Welfare, Improvability, and Variance: A Principal-Agent Approach to Optimal Benchmark Item Aggregation
Pith reviewed 2026-06-28 23:48 UTC · model grok-4.3
The pith
A principal-agent model shows uniform benchmark aggregation loses welfare based on item alignment, marginal improvability, and performance variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Benchmarking is modeled as a multitask principal-agent game, and the welfare loss incurred by a benchmark is shown to be jointly determined by three item-level primitives: alignment with normative welfare priorities, marginal improvability, and performance variance. These primitives are then used to construct an audit framework that ranks items and surfaces those that are Pareto-inferior under a given welfare operationalization.
What carries the argument
The multitask principal-agent game of benchmarking, which isolates welfare loss to the three item-level primitives of alignment, marginal improvability, and performance variance.
If this is right
- Item weights can be adjusted away from uniformity to reduce welfare loss by incorporating the three primitives.
- Items that rank poorly on alignment, improvability, and variance simultaneously can be identified as Pareto-inferior and downweighted or removed.
- Existing benchmarks can be audited by measuring each item on the three axes and reporting the implied welfare shortfall.
- The principal's welfare priorities become an explicit input that shapes which items matter most for the aggregate score.
Where Pith is reading between the lines
- The same primitives might be used to decide when to add or retire items as models improve over time.
- The approach could be applied to non-AI evaluation settings that also aggregate heterogeneous tasks under a welfare objective.
- Interactions between these primitives and other benchmark problems such as contamination could be measured in follow-up experiments.
Load-bearing premise
Once the principal-agent structure is imposed, the welfare loss from uniform aggregation is fully captured by the three item-level primitives.
What would settle it
An empirical comparison in which items are reweighted by the three primitives and the resulting aggregate welfare is no higher than under uniform averaging.
Figures
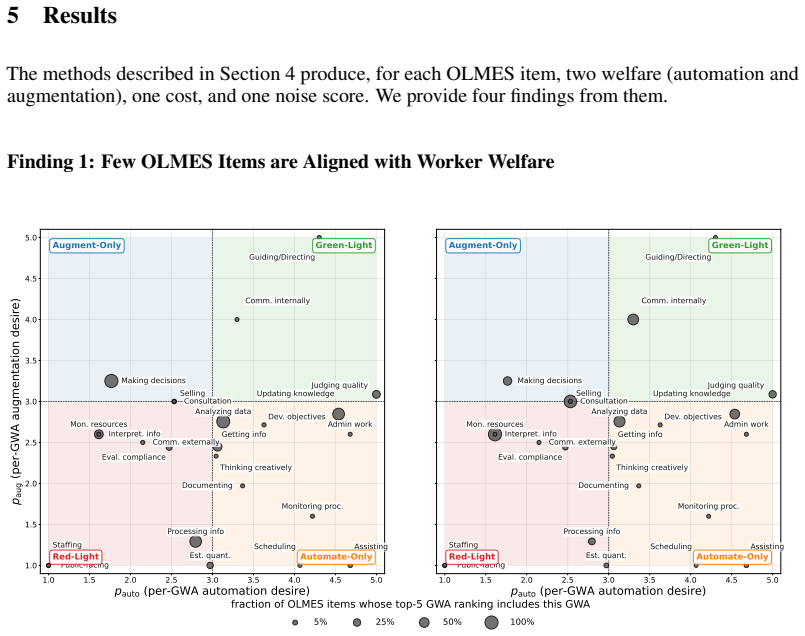
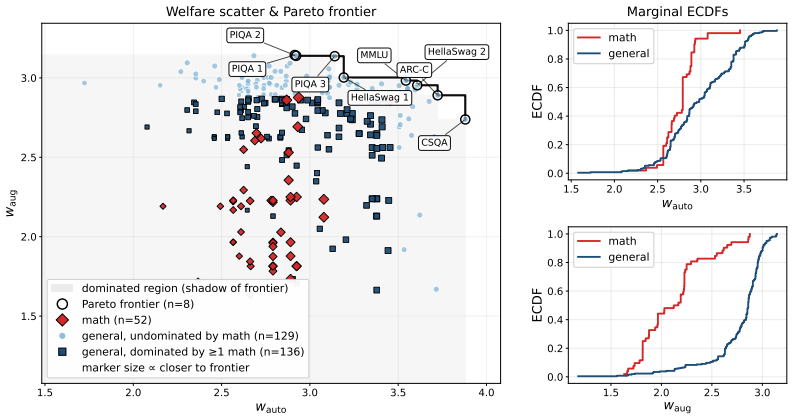
read the original abstract
AI benchmarks have well-documented limitations, with prior work examining contamination, saturation, and construct underspecification. Aggregation has received far less attention: benchmarks are typically summarized by uniformly averaging item-level scores, implicitly treating every test item as equally valuable. We model benchmarking as a multitask principal-agent game and show that the welfare loss from a benchmark is determined jointly by three item-level primitives: alignment with normative welfare priorities, marginal improvability, and performance variance. We translate the theory into an audit framework that ranks items along each of these three axes, and apply it to OLMES items using WORKBank for welfare, the EvoLM 4B suite for improvability, and the PolyPythias 410M panel for variance. The framework surfaces items that are Pareto-inferior within OLMES subject to a pro-worker welfare operationalization. All code is available at https://github.com/stair-lab/principal-agent-benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models AI benchmarking as a multitask principal-agent game in which a principal designs incentives for an agent to improve performance across items. It claims that the welfare loss incurred by uniform item aggregation is jointly determined by three item-level primitives: alignment with normative welfare priorities, marginal improvability, and performance variance. The authors translate the model into an audit framework that ranks items on these axes and apply it to the OLMES benchmark, using WORKBank for welfare alignment, the EvoLM 4B suite for improvability, and the PolyPythias 410M panel for variance. The framework identifies Pareto-inferior items under a pro-worker welfare operationalization. Reproducible code is provided at the linked GitHub repository.
Significance. If the principal-agent derivation establishes that welfare loss reduces exactly to a function of the three stated primitives without residual dependence on cross-item correlations or higher-order moments of the principal's utility, the work supplies a principled alternative to uniform averaging and a concrete audit tool for benchmark construction. The open-source code is a clear strength that supports verification and reuse.
major comments (1)
- [modeling section] Modeling section: the central claim requires an explicit loss formula whose only arguments are the three item-level primitives. The derivation must be checked to confirm that the agent's cost function and the principal's welfare aggregator introduce no non-separable terms (e.g., covariance between item performances or nonlinear aggregation) that would leave additional factors outside the three primitives.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [modeling section] Modeling section: the central claim requires an explicit loss formula whose only arguments are the three item-level primitives. The derivation must be checked to confirm that the agent's cost function and the principal's welfare aggregator introduce no non-separable terms (e.g., covariance between item performances or nonlinear aggregation) that would leave additional factors outside the three primitives.
Authors: We agree that the central claim is strengthened by an explicit loss formula. In the revised manuscript we will add a self-contained derivation in the modeling section showing that, under the maintained assumptions of additive separable agent costs across tasks and linear welfare aggregation by the principal, the welfare loss reduces exactly to a function of the three item-level primitives (welfare alignment, marginal improvability, and performance variance) with no residual cross-item covariance or nonlinear terms. The derivation will state the separability assumptions explicitly and present the closed-form expression. revision: yes
Circularity Check
No circularity: derivation is a modeling choice applied to external data
full rationale
The provided abstract and context describe a principal-agent model whose central claim is that welfare loss equals a function of three item-level primitives once the game structure is imposed. No equations, self-citations, or fitted-parameter renamings are supplied that would allow any reduction to be exhibited by construction. The primitives are sourced from independent external datasets (WORKBank, EvoLM, PolyPythias), and the audit framework is presented as an application rather than a tautological restatement of inputs. This is the normal case of a self-contained theoretical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmarking can be modeled as a multitask principal-agent game whose welfare loss is jointly determined by the three listed item primitives
Reference graph
Works this paper leans on
-
[1]
Can we have pro-worker AI.Choosing a path, 2023
Daron Acemoglu, David Autor, and Simon Johnson. Can we have pro-worker AI.Choosing a path, 2023
2023
-
[2]
Amazon bedrock pricing
Amazon Web Services. Amazon bedrock pricing. https://aws.amazon.com/bedrock/p ricing/, 2026. Accessed: 2026-05-06
2026
-
[3]
George P. Baker. Distortion and risk in optimal incentive contracts.Journal of Human Resources, 37(4):728–751, 2002
2002
-
[4]
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondˇrej Dušek. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2024. URLhttps://aclanthology.org/2024.eacl-long.5/
2024
-
[5]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020. doi: 10.1609/aaai.v34i05.6239
-
[6]
Bowman and George E
Samuel R. Bowman and George E. Dahl. What will it take to fix benchmarking in natural language understanding? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 4843–4855. Association for Computational Linguistics, 2021. URL https://aclantholog...
2021
-
[7]
The Turing trap: The promise & peril of human-like artificial intelligence
Erik Brynjolfsson. The Turing trap: The promise & peril of human-like artificial intelligence. Daedalus, 151(2):272–287, 2022
2022
-
[8]
Canaries in the coal mine?: Six facts about the recent employment effects of artificial intelligence
Erik Brynjolfsson, Bharat Chandar, and Ruyu Chen. Canaries in the coal mine?: Six facts about the recent employment effects of artificial intelligence. Technical report, Stanford Institute for Economic Policy Research (SIEPR), 2025
2025
-
[9]
Quality of primary care in England with the introduction of pay for performance.New England Journal of Medicine, 357(2):181–190, 2007
Stephen Campbell, David Reeves, Evangelos Kontopantelis, Elizabeth Middleton, Bonnie Sibbald, and Martin Roland. Quality of primary care in England with the introduction of pay for performance.New England Journal of Medicine, 357(2):181–190, 2007
2007
-
[10]
Robustness and linear contracts.American Economic Review, 105(2):536–563, 2015
Gabriel Carroll. Robustness and linear contracts.American Economic Review, 105(2):536–563, 2015
2015
-
[11]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. ARC- AGI-2: A new challenge for frontier AI reasoning systems, 2026. URL https://arxiv.org/ abs/2505.11831. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018. URL https://arxiv.org/abs/1803.0 5457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals
Mostafa Dehghani, Yi Tay, Alexey A. Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals. The benchmark lottery. InarXiv preprint arXiv:2107.07002, 2021
-
[14]
Can we trust ai benchmarks? an interdisciplinary review of current issues in ai evaluation, 2025
Maria Eriksson, Erasmo Purificato, Arman Noroozian, Joao Vinagre, Guillaume Chaslot, Emilia Gomez, and David Fernandez-Llorca. Can we trust ai benchmarks? an interdisciplinary review of current issues in ai evaluation, 2025. URLhttps://arxiv.org/abs/2502.06559
-
[15]
Eterno and Eli B
John A. Eterno and Eli B. Silverman.The Crime Numbers Game: Management by Manipulation. CRC Press, 2012
2012
-
[16]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, Claire Barale, Robert McHardy, Joshua Harris, Jean Kaddour, Emile Van Krieken, and Pasquale Minervini. Are we done with MMLU? In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Pr...
-
[17]
Olmes: A standard for language model evaluations
Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, and Hannaneh Ha- jishirzi. Olmes: A standard for language model evaluations. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5005–5033, 2025
2025
-
[18]
Ai should not be an imitation game: Centaur evaluations
Andreas Haupt and Erik Brynjolfsson. Ai should not be an imitation game: Centaur evaluations. InProceedings of the Forty-second International Conference on Machine Learning (ICML 2025), 2025
2025
-
[19]
Strategic candidacy in generative ai arenas.arXiv preprint arXiv:2603.26891, 2026
Chris Hays, Rachel Li, Bailey Flanigan, and Manish Raghavan. Strategic candidacy in generative ai arenas.arXiv preprint arXiv:2603.26891, 2026
-
[20]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations (ICLR), 2021. URL https://openreview.net/f orum?id=d7KBjmI3GmQ
2021
-
[21]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Aggregation and linearity in the provision of intertemporal incentives.Econometrica, 55(2):303–328, 1987
Bengt Holmström and Paul Milgrom. Aggregation and linearity in the provision of intertemporal incentives.Econometrica, 55(2):303–328, 1987
1987
-
[23]
Bengt Holmstrom and Paul Milgrom. Multitask principal–agent analyses: Incentive contracts, asset ownership, and job design.The Journal of Law, Economics, and Organization, 7(Special Issue):24–52, 1991. doi: 10.1093/jleo/7.special_issue.24. URL https://doi.org/10.1093/ jleo/7.special_issue.24
-
[24]
OpenAI and others seek new path to smarter AI as current methods hit limitations
Krystal Hu and Anna Tong. OpenAI and others seek new path to smarter AI as current methods hit limitations. Reuters, November 2024. URL https://www.reuters.com/technology/a rtificial-intelligence/openai-rivals-seek-new-path-smarter-ai-current -methods-hit-limitations-2024-11-11/. 11
2024
-
[25]
Jacob and Steven D
Brian A. Jacob and Steven D. Levitt. Rotten apples: An investigation of the prevalence and predictors of teacher cheating.Quarterly Journal of Economics, 118(3):843–877, 2003
2003
-
[26]
Abigail Z. Jacobs and Hanna Wallach. Measurement and fairness. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT), pages 375–385, 2021. doi: 10.1145/3442188.3445901
-
[27]
Thunderserve: High-performance and cost-efficient llm serving in cloud environments,
Youhe Jiang, Fangcheng Fu, Xiaozhe Yao, Taiyi Wang, Bin Cui, Ana Klimovic, and Eiko Yoneki. Thunderserve: High-performance and cost-efficient llm serving in cloud environments,
- [28]
-
[29]
Dynabench: Rethinking benchmarking in NLP
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. Dynabench: Rethinking benchmarking in NLP. InProceedings of the 202...
2021
-
[30]
Schulze Buschoff, and Eric Schulz
Alex Kipnis, Konstantinos V oudouris, Luca M. Schulze Buschoff, and Eric Schulz. metabench – a sparse benchmark to measure general ability in large language models. InInternational Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/24 07.12844
2025
-
[31]
Konrad.Strategy and Dynamics in Contests
Kai A. Konrad.Strategy and Dynamics in Contests. Oxford University Press, 2009
2009
-
[32]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023
2023
-
[33]
Lazear and Sherwin Rosen
Edward P. Lazear and Sherwin Rosen. Rank-order tournaments as optimum labor contracts. Journal of Political Economy, 89(5):841–864, 1981
1981
-
[34]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. From generation to judgment: Opportunities and challenges of LLM-as-a-judge. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2757–...
-
[35]
Numinamath
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath. [https://github.com/pro ject-numina/aimo-progress-prize](https://github.com/project-numina/aimo -progress-prize/blob/mai...
2024
-
[36]
Manning, et al
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, et al. Holistic evaluation of language models.Transactions on Machine Learning Research, 2023. URL https://openrev...
2023
-
[37]
tinybenchmarks: evaluating LLMs with fewer examples.arXiv preprint arXiv:2402.14992, 2024
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinybenchmarks: Evaluating LLMs with fewer examples. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. URL https://arxiv.org/ab s/2402.14992
-
[38]
Categorizing Variants of Goodhart's Law
David Manheim and Scott Garrabrant. Categorizing variants of Goodhart’s law.arXiv preprint arXiv:1803.04585, 2018. 12
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
State of what art? A call for multi-prompt LLM evaluation.Transactions of the Association for Computational Linguistics, 2024
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? A call for multi-prompt LLM evaluation.Transactions of the Association for Computational Linguistics, 2024
2024
-
[40]
O*NET 30.2 database
National Center for O*NET Development. O*NET 30.2 database. U.S. Department of Labor, Employment and Training Administration, 2026. URL https://www.onetcenter.org/dat abase.html
2026
-
[41]
Northcutt, Anish Athalye, and Jonas Mueller
Curtis G. Northcutt, Anish Athalye, and Jonas Mueller. Pervasive label errors in test sets destabilize machine learning benchmarks. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[42]
Mapping global dynamics of benchmark creation and saturation in artificial intelligence.Nature Communications, 13, 2022
Simon Ott, Adriano Barbosa-Silva, Kathrin Blagec, Jan Brauner, and Matthias Samwald. Mapping global dynamics of benchmark creation and saturation in artificial intelligence.Nature Communications, 13, 2022
2022
-
[43]
Efficient benchmarking (of language models)
Yotam Perlitz, Elron Bandel, Ariel Gera, Ofir Arviv, Liat Ein-Dor, Eyal Shnarch, Noam Slonim, Michal Shmueli-Scheuer, and Leshem Choshen. Efficient benchmarking (of language models). InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024. URLhttps://arxiv.org/abs/2308.11696
-
[44]
Efficiently scaling transformer inference
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. InProceedings of Machine Learning and Systems (MLSys), 2023
2023
-
[45]
John W. Pratt. Risk aversion in the small and in the large.Econometrica, 32(1–2):122–136,
-
[46]
doi: 10.2307/1913738
-
[47]
Xing, Sham M
Zhenting Qi, Fan Nie, Alexandre Alahi, James Zou, Himabindu Lakkaraju, Yilun Du, Eric P. Xing, Sham M. Kakade, and Hanlin Zhang. EvoLM: In search of lost training dynamics for language model reasoning. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[48]
URLhttps://openreview.net/forum?id=B6bE2GC71a
-
[49]
Bender, Amandalynne Paullada, Emily Denton, and Alex Hanna
Inioluwa Deborah Raji, Emily M. Bender, Amandalynne Paullada, Emily Denton, and Alex Hanna. AI and the everything in the whole wide world benchmark. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021. URLhttps://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/ 084b6fbb10729ed4da8c3d3f5a3a...
2021
-
[50]
Anka Reuel, Amelia Hardy, Chandler Smith, Max Lamparth, Malcolm Hardy, and Mykel J. Kochenderfer. Betterbench: Assessing ai benchmarks, uncovering issues, and establishing best practices, 2024. URLhttps://arxiv.org/abs/2411.12990
-
[51]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Chris J. Maddison, and Tatsunori Hashimoto. Observational scaling laws and the predictability of language model performance. InProceedings of NeurIPS, 2024
2024
-
[52]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Singapore, 2023. Association for Computational Linguistics. URL ...
2023
-
[53]
WinoGrande: An adversarial Winograd schema challenge at scale.Communications of the ACM, 64(9):99–106,
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial Winograd schema challenge at scale.Communications of the ACM, 64(9):99–106,
-
[54]
doi: 10.1145/3474381
-
[55]
Olawale Salaudeen, Anka Reuel, Ahmed Ahmed, Suhana Bedi, Zachary Robertson, Sudharsan Sundar, Ben Domingue, Angelina Wang, and Sanmi Koyejo. Measurement to meaning: A validity-centered framework for ai evaluation.arXiv preprint arXiv:2505.10573, 2025
-
[56]
Are emergent abilities of large language models a mirage? InAdvances in Neural Information Processing Systems (NeurIPS), 2023
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 13
2023
-
[57]
Pretraining scaling laws for generative evaluations of language models
Rylan Schaeffer, Noam Itzhak Levi, Brando Miranda, and Sanmi Koyejo. Pretraining scaling laws for generative evaluations of language models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=Ym33xJYI NV
2026
-
[58]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[59]
Future of work with ai agents: Auditing automation and augmentation potential across the u.s
Yijia Shao, Humishka Zope, Yucheng Jiang, Jiaxin Pei, David Nguyen, Erik Brynjolfsson, and Diyi Yang. Future of work with ai agents: Auditing automation and augmentation potential across the u.s. workforce, 2025. URLhttps://arxiv.org/abs/2506.06576
-
[60]
Smith, Beyza Ermis, Marzieh Fadaee, and Sara Hooker
Shivalika Singh, Yiyang Nan, Alex Wang, Daniel D’souza, Sayash Kapoor, Ahmet Üstün, Sanmi Koyejo, Yuntian Deng, Shayne Longpre, Noah A. Smith, Beyza Ermis, Marzieh Fadaee, and Sara Hooker. The leaderboard illusion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. URLhttps://open review.net/...
2025
-
[61]
Improving ratings: Audit in the British university system.European Review, 5(3):305–321, 1997
Marilyn Strathern. Improving ratings: Audit in the British university system.European Review, 5(3):305–321, 1997. doi: 10.1002/(SICI)1234-981X(199707)5:3<305::AID-EURO184>3 .0.CO;2-4. URL https://doi.org/10.1002/(SICI)1234-981X(199707)5:3<305:: AID-EURO184>3.0.CO;2-4
-
[62]
CommonsenseQA: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies (NAACL-HLT), pages 4149–4158. Association for Computational Lin...
2019
-
[63]
Thomas and David Uminsky
Rachel L. Thomas and David Uminsky. Reliance on metrics is a fundamental challenge for AI. Patterns, 3(5), 2022
2022
-
[64]
Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=mTCbq2QssD
2025
-
[65]
Truong, Yuheng Tu, Michael Hardy, Anka Reuel, Zeyu Tang, Jirayu Burapacheep, Jonathan Jude Perera, Chibuike Uwakwe, Benjamin W
Sang T. Truong, Yuheng Tu, Michael Hardy, Anka Reuel, Zeyu Tang, Jirayu Burapacheep, Jonathan Jude Perera, Chibuike Uwakwe, Benjamin W. Domingue, Nick Haber, and Sanmi Koyejo. Fantastic bugs and where to find them in AI benchmarks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. URLhttps:/...
2025
-
[66]
Truong, Yuheng Tu, Rylan Schaeffer, and Sanmi Koyejo
Sang T. Truong, Yuheng Tu, Rylan Schaeffer, and Sanmi Koyejo. Item response scaling laws: A measurement theory approach to generalizable neural performance prediction, 2026. URL https://openreview.net/forum?id=pIfopX18D1
2026
-
[67]
Polypythias: Stability and outliers across fifty language model pre-training runs
Oskar van der Wal, Pietro Lesci, Max Müller-Eberstein, Naomi Saphra, Hailey Schoelkopf, Willem Zuidema, and Stella Biderman. Polypythias: Stability and outliers across fifty language model pre-training runs. InThe Thirteenth International Conference on Learning Representa- tions, 2025. URLhttps://openreview.net/forum?id=bmrYu2Ekdz
2025
-
[68]
Teun van der Weij, Felix Hofstätter, Oliver Jaffe, Samuel F. Brown, and Francis Rhys Ward. AI sandbagging: Language models can strategically underperform on evaluations. InarXiv preprint arXiv:2406.07358, 2024
-
[69]
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu, Shuhao Guan, Derek Greene, and M-Tahar Kechadi. Benchmark data contamination of large language models: A survey.arXiv preprint arXiv:2406.04244, 2024. URL https: //arxiv.org/abs/2406.04244
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Metamath: Bootstrap your own mathematical questions for large language models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng YU, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=N8N0hgNDRt. 14
2024
-
[71]
HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Associa- tion for Computational Linguistics (ACL), pages 4791–4800
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Associa- tion for Computational Linguistics (ACL), pages 4791–4800. Association for Computational Linguistics, 2019. URLhttps://aclanthology.org/P19-1472/
2019
-
[72]
Lost in benchmarks? Rethinking large language model benchmarking with item response theory
Hongli Zhou et al. Lost in benchmarks? Rethinking large language model benchmarking with item response theory. InAAAI Conference on Artificial Intelligence (AAAI), 2026
2026
-
[73]
X., Chen, X., Lin, Y., Wen, J.-R., & Han, J
Kun Zhou et al. Don’t make your LLM an evaluation benchmark cheater.arXiv preprint arXiv:2311.01964, 2023. A Notation Reference Table 3 gives an overview of all notation used in the optimal benchmark aggregation problem. Table 3: Notation used throughout the model. Symbol Space Meaning Primitives nNNumber of effort dimensions, e.g., pretraining, SFT mNNum...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.