MemRepair: Hierarchical Memory for Agentic Repository-Level Vulnerability Repair
Pith reviewed 2026-05-19 23:02 UTC · model grok-4.3
The pith
MemRepair equips LLM repair agents with three persistent memory layers so they can reuse past fixes, security patterns, and refinement paths when fixing vulnerabilities across large code repositories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
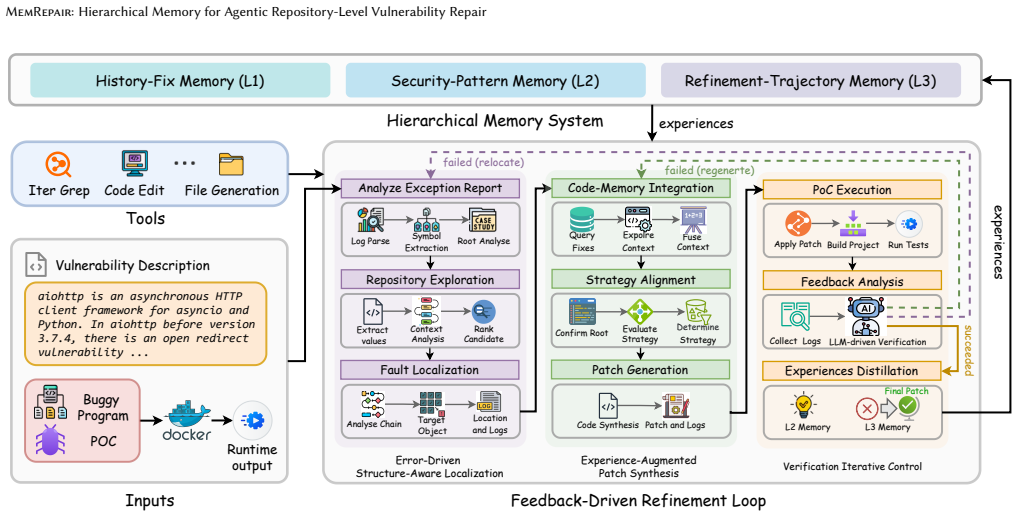
MemRepair formulates repository-level vulnerability repair as an iterative experience-driven process that retrieves from three complementary memory layers—History-Fix, Security-Pattern, and Refinement-Trajectory—inside a dynamic feedback loop, allowing the agent to apply prior fixes, reusable security patterns, and lessons from failed validations to produce more reliable patches.
What carries the argument
The three-layer hierarchical memory (History-Fix for repository conventions, Security-Pattern for defenses, Refinement-Trajectory for failure-to-success paths) retrieved at runtime inside a feedback-driven refinement loop.
If this is right
- Agents become able to reuse repository-specific repair conventions across similar projects instead of rediscovering them.
- Security patterns learned from one fix can be applied to prevent analogous vulnerabilities in later tasks.
- Prior failed validation attempts supply concrete evidence that lets the agent revise semantically invalid patches.
- The same memory structure supports repair across Python, Go, JavaScript, and C++ without language-specific redesign.
Where Pith is reading between the lines
- External memory could let future agents operate with smaller context windows while still handling long repair histories.
- The refinement-trajectory layer might transfer to other iterative tasks such as test generation or performance tuning.
- If retrieval stays accurate, the approach suggests a path toward agents whose repair quality improves over successive tasks on the same codebase.
Load-bearing premise
The three memory layers can be retrieved and applied at runtime without introducing retrieval errors or latency that cancel out the gains on complex multi-file repairs.
What would settle it
A controlled experiment on a new multi-file benchmark where the same base agent with the memory layers disabled shows equal or higher resolution rates and lower average cost than the full MemRepair system.
Figures



read the original abstract
Modern software ecosystems face a rapidly growing number of disclosed vulnerabilities, increasing the need for automated repair techniques that can operate reliably at repository scale. Although Large Language Model (LLM)-based agents have recently shown promise for automated vulnerability repair (AVR), most existing systems still treat repair as a single generation step over the currently visible code context. As a result, they lack a persistent mechanism for reusing prior fixes or learning from failed validation attempts, which limits their effectiveness on complex, multi-file repair tasks. We present MemRepair, a memory-augmented agentic framework that formulates vulnerability repair as an iterative, experience-driven process. MemRepair combines three complementary memory layers, i.e., History-Fix, Security-Pattern, and Refinement-Trajectory memories, with a dynamic feedback-driven refinement loop. This design allows the agent to retrieve repository-specific repair conventions, apply reusable security defenses, and exploit prior "failure-to-success" trajectories to revise semantically invalid patches based on runtime evidence. We evaluate MemRepair on three representative repository-level vulnerability repair benchmarks: SEC-Bench, PatchEval (Python, Go, JavaScript), and the C++ subset of Multi-SWE-bench. MemRepair achieves state-of-the-art resolution rates of 58.0%, 58.2%, and 30.58%, respectively, outperforming strong general-purpose agents such as OpenHands and SWE-agent, as well as the specialized AVR tool InfCode-C++, while maintaining competitive repair cost. These results show that persistent, hierarchical repair memory can substantially improve the reliability of agentic vulnerability repair across diverse languages and repository settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemRepair, a memory-augmented agentic framework for repository-level vulnerability repair. It introduces three memory layers—History-Fix, Security-Pattern, and Refinement-Trajectory—integrated with a refinement loop to enable iterative, experience-driven patch generation. The framework is evaluated on SEC-Bench, PatchEval, and Multi-SWE-bench (C++), achieving claimed state-of-the-art resolution rates of 58.0%, 58.2%, and 30.58% respectively, outperforming baselines like OpenHands, SWE-agent, and InfCode-C++.
Significance. Should the empirical gains hold under rigorous controls for evaluation protocol and memory retrieval accuracy, this work would represent a meaningful advance in agentic repair systems by showing how hierarchical memory can improve handling of complex, multi-file vulnerabilities across languages. It directly targets the limitation of stateless generation in current LLM agents.
major comments (3)
- Evaluation section: The reported resolution rates of 58.0% on SEC-Bench, 58.2% on PatchEval, and 30.58% on Multi-SWE-bench C++ are presented without ablation studies that isolate the contribution of each memory layer (History-Fix, Security-Pattern, Refinement-Trajectory) versus the refinement loop or base agent. This leaves the central attribution of gains to the hierarchical memory unverified.
- Evaluation section: No retrieval-precision, recall, or error-analysis metrics are provided for the three memory layers. Since the framework relies on runtime retrieval of repository-specific fixes, patterns, and trajectories to succeed on multi-file repairs, the absence of these diagnostics means it is unclear whether the SOTA numbers reflect successful memory use or other factors.
- Experiments section: The evaluation protocol lacks detail on statistical significance, number of runs, temperature/prompt controls, and safeguards against data leakage or benchmark contamination. These omissions weaken support for the performance claims against the named baselines.
minor comments (1)
- Abstract: The phrase 'competitive repair cost' is used without defining the metric (e.g., LLM calls, tokens, or wall-clock time) or supplying the corresponding baseline numbers for direct comparison.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the evaluation sections.
read point-by-point responses
-
Referee: Evaluation section: The reported resolution rates of 58.0% on SEC-Bench, 58.2% on PatchEval, and 30.58% on Multi-SWE-bench C++ are presented without ablation studies that isolate the contribution of each memory layer (History-Fix, Security-Pattern, Refinement-Trajectory) versus the refinement loop or base agent. This leaves the central attribution of gains to the hierarchical memory unverified.
Authors: We agree that dedicated ablation studies are necessary to rigorously attribute performance gains to the individual memory layers and the refinement loop. In the revised manuscript, we will add a new subsection in the evaluation with ablations that systematically disable each memory component (History-Fix, Security-Pattern, Refinement-Trajectory) and the refinement loop, reporting the resulting resolution rates on all benchmarks. This will provide direct evidence for the contribution of the hierarchical memory design. revision: yes
-
Referee: Evaluation section: No retrieval-precision, recall, or error-analysis metrics are provided for the three memory layers. Since the framework relies on runtime retrieval of repository-specific fixes, patterns, and trajectories to succeed on multi-file repairs, the absence of these diagnostics means it is unclear whether the SOTA numbers reflect successful memory use or other factors.
Authors: We acknowledge this gap in the current evaluation. We will incorporate retrieval precision and recall metrics for each of the three memory layers, computed over the successful repairs. Furthermore, we will add an error analysis section that categorizes failure cases related to memory retrieval inaccuracies versus other issues, such as patch generation errors. These additions will clarify the role of memory retrieval in achieving the reported performance. revision: yes
-
Referee: Experiments section: The evaluation protocol lacks detail on statistical significance, number of runs, temperature/prompt controls, and safeguards against data leakage or benchmark contamination. These omissions weaken support for the performance claims against the named baselines.
Authors: We will revise the Experiments section to provide comprehensive details on the evaluation protocol. This includes specifying the number of independent runs (e.g., 3 runs with different seeds), temperature settings used (e.g., 0.2 for generation), prompt engineering controls, and statistical significance testing (such as reporting p-values from McNemar's test for comparisons with baselines). We will also detail safeguards against data leakage, including verification that no benchmark instances were present in the LLM's training data and use of version-controlled repositories for evaluation. revision: yes
Circularity Check
No circularity: empirical framework evaluation on public benchmarks
full rationale
The paper introduces MemRepair as a memory-augmented agentic framework with three described memory layers and a refinement loop, then reports empirical resolution rates on SEC-Bench, PatchEval, and Multi-SWE-bench subsets. No equations, fitted parameters, or derivation steps appear in the provided abstract or evaluation summary. Claims rest on experimental comparisons against baselines rather than any self-definitional reduction, fitted-input prediction, or load-bearing self-citation chain. The central results are therefore independent of the inputs by construction and receive a score of 0.
Axiom & Free-Parameter Ledger
invented entities (3)
-
History-Fix memory
no independent evidence
-
Security-Pattern memory
no independent evidence
-
Refinement-Trajectory memory
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MemRepair combines three complementary memory layers, i.e., History-Fix, Security-Pattern, and Refinement-Trajectory memories, with a dynamic feedback-driven refinement loop.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L3 Refinement-Trajectory Memory stores failure-to-success trajectories... guiding iterative patch refinement
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2026. Common Weakness Enumeration. https://cwe.mitre.org/. Accessed: 2026-01-15. MemRepair: Hierarchical Memory for Agentic Repository-Level Vulnerability Repair
work page 2026
-
[2]
National Vulnerability Database (NVD)
2026. National Vulnerability Database (NVD). https://nvd.nist.gov/. Accessed: 2026-01-15
work page 2026
-
[3]
Aider. 2024. Introducing Aider. https://aider.chat/ Accessed: 2026-01-15
work page 2024
-
[4]
Alfred Asare Amoah and Yan Liu. 2025. Explainable Recommendation of Soft- ware Vulnerability Repair Based on Metadata Retrieval and Multifaceted LLMs. Machine Learning and Knowledge Extraction7, 4 (2025). doi:10.3390/make7040149
-
[5]
Guru Bhandari, Amara Naseer, and Leon Moonen. 2021. CVEfixes: automated collection of vulnerabilities and their fixes from open-source software. InProceed- ings of the 17th International Conference on Predictive Models and Data Analytics in Software Engineering. 30–39
work page 2021
-
[6]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2024. Repairagent: An autonomous, llm-based agent for program repair.arXiv preprint arXiv:2403.17134 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Quang-Cuong Bui, Ranindya Paramitha, Duc-Ly Vu, Fabio Massacci, and Ric- cardo Scandariato. 2024. APR4Vul: an empirical study of automatic program repair techniques on real-world Java vulnerabilities.Empirical software engineer- ing29, 1 (2024), 18
work page 2024
-
[8]
Xiansheng Cao, Junfeng Wang, and Peng Wu. 2025. Enhancing vulnerability repair through the extraction and matching of repair patterns.Journal of Systems and Software(2025), 112528
work page 2025
-
[9]
2024.6 Vulnerability Management Challenges (and How To Overcome Them)
Cyware. 2024.6 Vulnerability Management Challenges (and How To Overcome Them). https://cyware.com/ Accessed: 2026-01-12
work page 2024
-
[10]
Qingao Dong, Mengfei Wang, Hengzhi Zhang, Zhichao Li, Yuan Yuan, Mu Li, Xiang Gao, Hailong Sun, Chunming Hu, and Weifeng Lv. 2025. InfCode-C++: Intent-Guided Semantic Retrieval and AST-Structured Search for C++ Issue Resolution. arXiv:2511.16005 [cs.SE] https://arxiv.org/abs/2511.16005
-
[11]
Michael Fu, Chakkrit Tantithamthavorn, Trung Le, Van Nguyen, and Dinh Phung
-
[12]
VulRepair: a T5-based automated software vulnerability repair. InPro- ceedings of the 30th ACM joint european software engineering conference and symposium on the foundations of software engineering. 935–947
-
[13]
Michael Fu, Chakkrit Kla Tantithamthavorn, Van Nguyen, and Trung Le. 2023. Chatgpt for vulnerability detection, classification, and repair: How far are we?. In 2023 30th Asia-Pacific Software Engineering Conference (APSEC). IEEE, 632–636
work page 2023
-
[14]
Xiang Gao, Bo Wang, Gregory J Duck, Ruyi Ji, Yingfei Xiong, and Abhik Roy- choudhury. 2021. Beyond tests: Program vulnerability repair via crash constraint extraction.ACM Transactions on Software Engineering and Methodology (TOSEM) 30, 2 (2021), 1–27
work page 2021
-
[15]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al . 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
- [17]
-
[18]
Zhen Huang, David Lie, Gang Tan, and Trent Jaeger. 2019. Using safety properties to generate vulnerability patches. InIEEE Symposium on Security and Privacy (SP)
work page 2019
-
[19]
Nan Jiang, Thibaud Lutellier, and Lin Tan. 2021. Cure: Code-aware neural machine translation for automatic program repair. In2021 IEEE/ACM 43rd Inter- national Conference on Software Engineering (ICSE). IEEE, 1161–1173
work page 2021
-
[20]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
-
[22]
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. 2011. Genprog: A generic method for automatic software repair.Ieee transactions on software engineering38, 1 (2011), 54–72
work page 2011
- [23]
- [24]
- [25]
- [26]
-
[27]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. TBar: Revisiting template-based automated program repair. InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis. 31–42
work page 2019
-
[28]
Penghui Liu, Yingzhou Bi, Jiangtao Huang, Xinxin Jiang, and Lianmei Wang
- [29]
- [30]
- [31]
-
[32]
OpenAI. 2024. Text Embedding Models: text-embedding-3-small. https://platform. openai.com/docs/guides/embeddings. Accessed: 2026-01-13
work page 2024
-
[33]
Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Brendan Dolan-Gavitt. 2023. Examining zero-shot vulnerability repair with large language models. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2339–2356
work page 2023
-
[34]
Zichao Qi, Fan Long, Sara Achour, and Martin Rinard. 2015. An analysis of patch plausibility and correctness for generate-and-validate patch generation systems. InProceedings of the 2015 international symposium on software testing and analysis. 24–36
work page 2015
-
[35]
2025.H1 2025 Malware and Vulnerability Trends
Recorded Future. 2025.H1 2025 Malware and Vulnerability Trends. https: //www.recordedfuture.com/ Accessed: 2026-01-12
work page 2025
-
[36]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sun- daresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: a Method for Automatic Evaluation of Code Synthesis. arXiv:2009.10297 [cs.SE] https://arxiv.org/abs/2009.10297
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [37]
-
[38]
Tianqi Shen, Shaohua Liu, Jiaqi Feng, Ziye Ma, and Ning An. 2025. Topology- Aware 3D Gaussian Splatting: Leveraging Persistent Homology for Optimized Structural Integrity. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 6823–6832
work page 2025
-
[39]
Shailja Thakur et al . 2024. VRPilot: Larger Language Models for Automated Vulnerability Repair.arXiv preprint(2024)
work page 2024
-
[40]
2024.Vulnerability Remediation: Complete Process, Challenges, and Automated Best Practices
Vicarius. 2024.Vulnerability Remediation: Complete Process, Challenges, and Automated Best Practices. https://www.vicarius.io/ Accessed: 2026-01-12
work page 2024
-
[41]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [42]
-
[43]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. Demystifying llm-based software engineering agents.Proceedings of the ACM on Software Engineering2, FSE (2025), 801–824
work page 2025
-
[44]
Chunqiu Steven Xia, Yifeng Ding, and Lingming Zhang. 2023. The plastic surgery hypothesis in the era of large language models. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 522– 534
work page 2023
-
[45]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 819–831
work page 2024
-
[46]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 819–831
work page 2024
-
[47]
Jifeng Xuan, Matias Martinez, Favio Demarco, Maxime Clement, Sebastian Lame- las Marcote, Thomas Durieux, Daniel Le Berre, and Martin Monperrus. 2016. Nopol: Automatic repair of conditional statement bugs in java programs.IEEE Transactions on Software Engineering43, 1 (2016), 34–55
work page 2016
-
[49]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
work page 2024
-
[50]
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang
-
[51]
InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis
Thinkrepair: Self-directed automated program repair. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1274–1286
-
[52]
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, et al. 2025. Multi-swe-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605 Liu et al. (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Chenyuan Zhang, Hao Liu, Jiutian Zeng, Kejing Yang, Yuhong Li, and Hui Li. 2024. Prompt-enhanced software vulnerability detection using chatgpt. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings. 276–277
work page 2024
- [54]
-
[55]
Yufeng Zhang, Zhenbang Chen, Ziqi Shuai, Tianqi Zhang, Kenli Li, and Ji Wang
-
[56]
In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering
Multiplex symbolic execution: Exploring multiple paths by solving once. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. 846–857
-
[57]
Yuntong Zhang, Xiang Gao, Gregory J Duck, and Abhik Roychoudhury. 2022. Program vulnerability repair via inductive inference. InProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA)
work page 2022
-
[58]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Autocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592– 1604
work page 2024
- [59]
-
[60]
Xin Zhou, Kisub Kim, Bowen Xu, DongGyun Han, and David Lo. 2024. Large Language Model as Synthesizer: Fusing Diverse Inputs for Better Automatic Vulnerability Repair.CoRRabs/2401.15459 (2024). https://doi.org/10.48550/arXiv. 2401.15459
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[61]
Tingwei Zhu, Tongtong Xu, Kui Liu, Jiayuan Zhou, Xing Hu, Xin Xia, Tian Zhang, and David Lo. 2024. An Empirical Study of Automatic Program Repair Techniques for Injection Vulnerabilities. In2024 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 25–37. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.