Tackling Multimodal Learning Challenges with Mixture-of-Expert: A Survey
Pith reviewed 2026-06-30 15:23 UTC · model grok-4.3
The pith
Mixture-of-Experts acts as a scalable framework that addresses multimodal learning challenges through selective activation, multi-opinion representations, and modular adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Mixture-of-Experts presents a naturally compatible and scalable framework for multimodal learning, demonstrating strong adaptability across diverse modalities and tasks, by enabling scalable modeling through selective activation, enriching representations via multi-opinion experts, and providing modular adaptation for imperfect data scenarios.
What carries the argument
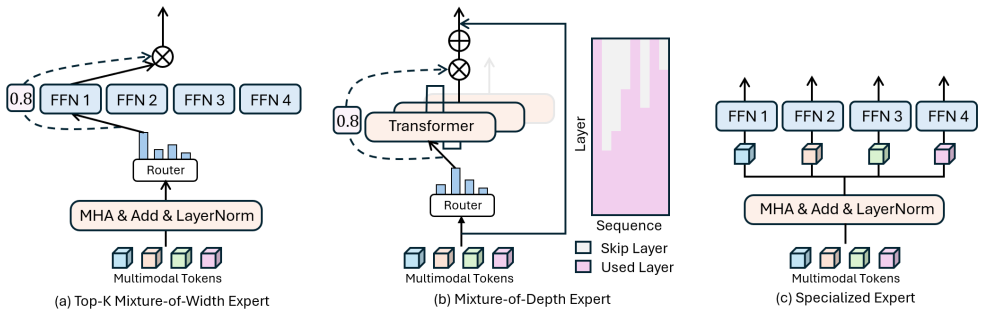
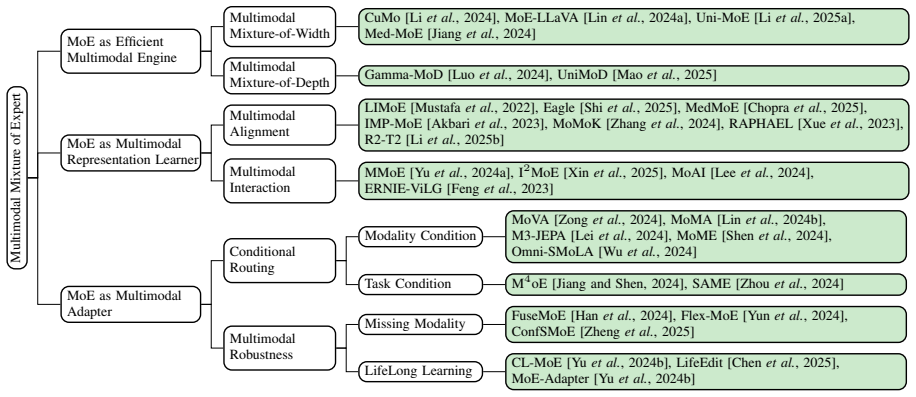
The three perspectives used to classify MoE-multimodal work: MoE as an Efficient Multimodal Engine that decouples compute from parameter count via selective activation; MoE as a Multimodal Representation Learner that combines complementary expert knowledge; and MoE as a Multimodal Adapter that flexibly handles modality imbalance or absence.
If this is right
- Selective expert activation reduces computational cost while allowing larger multimodal models.
- Multiple expert opinions improve alignment and interaction between modalities.
- Modular adapter design supports training when modalities are imbalanced or missing.
- Research gaps remain in interpretable routing, expert communication, and lifelong multimodal learning.
Where Pith is reading between the lines
- The three-perspective structure could be tested by attempting to reclassify recent multimodal papers and measuring how cleanly they fit.
- Combining the engine, learner, and adapter roles in a single system might address multiple challenges at once, though the survey does not explore such hybrids.
- The identified gaps suggest that future MoE designs could incorporate explicit communication protocols between experts to improve cross-modal consistency.
Load-bearing premise
That the body of existing MoE-multimodal papers can be partitioned into these three perspectives without significant overlap or omission, and that the partition captures the main mechanisms by which MoE resolves multimodal problems.
What would settle it
Identification of a substantial set of MoE-multimodal papers whose methods do not fit any of the three perspectives or whose primary benefit arises from a mechanism outside the three categories.
Figures
read the original abstract
Mixture-of-Experts (MoE) presents a naturally compatible and scalable framework for multimodal learning, demonstrating strong adaptability across diverse modalities and tasks. Despite its growing success, a comprehensive and systematic review on the MoE metho addressing multimodal challenges remains lacking. Existing surveys tend to evaluate either multimodal learning or MoE independently from method taxonomy, overlooking the unique interplay between them. This survey fills that gap by answering a central question: \textit{How does MoE effectively resolve multimodal challenges?} We approach this from three key perspectives: (1) \textbf{MoE as an Efficient Multimodal Engine:} enabling scalable multimodal modeling by decoupling computational cost from parameter growth and mitigating modality redundancy through selective expert activation; (2) \textbf{MoE as a Multimodal Representation Learner:} integrating complementary multi-opinion expert knowledge to enrich alignment and interaction representations; and (3) \textbf{MoE as a Multimodal Adapter:} providing a modular and flexible mechanism to model imperfect data scenarios such as modality imbalance and missing modality. Through our extensive literature review, we identify critical research gaps, including interpretable routing, expert communication, modality integration, and lifelong multimodal learning. We position this survey as a foundation for future research toward interpretable and sustainable multimodal Mixture-of-Experts system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey claiming that Mixture-of-Experts (MoE) offers a naturally compatible framework for multimodal learning. It answers 'How does MoE effectively resolve multimodal challenges?' by organizing the literature into three perspectives: (1) MoE as an Efficient Multimodal Engine (selective activation to decouple cost from parameters and reduce modality redundancy), (2) MoE as a Multimodal Representation Learner (multi-opinion experts for enriched alignment and interaction), and (3) MoE as a Multimodal Adapter (modular handling of imperfect data such as imbalance or missing modalities). The survey reviews existing work under this taxonomy, identifies gaps including interpretable routing, expert communication, modality integration, and lifelong multimodal learning, and positions itself as a foundation for future interpretable and sustainable MoE systems.
Significance. If the taxonomy is robust, the survey fills a documented gap by examining the MoE-multimodal interplay rather than treating the topics separately. It could serve as an organizational reference for researchers working on scalable multimodal models, particularly by highlighting mechanisms like selective activation and modular adaptation. The explicit identification of research gaps (interpretable routing, etc.) adds value for directing follow-on work.
major comments (1)
- [Abstract and taxonomy introduction] Abstract and §1 (central taxonomy): The paper's core contribution rests on partitioning existing MoE-multimodal papers into the three perspectives without substantial overlap or omission, so that the partition reveals distinct primary mechanisms. However, many routing-based designs simultaneously achieve sparsity (efficiency) and expert specialization (representation), making the boundaries non-sharp. The manuscript must either supply concrete paper-to-category assignments demonstrating low overlap or revise the taxonomy to accommodate multi-role designs; otherwise the claim that the three perspectives cleanly demonstrate how MoE resolves multimodal challenges is weakened.
minor comments (1)
- [Abstract] Abstract: 'review on the MoE metho addressing' contains an apparent truncation/typo; should read 'MoE methods addressing'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our survey. We address the major comment regarding the taxonomy below.
read point-by-point responses
-
Referee: [Abstract and taxonomy introduction] Abstract and §1 (central taxonomy): The paper's core contribution rests on partitioning existing MoE-multimodal papers into the three perspectives without substantial overlap or omission, so that the partition reveals distinct primary mechanisms. However, many routing-based designs simultaneously achieve sparsity (efficiency) and expert specialization (representation), making the boundaries non-sharp. The manuscript must either supply concrete paper-to-category assignments demonstrating low overlap or revise the taxonomy to accommodate multi-role designs; otherwise the claim that the three perspectives cleanly demonstrate how MoE resolves multimodal challenges is weakened.
Authors: We acknowledge that certain MoE designs can contribute to both efficiency through sparsity and representation learning through specialization, as the referee correctly observes. Our taxonomy classifies works according to the primary mechanism highlighted in the original papers rather than claiming mutually exclusive categories. To directly address the concern, the revised manuscript will include a table that maps each reviewed paper to its primary perspective with notes on secondary contributions where relevant. This addition supplies the requested concrete assignments while retaining the three-perspective structure, which organizes the literature around distinct ways MoE tackles multimodal issues. revision: yes
Circularity Check
No circularity: survey synthesizes external literature without self-referential derivations
full rationale
This paper is a literature survey that organizes existing MoE-multimodal work into three proposed perspectives based on a review of prior publications. It contains no equations, parameter fittings, predictions, or first-principles derivations that could reduce to the paper's own inputs by construction. The central claim is a synthesis and taxonomy of external results rather than a self-defining or load-bearing self-citation chain. No steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shivang Chopra, Gabriela Sanchez-Rodriguez, Lingchao Mao, Andrew J Feola, Jing Li, and Zsolt Kira. Med- moe: Modality-specialized mixture of experts for med- ical vision-language understanding.arXiv preprint arXiv:2506.08356,
-
[2]
Multimodal large lan- guage models: A survey.arXiv preprint arXiv:2506.10016,
Longzhen Han, Awes Mubarak, Almas Baimagambetov, Nikolaos Polatidis, and Thar Baker. Multimodal large lan- guage models: A survey.arXiv preprint arXiv:2506.10016,
-
[3]
Upcycling large language models into mixture of experts.arXiv preprint arXiv:2410.07524,
Ethan He, Abhinav Khattar, Ryan Prenger, Vijay Korthikanti, Zijie Yan, Tong Liu, Shiqing Fan, Ashwath Aithal, Mo- hammad Shoeybi, and Bryan Catanzaro. Upcycling large language models into mixture of experts.arXiv preprint arXiv:2410.07524,
-
[4]
Med-moe: Mixture of domain-specific experts for lightweight medical vision-language models
Songtao Jiang, Tuo Zheng, Yan Zhang, Yeying Jin, Li Yuan, and Zuozhu Liu. Med-moe: Mixture of domain-specific experts for lightweight medical vision-language models. arXiv preprint arXiv:2404.10237,
-
[5]
Efficient multimodal large language models: A survey.arXiv preprint arXiv:2405.10739,
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, et al. Efficient multimodal large language models: A survey.arXiv preprint arXiv:2405.10739,
-
[6]
Hongyang Lei, Xiaolong Cheng, Dan Wang, Kun Fan, Qi Qin, Huazhen Huang, Yetao Wu, Qingqing Gu, Zhonglin Jiang, Yong Chen, et al. M3-jepa: Multimodal alignment via multi-directional moe based on the jepa framework.arXiv preprint arXiv:2409.05929,
-
[7]
R2-t2: Re-routing in test-time for multimodal mixture-of-experts.arXiv preprint arXiv:2502.20395,
Zhongyang Li, Ziyue Li, and Tianyi Zhou. R2-t2: Re-routing in test-time for multimodal mixture-of-experts.arXiv preprint arXiv:2502.20395,
-
[8]
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Jinfa Huang, Junwu Zhang, Yatian Pang, Munan Ning, et al. Moe-llava: Mixture of experts for large vision- language models.arXiv preprint arXiv:2401.15947,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
2024.MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-A ware Experts
Xi Victoria Lin, Akshat Shrivastava, Liang Luo, Srinivasan Iyer, Mike Lewis, Gargi Ghosh, Luke Zettlemoyer, and Armen Aghajanyan. Moma: Efficient early-fusion pre- training with mixture of modality-aware experts.arXiv preprint arXiv:2407.21770,
- [10]
-
[11]
From efficient multimodal models to world models: A sur- vey.arXiv preprint arXiv:2407.00118,
Xinji Mai, Zeng Tao, Junxiong Lin, Haoran Wang, Yang Chang, Yanlan Kang, Yan Wang, and Wenqiang Zhang. From efficient multimodal models to world models: A sur- vey.arXiv preprint arXiv:2407.00118,
-
[12]
Weijia Mao, Zhenheng Yang, and Mike Zheng Shou. Uni- mod: Efficient unified multimodal transformers with mixture-of-depths.arXiv preprint arXiv:2502.06474,
-
[13]
Multimodal contrastive learn- ing with limoe: the language-image mixture of experts
Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby. Multimodal contrastive learn- ing with limoe: the language-image mixture of experts. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Bel- grave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Pro...
2022
-
[14]
arXiv preprint arXiv:2308.00951 (2023)
Joan Puigcerver, Carlos Riquelme, Basil Mustafa, and Neil Houlsby. From sparse to soft mixtures of experts.arXiv preprint arXiv:2308.00951,
-
[15]
Eagle: Exploring the design space for multimodal llms with mixture of encoders
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, Yilin Zhao, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catan- zaro, Andrew Tao, Jan Kautz, Zhiding Yu, and Guilin Liu. Eagle: Exploring the design space for multimodal llms with mixture of encoders. InThe Thirteenth Inter- national Conference on Learning ...
2025
-
[16]
Xingyu Tan, Xiaoyang Wang, Qing Liu, Xiwei Xu, Xin Yuan, Liming Zhu, and Wenjie Zhang. Privgemo: Privacy- preserving dual-tower graph retrieval for empowering llm reasoning with memory augmentation.arXiv preprint arXiv:2601.08739,
-
[17]
arXiv preprint arXiv:2505.19190 , year=
Jiayi Xin, Sukwon Yun, Jie Peng, Inyoung Choi, Jenna L Bal- lard, Tianlong Chen, and Qi Long. I2moe: Interpretable multimodal interaction-aware mixture-of-experts.arXiv preprint arXiv:2505.19190,
-
[18]
Mmoe: Enhancing multimodal models with mixtures of multi- modal interaction experts
Haofei Yu, Zhengyang Qi, Lawrence Jang, Russ Salakhutdi- nov, Louis-Philippe Morency, and Paul Pu Liang. Mmoe: Enhancing multimodal models with mixtures of multi- modal interaction experts. InProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Pro- cessing, Miami, FL, USA,
2024
-
[19]
Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Binbin Hu, Ziqi Liu, Wen Zhang, and Huajun Chen. Multiple heads are better than one: Mixture of modality knowledge experts for entity representation learning.arXiv preprint arXiv:2405.16869,
-
[20]
Liangwei Nathan Zheng, Wei Emma Zhang, Mingyu Guo, Miao Xu, Olaf Maennel, and Weitong Chen. Rethink- ing gating mechanism in sparse moe: Handling arbi- trary modality inputs with confidence-guided gate.arXiv preprint arXiv:2505.19525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Gengze Zhou, Yicong Hong, Zun Wang, Chongyang Zhao, Mohit Bansal, and Qi Wu. Same: Learning generic language-guided visual navigation with state-adaptive mix- ture of experts.arXiv preprint arXiv:2412.05552,
-
[22]
Mova: Adapting mixture of vision experts to multimodal context.Advances in Neural Information Processing Sys- tems, 37:103305–103333, 2024
Zhuofan Zong, Bingqi Ma, Dazhong Shen, Guanglu Song, Hao Shao, Dongzhi Jiang, Hongsheng Li, and Yu Liu. Mova: Adapting mixture of vision experts to multimodal context.Advances in Neural Information Processing Sys- tems, 37:103305–103333, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.