Polynomial Context-Truncation Sensitivity in Autoregressive Language Models: Sequential Wyner-Ziv Bounds for KV Cache Compression
Pith reviewed 2026-06-29 23:44 UTC · model grok-4.3
The pith
Under a polynomial truncation-sensitivity assumption, suffix-only KV cache policies require memory scaling as Θ(ε^{-1/α}) to achieve distortion ε.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
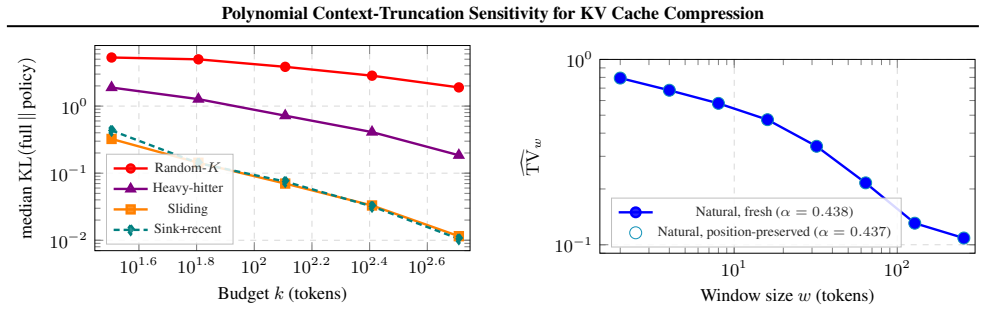
Under the polynomial truncation-sensitivity assumption, the per-token memory requirement of suffix-only cache policies is characterized: a sliding-window scheme attains distortion ε with window w = O(ε^{-1/α}), and under an additional two-sided Bayes-risk condition a converse shows w = Ω(ε^{-1/α}) is necessary within this policy class, so the scaling is Θ(ε^{-1/α}) for suffix-only policies. An explicit block-Markov scheme achieves the upper bound.
What carries the argument
The polynomial truncation-sensitivity assumption that next-token distribution sensitivity to context truncation decays as a power law with truncation distance, inside a sequential Wyner-Ziv formulation of KV cache compression.
If this is right
- Sliding-window caches achieve the optimal scaling among all suffix-only policies under the stated assumptions.
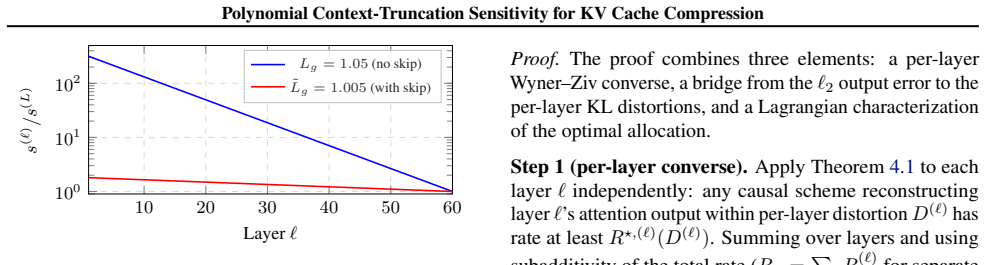
- An explicit block-Markov scheme attains the upper bound, with rate-of-convergence exponent matching the converse under forward-decay and regularity hypotheses.
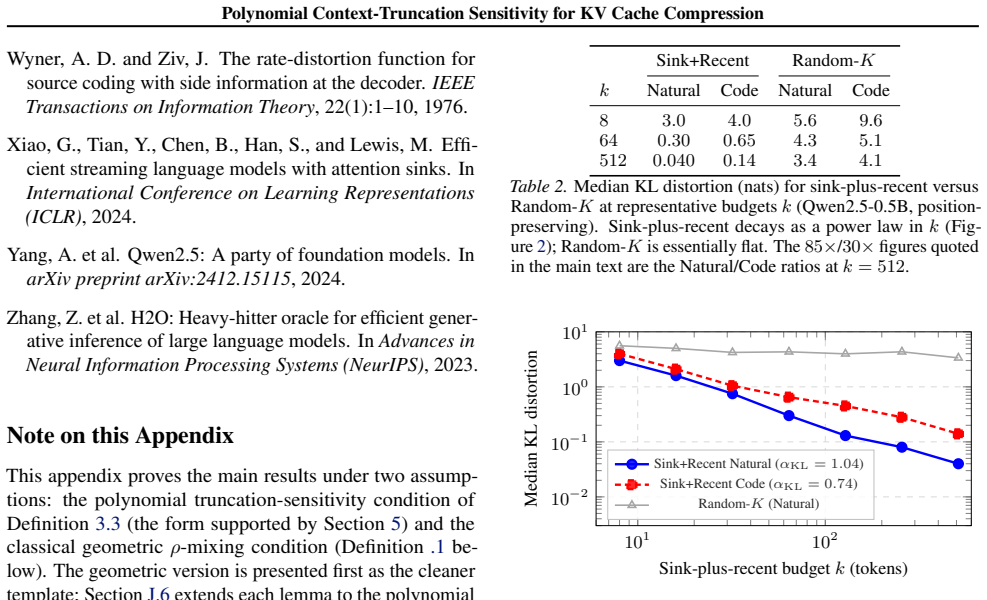
- Recency-based eviction (sliding or sink-plus-recent) suppresses distortion by roughly two orders of magnitude over random retention at equal budget.
- The fitted polynomial law predicts the observed degradation curves of concrete cache policies across models.
Where Pith is reading between the lines
- Whether recurrent or propagating cache summaries can beat the Θ(ε^{-1/α}) scaling for suffix-only policies remains open by the paper's own statement.
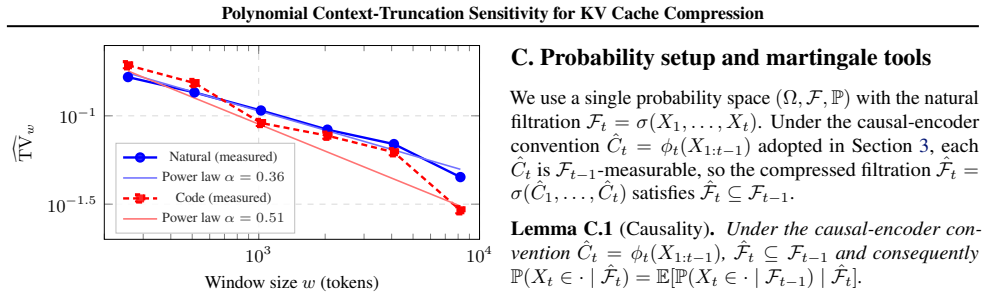
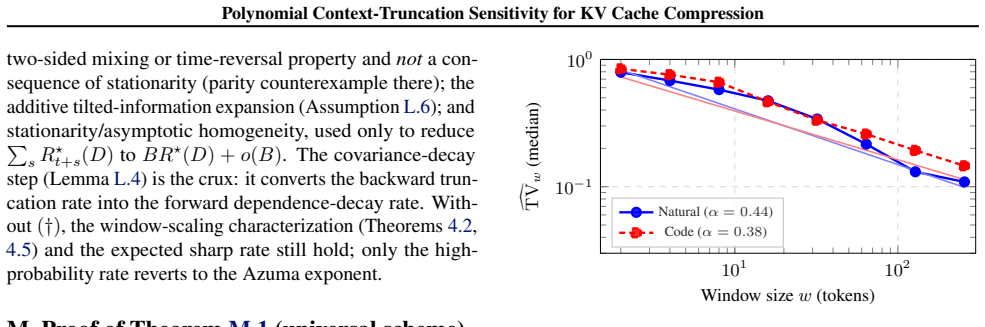
- The empirical power-law fit recovered independently from sink-plus-recent KL measurements suggests the assumption may hold across a range of model sizes and families.
- Position-preserving ablation confirms the decay is not an artifact of positional encodings, pointing toward a test on models without such encodings.
Load-bearing premise
The next-token distribution's sensitivity to context truncation decays polynomially rather than geometrically with truncation distance.
What would settle it
A measurement showing that the KL divergence between next-token distributions with and without the oldest w tokens decays exponentially in w rather than polynomially would falsify the assumption and collapse the Θ(ε^{-1/α}) scaling claim.
Figures

read the original abstract
We study the rate-distortion limits of online KV cache compression in autoregressive language models, formulating it as sequential Wyner-Ziv source coding on the filtration induced by the model, with the next-step query as decoder side information. Empirically, across four models spanning two families and $0.5$-$3$B parameters, we find that the next-token distribution's sensitivity to context truncation decays \emph{polynomially} rather than \emph{geometrically}: a power law improves on an exponential fit by an order of magnitude in extrapolation, the fitted exponent is recovered independently from a sink-plus-recent KL measurement, and the decay is verified to be free of positional-encoding artifacts by a position-preserving ablation. Under a corresponding \emph{polynomial truncation-sensitivity} assumption, our main result characterizes the per-token memory requirement of \emph{suffix-only} cache policies: a sliding-window scheme attains distortion $\varepsilon$ with window $w = O(\varepsilon^{-1/\alpha})$, and -- under an additional two-sided Bayes-risk condition -- a converse shows $w = \Omega(\varepsilon^{-1/\alpha})$ is necessary within this policy class, so the scaling is $\Theta(\varepsilon^{-1/\alpha})$ for suffix-only policies. Whether recurrent or propagating cache summaries can beat this scaling is left open. An explicit block-Markov scheme achieves the upper bound; its rate-of-convergence exponent matches the converse under additional forward-decay and regularity hypotheses (not implied by truncation sensitivity alone), and differs by a factor of two otherwise. Empirically, the polynomial law predicts the degradation curves of concrete cache policies: recency-based eviction (sliding, sink-plus-recent) suppresses distortion by roughly two orders of magnitude over random retention at equal budget, with a power-law decay in the budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically demonstrates that next-token distribution sensitivity to context truncation in autoregressive LMs decays polynomially (rather than geometrically) across multiple models, and under a corresponding polynomial truncation-sensitivity assumption formulates KV cache compression as sequential Wyner-Ziv coding; it shows that suffix-only policies (e.g., sliding-window) attain distortion ε with window size O(ε^{-1/α}), and under an additional two-sided Bayes-risk condition establishes a matching Ω lower bound, yielding Θ(ε^{-1/α}) scaling, with an explicit block-Markov scheme achieving the upper bound (whose exponent matches the converse only under further hypotheses).
Significance. If the polynomial assumption and bounds hold, the result supplies the first information-theoretic scaling law for suffix-only KV cache compression, explaining why recency-based policies outperform random retention by orders of magnitude and guiding practical memory-distortion trade-offs; the cross-model empirical support and independent exponent recovery are notable strengths, though the additional conditions required for tightness limit the scope of the central characterization.
major comments (2)
- [Abstract / main result] Abstract and main result statement: the Θ(ε^{-1/α}) characterization for suffix-only policies rests on the two-sided Bayes-risk condition for the converse, which the text explicitly states is additional and 'not implied by truncation sensitivity alone' (as also noted for the block-Markov exponent match); without a proof relating this condition to the core polynomial assumption or an empirical verification on the induced filtration, the necessity direction is not established and the claim reduces to an O upper bound.
- [Empirical section] Empirical verification paragraph: the claim that the fitted exponent α is 'recovered independently from a sink-plus-recent KL measurement' is central to supporting the polynomial law, yet no quantitative match statistic, confidence interval, or extrapolation error comparison between the two measurements is provided; this leaves open whether the recovery is statistically robust or coincidental.
minor comments (1)
- [Problem formulation] Notation for the filtration and side-information query should be introduced with an explicit diagram or equation reference in the problem formulation to aid readability for readers outside information theory.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below. Both points identify areas where the presentation can be strengthened, and we will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / main result] Abstract and main result statement: the Θ(ε^{-1/α}) characterization for suffix-only policies rests on the two-sided Bayes-risk condition for the converse, which the text explicitly states is additional and 'not implied by truncation sensitivity alone' (as also noted for the block-Markov exponent match); without a proof relating this condition to the core polynomial assumption or an empirical verification on the induced filtration, the necessity direction is not established and the claim reduces to an O upper bound.
Authors: We agree that the Θ(ε^{-1/α}) scaling for suffix-only policies is established only conditionally on the two-sided Bayes-risk assumption, as already stated in the manuscript. The upper bound O(ε^{-1/α}) holds under the polynomial truncation-sensitivity assumption alone. To make the conditional nature of the converse fully explicit, we will revise the abstract and the statement of the main result to foreground that the matching lower bound requires the additional condition. No proof linking the Bayes-risk condition to truncation sensitivity is available, and we do not claim one. revision: yes
-
Referee: [Empirical section] Empirical verification paragraph: the claim that the fitted exponent α is 'recovered independently from a sink-plus-recent KL measurement' is central to supporting the polynomial law, yet no quantitative match statistic, confidence interval, or extrapolation error comparison between the two measurements is provided; this leaves open whether the recovery is statistically robust or coincidental.
Authors: We acknowledge the absence of quantitative support for the independent exponent recovery. In the revised manuscript we will add R² values and 95% confidence intervals for the exponents obtained from both the direct truncation-sensitivity fit and the sink-plus-recent KL measurement, together with a direct comparison of extrapolation error on held-out context lengths. These additions will allow readers to assess the statistical robustness of the recovery. revision: yes
Circularity Check
No circularity: theoretical bounds derived from stated assumption with independent empirical motivation
full rationale
The paper motivates a polynomial truncation-sensitivity assumption via empirical fits (power-law decay verified independently via multiple measurements and ablations) but then derives the O(ε^{-1/α}) upper bound and conditional Ω lower bound as mathematical consequences of that assumption plus an explicitly noted extra Bayes-risk condition. The scaling expression uses the fitted α as a parameter of the assumption rather than re-deriving or predicting the same fitted quantity. The abstract itself flags that the block-Markov exponent match requires further hypotheses 'not implied by truncation sensitivity alone,' avoiding any claim that the full Θ result follows from the core assumption. No self-citations, self-definitional steps, or fitted-input-as-prediction reductions appear in the provided derivation outline.
Axiom & Free-Parameter Ledger
free parameters (1)
- exponent α =
empirically fitted
axioms (1)
- domain assumption Polynomial truncation-sensitivity assumption
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Ainslie, J. et al. GQA : Training generalized multi-query transformer models from multi-head checkpoints. In Proceedings of EMNLP, 2023
2023
-
[3]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Allal, L. B., Lozhkov, A., Bakouch, E., Bl \'a gojevi \'c , G. M., Penedo, G., Kydl \' c ek, H., et al. Smollm2: When smol goes big -- data-centric training of a small language model. arXiv preprint arXiv:2502.02737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
H., and Zoccolan, D
Ansuini, A., Laio, A., Macke, J. H., and Zoccolan, D. Intrinsic dimension of data representations in deep neural networks. In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[5]
and Tatikonda, S
Behmin, M. and Tatikonda, S. Multi-task rate-distortion: theory and applications. IEEE Trans. Inf. Theory, 2022
2022
-
[6]
Bennett, W. R. Spectra of quantized signals. Bell System Technical Journal, 27 0 (3): 0 446--472, 1948
1948
-
[7]
Concentration Inequalities: A Nonasymptotic Theory of Independence
Boucheron, S., Lugosi, G., and Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013
2013
-
[8]
Bradley, R. C. Basic properties of strong mixing conditions: A survey and some open questions. Probability Surveys, 2: 0 107--144, 2005
2005
-
[9]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Cai, Z., Zhang, Y., Gao, B., Liu, Y., Liu, T., Lu, K., Xiong, W., Dong, Y., Chang, B., Hu, J., and Xiao, W. PyramidKV : Dynamic KV cache compression based on pyramidal information funneling. arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
and Lugosi, G
Cesa-Bianchi, N. and Lugosi, G. Prediction, Learning, and Games. Cambridge University Press, 2006
2006
-
[11]
D., Stavrou, P
Charalambous, C. D., Stavrou, P. A., and Ahmed, N. U. Nonanticipative rate distortion function and relations to filtering theory. IEEE Transactions on Automatic Control, 59 0 (4): 0 937--952, 2013
2013
-
[12]
LongLoRA : Efficient fine-tuning of long-context large language models
Chen, Y., Qian, S., Tang, H., Lai, X., Liu, Z., Han, S., and Jia, J. LongLoRA : Efficient fine-tuning of long-context large language models. In International Conference on Learning Representations (ICLR), 2024
2024
-
[13]
Cover, T. M. and Thomas, J. A. Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006
2006
-
[14]
and K \"o rner, J
Csisz \'a r, I. and K \"o rner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems. Cambridge University Press, 2nd edition, 2011
2011
-
[15]
and Shields, P
Csisz \'a r, I. and Shields, P. C. Information theory and statistics: A tutorial. Now Publishers, 2004
2004
-
[16]
Lipschitz normalization for self-attention layers with application to graph neural networks
Dasoulas, G., Scaman, K., and Virmaux, A. Lipschitz normalization for self-attention layers with application to graph neural networks. In International Conference on Machine Learning (ICML), 2021
2021
-
[17]
DeepSeek-V2 : A strong, economical, and efficient mixture-of-experts language model, 2024
DeepSeek-AI . DeepSeek-V2 : A strong, economical, and efficient mixture-of-experts language model, 2024
2024
-
[18]
Attention is not all you need: Pure attention loses rank doubly exponentially with depth
Dong, Y., Cordonnier, J.-B., and Loukas, A. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. In Proceedings of the 38th International Conference on Machine Learning (ICML), pp.\ 2793--2803, 2021
2021
-
[19]
Subgeometric rates of convergence of f -ergodic strong Markov processes
Douc, R., Fort, G., and Guillin, A. Subgeometric rates of convergence of f -ergodic strong Markov processes. Stochastic Processes and their Applications, 119 0 (3): 0 897--923, 2009
2009
-
[20]
Markov Chains
Douc, R., Moulines, E., Priouret, P., and Soulier, P. Markov Chains. Springer, 2018
2018
-
[21]
and Kim, Y.-H
El Gamal, A. and Kim, Y.-H. Network Information Theory. Cambridge University Press, 2011
2011
-
[22]
Feng, Y., Lv, J., Cao, Y., Xie, X., and Zhou, S. K. Ada-KV : Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference. arXiv preprint arXiv:2407.11550, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Freedman, D. A. On tail probabilities for martingales. The Annals of Probability, 3 0 (1): 0 100--118, 1975
1975
-
[24]
Model tells you what to discard: Adaptive KV cache compression for LLMs
Ge, S., Zhang, Y., Liu, L., Zhang, M., Han, J., and Gao, J. Model tells you what to discard: Adaptive KV cache compression for LLMs . In International Conference on Learning Representations (ICLR), 2024
2024
-
[25]
Geiger, B. C. and Koch, T. Rate-distortion dimension of stochastic processes. In IEEE International Symposium on Information Theory (ISIT), 2016. arXiv:1607.06792
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Asymptotically optimal block quantization
Gersho, A. Asymptotically optimal block quantization. IEEE Transactions on Information Theory, 25 0 (4): 0 373--380, 1979
1979
-
[27]
A mathematical perspective on transformers
Geshkovski, B., Letrouit, C., Polyanskiy, Y., and Rigollet, P. A mathematical perspective on transformers. arXiv preprint arXiv:2312.10794, 2023
-
[28]
Transformer feed-forward layers are key-value memories
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. In EMNLP, 2021
2021
-
[29]
Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7B , 2023
2023
-
[30]
GEAR : An efficient KV cache compression recipe for near-lossless generative inference of LLM , 2024
Kang, H., Zhang, Q., Kundu, S., Jeong, G., Liu, Z., Krishna, T., and Zhao, T. GEAR : An efficient KV cache compression recipe for near-lossless generative inference of LLM , 2024
2024
-
[31]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[32]
and Dembo, A
Kawabata, T. and Dembo, A. The rate-distortion dimension of sets and measures. IEEE Transactions on Information Theory, 40 0 (5): 0 1564--1572, 1994
1994
-
[33]
The Lipschitz constant of self-attention
Kim, H., Papamakarios, G., and Mnih, A. The Lipschitz constant of self-attention. In Proceedings of the 38th International Conference on Machine Learning (ICML), pp.\ 5562--5571, 2021
2021
-
[34]
and Tuncel, E
Kostina, V. and Tuncel, E. Multiterminal source coding: fundamental limits and algorithms. Foundations and Trends in Communications and Information Theory, 2022
2022
-
[35]
and Verd \'u , S
Kostina, V. and Verd \'u , S. Fixed-length lossy compression in the finite blocklength regime. IEEE Transactions on Information Theory, 58 0 (6): 0 3309--3338, 2012
2012
-
[36]
SnapKV : LLM knows what you are looking for before generation
Li, Y., Huang, Y., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., and Chen, D. SnapKV : LLM knows what you are looking for before generation. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[37]
KIVI : a tuning-free asymmetric 2bit quantization for KV cache, 2024
Liu, Z., Yuan, J., Jin, H., Zhong, S., Xu, Z., Braverman, V., Chen, B., and Hu, X. KIVI : a tuning-free asymmetric 2bit quantization for KV cache, 2024
2024
-
[38]
Liu, Z. et al. Scissorhands : Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[39]
Mahmood, A. and Wagner, A. B. Minimax rate-distortion. IEEE Transactions on Information Theory, 2024. arXiv:2202.04481
-
[40]
Massey, J. L. Causality, feedback and directed information. In Proceedings of the International Symposium on Information Theory and its Applications (ISITA), pp.\ 303--305, 1990
1990
-
[41]
Meta AI . The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Phuong, M. and Hutter, M. Formal algorithms for transformers. arXiv preprint arXiv:2207.09238, 2022
-
[43]
Piantadosi, S. T. Zipf's word frequency law in natural language: A critical review and future directions. Psychonomic Bulletin and Review, 21: 0 1112--1130, 2014
2014
-
[44]
The intrinsic dimension of images and its impact on learning
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., and Goldstein, T. The intrinsic dimension of images and its impact on learning. In International Conference on Learning Representations (ICLR), 2021
2021
-
[45]
Universal coding, information, prediction, and estimation
Rissanen, J. Universal coding, information, prediction, and estimation. IEEE Transactions on Information Theory, 30 0 (4): 0 629--636, 1984
1984
-
[46]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[47]
Quest : Query-aware sparsity for efficient long-context LLM inference
Tang, J., Zhao, Y., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest : Query-aware sparsity for efficient long-context LLM inference. In International Conference on Machine Learning (ICML), 2024
2024
-
[48]
Dispersion of Gaussian Sources with Memory and an Extension to Abstract Sources
Tasci, E. and Kostina, V. Dispersion of Gaussian sources with memory and an extension to abstract sources. arXiv preprint arXiv:2602.09176, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Tsybakov, A. B. Introduction to nonparametric estimation. Springer, 2009
2009
-
[50]
N., Kaiser, L., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. Advances in Neural Information Processing Systems, 2017
2017
-
[51]
Probability with Martingales
Williams, D. Probability with Martingales. Cambridge University Press, 1991
1991
-
[52]
Witsenhausen, H. S. Indirect rate distortion problems. IEEE Transactions on Information Theory, 26 0 (5): 0 518--521, 1980
1980
-
[53]
Wyner, A. D. and Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Transactions on Information Theory, 22 0 (1): 0 1--10, 1976
1976
-
[54]
Efficient streaming language models with attention sinks
Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M. Efficient streaming language models with attention sinks. In International Conference on Learning Representations (ICLR), 2024
2024
-
[55]
Yang, A. et al. Qwen2.5: A party of foundation models. In arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Zhang, Z. et al. H2O : Heavy-hitter oracle for efficient generative inference of large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.