The State-Prediction Separation Hypothesis
Pith reviewed 2026-07-02 12:23 UTC · model grok-4.3
The pith
Separating state storage from next-token prediction improves Transformer performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
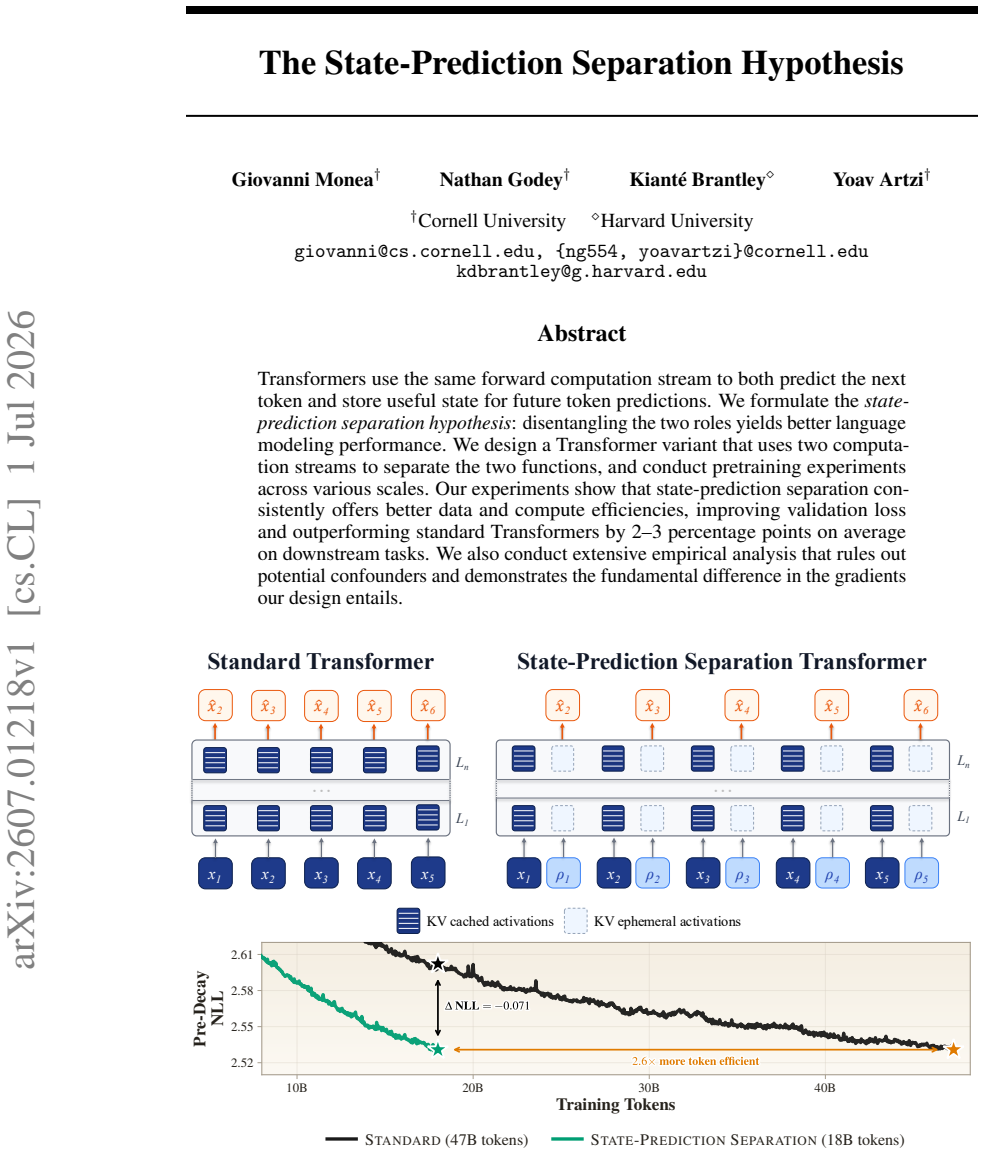
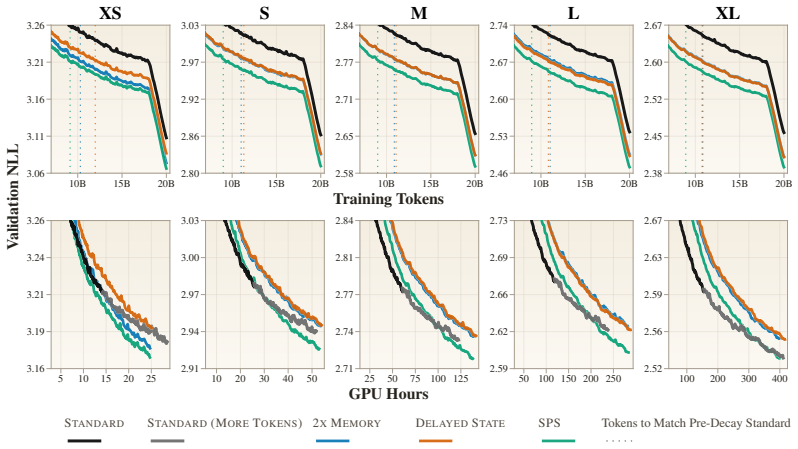
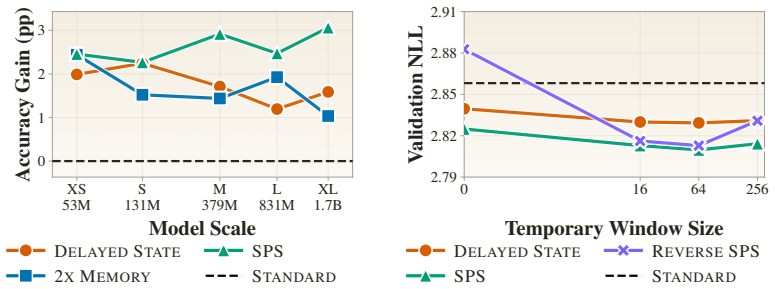
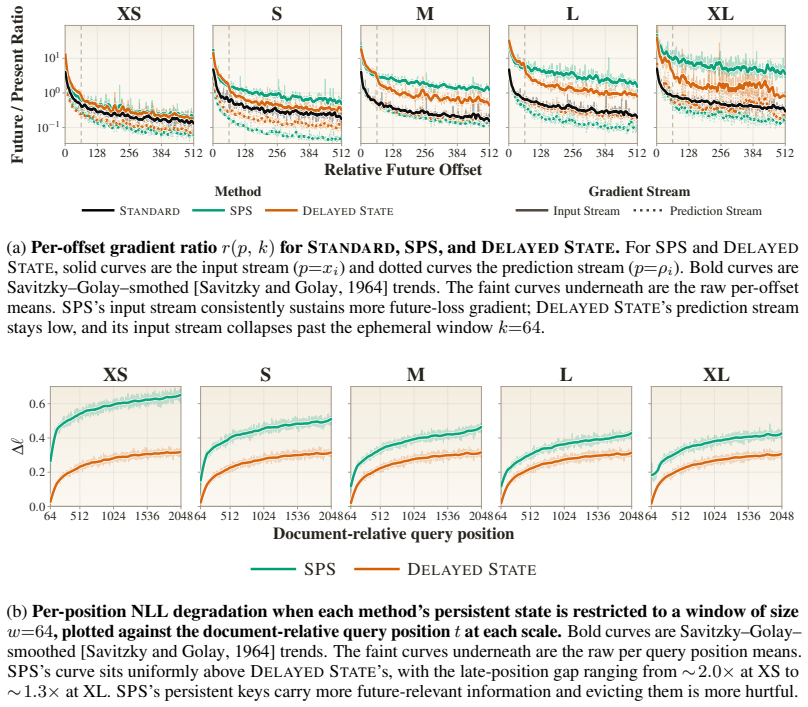
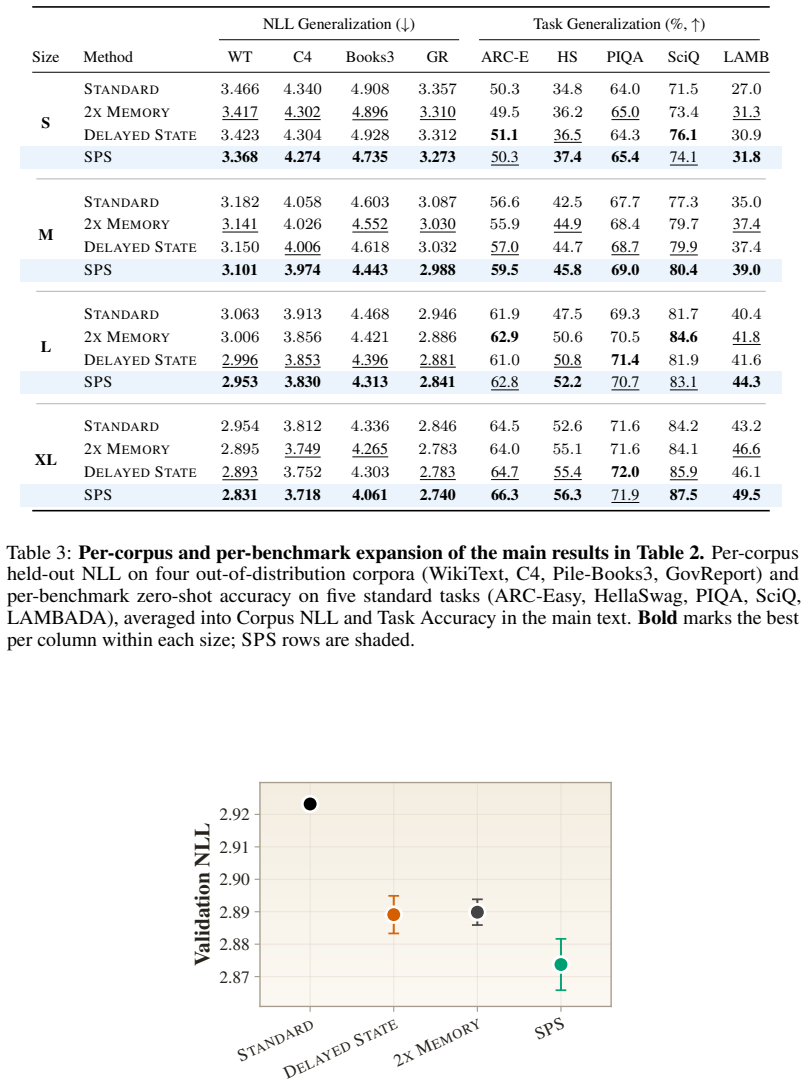
Transformers use the same forward computation stream to both predict the next token and store useful state for future token predictions. Disentangling the two roles by using two computation streams yields better language modeling performance, improving validation loss and outperforming standard Transformers by 2--3 percentage points on average on downstream tasks.
What carries the argument
A two-stream Transformer variant that assigns state storage to one stream and next-token prediction to the other.
Load-bearing premise
The state storage and next-token prediction roles can be cleanly separated into independent streams without losing essential interactions that the single-stream architecture needs for effective learning.
What would settle it
A matched-scale pretraining run in which the two-stream model shows no improvement in validation loss or downstream performance relative to a standard single-stream Transformer.
Figures
read the original abstract
Transformers use the same forward computation stream to both predict the next token and store useful state for future token predictions. We formulate the \emph{state-prediction separation hypothesis}: disentangling the two roles yields better language modeling performance. We design a Transformer variant that uses two computation streams to separate the two functions, and conduct pretraining experiments across various scales. Our experiments show that state-prediction separation consistently offers better data and compute efficiencies, improving validation loss and outperforming standard Transformers by 2--3 percentage points on average on downstream tasks. We also conduct extensive empirical analysis that rules out potential confounders and demonstrates the fundamental difference in the gradients our design entails.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates the state-prediction separation hypothesis, claiming that disentangling state storage and next-token prediction into two independent computation streams in a Transformer yields better language modeling. Pretraining experiments across scales report consistent gains in validation loss and data/compute efficiency, plus 2--3 percentage point average improvements on downstream tasks; extensive analysis is said to rule out confounders and demonstrate fundamental gradient differences.
Significance. If the empirical claims hold, the result would be a notable architectural contribution for more efficient Transformers. Credit is due for the multi-scale experiments, explicit controls for confounders, and gradient analysis; these elements go beyond single-run comparisons and provide falsifiable distinctions from the baseline.
major comments (2)
- [Methods / Architecture description] The two-stream architecture is introduced without a precise specification of stream interaction, information flow between streams, or parameter allocation (e.g., how the separation is realized in the forward and backward passes). This detail is load-bearing for the central claim that essential interactions are preserved while yielding the reported gains.
- [Empirical analysis section] The gradient analysis is asserted to show fundamental differences that explain the performance advantage, yet no quantitative metrics, statistical tests, or direct comparisons (e.g., gradient norms, cosine similarities, or layer-wise statistics) are supplied to substantiate the distinction from standard Transformer gradients.
minor comments (2)
- [Abstract] Downstream tasks, evaluation metrics, and exact baselines are not enumerated in the abstract or summary results, which would allow readers to gauge the practical magnitude of the 2--3 pp gains.
- [Experimental setup] The manuscript would benefit from an explicit statement of total parameter count and FLOPs for the two-stream model versus the matched Transformer baseline to confirm efficiency claims are not confounded by capacity differences.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our state-prediction separation hypothesis. We address each major comment below with proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / Architecture description] The two-stream architecture is introduced without a precise specification of stream interaction, information flow between streams, or parameter allocation (e.g., how the separation is realized in the forward and backward passes). This detail is load-bearing for the central claim that essential interactions are preserved while yielding the reported gains.
Authors: We agree that a more precise architectural specification is necessary to substantiate the central claim. In the revised manuscript, we will expand the Methods section to include: (i) explicit equations for the forward passes of the state and prediction streams, (ii) details on cross-stream attention or concatenation mechanisms governing information flow, (iii) parameter allocation (separate weights per stream with no unintended sharing), and (iv) a description of gradient flow in the backward pass. A supplementary diagram will illustrate the two-stream computation graph. revision: yes
-
Referee: [Empirical analysis section] The gradient analysis is asserted to show fundamental differences that explain the performance advantage, yet no quantitative metrics, statistical tests, or direct comparisons (e.g., gradient norms, cosine similarities, or layer-wise statistics) are supplied to substantiate the distinction from standard Transformer gradients.
Authors: We acknowledge that the gradient analysis section would benefit from additional quantitative support. In revision, we will augment this section with direct comparisons including gradient norm statistics, cosine similarities between gradients from the separated streams versus the baseline Transformer, layer-wise gradient distributions, and appropriate statistical tests (e.g., t-tests or Wilcoxon tests) to establish the significance of observed differences. These additions will provide falsifiable evidence for the claimed fundamental gradient distinctions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper formulates the state-prediction separation hypothesis as an empirical claim and tests it via a two-stream Transformer variant through pretraining experiments at multiple scales. Reported gains in validation loss and downstream performance (2-3 points) are presented as measured outcomes of the architectural change, accompanied by gradient analysis and controls for confounders. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present; the central results rest on external experimental evidence rather than reducing to the hypothesis by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Two independent computation streams
no independent evidence
Reference graph
Works this paper leans on
-
[1]
First Conference on Language Modeling , year=
Do Language Models Plan Ahead for Future Tokens? , author=. First Conference on Language Modeling , year=
-
[2]
The Twelfth International Conference on Learning Representations , year=
Think before you speak: Training Language Models With Pause Tokens , author=. The Twelfth International Conference on Learning Representations , year=
-
[3]
Monea, Giovanni and Joulin, Armand and Grave, Edouard , journal=
-
[4]
The Thirteenth International Conference on Learning Representations , year=
Long Context Compression with Activation Beacon , author=. The Thirteenth International Conference on Learning Representations , year=
-
[5]
2026 , url=
Breadcrumbs Reasoning: Memory-Efficient Reasoning with Compression Beacons , author=. 2026 , url=
2026
-
[6]
2023 , eprint=
Accelerating Large Language Model Decoding with Speculative Sampling , author=. 2023 , eprint=
2023
-
[7]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[8]
and Golay, M
Savitzky, Abraham. and Golay, M. J. E. , title =. Analytical Chemistry , volume =. 1964 , doi =
1964
-
[9]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[10]
The Twelfth International Conference on Learning Representations , year=
The Expressive Power of Transformers with Chain of Thought , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
2020 , eprint=
GLU Variants Improve Transformer , author=. 2020 , eprint=
2020
-
[12]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[13]
Proceedings of the 41st International Conference on Machine Learning , pages =
The Pitfalls of Next-Token Prediction , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[14]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Multi-Token Prediction Needs Registers , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[15]
2024 , eprint=
DeepSeek-V3 Technical Report , author=. 2024 , eprint=
2024
-
[16]
The Thirteenth International Conference on Learning Representations , year=
The Belief State Transformer , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
Blockwise Parallel Decoding for Deep Autoregressive Models , url =
Stern, Mitchell and Shazeer, Noam and Uszkoreit, Jakob , booktitle =. Blockwise Parallel Decoding for Deep Autoregressive Models , url =
-
[18]
Bowman , booktitle=
Jacob Pfau and William Merrill and Samuel R. Bowman , booktitle=. Let. 2024 , url=
2024
-
[19]
The Twelfth International Conference on Learning Representations , year=
Vision Transformers Need Registers , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[21]
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State , url=
Pal, Koyena and Sun, Jiuding and Yuan, Andrew and Wallace, Byron and Bau, David , year=. Future Lens: Anticipating Subsequent Tokens from a Single Hidden State , url=. doi:10.18653/v1/2023.conll-1.37 , booktitle=
-
[22]
Root Mean Square Layer Normalization , url =
Zhang, Biao and Sennrich, Rico , booktitle =. Root Mean Square Layer Normalization , url =
-
[23]
2021 , eprint=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2021 , eprint=
2021
-
[24]
2019 , journal=
Language Models are Unsupervised Multitask Learners , author=. 2019 , journal=
2019
-
[25]
The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[26]
GitHub repository , howpublished =
Andrej Karpathy , title =. GitHub repository , howpublished =. 2022 , publisher =
2022
-
[27]
2024 , eprint=
Flex Attention: A Programming Model for Generating Optimized Attention Kernels , author=. 2024 , eprint=
2024
-
[28]
FlashAttention: Fast and Memory-Efficient Exact Attention with
Tri Dao and Daniel Y Fu and Stefano Ermon and Atri Rudra and Christopher Re , booktitle=. FlashAttention: Fast and Memory-Efficient Exact Attention with. 2022 , url=
2022
-
[29]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[30]
Advances in Neural Information Processing Systems , editor=
An empirical analysis of compute-optimal large language model training , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[31]
Bridging Planning and Reasoning in Natural Language with Foundational Models , year=
Next-Latent Prediction Transformers Learn Compact World Models , author=. Bridging Planning and Reasoning in Natural Language with Foundational Models , year=
-
[32]
2025 , eprint=
Efficient Joint Prediction of Multiple Future Tokens , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
Better & Faster Large Language Models via Multi-token Prediction , author=. 2024 , eprint=
2024
-
[34]
2024 , eprint=
Will we run out of data? Limits of LLM scaling based on human-generated data , author=. 2024 , eprint=
2024
-
[35]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[36]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2020 , issue_date =
2020
-
[37]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor , journal=. The
-
[38]
Efficient Attentions for Long Document Summarization
Huang, Luyang and Cao, Shuyang and Parulian, Nikolaus and Ji, Heng and Wang, Lu. Efficient Attentions for Long Document Summarization. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.112
-
[39]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[40]
HellaSwag: Can a Machine Really Finish Your Sentence? , booktitle =
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin. H ella S wag: Can a Machine Really Finish Your Sentence?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1472
-
[41]
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. The Thirty-Fourth. 2020 , url =. doi:10.1609/AAAI.V34I05.6239 , timestamp =
-
[42]
Welbl, Johannes and Liu, Nelson F. and Gardner, Matt. Crowdsourcing Multiple Choice Science Questions. Proceedings of the 3rd Workshop on Noisy User-generated Text. 2017. doi:10.18653/v1/W17-4413
-
[43]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Paperno, Denis and Kruszewski, Germ \'a n and Lazaridou, Angeliki and Pham, Ngoc Quan and Bernardi, Raffaella and Pezzelle, Sandro and Baroni, Marco and Boleda, Gemma and Fern \'a ndez, Raquel. The LAMBADA dataset: Word prediction requiring a broad discourse context. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (...
-
[44]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[45]
Neural Machine Translation by Jointly Learning to Align and Translate , booktitle =
Dzmitry Bahdanau and Kyunghyun Cho and Yoshua Bengio , editor =. Neural Machine Translation by Jointly Learning to Align and Translate , booktitle =. 2015 , url =
2015
-
[46]
XLNet: Generalized Autoregressive Pretraining for Language Understanding , url =
Yang, Zhilin and Dai, Zihang and Yang, Yiming and Carbonell, Jaime and Salakhutdinov, Russ R and Le, Quoc V , booktitle =. XLNet: Generalized Autoregressive Pretraining for Language Understanding , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.