection heads that align frozen image and text encoders into a shared space, which enable cosine similarity to recover original image-report pairings.
If this is right
- Re-linkage success scales with the degree of clinical specialization of the VLM.
- The signal remains detectable even after removing disease-label shortcuts via pathology-matched negatives.
- Targeted differential privacy on the alignment layer reduces Recall@1 by more than 60 percent at large candidate pools.
- Image-side diagnostic utility measured by macro AUROC across 14 labels drops by only 0.2 percentage points.
- The mitigation transfers to an external dataset without additional training.
Where Pith is reading between the lines
- Hospitals that release images alone may still need to treat the released images as carrying report-level information if a specialized VLM is in use.
- The same alignment-layer privacy technique could be tested on other paired modalities such as pathology slides and captions.
- Audits of future VLMs could include retrieval benchmarks on held-out paired data as a standard privacy check.
- If the projection heads are the main carriers of linkage, architectures that avoid a single shared alignment layer might inherently lower the risk.
Load-bearing premise
The linkage rates observed on public paired cohorts directly indicate the re-identification risk that would occur in real deployments where images and reports are kept separate.
What would settle it
A test in which a specialized VLM's image-to-report retrieval accuracy on a large held-out paired cohort falls to random-chance levels would show the claimed cross-modal linkage risk does not exist.
Figures
read the original abstract
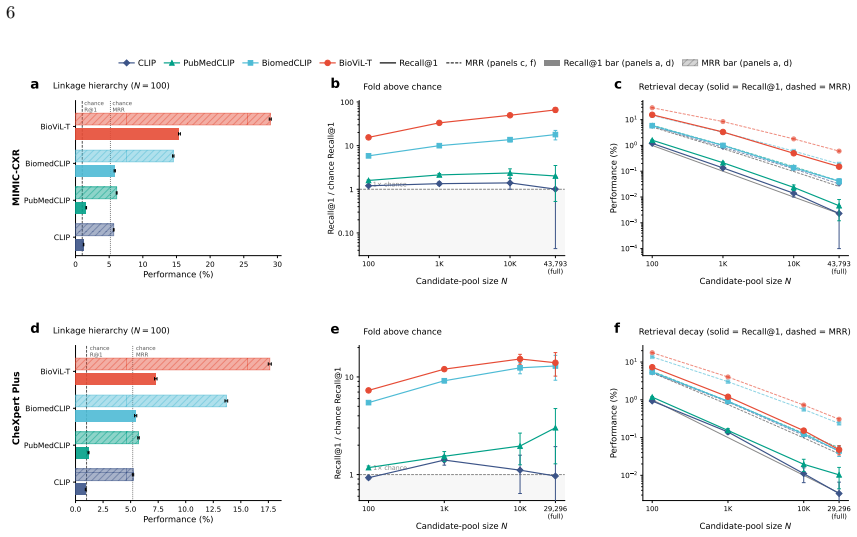
Vision-language models (VLMs) trained on paired chest radiographs and radiology reports learn a shared embedding space that can preserve instance-level image-report correspondence. This poses a privacy risk in settings where radiographs and reports are deliberately kept separate after acquisition, such as image-only data sharing or access-controlled reports, because a de-identified image may be re-linked to its original narrative report through cosine similarity alone. We formalized this as image-to-report retrieval and used public paired cohorts, in which the true pairing is known by design, as ground-truth benchmarks to audit the risk rather than as the privacy scenario. Evaluating VLMs of increasing clinical specialization on 406,241 paired examples from 126,804 patients across MIMIC-CXR (43,793 held-out pairs) and external CheXpert Plus (29,296 pairs), we found that re-linkage rose systematically with specialization: the strongest VLM retrieved the correct report at 15 times chance at a candidate pool of N = 100, 50 times chance at N = 10,000, and well above chance at full-database scale. The signal persisted under pathology-matched hard negatives that removed disease-label shortcuts, indicating correspondence beyond broad diagnostic categories. To reduce it without retraining, we froze both encoders and applied differentially private optimization only to the projection heads defining the alignment layer (epsilon = 0.34, delta = 6x10-6). This reduced Recall@1 by 61.8% at N = 10,000 on MIMIC-CXR and transferred to CheXpert Plus without retraining, while image-side utility was largely preserved: macro AUROC for linear-probe classification across 14 labels shifted only from 79.63% to 79.43%. Targeted DP finetuning of the shared alignment layer can substantially reduce cross-modal re-linkage without materially degrading the image representations that make these models clinically useful.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that vision-language models trained on paired chest radiographs and radiology reports learn embeddings that enable high-accuracy image-to-report retrieval, creating a re-identification risk even when images and reports are stored separately. Using held-out pairs from MIMIC-CXR (43,793 pairs) and CheXpert Plus (29,296 pairs), it shows retrieval performance scales with model specialization (up to 50x chance at N=10,000), persists under pathology-matched hard negatives, and can be reduced 61.8% in Recall@1 via differentially private fine-tuning of the projection heads (ε=0.34) with negligible impact on downstream AUROC (79.63% to 79.43%).
Significance. If the empirical measurements hold, the work is significant because it supplies concrete, reproducible retrieval metrics on two public datasets with hard-negative controls and demonstrates a targeted mitigation that largely preserves image utility. The use of known ground-truth pairings as an audit benchmark (rather than claiming direct real-world re-identification) and the transfer of the DP intervention to an external dataset are strengths that make the findings actionable for clinical VLM deployment.
major comments (2)
- [Introduction and Discussion] Introduction and Discussion: The central privacy-risk claim rests on retrieval rates measured in paired cohorts serving as a proxy for re-identification when images and reports are deliberately kept separate. The manuscript correctly frames the paired data as an audit benchmark, yet provides no quantitative bounds, sensitivity analysis, or experiments on how performance would degrade when the report pool is not guaranteed to contain the exact match or under distribution shift between acquisition and deployment pools. This deployment mismatch is load-bearing for translating the reported 15–50× chance figures into actionable risk estimates.
- [§4.3] §4.3 (Hard-negative controls): The pathology-matched negatives are reported to remove disease-label shortcuts, but the exact construction of the negative pools (e.g., matching criteria, number of negatives per query, and verification that no other instance-level cues remain) is not specified in sufficient detail to confirm that the retained signal is truly instance-level rather than residual category-level leakage.
minor comments (2)
- [Table 1 and §4.1] Table 1 and §4.1: The candidate-pool sizes (N=100, N=10,000, full database) are clearly stated, but the exact definition of 'chance' baseline (uniform random or adjusted for pool size) should be stated explicitly in the caption or methods for immediate reproducibility.
- [§5.1] §5.1 (DP fine-tuning): The statement that macro AUROC 'shifted only from 79.63% to 79.43%' is useful, but reporting per-label AUROC changes or confidence intervals would strengthen the claim that utility is 'largely preserved.'
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below, proposing targeted revisions to improve clarity while preserving the manuscript's focus on audit benchmarks.
read point-by-point responses
-
Referee: [Introduction and Discussion] The central privacy-risk claim rests on retrieval rates measured in paired cohorts serving as a proxy for re-identification when images and reports are deliberately kept separate. The manuscript correctly frames the paired data as an audit benchmark, yet provides no quantitative bounds, sensitivity analysis, or experiments on how performance would degrade when the report pool is not guaranteed to contain the exact match or under distribution shift between acquisition and deployment pools. This deployment mismatch is load-bearing for translating the reported 15–50× chance figures into actionable risk estimates.
Authors: We agree that additional context on pool mismatch and shift would aid translation to deployment. The manuscript explicitly positions the paired cohorts as an 'audit benchmark' (abstract: 'used public paired cohorts... as ground-truth benchmarks to audit the risk rather than as the privacy scenario') rather than a direct re-identification simulation. We will add a paragraph in the Discussion acknowledging this scope limitation, noting that exact-match absence would reduce performance to semantic similarity levels and outlining future sensitivity analyses. No new experiments are feasible within the current audit design, but the revision will better bound the claims. revision: partial
-
Referee: [§4.3] §4.3 (Hard-negative controls): The pathology-matched negatives are reported to remove disease-label shortcuts, but the exact construction of the negative pools (e.g., matching criteria, number of negatives per query, and verification that no other instance-level cues remain) is not specified in sufficient detail to confirm that the retained signal is truly instance-level rather than residual category-level leakage.
Authors: We will expand Section 4.3 and the methods appendix with the precise construction details: negatives are drawn from reports sharing identical CheXpert label vectors (14 categories) but different patient IDs, with pool size N yielding N-1 negatives per query. Verification included confirming no systematic differences in report length or metadata across a sampled subset. These additions will confirm the instance-level nature of the retained signal beyond category leakage. revision: yes
Circularity Check
No circularity: purely empirical retrieval measurements on external paired benchmarks
full rationale
The paper reports direct empirical measurements of image-to-report retrieval performance (Recall@K, AUROC) on public paired cohorts (MIMIC-CXR, CheXpert Plus) with known ground-truth pairings. No mathematical derivations, parameter fits presented as predictions, self-definitional quantities, or load-bearing self-citations appear in the provided text. The central quantities are computed from cosine similarity on held-out pairs and hard-negative sets; the DP mitigation is an applied optimization step whose effect is measured, not derived by construction from the risk metric itself. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- epsilon =
0.34
- delta =
6x10-6
axioms (1)
- domain assumption Cosine similarity between image and report embeddings reflects instance-level correspondence beyond broad diagnostic categories.
Reference graph
Works this paper leans on
-
[1]
Medi- cal Image Analysis102, 103514 (2025).https://doi.org/https://doi.org/10.1016/j.media.2025
Lu, Y., Wang, A.: Integrating language into medical visual recognition and reasoning: A survey. Medi- cal Image Analysis102, 103514 (2025).https://doi.org/https://doi.org/10.1016/j.media.2025. 103514
-
[2]
Biomedical Engineering Letters15(5), 845–863 (2025)
Buess, L., Keicher, M., Navab, N., Maier, A., Tayebi Arasteh, S.: From large language models to multimodal ai: a scoping review on the potential of generative ai in medicine. Biomedical Engineering Letters15(5), 845–863 (2025)
2025
-
[3]
Scientific data6(1), 317 (2019)
Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: Mimic-cxr, a de-identified publicly available database of chest radiographs with free- text reports. Scientific data6(1), 317 (2019)
2019
-
[4]
In: Machine learning for healthcare conference
Zhang, Y., Jiang, H., Miura, Y., Manning, C.D., Langlotz, C.P.: Contrastive learning of medical visual representations from paired images and text. In: Machine learning for healthcare conference. pp. 2–25. PMLR (2022)
2022
-
[5]
In: 2021 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV)
Huang, S.C., Shen, L., Lungren, M.P., Yeung, S.: Gloria: A multimodal global-local representa- tion learning framework for label-efficient medical image recognition. In: 2021 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). pp. 3922–3931 (2021).https://doi.org/10.1109/ ICCV48922.2021.00391
arXiv 2021
-
[6]
Garrido, Q., Chen, Y ., Bardes, A., Najman, L., and Le- Cun, Y
Bannur, S., Hyland, S., Liu, Q., Perez-Garcia, F., Ilse, M., Castro, D.C., Boecking, B., Sharma, H., Bouzid, K., Thieme, A., Schwaighofer, A., Wetscherek, M., Lungren, M.P., Nori, A., Alvarez-Valle, J., Oktay, O.: Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing . In: 2023 IEEE/CVF Conference on Computer Vision and Pattern ...
-
[7]
Journal of Medical Imaging and Radiation Oncology57(1), 1–7 (2013)
Goergen, S.K., Pool, F.J., Turner, T.J., Grimm, J.E., Appleyard, M.N., Crock, C., Fahey, M.C., Fay, M.F., Ferris, N.J., Liew, S.M., Perry, R.D., Revell, A., Russell, G.M., Wang, S.c.S., Wriedt, C.: Evidence-based guideline for the written radiology report: Methods, recommendations and im- plementation challenges. Journal of Medical Imaging and Radiation O...
-
[8]
In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) (2021),https://openreview.net/forum?id=pMWtc5NKd7V
Jain, S., Agrawal, A., Saporta, A., Truong, S., Duong, D.N., Bui, T., Chambon, P., Zhang, Y., Lungren, M.P., Ng, A.Y., Langlotz, C., Rajpurkar, P.: Radgraph: Extracting clinical entities and relations from radiology reports. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) (2021),https://openrevi...
2021
-
[9]
Medical Image Analysis92, 103059 (2024)
Truhn, D., Tayebi Arasteh, S., Saldanha, O.L., Müller-Franzes, G., Khader, F., Quirke, P., West, N.P., Gray, R., Hutchins, G.G., James, J.A., Loughrey, M.B., Salto-Tellez, M., Brenner, H., Brobeil, A., Yuan, T., Chang-Claude, J., Hoffmeister, M., Foersch, S., Han, T., Keil, S., Schulze-Hagen, M., Isfort, P., Bruners, P., Kaissis, G., Kuhl, C., Nebelung, S...
-
[10]
npj Digital Medicine9, 93 (2026)
Mohammadi, M., Vejdanihemmat, M., Lotfinia, M., Rusu, M., Truhn, D., Maier, A., Tayebi Arasteh, S.: Differential privacy for medical deep learning: methods, tradeoffs, and deployment implications. npj Digital Medicine9, 93 (2026)
2026
-
[11]
foundations and trends®in theoretical computer science 9 (3-4), 211–407 (2014)
Dwork, C., Roth, A.: The algorithmic foundations of differential privacy. foundations and trends®in theoretical computer science 9 (3-4), 211–407 (2014)
2014
-
[12]
Communications Medicine4(1), 46 (2024)
Tayebi Arasteh, S., Ziller, A., Kuhl, C., Makowski, M., Nebelung, S., Braren, R., Rueckert, D., Truhn, D., Kaissis, G.: Preserving fairness and diagnostic accuracy in private large-scale ai models for medical imaging. Communications Medicine4(1), 46 (2024)
2024
-
[13]
Nature Machine Intelligence6(7), 764–774 (2024)
Ziller, A., Mueller, T.T., Stieger, S., Feiner, L.F., Brandt, J., Braren, R., Rueckert, D., Kaissis, G.: Reconciling privacy and accuracy in ai for medical imaging. Nature Machine Intelligence6(7), 764–774 (2024)
2024
-
[14]
Nature Machine Intelligence3(6), 473–484 (2021)
Kaissis, G., Ziller, A., Passerat-Palmbach, J., Ryffel, T., Usynin, D., Trask, A., Lima Jr, I., Mancuso, J., Jungmann, F., Steinborn, M.M., et al.: End-to-end privacy preserving deep learning on multi- institutional medical imaging. Nature Machine Intelligence3(6), 473–484 (2021)
2021
-
[15]
Radiology309(1), e230806 (2023)
Khader, F., Müller-Franzes, G., Wang, T., Han, T., Tayebi Arasteh, S., Haarburger, C., Stegmaier, J., Bressem, K., Kuhl, C., Nebelung, S., et al.: Multimodal deep learning for integrating chest radiographs and clinical parameters: a case for transformers. Radiology309(1), e230806 (2023)
2023
-
[16]
arXiv preprint arXiv:2604.09537 (2026)
Arasteh, S.T., Joodaki, M., Lotfinia, M., Nebelung, S., Truhn, D.: Case-grounded evidence verification: A framework for constructing evidence-sensitive supervision. arXiv preprint arXiv:2604.09537 (2026)
Pith/arXiv arXiv 2026
-
[17]
arXiv preprint arXiv:2505.21698 (2025)
Li, Y., Ghahremani, M., Wachinger, C.: Medbridge: Bridging foundation vision-language models to medical image diagnosis in chest x-ray. arXiv preprint arXiv:2505.21698 (2025)
Pith/arXiv arXiv 2025
-
[18]
arXiv preprint arXiv:1707.05612 (2017)
Faghri, F., Fleet, D.J., Kiros, J.R., Fidler, S.: Vse++: Improving visual-semantic embeddings with hard negatives. arXiv preprint arXiv:1707.05612 (2017)
Pith/arXiv arXiv 2017
-
[19]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Resea...
2021
-
[20]
Chambon, P., Delbrouck, J.B., Sounack, T., Huang, S.C., Chen, Z., Varma, M., Truong, S.Q., Chuong, C.T., Langlotz, C.P.: Chexpert plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats (2024),https://arxiv.org/abs/2405. 19538
2024
-
[21]
Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., Seekins, J., Mong, D.A., Halabi, S.S., Sandberg, J.K., Jones, R., Lar- son, D.B., Langlotz, C.P., Patel, B.N., Lungren, M.P., Ng, A.Y.: Chexpert: a large chest radiograph dataset with uncertainty labels and expert comparison. In: Pro...
-
[22]
The Bell system technical journal27(3), 379–423 (1948)
Shannon, C.E.: A mathematical theory of communication. The Bell system technical journal27(3), 379–423 (1948)
1948
-
[23]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Chen, W., Shen, L., Lin, J., Luo, J., Li, X., Yuan, Y.: Fine-grained image-text alignment in medi- cal imaging enables explainable cyclic image-report generation. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9494–9509. Association for Computational Linguistics, Bangkok, Thailand (...
2024
-
[24]
Zhang, S., Xu, Y., Usuyama, N., Xu, H., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., Wong, C., Tupini, A., Wang, Y., Mazzola, M., Shukla, S., Liden, L., Gao, J., Crabtree, A., Piening, B., Bifulco, C., Lungren, M.P., Naumann, T., Wang, S., Poon, H.: A multimodal biomedical foundation model trained from fifteen million image–text pairs....
-
[25]
Nature Machine Intelligence2(6), 305–311 (2020)
Kaissis, G.A., Makowski, M.R., Rückert, D., Braren, R.F.: Secure, privacy-preserving and federated machine learning in medical imaging. Nature Machine Intelligence2(6), 305–311 (2020)
2020
-
[26]
(eds.) Findings of the Association for Computational Linguistics: EACL 2023
Eslami, S., Meinel, C., de Melo, G.: PubMedCLIP: How much does CLIP benefit visual question answering in the medical domain? In: Vlachos, A., Augenstein, I. (eds.) Findings of the Association for Computational Linguistics: EACL 2023. pp. 1181–1193. Association for Computational Linguistics, Dubrovnik, Croatia (May 2023).https://doi.org/10.18653/v1/2023.fi...
-
[27]
Radiology: Artificial Intelligence6(1), e230212 (2023)
Tayebi Arasteh, S., Lotfinia, M., Nolte, T., Sähn, M.J., Isfort, P., Kuhl, C., Nebelung, S., Kaissis, G., Truhn, D.: Securing collaborative medical ai by using differential privacy: Domain transfer for classification of chest radiographs. Radiology: Artificial Intelligence6(1), e230212 (2023)
2023
-
[28]
Wind, S., Nguyen, T.T., Sopa, J., Lotfinia, M., Bickelhaup, S., Uder, M., Köstler, H., Wellein, G., Nebelung, S., Truhn, D., Maier, A., Arasteh, S.T.: Safety and accuracy follow different scaling laws in clinical large language models (2026),https://arxiv.org/abs/2605.04039
Pith/arXiv arXiv 2026
-
[29]
Radiology: Artificial Intelligence8(3), e260346 (2026)
Tayebi Arasteh, S., Truhn, D.: When framing shapes the answer: Cognitive bias and large language model reliability in radiology. Radiology: Artificial Intelligence8(3), e260346 (2026)
2026
-
[30]
In: Proceedings of the 2016 ACM SIGSAC conference on computer and communications security
Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., Zhang, L.: Deep learning with differential privacy. In: Proceedings of the 2016 ACM SIGSAC conference on computer and communications security. pp. 308–318 (2016)
2016
-
[31]
Scientific Reports13(1), 6046 (2023)
Tayebi Arasteh, S., Isfort, P., Saehn, M., Mueller-Franzes, G., Khader, F., Kather, J.N., Kuhl, C., Nebelung, S., Truhn, D.: Collaborative training of medical artificial intelligence models with non- uniform labels. Scientific Reports13(1), 6046 (2023)
2023
-
[32]
Lotfinia, M., Tayebiarasteh, A., Samiei, S., Joodaki, M., Tayebi Arasteh, S.: Boosting multi- demographic federated learning for chest radiograph analysis using general-purpose self-supervised representations. European Journal of Radiology Artificial Intelligence3, 100028 (2025).https: //doi.org/https://doi.org/10.1016/j.ejrai.2025.100028
-
[33]
European Radiology Experimental8(1), 10 (2024)
Tayebi Arasteh, S., Misera, L., Kather, J.N., Truhn, D., Nebelung, S.: Enhancing diagnostic deep learn- ing via self-supervised pretraining on large-scale, unlabeled non-medical images. European Radiology Experimental8(1), 10 (2024)
2024
-
[34]
Sabottke,C.F.,Spieler,B.M.:Theeffectofimageresolutionondeeplearninginradiography.Radiology: Artificial Intelligence2(1), e190015 (2020)
2020
-
[35]
In: International Conference on Learning Representations (ICLR) (2019),https://openreview.net/forum?id=Bkg6RiCqY7
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (ICLR) (2019),https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[36]
In: International conference on machine learning (ICML)
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: International conference on machine learning (ICML). pp. 448–456. pmlr (2015)
2015
-
[37]
npj Artificial Intelligence1(1), 37 (2025)
Tayebi Arasteh, S., Lotfinia, M., Perez-Toro, P.A., Arias-Vergara, T., Ranji, M., Orozco-Arroyave, J.R., Schuster, M., Maier, A., Yang, S.H.: Differential privacy enables fair and accurate ai-based analysis of speech disorders while protecting patient data. npj Artificial Intelligence1(1), 37 (2025)
2025
-
[38]
In: Proceedings of the European conference on computer vision (ECCV)
Wu, Y., He, K.: Group normalization. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
2018
-
[39]
In: Li, Y., Mandt, S., Agrawal, S., Khan, E
Rusak, E., Reizinger, P., Juhos, A., Bringmann, O., Zimmermann, R.S., Brendel, W.: Infonce: Iden- tifying the gap between theory and practice. In: Li, Y., Mandt, S., Agrawal, S., Khan, E. (eds.) Proceedings of The 28th International Conference on Artificial Intelligence and Statistics. Proceed- ings of Machine Learning Research, vol. 258, pp. 4159–4167. P...
2025
-
[40]
van den Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding (2019),https://arxiv.org/abs/1807.03748
Pith/arXiv arXiv 2019
-
[41]
In: 2017 IEEE 30th computer security foundations symposium (CSF)
Mironov, I.: Rényi differential privacy. In: 2017 IEEE 30th computer security foundations symposium (CSF). pp. 263–275. IEEE (2017)
2017
-
[42]
Monographs on statistics and applied probability57(1), 1–436 (1993)
Tibshirani, R.J., Efron, B.: An introduction to the bootstrap. Monographs on statistics and applied probability57(1), 1–436 (1993)
1993
-
[43]
Neural computation10(7), 1895–1923 (1998)
Dietterich, T.G.: Approximate statistical tests for comparing supervised classification learning algo- rithms. Neural computation10(7), 1895–1923 (1998)
1923
-
[44]
Statistics and Computing24(3), 283–296 (2014) 26
Konietschke, F., Pauly, M.: Bootstrapping and permuting paired t-test type statistics. Statistics and Computing24(3), 283–296 (2014) 26
2014
-
[45]
Yousefpour, A., Shilov, I., Sablayrolles, A., Testuggine, D., Prasad, K., Malek, M., Nguyen, J., Ghosh, S.,Bharadwaj,A.,Zhao,J.,Cormode,G.,Mironov,I.:Opacus:User-friendlydifferentialprivacylibrary in PyTorch. In: NeurIPS Workshop on Privacy in Machine Learning (2021) 27 Supplementary information Supplementary Table 1: Full retrieval results on MIMIC-CXR u...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.