Recognition: 1 theorem link
· Lean TheoremGlimpRouter: Efficient Collaborative Inference by Glimpsing One Token of Thoughts
Pith reviewed 2026-05-16 15:49 UTC · model grok-4.3
The pith
The entropy of the initial token of a reasoning step predicts its difficulty for model routing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
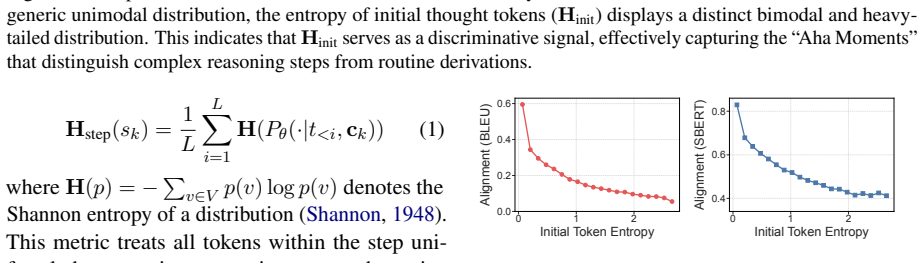
The central discovery is that the entropy of the initial token serves as a strong predictor of step difficulty in large reasoning models. GlimpRouter implements this by having a lightweight model generate only the first token per step and routing to the larger model solely when this entropy exceeds a fixed threshold. This training-free approach yields better accuracy and lower latency than using the large model alone, as shown on multiple benchmarks including a 10.7 percent accuracy gain and 25.9 percent latency reduction on AIME25.
What carries the argument
GlimpRouter, which routes each reasoning step based on the entropy of its first generated token from a lightweight model.
If this is right
- Hard steps identified by high initial entropy are completed by the large model for higher accuracy.
- Easy steps are handled entirely by the lightweight model to reduce overall latency.
- The system achieves higher accuracy than the large model standalone by optimal allocation of compute.
- Only the first token needs to be generated by the small model before deciding, minimizing overhead.
Where Pith is reading between the lines
- If first-token entropy predicts difficulty, it implies that the insight often occurs early in the step rather than building gradually.
- This routing could be extended to other sequential tasks like code generation where step difficulty varies.
- Combining this signal with other cheap indicators might improve routing decisions further.
Load-bearing premise
The entropy of the first token reliably indicates the difficulty of the whole reasoning step and a single threshold works without task-specific tuning.
What would settle it
Finding a set of reasoning steps where low first-token entropy leads to frequent errors by the small model, or where high entropy steps are solved accurately by the small model anyway.
Figures



read the original abstract
Large Reasoning Models (LRMs) achieve remarkable performance by explicitly generating multi-step chains of thought, but this capability incurs substantial inference latency and computational cost. Collaborative inference offers a promising solution by selectively allocating work between lightweight and large models, yet a fundamental challenge remains: determining when a reasoning step requires the capacity of a large model or the efficiency of a small model. Existing routing strategies either rely on local token probabilities or post-hoc verification, introducing significant inference overhead. In this work, we propose a novel perspective on step-wise collaboration: the difficulty of a reasoning step can be inferred from its very first token. Inspired by the "Aha Moment" phenomenon in LRMs, we show that the entropy of the initial token serves as a strong predictor of step difficulty. Building on this insight, we introduce GlimpRouter, a training-free step-wise collaboration framework. GlimpRouter employs a lightweight model to generate only the first token of each reasoning step and routes the step to a larger model only when the initial token entropy exceeds a threshold. Experiments on multiple benchmarks demonstrate that our approach significantly reduces inference latency while preserving accuracy. For instance, GlimpRouter attains a substantial 10.7% improvement in accuracy while reducing inference latency by 25.9% compared to a standalone large model on AIME25. These results suggest a simple yet effective mechanism for reasoning: allocating computation based on a glimpse of thought rather than full-step evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GlimpRouter, a training-free step-wise collaborative inference framework for large reasoning models (LRMs). A lightweight model generates only the first token of each reasoning step; the step is routed to the large model only if the entropy of that token exceeds a fixed threshold. The central claim is that this first-token entropy serves as a reliable predictor of step difficulty, yielding substantial accuracy gains (e.g., +10.7% on AIME25) together with latency reductions (e.g., -25.9%) relative to a standalone large model across multiple benchmarks.
Significance. If the routing assumption holds and the reported gains are reproducible, the work would offer a simple, zero-training overhead mechanism for trading off accuracy and latency in multi-step reasoning, with clear practical value for deploying LRMs under compute constraints. The training-free design and the reported cross-benchmark improvements are notable strengths.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claimed 10.7% accuracy improvement and 25.9% latency reduction on AIME25 are presented without any description of how the entropy threshold was chosen, whether it was tuned on validation or test data, the precise baselines, or error bars/statistical tests. These omissions directly undermine evaluation of the central routing claim.
- [§3] §3 (Method): the load-bearing assumption that small-model first-token entropy reliably indicates difficulty of the full step for the large model receives no cross-model validation, ablation against large-model error rates or token counts, or evidence that a single fixed threshold generalizes without per-benchmark retuning.
minor comments (1)
- [§3] Clarify the exact lightweight and large model pair used, the precise entropy formula, and whether any post-hoc verification of routed steps was performed.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments highlight important gaps in experimental transparency and validation of the core routing assumption. We address each point below and will incorporate the requested clarifications and additional analyses into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claimed 10.7% accuracy improvement and 25.9% latency reduction on AIME25 are presented without any description of how the entropy threshold was chosen, whether it was tuned on validation or test data, the precise baselines, or error bars/statistical tests. These omissions directly undermine evaluation of the central routing claim.
Authors: We agree that the threshold selection procedure and evaluation details must be explicitly documented. The entropy threshold (set to 1.2 nats) was chosen on a small held-out validation split drawn from the same distribution as the test benchmarks to achieve a target accuracy-latency trade-off; it was not tuned on the test data. We will expand §4 to describe this procedure, list all baselines (standalone LRM, random routing, and token-probability routing), report standard deviations over 5 random seeds, and include paired t-tests for the accuracy and latency differences. These additions will be reflected in both the abstract and the experimental section. revision: yes
-
Referee: [§3] §3 (Method): the load-bearing assumption that small-model first-token entropy reliably indicates difficulty of the full step for the large model receives no cross-model validation, ablation against large-model error rates or token counts, or evidence that a single fixed threshold generalizes without per-benchmark retuning.
Authors: We acknowledge that the manuscript currently lacks direct ablations linking small-model entropy to large-model step difficulty. In the revision we will add a new subsection in §3 that (i) reports the correlation between first-token entropy (from the 1.5B model) and subsequent large-model (7B) step accuracy on 500 sampled reasoning steps, (ii) compares entropy against large-model token-level uncertainty and step length as predictors, and (iii) shows that the same fixed threshold yields consistent gains across all five benchmarks without per-benchmark retuning. Full cross-model experiments with additional large-model families are computationally prohibitive for the current study but will be noted as future work. revision: partial
Circularity Check
No circularity: entropy routing is an independent observable, not a self-definition
full rationale
The paper's derivation chain is self-contained. It computes first-token entropy directly from the lightweight model's output distribution as an observable input, then applies a fixed threshold to decide routing. This does not reduce the claimed accuracy/latency gains to a fitted parameter or tautology by construction; the link between entropy and step difficulty is presented as an empirical correlation validated on benchmarks rather than defined into existence. No self-citations, uniqueness theorems, or ansatzes are invoked to force the result. The mechanism remains falsifiable against external large-model error rates and does not collapse into its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropy threshold
axioms (1)
- domain assumption Entropy of the initial token of a reasoning step predicts the difficulty of the full step
Forward citations
Cited by 2 Pith papers
-
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Multimodal LLMs process code as images to achieve up to 8x token compression, with visual cues like syntax highlighting aiding tasks and clone detection remaining resilient or even improving under compression.
-
RankGuide: Tensor-Rank-Guided Routing and Steering for Efficient Reasoning
RankGuide uses tensor-rank analysis of consecutive hidden states to route between small and large reasoning models and steer generations, reducing latency up to 1.75x while maintaining competitive accuracy on reasonin...
Reference graph
Works this paper leans on
-
[1]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa: Simple llm inference acceleration frame- work with multiple decoding heads.arXiv preprint arXiv:2401.10774. Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023a. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318. Lingjiao Chen, Matei Zahar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas
Stepwise perplexity-guided refinement for efficient chain-of- thought reasoning in large language models.arXiv preprint arXiv:2502.13260. Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas
-
[3]
arXiv preprint arXiv:2410.04707
Learning how hard to think: Input-adaptive allocation of lm computation. arXiv preprint arXiv:2410.04707. Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks VS Laksh- manan, and Ahmed Hassan Awadallah
-
[4]
arXiv preprint arXiv:2404.14618
Hybrid llm: Cost-efficient and quality-aware query routing. arXiv preprint arXiv:2404.14618. Tianyu Fu, Yi Ge, Yichen You, Enshu Liu, Zhihang Yuan, Guohao Dai, Shengen Yan, Huazhong Yang, and Yu Wang
-
[5]
R2r: Efficiently navigating divergent reasoning paths with small-large model token routing.arXiv preprint arXiv:2505.21600. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Minghao Hu, Junzhe Wang, Weisen Zhao, Qiang Zeng, and Lannan Luo
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Flowmaltrans: Unsuper- vised binary code translation for malware detec- tion using flow-adapter architecture.arXiv preprint arXiv:2508.20212. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others
-
[8]
Openai o1 system card.arXiv preprint arXiv:2412.16720. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Live- codebench: Holistic and contamination free eval- uation of large language models for code.arXiv preprint arXiv:2403.07974. Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Semantic uncertainty: Linguistic invariances for un- certainty estimation in natural language generation. arXiv preprint arXiv:2302.09664. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
9 Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang
Swe-debate: Competitive multi- agent debate for software issue resolution.arXiv preprint arXiv:2507.23348. 9 Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang
-
[12]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Eagle: Speculative sampling re- quires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077. Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, Christof Monz, Silvio Savarese, Doyen Sahoo, and Caiming Xiong
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Orange: a method for evaluating automatic evaluation metrics for machine translation. InCOLING 2004: Pro- ceedings of the 20th International Conference on Computational Linguistics, pages 501–507. Andrey Malinin and Mark Gales
work page 2004
-
[14]
Uncertainty esti- mation in autoregressive structured prediction.arXiv preprint arXiv:2002.07650. Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica
-
[15]
Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.18665. OpenAI
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Specreason: Fast and accurate inference-time compute via specu- lative reasoning.arXiv preprint arXiv:2504.07891. Xiaoye Qu, Yafu Li, Zhaochen Su, Weigao Sun, Jianhao Yan, Dongrui Liu, Ganqu Cui, Daizong Liu, Shuxian Liang, Junxian He, and 1 others
-
[17]
Nils Reimers and Iryna Gurevych
A survey of efficient reasoning for large reasoning models: Lan- guage, multimodality, and beyond.arXiv preprint arXiv:2503.21614. Nils Reimers and Iryna Gurevych
-
[18]
InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Associa- tion for Computational Linguistics. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Ju- lian Michael, and Samuel R Bowman
work page 2019
-
[19]
InFindings of the Association for Com- putational Linguistics: EMNLP 2025, pages 24405– 24415
Speccot: Accelerating chain-of-thought reasoning through speculative ex- ploration. InFindings of the Association for Com- putational Linguistics: EMNLP 2025, pages 24405– 24415. Qiuchen Wang, Ruixue Ding, Zehui Chen, Weiqi Wu, Shihang Wang, Pengjun Xie, and Feng Zhao. 2025a. Vidorag: Visual document retrieval-augmented gen- eration via dynamic iterative ...
-
[20]
Prox- ythinker: Test-time guidance through small visual reasoners.arXiv preprint arXiv:2505.24872. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025a. Qwen3 technical report.arXiv preprint arXiv:2505.09388. Wang Yang, Xiang Yue, Vipin Chaudhary, and Xiao- tian Han. 202...
-
[21]
Given an input question, the system operates in a step-wise manner. At the onset of each step, instead of blindly generating the full content, GlimpRouter employs MS to “glimpse” the first token, yielding an entropy Hinit that quan- tizes the difficulty of the upcoming step: If Hinit falls below a threshold, the step is deemed routine, and the small model...
-
[22]
Step 3 (Critical Pivot) Content (MS):“Maybe I can try to find...”( Hinit: 1.8985> τ) ,→Action: Intervene (M L) Content (ML):The most efficient way is to divide 2024 by 2 repeatedly to find its binary representa- tion directly. Step 4[SLM](H init: 0.0046) Compute2024/2 = 1012, remainder0. Step 5[SLM](H init: 0.0008) Then1012/2 = 506, remainder0. Step 6[SLM...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.