Geometric Action Model for Robot Policy Learning
Pith reviewed 2026-06-27 03:55 UTC · model grok-4.3
The pith
Splitting a pretrained geometric foundation model at an intermediate layer and inserting a causal future predictor allows a single backbone to handle perception, temporal prediction, and action decoding for robot manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
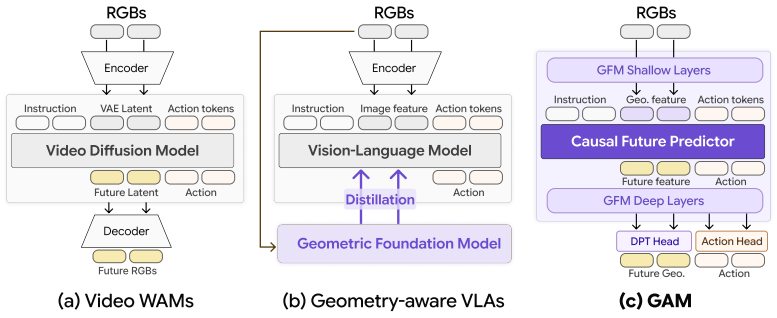
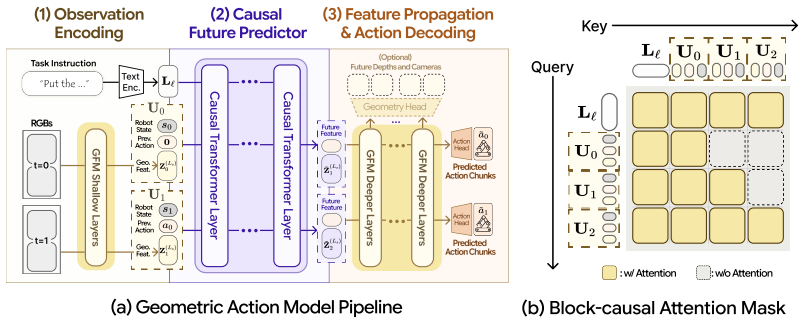
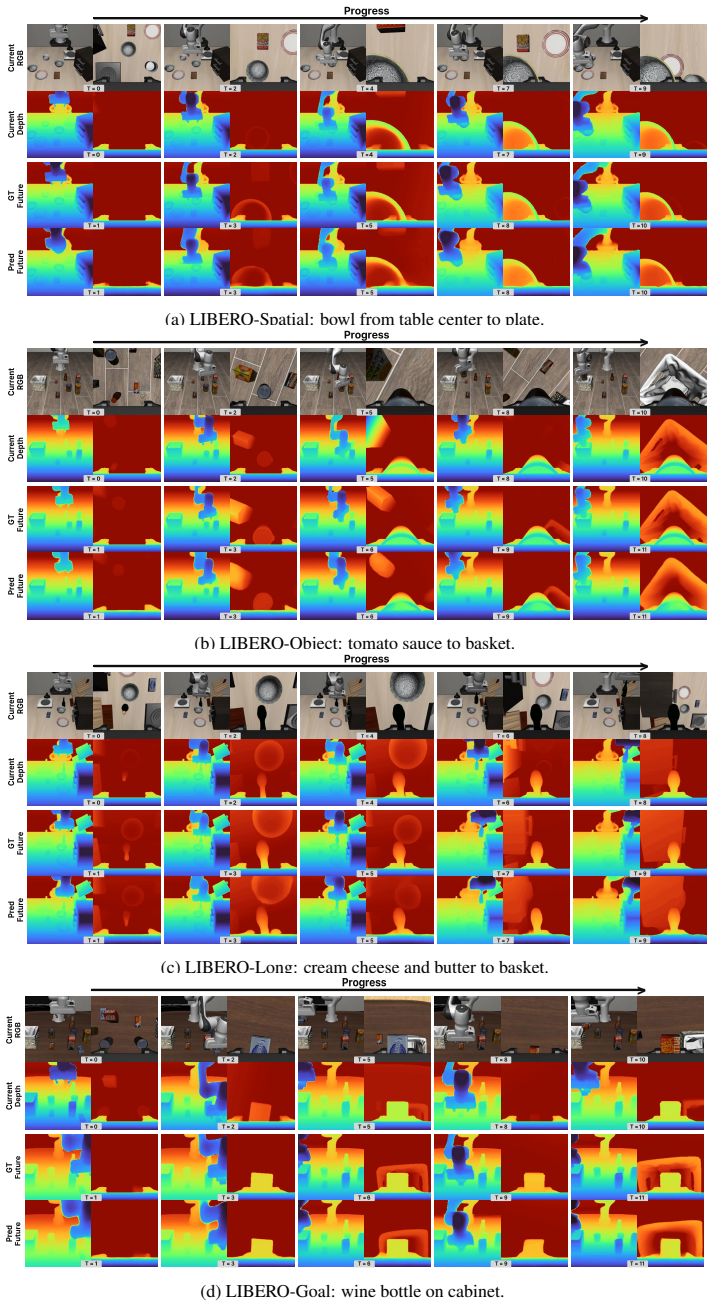
GAM splits the GFM at an intermediate layer where shallow layers encode observations and a causal future predictor inserted there forecasts future latent tokens conditioned on language, proprioception, and action history; these tokens are then routed through remaining blocks to produce both future geometry and actions from one backbone.
What carries the argument
The split-layer insertion of a causal future predictor into a pretrained geometric foundation model (GFM) to enable language-conditioned temporal token forecasting while preserving geometric priors.
If this is right
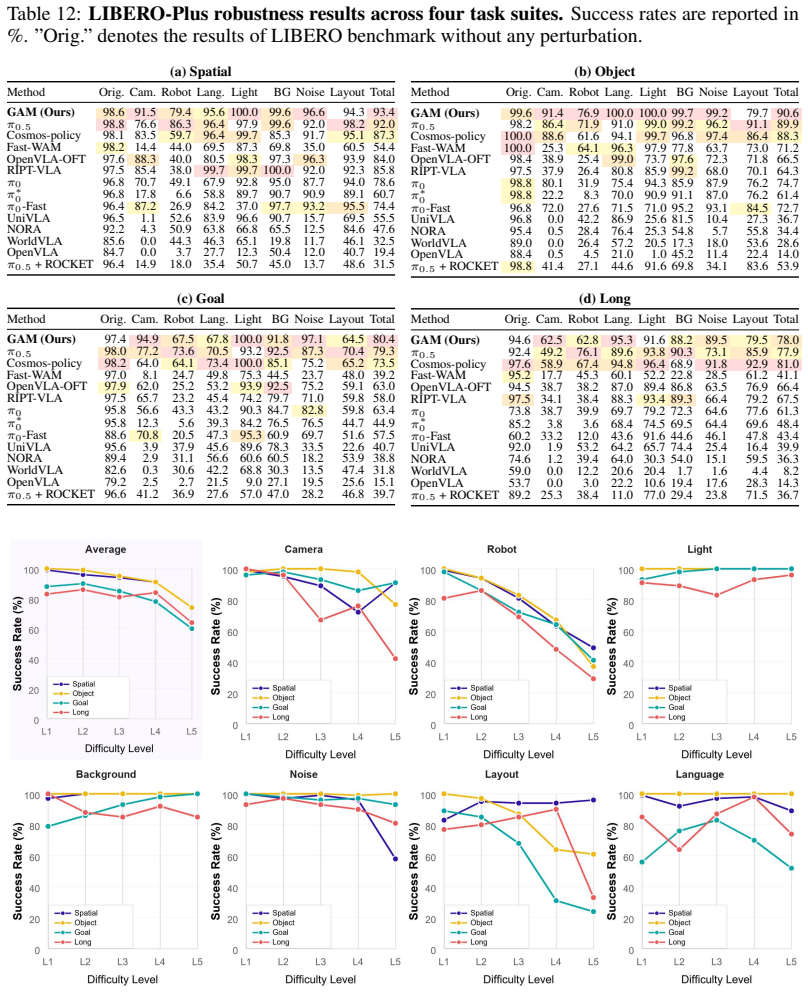
- GAM produces more accurate and robust policies on simulation and real-robot manipulation benchmarks than current foundation-model-scale baselines.
- The approach results in faster and lighter models.
- A single backbone generates both future geometry predictions and actions.
- Minimal modification equips the GFM with temporal world modeling capabilities.
Where Pith is reading between the lines
- Similar split-and-predict patterns might apply to other types of foundation models for different robotics tasks.
- Integrating such models could lead to more efficient real-time robot control systems.
- Further work might explore how the choice of split layer affects the balance between perception and prediction accuracy.
Load-bearing premise
That routing the predicted future tokens through the remaining GFM blocks will effectively combine temporal modeling with the original geometric capabilities.
What would settle it
Running the benchmarks with a version of GAM that lacks the causal future predictor and finding equivalent performance would indicate that the predictor is not necessary for the claimed benefits.
Figures





read the original abstract
Generalist robot policies must follow user instructions while reasoning about how objects, cameras, and robot actions interact in the 3D physical world. Recent vision-language-action models (VLAs) and video world-action models (WAMs) inherit strong semantic or temporal priors from large-scale foundation models, but they still operate primarily on 2D image frames or 2D-derived latent spaces, leaving implicit the 3D geometry required for contact-rich manipulation. We propose the Geometric Action Model (GAM), a language-conditioned manipulation policy that directly repurposes a pretrained geometric foundation model (GFM) as a shared substrate for perception, temporal prediction, and action decoding. GAM splits the GFM at an intermediate layer: the shallow layers serve as an observation encoder, and a causal future predictor inserted at the split layer forecasts future latent tokens conditioned on language, proprioception, and action history. The predicted future tokens are then routed through the remaining GFM blocks for feature propagation and decoding, allowing a single backbone to produce both future geometry and actions. This design equips the GFM with language-conditioned temporal world modeling through minimal architectural modification while preserving its rich geometric priors. Across a broad suite of simulation and real-robot manipulation benchmarks, GAM is more accurate, more robust, faster, and lighter than current foundation-model-scale baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Geometric Action Model (GAM), a language-conditioned robot manipulation policy obtained by minimally modifying a pretrained geometric foundation model (GFM). The GFM is split at an intermediate layer so that shallow blocks act as an observation encoder; a causal future predictor is inserted at the split to forecast future latent tokens conditioned on language, proprioception, and action history; the predicted tokens are then passed through the remaining GFM blocks for feature propagation and action decoding. The central claim is that this architecture adds language-conditioned temporal world modeling while retaining the GFM’s geometric priors, and that the resulting policy is more accurate, robust, faster, and lighter than current foundation-model-scale VLAs and WAMs on a broad suite of simulation and real-robot benchmarks.
Significance. If the reported benchmark gains hold under controlled re-evaluation, the result is significant because it demonstrates that temporal prediction can be grafted onto an existing geometric backbone with only a single inserted module and no full retraining, thereby preserving rich 3D priors while adding language-conditioned forecasting. The approach directly addresses the 2D-to-3D gap noted in prior VLA/WAM literature and supplies a concrete, reusable architectural pattern that could be applied to other GFMs.
major comments (2)
- [§4.3, Table 2] §4.3 and Table 2: the claim that GAM is “more accurate” than the strongest baseline rests on success-rate deltas whose statistical significance is not reported (no error bars, no paired t-test or Wilcoxon results across the N=5 seeds). Because the central empirical claim is that GAM outperforms foundation-model-scale baselines, the absence of significance testing on the primary metric is load-bearing.
- [§3.2, Eq. (3)] §3.2, Eq. (3): the future-predictor loss is defined only on the inserted module, yet the paper states that “the predicted future tokens are routed through the remaining GFM blocks.” It is unclear whether gradients from the action-decoding loss also update the predictor parameters; if they do not, the temporal modeling objective may be under-constrained relative to the geometric priors, weakening the “preserving geometric priors” guarantee.
minor comments (2)
- [Figure 1] Figure 1: the split-layer diagram would be clearer if the causal predictor block were drawn with explicit input/output arrows labeled “language + proprio + action history.”
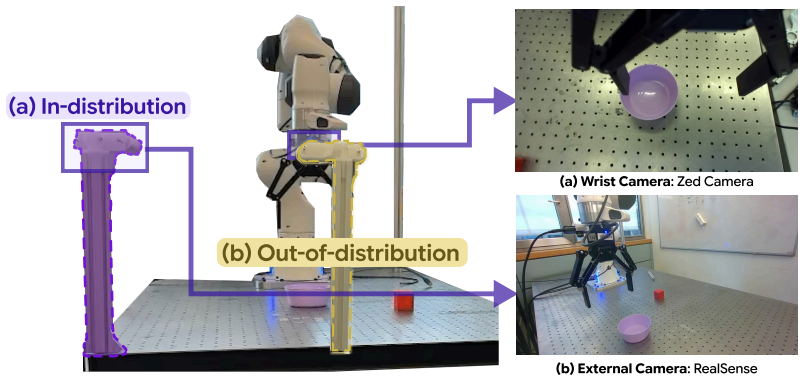
- [§5.1] §5.1: the real-robot hardware description omits the camera calibration procedure and the exact proprioceptive state vector; both are needed to reproduce the reported robustness numbers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will update the manuscript to incorporate clarifications and additional analyses where appropriate.
read point-by-point responses
-
Referee: [§4.3, Table 2] §4.3 and Table 2: the claim that GAM is “more accurate” than the strongest baseline rests on success-rate deltas whose statistical significance is not reported (no error bars, no paired t-test or Wilcoxon results across the N=5 seeds). Because the central empirical claim is that GAM outperforms foundation-model-scale baselines, the absence of significance testing on the primary metric is load-bearing.
Authors: We agree that statistical significance testing strengthens the empirical claims. In the revised manuscript we will augment Table 2 with error bars (standard deviation across the five seeds) and report the results of paired Wilcoxon signed-rank tests comparing GAM against each baseline on the primary success-rate metric. revision: yes
-
Referee: [§3.2, Eq. (3)] §3.2, Eq. (3): the future-predictor loss is defined only on the inserted module, yet the paper states that “the predicted future tokens are routed through the remaining GFM blocks.” It is unclear whether gradients from the action-decoding loss also update the predictor parameters; if they do not, the temporal modeling objective may be under-constrained relative to the geometric priors, weakening the “preserving geometric priors” guarantee.
Authors: We appreciate the opportunity to clarify the training dynamics. The pretrained GFM blocks remain frozen to retain their geometric priors; only the inserted causal future predictor is optimized. The future-prediction loss (Eq. 3) is therefore the sole training signal for the predictor. Because the remaining GFM blocks are frozen, gradients from the downstream action-decoding loss do not reach the predictor. We will revise §3.2 to state this explicitly and explain that the future-prediction objective is formulated to produce tokens that remain compatible with the frozen geometric decoder, thereby preserving the priors while adding language-conditioned temporal forecasting. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an architectural modification to a pretrained GFM (split at intermediate layer, insert causal future predictor, route tokens) and evaluates it empirically on manipulation benchmarks. No equations, fitted parameters renamed as predictions, or self-citations are presented as load-bearing for the central claim. The design is described as a direct reuse of the GFM backbone with minimal change, and performance gains are supported by external benchmarks rather than reducing to input definitions or prior self-citations. The derivation chain is self-contained as an empirical engineering contribution without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained geometric foundation models contain rich geometric priors suitable for manipulation tasks.
Reference graph
Works this paper leans on
-
[1]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[2]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[3]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[6]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[7]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[8]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
Pith/arXiv arXiv 2025
-
[9]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
- [10]
-
[11]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[12]
W. Huang, Y .-W. Chao, A. Mousavian, M.-Y . Liu, D. Fox, K. Mo, and L. Fei-Fei. Point- world: Scaling 3d world models for in-the-wild robotic manipulation.arXiv preprint arXiv:2601.03782, 2026
arXiv 2026
-
[13]
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[14]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual ge- ometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[15]
J. Wang, M. Chen, S. Zhang, N. Karaev, J. Sch¨onberger, P. Labatut, P. Bojanowski, D. Novotny, A. Vedaldi, and C. Rupprecht. Vggt-ω.arXiv preprint arXiv:2605.15195, 2026. 19
Pith/arXiv arXiv 2026
-
[16]
S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie. Representation align- ment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
Pith/arXiv arXiv 2024
-
[17]
F. Li, W. Song, H. Zhao, J. Wang, P. Ding, D. Wang, L. Zeng, and H. Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model.arXiv preprint arXiv:2510.12276, 2025
arXiv 2025
-
[18]
G. Sun, T. Du, K. Feng, C. Luo, X. Ding, Z. Shen, Z. Wang, Y . He, and A. Li. Rocket: Residual-oriented multi-layer alignment for spatially-aware vision-language-action models. arXiv preprint arXiv:2602.17951, 2026
arXiv 2026
-
[19]
Q. Qian, G. Zhao, G. Zhang, J. Wang, R. Xu, J. Gao, and D. Zhao. Gp3: A 3d geometry-aware policy with multi-view images for robotic manipulation.arXiv preprint arXiv:2509.15733, 2025
arXiv 2025
-
[20]
S. Ge, Y . Zhang, S. Xie, W. Zhang, M. Zhou, and Z. Wang. Vggt-dp: Generalizable robot control via vision foundation models.arXiv preprint arXiv:2509.18778, 2025
arXiv 2025
-
[21]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[22]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
-
[23]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[24]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language- action models.arXiv preprint arXiv:2502.19417, 2025
Pith/arXiv arXiv 2025
-
[25]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[26]
C.-Y . Hung, Q. Sun, P. Hong, A. Zadeh, C. Li, U. Tan, N. Majumder, S. Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
Pith/arXiv arXiv 2025
-
[27]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al. others. 2025. qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 4(5), 1
Pith/arXiv arXiv 2025
-
[28]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[29]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Bal- akrishna, N. Batchelor, A. Bewley, J. Bingham, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342, 2025
Pith/arXiv arXiv 2025
-
[30]
C. Cheang, S. Chen, Z. Cui, Y . Hu, L. Huang, T. Kong, H. Li, Y . Li, Y . Liu, X. Ma, et al. Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
Pith/arXiv arXiv 2025
-
[31]
J. Yang, R. Tan, Q. Wu, R. Zheng, B. Peng, Y . Liang, Y . Gu, M. Cai, S. Ye, J. Jang, et al. Magma: A foundation model for multimodal ai agents. InProceedings of the computer vision and pattern recognition conference, pages 14203–14214, 2025. 20
2025
-
[32]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[33]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[34]
S. Tan, K. Dou, Y . Zhao, and P. Kr ¨ahenb¨uhl. Interactive post-training for vision-language- action models.arXiv preprint arXiv:2505.17016, 2025
Pith/arXiv arXiv 2025
-
[35]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[36]
A. Abouzeid, M. Mansour, Q. Sun, Z. Sun, and D. Song. Geoaware-vla: Implicit geometry aware vision-language-action model.arXiv preprint arXiv:2509.14117, 2025
arXiv 2025
-
[37]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[38]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024
Pith/arXiv arXiv 2024
-
[39]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[40]
R. Zheng, J. Wang, S. Reed, J. Bjorck, Y . Fang, F. Hu, J. Jang, K. Kundalia, Z. Lin, L. Magne, et al. Flare: Robot learning with implicit world modeling.arXiv preprint arXiv:2505.15659, 2025
Pith/arXiv arXiv 2025
-
[41]
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He.π3: Scalable permutation-equivariant visual geometry learning.arXiv e-prints, pages arXiv–2507, 2025
2025
-
[42]
N. Keetha, N. M ¨uller, J. Sch¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414, 2025
Pith/arXiv arXiv 2025
-
[43]
L. Sun, B. Xie, Y . Liu, H. Shi, T. Wang, and J. Cao. Geovla: Empowering 3d representations in vision-language-action models.arXiv preprint arXiv:2508.09071, 2025
arXiv 2025
-
[44]
Z. Song, Q. Li, J. Zhou, Z. Yuan, T. Chen, L. Lin, and G. Wang. Robotic manipulation is vision-to-geometry mapping (f(v)→g): Vision-geometry backbones over language and video models.arXiv preprint arXiv:2604.12908, 2026
Pith/arXiv arXiv 2026
-
[45]
C. Xu, H. Li, S. Cheng, J. Hu, H. Fan, Z. Feng, and S. Liu. Action-geometry prediction with 3d geometric prior for bimanual manipulation.arXiv preprint arXiv:2602.23814, 2026
arXiv 2026
-
[46]
Ranftl, A
R. Ranftl, A. Bochkovskiy, and V . Koltun. Vision transformers for dense prediction. InPro- ceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021
2021
-
[47]
J. Lu, J. Xu, W. Hu, R. Zhu, C. Zhao, S.-K. Yeung, Y . Shan, and Y . Liu. Track4world: Feed- forward world-centric dense 3d tracking of all pixels.arXiv preprint arXiv:2603.02573, 2026
arXiv 2026
-
[48]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 21
2020
-
[49]
S. Nasiriany, S. Nasiriany, A. Maddukuri, and Y . Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots.arXiv preprint arXiv:2603.04356, 2026
arXiv 2026
-
[50]
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. arXiv preprint arXiv:2310.17596, 2023
Pith/arXiv arXiv 2023
-
[51]
O.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, et al. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 1(2), 2023
Pith/arXiv arXiv 2023
-
[52]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[53]
C. Wen, J. Lin, T. Darrell, D. Jayaraman, and Y . Gao. Fighting copycat agents in behavioral cloning from observation histories.Advances in Neural Information Processing Systems, 33: 2564–2575, 2020
2020
-
[54]
De Haan, D
P. De Haan, D. Jayaraman, and S. Levine. Causal confusion in imitation learning.Advances in neural information processing systems, 32, 2019
2019
-
[55]
Y . Zheng, X. Li, S. Gu, Y . Zheng, S. Tian, W. Li, L. Wang, S. Fei, P. Li, Y . Gao, et al. Pokevla: Empowering pocket-sized vision-language-action model with comprehensive world knowledge guidance.arXiv preprint arXiv:2604.20834, 2026. 22
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.