MINGLE: VLMs for Semantically Complex Region Detection in Urban Scenes
Pith reviewed 2026-05-18 15:31 UTC · model grok-4.3
The pith
MINGLE detects socially interacting groups in street scenes by chaining human detection, depth maps, VLM pairwise reasoning, and spatial aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
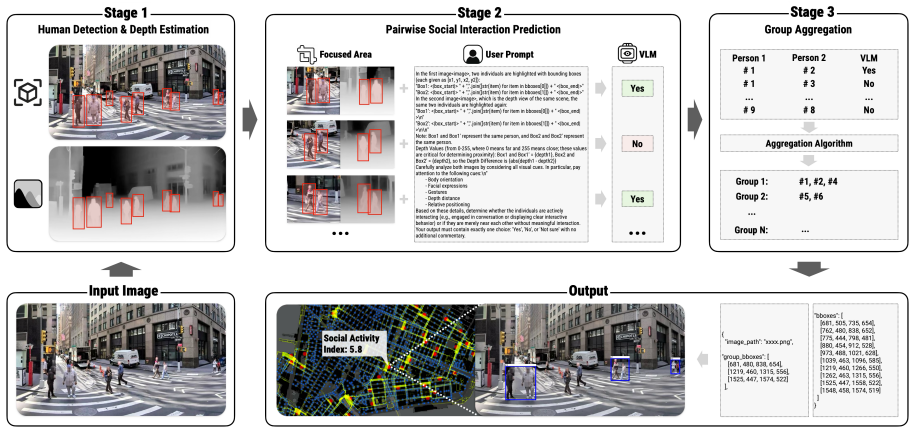
MINGLE shows that off-the-shelf human detectors combined with depth estimation, VLM-based classification of pairwise social affiliation, and a lightweight spatial aggregation step can localize regions corresponding to socially connected groups, with the pipeline evaluated on a newly collected set of 100K street-view images annotated for both individuals and groups.
What carries the argument
The three-stage MINGLE pipeline that uses human detection and depth estimation to ground individuals, VLM reasoning to classify pairwise social affiliation, and spatial aggregation to form group regions.
If this is right
- Urban planners gain a tool to quantify social vibrancy and inclusivity from existing street imagery.
- Detection of semantically complex regions becomes feasible without training new models for every abstract relation.
- The released 100K-image dataset supplies training and evaluation material for future group-interaction work.
- Modular design lets researchers swap in improved detectors or VLMs as they become available.
Where Pith is reading between the lines
- The same pipeline could be applied to video to track how social groups form and dissolve over time.
- Applications in crowd management or assistive robotics could emerge if the spatial groups are used as input for higher-level behavior prediction.
- The task formulation may generalize to other abstract relational groupings such as family units or professional clusters in different scene types.
Load-bearing premise
Vision-language models can reliably judge subtle interpersonal relations such as social affiliation from visual cues alone in typical street-view images.
What would settle it
A test set of street-view images with independently verified ground-truth social affiliations where the VLM pairwise classification step is measured for accuracy; high error rates would falsify the pipeline's core step.
Figures



read the original abstract
Understanding group-level social interactions in public spaces is crucial for urban planning, informing the design of socially vibrant and inclusive environments. Detecting such interactions from images involves interpreting subtle visual cues such as relations, proximity, and co-movement - semantically complex signals that go beyond traditional object detection. To address this challenge, we introduce a social group region detection task, which requires inferring and spatially grounding visual regions defined by abstract interpersonal relations. We propose MINGLE (Modeling INterpersonal Group-Level Engagement), a modular three-stage pipeline that integrates: (1) off-the-shelf human detection and depth estimation, (2) VLM-based reasoning to classify pairwise social affiliation, and (3) a lightweight spatial aggregation algorithm to localize socially connected groups. To support this task and encourage future research, we present a new dataset of 100K urban street-view images annotated with bounding boxes and labels for both individuals and socially interacting groups. The annotations combine human-created labels and outputs from the MINGLE pipeline, ensuring semantic richness and broad coverage of real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the social group region detection task for urban scenes and proposes MINGLE, a three-stage modular pipeline that combines off-the-shelf human detection and depth estimation, VLM-based classification of pairwise social affiliations from visual cues, and a lightweight spatial aggregation algorithm to localize connected groups. It also releases a new dataset of 100K street-view images annotated with bounding boxes and labels for individuals and groups, where annotations mix human labels with outputs from the proposed pipeline.
Significance. If the empirical results hold, the work could meaningfully advance automated analysis of social interactions in public spaces, with direct relevance to urban planning and inclusive design. The modular reuse of existing detectors and VLMs is pragmatic and lowers the barrier to adoption, while the scale of the released dataset offers a useful resource for future research on semantically complex region grounding. Credit is due for framing a new task that goes beyond standard object detection.
major comments (2)
- [Pipeline description (stage 2)] Stage (2) description: the central claim depends on the off-the-shelf VLM reliably classifying subtle pairwise social affiliations (gaze, posture, co-movement) in street-view imagery, yet no accuracy, precision-recall, or error analysis is reported for this step on the target domain. If classification error exceeds ~20-30% on distant or occluded pairs, incorrect edges will propagate through the aggregation algorithm and undermine group localization performance regardless of the quality of stages (1) and (3).
- [Dataset section] Dataset construction paragraph: annotations are generated by combining human-created labels with outputs from the MINGLE pipeline itself. This creates a mild but load-bearing circularity risk for any quantitative evaluation performed on the dataset, as the system may be assessed partly on data it helped label, potentially inflating reported metrics and limiting claims of independent validation.
minor comments (1)
- [Abstract] The abstract outlines the pipeline and dataset but omits any quantitative performance figures, ablation results, or key metrics, which would allow readers to gauge the contribution at a glance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of the social group region detection task and the released dataset. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Pipeline description (stage 2)] Stage (2) description: the central claim depends on the off-the-shelf VLM reliably classifying subtle pairwise social affiliations (gaze, posture, co-movement) in street-view imagery, yet no accuracy, precision-recall, or error analysis is reported for this step on the target domain. If classification error exceeds ~20-30% on distant or occluded pairs, incorrect edges will propagate through the aggregation algorithm and undermine group localization performance regardless of the quality of stages (1) and (3).
Authors: We agree that isolating and quantifying the VLM classification performance in stage 2 is necessary to assess error propagation risks. The current manuscript reports only end-to-end group localization metrics. In the revision we will add a dedicated error analysis subsection that evaluates pairwise affiliation classification accuracy, precision, and recall on a manually verified subset of the dataset. Results will be stratified by distance, occlusion level, and scene density to directly address the concern about performance on challenging pairs. revision: yes
-
Referee: [Dataset section] Dataset construction paragraph: annotations are generated by combining human-created labels with outputs from the MINGLE pipeline itself. This creates a mild but load-bearing circularity risk for any quantitative evaluation performed on the dataset, as the system may be assessed partly on data it helped label, potentially inflating reported metrics and limiting claims of independent validation.
Authors: We acknowledge the circularity concern. The manuscript will be revised to clarify the annotation protocol: a core subset received fully human-generated labels, while the MINGLE pipeline was applied to scale annotations to the remaining images, followed by human review of a random sample. All quantitative results in the revised paper will be reported on a held-out test split consisting exclusively of human-annotated images, with separate metrics provided for the human-only subset to support independent validation. revision: yes
Circularity Check
Mild self-referential element in dataset annotation but central pipeline remains independent
specific steps
-
other
[Abstract]
"The annotations combine human-created labels and outputs from the MINGLE pipeline, ensuring semantic richness and broad coverage of real-world scenarios."
Part of the ground-truth labels for the evaluation dataset are generated by the MINGLE pipeline itself. While mixed with human labels, this creates partial self-reference in reported performance metrics on group localization, as some 'correct' outputs are the model's own prior outputs rather than fully independent annotations.
full rationale
The paper presents a modular pipeline using off-the-shelf detectors, VLM reasoning, and spatial aggregation to detect social groups, supported by a new 100K-image dataset. The only potential circularity arises from the dataset description noting that annotations combine human labels with MINGLE pipeline outputs. This affects evaluation mildly but does not reduce any derivation, prediction, or core claim to its inputs by construction, nor involve self-citations, uniqueness theorems, or ansatzes. The central method integrates distinct components without statistical forcing or definitional loops, making the overall derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can accurately classify pairwise social affiliation from visual cues in urban images
Forward citations
Cited by 1 Pith paper
-
Diagnosing Urban Street Vitality via a Visual-Semantic and Spatiotemporal Framework for Street-Level Economics
A visual-semantic spatiotemporal framework creates the Street Economic Vitality Index (SEVI) to diagnose urban street economic vitality by parsing streetscapes with AI, standardizing brands via VLM-LLM, and incorporat...
Reference graph
Works this paper leans on
-
[1]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision, pages 38–55. Springer, 2024. 11
work page 2024
-
[2]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.IEEE transactions on pattern analysis and machine intelligence, 39(6):1137–1149, 2016
work page 2016
-
[3]
Ultralytics YOLO, January 2023
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Ultralytics YOLO, January 2023. URL https://github.com/ultralytics/ultralytics
work page 2023
-
[4]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024
work page 2024
-
[5]
Conservation Foundation Washington, DC, 1980
William Hollingsworth Whyte et al.The Social Life of Small Urban Spaces, volume 116. Conservation Foundation Washington, DC, 1980
work page 1980
- [6]
-
[7]
Jane Jacobs.The Death and Life of Great American Cities.Random House, 1961
work page 1961
-
[8]
Harvard University Press, 1985
Allan B Jacobs.Looking at cities. Harvard University Press, 1985
work page 1985
-
[9]
Vikas Mehta and Jennifer K Bosson. Revisiting lively streets: Social interactions in public space.Journal of Planning Education and Research, 41(2):160–172, 2021
work page 2021
-
[10]
Jie Qi, Suvodeep Mazumdar, and Ana C Vasconcelos. Understanding the relationship between urban public space and social cohesion: A systematic review.International Journal of Community Well-Being, 7(2):155–212, 2024
work page 2024
-
[11]
Maryam Hosseini, Marco Cipriano, Sedigheh Eslami, Daniel Hodczak, Liu Liu, Andres Sevtsuk, and Gerard de Melo. Elsa: Evaluating localization of social activities in ur- ban streets using open-vocabulary detection, 2024. URLhttps://arxiv.org/abs/2406. 01551
work page 2024
-
[12]
Jrdb- act: A large-scale dataset for spatio-temporal action, social group and activity detection
Mahsa Ehsanpour, Fatemeh Saleh, Silvio Savarese, Ian Reid, and Hamid Rezatofighi. Jrdb- act: A large-scale dataset for spatio-temporal action, social group and activity detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20983–20992, 2022
work page 2022
-
[13]
Simindokht Jahangard, Zhixi Cai, Shiki Wen, and Hamid Rezatofighi. Jrdb-social: A mul- tifaceted robotic dataset for understanding of context and dynamics of human interactions within social groups. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22087–22097, 2024
work page 2024
-
[14]
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Chunhui Gu, Chen Sun, David A. Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sud- heendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, and Jitendra Malik. Ava: A video dataset of spatio-temporally localized atomic visual actions, 2018. URLhttps://arxiv.org/abs/1705.08421
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Human-to-human interaction detection, 2023
Zhenhua Wang, Kaining Ying, Jiajun Meng, and Jifeng Ning. Human-to-human interaction detection, 2023. URLhttps://arxiv.org/abs/2307.00464
-
[16]
Nonverbal interaction detection
Jianan Wei, Tianfei Zhou, Yi Yang, and Wenguan Wang. Nonverbal interaction detection. InEuropean Conference on Computer Vision, pages 277–295. Springer, 2024
work page 2024
-
[17]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Florence-2: Advancing a unified representation for a variety of vision tasks, 2023
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks, 2023. URLhttps://arxiv.org/abs/2311.06242
-
[19]
Rod-mllm: Towards more reliable object detection in multimodal large language models
Heng Yin, Yuqiang Ren, Ke Yan, Shouhong Ding, and Yongtao Hao. Rod-mllm: Towards more reliable object detection in multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14358–14368, 2025
work page 2025
-
[20]
Lisa: Reasoning segmentation via large language model.arXiv preprint arXiv:2308.00692, 2023
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model, 2024. URLhttps://arxiv.org/ abs/2308.00692
-
[21]
u-llava: Unifying multi-modal tasks via large language model, 2024
Jinjin Xu, Liwu Xu, Yuzhe Yang, Xiang Li, Fanyi Wang, Yanchun Xie, Yi-Jie Huang, and Yaqian Li. u-llava: Unifying multi-modal tasks via large language model, 2024. URL https://arxiv.org/abs/2311.05348
-
[22]
Anwer, Erix Xing, Ming-Hsuan Yang, and Fahad S
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji Mullappilly, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Erix Xing, Ming-Hsuan Yang, and Fahad S. Khan. Glamm: Pixel grounding large multimodal model, 2024. URLhttps: //arxiv.org/abs/2311.03356
-
[23]
Perceptiongpt: Effec- tively fusing visual perception into llm, 2023
Renjie Pi, Lewei Yao, Jiahui Gao, Jipeng Zhang, and Tong Zhang. Perceptiongpt: Effec- tively fusing visual perception into llm, 2023. URLhttps://arxiv.org/abs/2311.06612
-
[24]
Pixellm: Pixel reasoning with large multimodal model.arXiv preprint arXiv:2312.02228, 2023
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, and Xiaojie Jin. Pixellm: Pixel reasoning with large multimodal model, 2024. URLhttps: //arxiv.org/abs/2312.02228
-
[25]
Vision-language model for object de- tection and segmentation: A review and evaluation, 2025
Yongchao Feng, Yajie Liu, Shuai Yang, Wenrui Cai, Jinqing Zhang, Qiqi Zhan, Ziyue Huang, Hongxi Yan, Qiao Wan, Chenguang Liu, Junzhe Wang, Jiahui Lv, Ziqi Liu, Tengyuan Shi, Qingjie Liu, and Yunhong Wang. Vision-language model for object de- tection and segmentation: A review and evaluation, 2025. URLhttps://arxiv.org/abs/ 2504.09480
-
[26]
Ground-v: Teaching vlms to ground complex instruc- tions in pixels, 2025
Yongshuo Zong, Qin Zhang, Dongsheng An, Zhihua Li, Xiang Xu, Linghan Xu, Zhuowen Tu, Yifan Xing, and Onkar Dabeer. Ground-v: Teaching vlms to ground complex instruc- tions in pixels, 2025. URLhttps://arxiv.org/abs/2505.13788
-
[27]
Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and Stan Z Li. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9759–9768, 2020
work page 2020
-
[28]
Mykola Lavreniuk, Shariq Farooq Bhat, Matthias M¨ uller, and Peter Wonka. Evp: En- hanced visual perception using inverse multi-attentive feature refinement and regular- ized image-text alignment. InEuropean Conference on Computer Vision, pages 206–225. Springer, 2024. 13
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.