Enhancing Numerical Prediction in LLMs via Smooth MMD Alignment
Pith reviewed 2026-06-29 04:47 UTC · model grok-4.3
The pith
Smooth MMD alignment with value-distance kernels and graph smoothness improves numeric prediction accuracy in LLMs over cross-entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
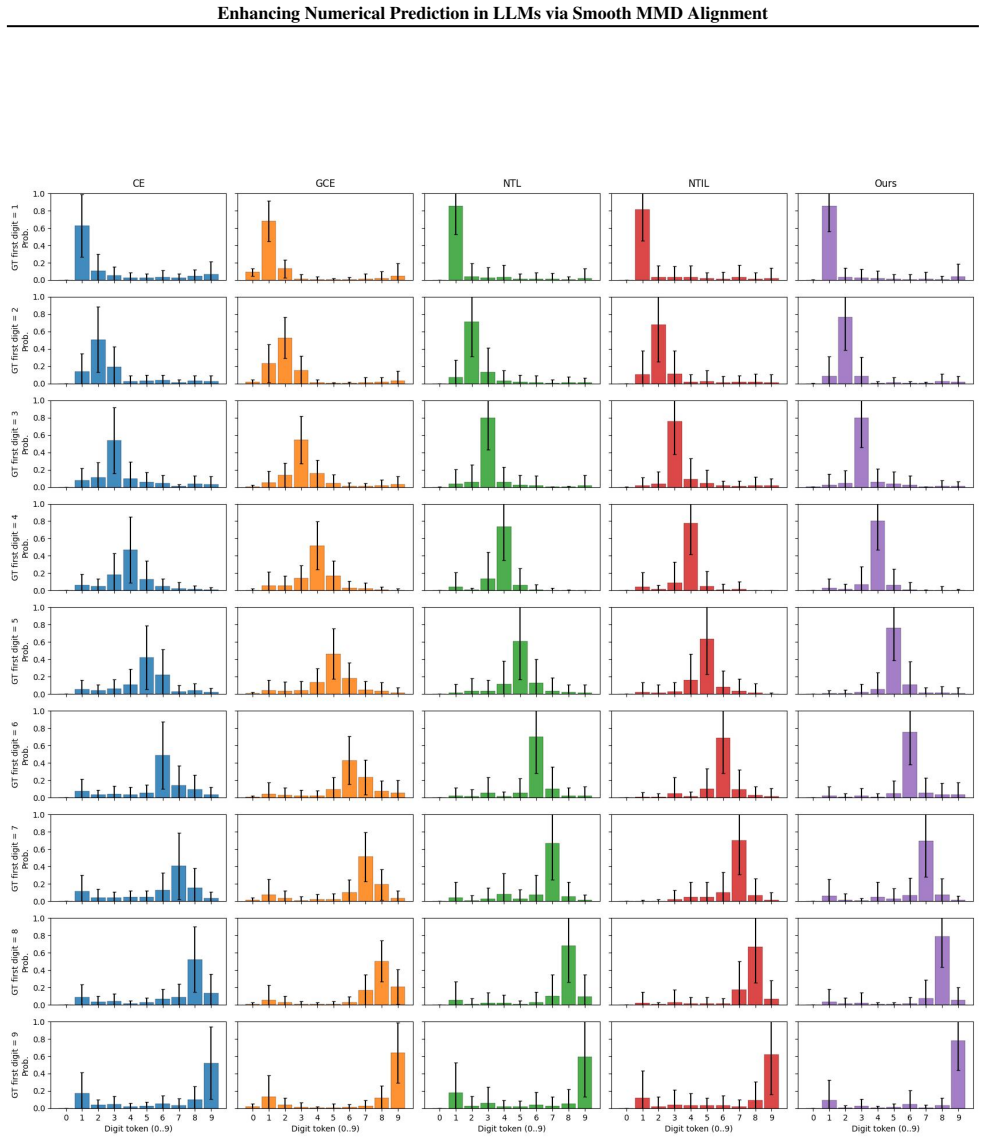
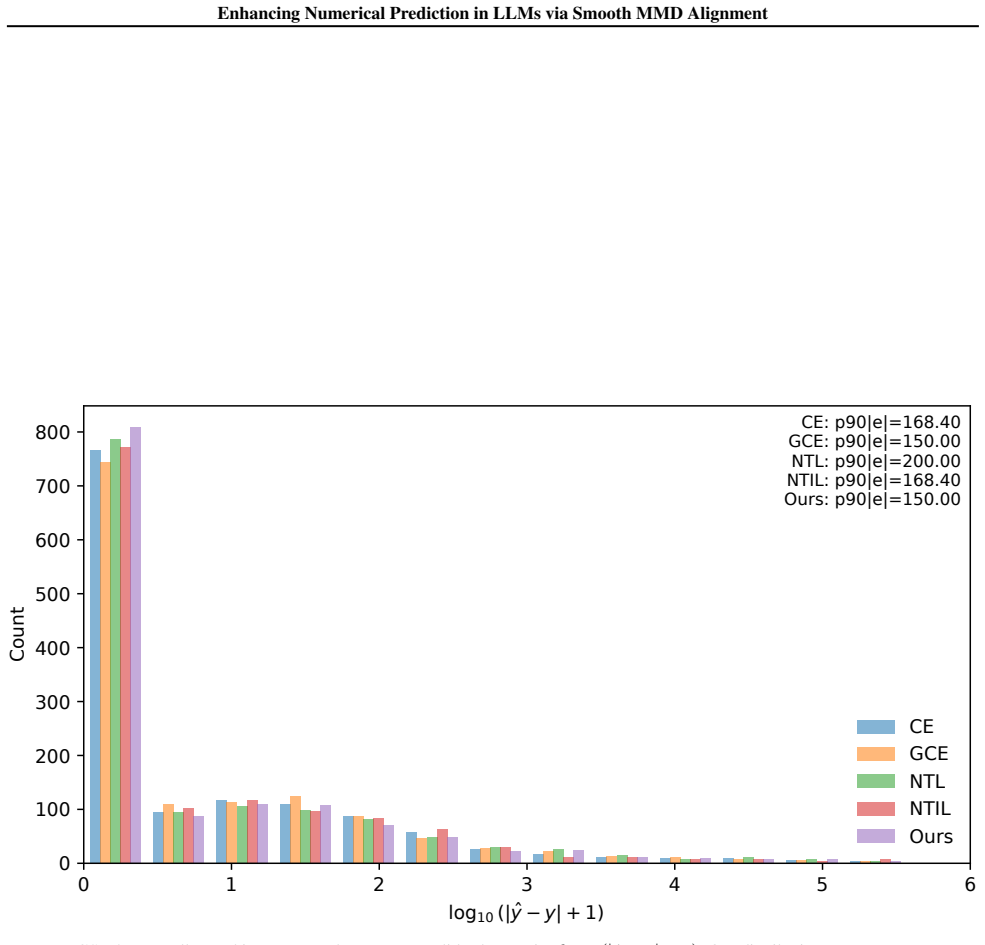
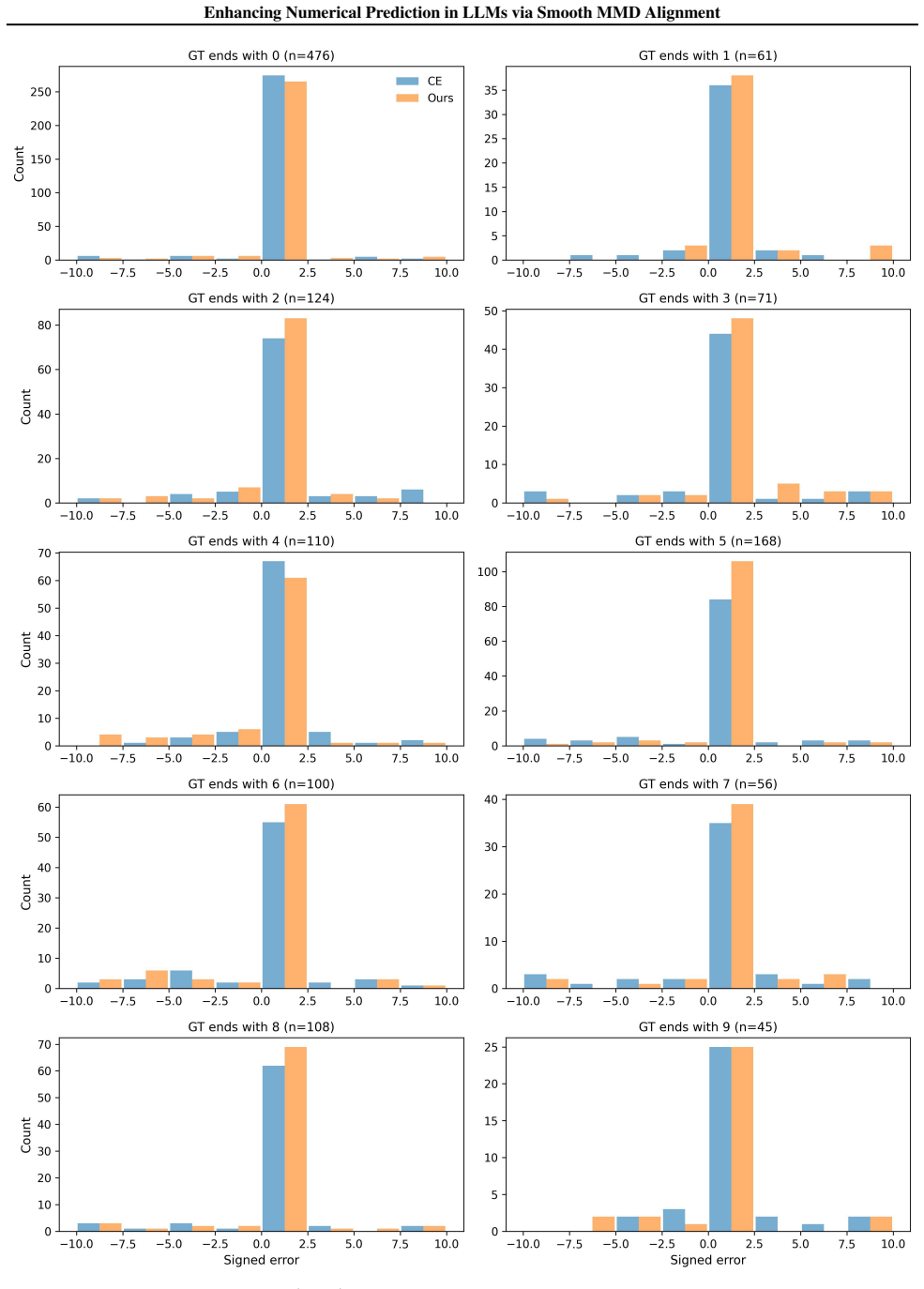
SMMD builds on classic MMD by defining kernels over a numeric sub-vocabulary according to value distances, aligns the model's output distribution to the target via this kernel matching, and applies graph-based smoothness to the prediction-target residual over the induced kernel graph, yielding higher accuracy than cross-entropy or prior numeric losses on four numeric-target tasks.
What carries the argument
Smooth Maximum Mean Discrepancy (SMMD) loss, which performs kernel matching on value-distance kernels over numeric tokens and smooths the residual over the induced kernel graph.
If this is right
- SMMD raises accuracy on mathematical reasoning, arithmetic calculation, clock-time recognition, and chart question answering.
- The MMD kernel-matching term and the smoothness term produce complementary gains.
- Distance-based kernel design is required for the observed improvements.
- The loss applies across multiple open-weight LLM and VLM backbones without architecture changes.
Where Pith is reading between the lines
- The same kernel-plus-smoothness construction could extend to other ordered token sets such as dates or measurement units.
- SMMD may reduce specific numeric hallucination patterns that standard alignment methods leave untouched.
- Interactions between SMMD and post-training methods like RLHF remain untested and could either reinforce or dilute the numeric alignment.
- Over-smoothing risk might appear first on tasks with wide numeric ranges or sparse target distributions.
Load-bearing premise
Defining a kernel over a numeric sub-vocabulary and applying graph-based smoothness on the induced kernel graph will produce local consistency without introducing new biases or over-smoothing effects that degrade performance on some numeric ranges.
What would settle it
Running the four tasks with SMMD and finding no accuracy gain or outright degradation relative to cross-entropy and recent numeric losses on any backbone would falsify the improvement claim.
Figures
read the original abstract
Despite their strong general capabilities, large language models (LLMs) often remain unreliable when outputs must be numerically precise. A key reason is the training objective: standard cross-entropy treats numeric tokens as unstructured categories and ignores the metric structure of their values. We address this mismatch with Smooth Maximum Mean Discrepancy (SMMD), which builds on the classic MMD by incorporating value-distance kernels over numeric tokens and graph-based smoothness. With this kernel defined over a numeric sub-vocabulary, SMMD aligns the predicted numeric distribution to the target via kernel matching and smooths the prediction-target residual over the induced kernel graph to encourage local consistency. We evaluate SMMD on four numeric-target tasks: mathematical reasoning, arithmetic calculation, clock-time recognition, and chart question answering, across multiple open-weight LLM and VLM backbones. SMMD consistently improves accuracy over both cross-entropy and recent numeric-target losses; analyses show complementary effects between MMD and smoothness and underscore the importance of distance-based kernel design. Code is available at https://github.com/Zuozhuo/smmd-loss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Smooth Maximum Mean Discrepancy (SMMD) as a training objective for LLMs to improve numerical prediction accuracy. SMMD extends MMD by using kernels based on value distances over numeric tokens and applies graph-based smoothness to encourage local consistency in predictions. The method is evaluated on four tasks—mathematical reasoning, arithmetic calculation, clock-time recognition, and chart question answering—using multiple open-weight LLM and VLM backbones, with claims of consistent improvements over cross-entropy and recent numeric-target losses. Analyses highlight complementary effects of MMD and smoothness, and the importance of distance-based kernels. Code is made available.
Significance. If the empirical claims hold, this provides a principled way to incorporate numeric metric structure into LLM training, potentially enhancing performance on tasks requiring precise numeric outputs without architectural changes. The release of code supports reproducibility and further research. The approach could have broad impact in applications like math reasoning and visual QA involving numbers.
major comments (1)
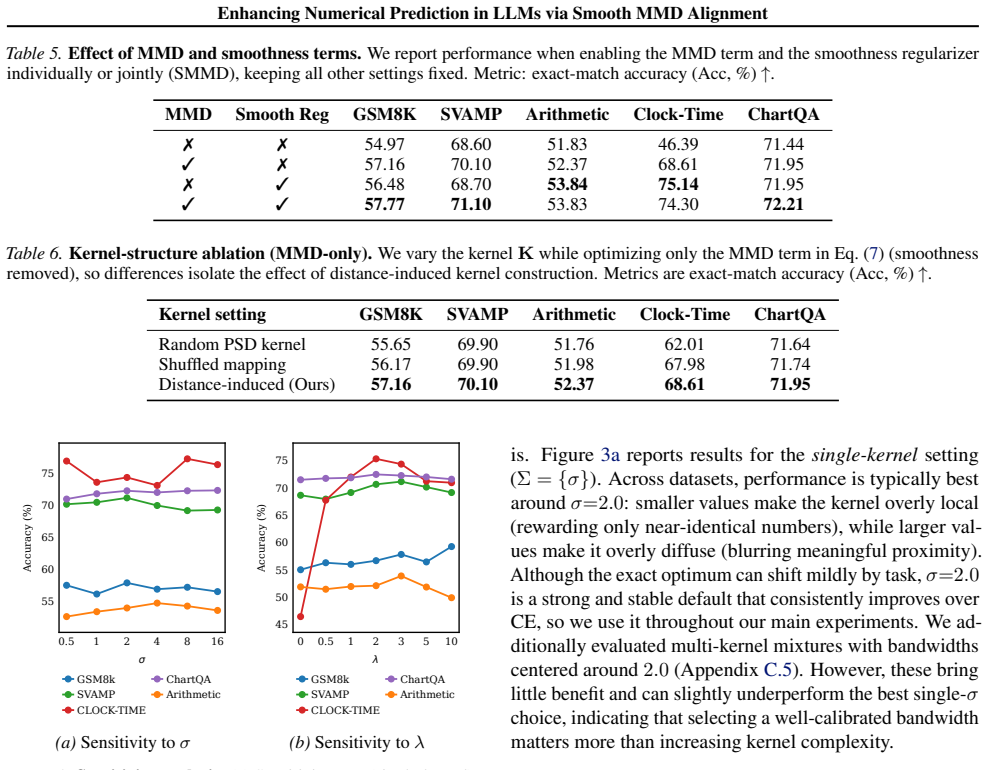
- [§4] §4 (Experiments): the central claim of 'consistent improvements' across four tasks and multiple backbones is presented without reported statistical significance tests, standard deviations across seeds, or confidence intervals on the accuracy deltas; this weakens the ability to assess whether gains are reliable or could be due to variance.
minor comments (2)
- [Abstract] Abstract: 'recent numeric-target losses' are referenced but not named or cited; adding the specific baselines (e.g., by name or short citation) would improve readability.
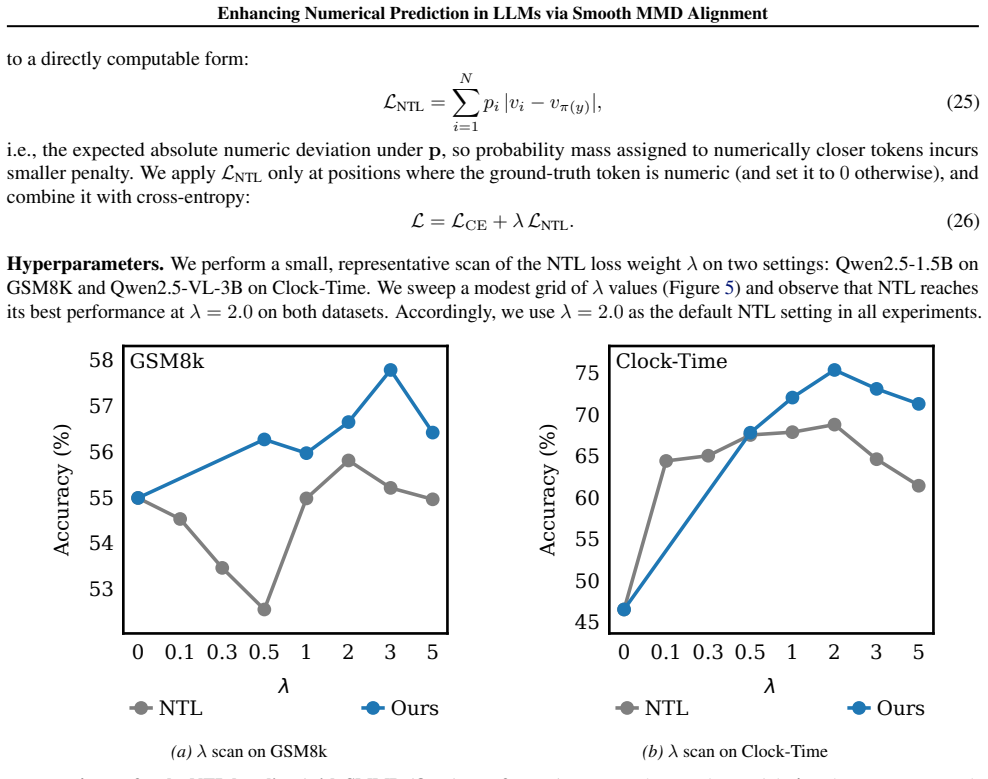
- [§3.1] §3.1 (Method): the construction of the numeric sub-vocabulary and the exact form of the distance-based kernel could include a short illustrative example with 3-4 tokens to clarify how value distances are computed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address the single major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the central claim of 'consistent improvements' across four tasks and multiple backbones is presented without reported statistical significance tests, standard deviations across seeds, or confidence intervals on the accuracy deltas; this weakens the ability to assess whether gains are reliable or could be due to variance.
Authors: We agree that the absence of variability measures and significance testing limits the strength of the empirical claims. In the revised version we will rerun the key experiments with at least three random seeds, report mean accuracy ± standard deviation for each method and task, and include paired t-test p-values (or Wilcoxon signed-rank tests where appropriate) on the per-seed differences between SMMD and the baselines. These results will be added to the main tables in §4 and to the appendix. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines SMMD as an explicit loss combining classic MMD with value-distance kernels and graph smoothness over a numeric sub-vocabulary; the central claim is an empirical accuracy gain measured on four external tasks against cross-entropy and other baselines. No equation, prediction, or result is shown to reduce by construction to a fitted parameter or self-citation chain. The derivation is self-contained: the method is stated independently of the target accuracy numbers, and evaluation uses held-out task performance rather than any internal re-use of the same quantities.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Maximum Mean Discrepancy provides a valid kernel-based measure of distribution difference
- domain assumption Numeric tokens have a metric structure that value-distance kernels can usefully capture
invented entities (1)
-
Smooth MMD (SMMD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PMLR. URL https://proceedings.mlr. press/v37/long15.html. Masry, A., Long, D., Tan, J. Q., Joty, S., and Hoque, E. ChartQA: A benchmark for question answering about charts with visual and logical rea- soning. InFindings of the Association for Com- putational Linguistics: ACL 2022, pp. 2263–2279, Dublin, Ireland, May 2022. Association for Computa- tional L...
-
[2]
URL https://aclanthology.org/2022. findings-acl.177. 10 Enhancing Numerical Prediction in LLMs via Smooth MMD Alignment Meta. meta-llama/llama-3.2-11b-vision: Model card. https://huggingface.co/meta-llama/ Llama-3.2-11B-Vision, 2024. Methani, N., Ganguly, P., Khapra, M. M., and Kumar, P. Plotqa: Reasoning over scientific plots. In2020 IEEE Winter Conferen...
-
[3]
URL https://aclanthology.org/2021. naacl-main.168/. Petrak, D., Moosavi, N. S., and Gurevych, I. Arithmetic- based pretraining improving numeracy of pretrained lan- guage models. In Palmer, A. and Camacho-collados, J. (eds.),Proceedings of the 12th Joint Conference on Lexi- cal and Computational Semantics (*SEM 2023), pp. 477– 493, Toronto, Canada, July 2...
-
[4]
Analysing Mathematical Reasoning Abilities of Neural Models
URL https://aclanthology.org/2023. starsem-1.42/. Saxena, R., Gema, A. P., and Minervini, P. Lost in time: Clock and calendar understanding challenges in multi- modal llms, 2025. Saxton, D., Grefenstette, E., Hill, F., and Kohli, P. Analysing mathematical reasoning abilities of neural models, 2019. URLhttps://arxiv.org/abs/1904.01557. Singh, A. K. and Str...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2023
-
[5]
Transformers: State-of-the-Art Natural Language Processing
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-demos.6. URL https:// aclanthology.org/2020.emnlp-demos.6/. Zausinger, J., Pennig, L., Kozina, A., Sdahl, S., Sikora, J., Dendorfer, A., Kuznetsov, T., Hagog, M., Wiedemann, N., Chlodny, K., Limbach, V ., Ketteler, A., Prein, T., Singh, V . M., Danziger, M., and Born, J. Regress, don’t...
-
[6]
12 Enhancing Numerical Prediction in LLMs via Smooth MMD Alignment A
URL https://proceedings.mlr.press/ v304/zuo25a.html. 12 Enhancing Numerical Prediction in LLMs via Smooth MMD Alignment A. Algorithms Algorithm 1Constructing the numeric sub-vocabularyV num Require:token vocabularyV; deterministic numeric parserparse(·)(float casting) Ensure:numeric sub-vocabularyV num; value map{v i}N i=1; index mapπ Vnum ← ∅ Initialize ...
-
[7]
General Expectation Form.For two distributionsPandQin a RKHSHwith kernelk(·,·), the squared MMD is: MMD2(P, Q) =E x,x′∼P [k(x, x′)]−2E x∼P,y∼Q[k(x, y)] +E y,y ′∼Q[k(y, y ′)].(13) 13 Enhancing Numerical Prediction in LLMs via Smooth MMD Alignment
-
[8]
The distributions are discrete vectorsp,q∈∆ N
Discrete Summation.In our setting, the domain is the finite sub-vocabulary Vnum of size N. The distributions are discrete vectorsp,q∈∆ N . The expectations become double summations over indicesiandj: LMMD = NX i=1 NX j=1 pipjKij −2 NX i=1 NX j=1 piqjKij + NX i=1 NX j=1 qiqjKij.(14)
-
[9]
Residual Vectorization.Exploiting the linearity of summation and the symmetry of K, we factorize the expression using the prediction–target residualr i =p i −q i: LMMD = NX i=1 NX j=1 Kij(pipj −p iqj −q ipj +q iqj)(15) = NX i=1 NX j=1 Kij(pi −q i)(pj −q j) = NX i=1 NX j=1 Kijrirj.(16) This yields the compact quadratic form: LMMD =r ⊤Kr.(17) B.2. Derivatio...
-
[10]
Expansion of Dirichlet Energy.Starting from the pairwise difference penalty in Eq. (9): Lsmooth = 1 2 NX i=1 NX j=1 Kij(ri −r j)2.(18) Expanding the quadratic term(r i −r j)2 =r 2 i −2r irj +r 2 j : Lsmooth = 1 2 X i,j Kijr2 i −2 X i,j Kijrirj + X i,j Kijr2 j .(19)
-
[11]
Thus: NX i=1 NX j=1 Kijr2 i = NX i=1 r2 i NX j=1 Kij = NX i=1 degir2 i =r ⊤Dr,(20) whereD=diag(deg 1,
Relation to the Degree Matrix.For the first term, summing over j yields the degree of node i: degi =PN j=1 Kij. Thus: NX i=1 NX j=1 Kijr2 i = NX i=1 r2 i NX j=1 Kij = NX i=1 degir2 i =r ⊤Dr,(20) whereD=diag(deg 1, . . . , degN). Due to the symmetry ofK, the third term P i,j Kijr2 j also equalsr ⊤Dr
-
[12]
14 Enhancing Numerical Prediction in LLMs via Smooth MMD Alignment C
Final Laplacian Form.Substituting these into the expression: Lsmooth = 1 2 r⊤Dr−2r ⊤Kr+r ⊤Dr (21) =r ⊤Dr−r ⊤Kr=r ⊤(D−K)r.(22) Defining the graph LaplacianL=D−K, we obtain the final form: Lsmooth =r ⊤Lr.(23) Comparing the two objectives, while LMMD =r ⊤Kr captures global distribution alignment, Lsmooth =r ⊤Lr ensures that the residual is distributed smooth...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.