Vision-and-Language Navigation for UAVs: Progress, Challenges, and a Research Roadmap
Pith reviewed 2026-05-10 13:44 UTC · model grok-4.3
The pith
UAV vision-and-language navigation has progressed from modular and deep learning methods to agentic systems using large foundation models, with a proposed roadmap for addressing deployment barriers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a methodological taxonomy that charts the technological evolution from early modular and deep learning approaches to contemporary agentic systems driven by large foundation models, including VLMs, VLA models, and the emerging integration of generative world models with VLA architectures for physically-grounded reasoning. It reviews the ecosystem of simulators, datasets, and evaluation metrics, conducts a critical analysis of the primary challenges impeding real-world deployment including the simulation-to-reality gap, robust perception in dynamic outdoor settings, reasoning with linguistic ambiguity, and efficient deployment of large models, and concludes by proposing a
What carries the argument
The methodological taxonomy that organizes the evolution of UAV-VLN approaches from modular and deep learning to agentic foundation model systems.
Load-bearing premise
That the taxonomy comprehensively captures all important developments in the field and that the four challenges are the main barriers to real-world UAV deployment.
What would settle it
A review of the latest literature identifying multiple UAV-VLN approaches that fall outside the proposed taxonomy categories or uncovering additional primary challenges not listed in the survey.
Figures










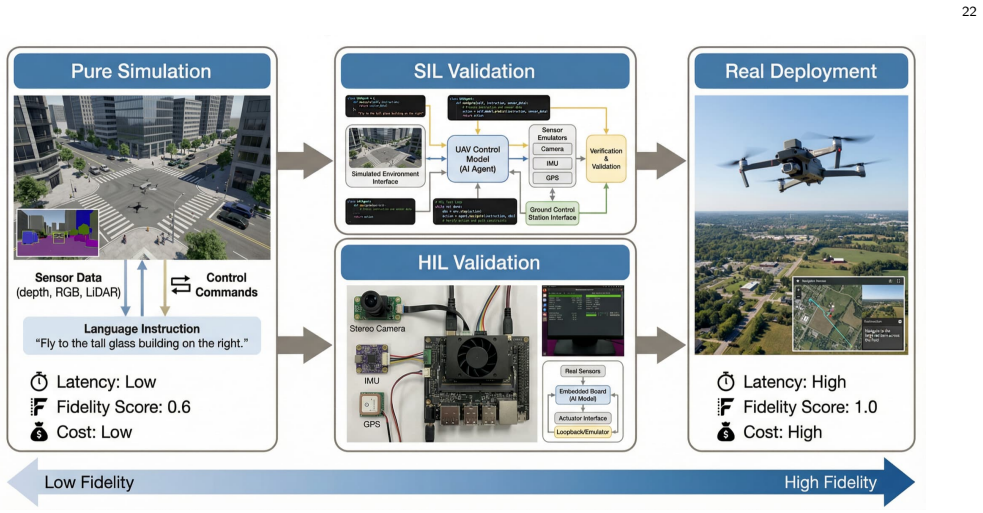




read the original abstract
Vision-and-Language Navigation for Unmanned Aerial Vehicles (UAV-VLN) represents a pivotal challenge in embodied artificial intelligence, focused on enabling UAVs to interpret high-level human commands and execute long-horizon tasks in complex 3D environments. This paper provides a comprehensive and structured survey of the field, from its formal task definition to the current state of the art. We establish a methodological taxonomy that charts the technological evolution from early modular and deep learning approaches to contemporary agentic systems driven by large foundation models, including Vision-Language Models (VLMs), Vision-Language-Action (VLA) models, and the emerging integration of generative world models with VLA architectures for physically-grounded reasoning. The survey systematically reviews the ecosystem of essential resources simulators, datasets, and evaluation metrics that facilitates standardized research. Furthermore, we conduct a critical analysis of the primary challenges impeding real-world deployment: the simulation-to-reality gap, robust perception in dynamic outdoor settings, reasoning with linguistic ambiguity, and the efficient deployment of large models on resource-constrained hardware. By synthesizing current benchmarks and limitations, this survey concludes by proposing a forward-looking research roadmap to guide future inquiry into key frontiers such as multi-agent swarm coordination and air-ground collaborative robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys Vision-and-Language Navigation for UAVs (UAV-VLN), defining the task and establishing a methodological taxonomy that traces evolution from early modular and deep-learning approaches to contemporary agentic systems based on VLMs, VLA models, and generative world models. It reviews the ecosystem of simulators, datasets, and evaluation metrics, critically analyzes four primary challenges (simulation-to-reality gap, robust perception in dynamic outdoor settings, reasoning with linguistic ambiguity, and efficient deployment of large models), and concludes with a forward-looking research roadmap covering multi-agent swarm coordination and air-ground collaboration.
Significance. If the taxonomy and challenge prioritization hold, the survey would organize a rapidly evolving subfield of embodied AI, synthesize benchmarks, and provide a useful roadmap for UAV navigation research. The structured progression from modular to foundation-model approaches and the explicit focus on real-world deployment barriers could help standardize evaluation and direct effort toward high-impact areas.
major comments (1)
- [Taxonomy and Challenges sections] The central claim that the survey establishes a comprehensive methodological taxonomy and identifies the four primary challenges rests on an undocumented literature selection process. No section (including the taxonomy presentation or challenges analysis) specifies search databases, keywords, date ranges, inclusion/exclusion criteria, total papers screened, or quantitative breakdown of coverage per category. This absence makes it impossible to assess whether the reviewed works are representative or whether omitted issues (e.g., safety certification or regulatory constraints) are equally load-bearing.
minor comments (2)
- [Abstract] The abstract and introduction could include a brief quantitative overview (e.g., number of papers reviewed or distribution across taxonomy categories) to give readers immediate context on scope.
- [Resources and Evaluation Metrics sections] A summary table mapping taxonomy categories to representative papers, simulators, and metrics would improve readability and allow quick cross-referencing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our survey. We address the major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Taxonomy and Challenges sections] The central claim that the survey establishes a comprehensive methodological taxonomy and identifies the four primary challenges rests on an undocumented literature selection process. No section (including the taxonomy presentation or challenges analysis) specifies search databases, keywords, date ranges, inclusion/exclusion criteria, total papers screened, or quantitative breakdown of coverage per category. This absence makes it impossible to assess whether the reviewed works are representative or whether omitted issues (e.g., safety certification or regulatory constraints) are equally load-bearing.
Authors: We agree that documenting the literature selection process would enhance the transparency and reproducibility of the survey. Our review was comprehensive, drawing from key publications in the field, but it was not conducted as a formal systematic review with predefined protocols. To address this, we will revise the manuscript to include a dedicated 'Literature Review Methodology' subsection. This will specify the primary sources (arXiv, major robotics and AI conferences such as ICRA, IROS, CVPR, NeurIPS), search keywords (e.g., 'UAV VLN', 'drone vision language navigation', 'aerial embodied AI'), date range (papers published from 2015 onwards), and quantitative breakdown of coverage per category. Regarding potential omitted issues such as safety certification and regulatory constraints, we acknowledge their importance for real-world UAV deployment. We will incorporate a brief discussion of these in the challenges section and the research roadmap, noting them as complementary barriers alongside the four primary technical challenges we identified. revision: yes
Circularity Check
No circularity: survey synthesizes external literature without self-referential derivations
full rationale
This paper is a literature survey that defines a taxonomy of UAV-VLN approaches and lists challenges by reviewing prior external work. No equations, fitted parameters, predictions, or derivations appear in the abstract or described structure. The central claims rest on synthesis of cited literature rather than any reduction to the paper's own inputs, self-citations as load-bearing premises, or renamed ansatzes. Absence of documented search methods affects representativeness but does not create circularity under the specified patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
CosFly: Plan in the Matrix, Fly in the World
CosFly introduces a box-structured planning and multimodal simulation pipeline for aerial target tracking in CARLA, paired with the public CosFly-Track dataset containing 250 trajectories and approximately 100,000 ren...
Reference graph
Works this paper leans on
-
[1]
T. Feng et al. Embodied AI: From LLMs to world models. IEEE Circuits and Systems Magazine , 2025
work page 2025
-
[2]
Large model empow- ered embodied ai: A survey on decision-making and embodied learning,
W. Liang et al. Large model empowered embodied ai: A survey on decision-making and embodied learning. arXiv preprint arXiv:2508.10399, 2025
-
[3]
Y. Liu et al. Aligning cyber space with physical world: A comprehensive survey on embodied AI. arXiv preprint arXiv:2407.06886, 2024
-
[4]
K. Choutri et al. Leveraging large language models for real-time uav control. Electronics, 14(21):4312, 2025
work page 2025
-
[5]
S. A. Salunkhe et al. Intuitive human-drone collaborative navigation in unknown environments through mixed reality. In 2025 International Conference on Unmanned Aircraft Systems (ICUAS), 2025
work page 2025
- [6]
- [7]
-
[8]
H. Cai et al. FlightGPT: Towards generalizable and inter- pretable UA V vision-and-Language Navigation with vision- Language Models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pp. 6659– 6676, Suzhou, China, november 2025. Association for Compu- tational Linguistics
work page 2025
-
[9]
L. Feng. Invited speaker 1: Navigation without GPS for un- manned aerial vehicles. In 2019 International Conference on Computer and Drone Applications (IConDA) , pp. 1, 2019
work page 2019
-
[10]
L. Seidel et al. Advancing early wildfire detection: Integration of vision language models with unmanned aerial vehicle remote sensing for enhanced situational awareness. Drones, 9(5):347, 2025
work page 2025
-
[11]
E. Salahat et al. Waypoint planning for autonomous aerial inspection of large-scale solar farms. In IECON 2019 - 45th Annual Conference of the IEEE Industrial Electronics Society , pp. 763–769, 2019
work page 2019
-
[12]
Z. Zhou et al. A lightweight drone vision system for autonomous inspection with real-time processing. Drones, 10(2):126, 2026
work page 2026
-
[13]
X. Zhang et al. Logisticsvln: Vision-language navigation for low- altitude terminal delivery based on agentic uavs. In 2025 IEEE 28th International Conference on Intelligent Transportation Systems (ITSC), 2025
work page 2025
-
[14]
D. H. Lee et al. A review on recent deep learning-based seman- tic segmentation for urban greenness measurement. Sensors, 24(7):2245, 2024
work page 2024
-
[15]
Uavs meet agentic ai: A multidomain survey of autonomous aerial intelligence and agentic uavs,
R. Sapkota et al. Uavs meet agentic ai: A multidomain survey of autonomous aerial intelligence and agentic uavs. arXiv preprint arXiv:2506.08045, 2025
-
[16]
L. Morando and G. Loianno. Spatial assisted human-drone col- laborative navigation and interaction through immersive mixed reality. In 2024 IEEE International Conference on Robotics and Automation (ICRA) , 2024
work page 2024
-
[17]
J. Feng et al. A survey of large language model-powered spatial intelligence across scales: Advances in embodied agents, smart cities, and earth science. arXiv preprint arXiv:2504.09848 , 2025
-
[18]
Y. Zhang et al. Vision-and-language navigation today and to- morrow: A survey in the era of foundation models. Transactions on Machine Learning Research, 2024. Survey Certification
work page 2024
-
[19]
R. Firoozi et al. Foundation models in robotics: Applications, challenges, and the future. The International Journal of Robotics Research, 44(5):701–739, 2024
work page 2024
-
[20]
S. Chen et al. Exploring embodied multimodal large models: Development, datasets, and future directions. Information Fusion, 122:103198, 2025
work page 2025
-
[21]
Pure vision language action (vla) models: A comprehensive survey.arXiv preprint arXiv:2509.19012,
D. Zhang et al. Pure vision language action (vla) models: A comprehensive survey. arXiv preprint arXiv:2509.19012 , 2025
-
[22]
R. Sapkota et al. Vision-language-action (vla) models: Con- cepts, progress, applications and challenges. arXiv preprint arXiv:2505.04769, 2025
-
[23]
Embodied navigation foundation model
J. Zhang et al. Embodied Navigation Foundation Model. arXiv preprint arXiv:2509.12129, 2025
-
[24]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 , 2024. 31
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck et al. GR00T N1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 , 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
NVIDIA. Cosmos-Reason1: From physical common sense to embodied reasoning. arXiv preprint arXiv:2503.15558 , 2025
work page internal anchor Pith review arXiv 2025
-
[27]
P. Anderson et al. Vision-and-language navigation: Interpret- ing visually-grounded navigation instructions in real environ- ments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3674–3683, 2018
work page 2018
- [28]
- [29]
- [30]
- [31]
-
[32]
W. Zhang et al. CityNavAgent: Aerial Vision-and-Language Navigation with Hierarchical Semantic Planning and Global Memory. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pp. 31292–31309, Vienna, Austria, jul 2025. Association for Computational Linguistics
work page 2025
- [33]
- [34]
- [35]
- [36]
-
[37]
Y. Tian et al. UA Vs Meet LLMs: Overviews and Perspectives Toward Agentic Low-Altitude Mobility. Information Fusion , 122:103158, 2025
work page 2025
-
[38]
S. Javaid et al. Large language models for uavs: Current state and pathways to the future. arXiv preprint arXiv:2405.01745 , 2024
-
[39]
X. Zhao et al. Agrivln: Vision-and-language navigation for agricultural robots. arXiv preprint arXiv:2508.07406 , 2025
-
[40]
A. Torneiro et al. Towards general urban monitoring with vision-language models: A review, evaluation, and a research agenda. arXiv preprint arXiv:2510.12400 , 2025
-
[41]
K. Osmani and D. Schulz. Comprehensive investigation of un- manned aerial vehicles (uavs): An in-depth analysis of avionics systems. Sensors, 24(10):3064, 2024
work page 2024
-
[42]
A. Xiao et al. Foundation models for remote sensing and earth observation: A survey. IEEE Geoscience and Remote Sensing Magazine, 2024
work page 2024
-
[43]
X. Weng et al. Vision-language modeling meets remote sens- ing: Models, datasets and perspectives. IEEE Geoscience and Remote Sensing Magazine , 2025
work page 2025
- [44]
-
[45]
L. Zhai et al. Intelligent optimization algorithms for multi-uav path planning: A comprehensive review. IEEE Access, 13:1–1, 2025
work page 2025
-
[46]
W. Y. H. Adoni et al. Investigation of autonomous multi- uav systems for target detection in distributed environment: Current developments and open challenges. Drones, 7(4):263, 2023
work page 2023
-
[47]
Y. Gong et al. Safe and economical uav trajectory planning in low-altitude airspace: A hybrid drl-llm approach with compli- ance awareness. arXiv preprint arXiv:2506.08532 , 2025
-
[48]
E. Cereda et al. On-device self-supervised learning of visual per- ception tasks aboard hardware-limited nano-quadrotors. arXiv preprint arXiv:2403.04071, 2024
-
[49]
J. Wang et al. Vision-based deep reinforcement learning of unmanned aerial vehicle (uav) autonomous navigation using privileged information. Drones, 8(12):782, 2024
work page 2024
-
[50]
M. Sartori et al. AI and vision based autonomous navigation of nano-drones in partially-known environments. In 2025 21st International Conference on Distributed Computing in Smart Systems and the Internet of Things (DCOSS-IoT) , 2025
work page 2025
-
[51]
P. Doma et al. LLM-Enhanced Path Planning: Safe and Effi- cient Autonomous Navigation with Instructional Inputs. arXiv preprint arXiv:2412.02655, 2024
-
[52]
F. Frattolillo et al. Scalable and cooperative deep reinforcement learning approaches for multi-uav systems: A systematic review. Drones, 7(4):236, 2023
work page 2023
-
[53]
K. I. Qureshi et al. Multi-agent drl for air-to-ground com- munication planning in uav-enabled iot networks. Sensors, 24(20):6535, 2024
work page 2024
-
[54]
A. Singla et al. Memory-based deep reinforcement learning for obstacle avoidance in UA V with limited environment knowl- edge. IEEE Transactions on Intelligent Transportation Sys- tems, 22(1):107–118, 2021
work page 2021
- [55]
-
[56]
H. Hong et al. Why only text: Empowering vision-and-language navigation with multi-modal prompts. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intel- ligence, IJCAI-24, pp. 839–847, 8 2024
work page 2024
- [57]
-
[58]
C. Huang et al. Visual language maps for robot navigation. In 2023 IEEE International Conference on Robotics and Automa- tion (ICRA), pp. 9947–9954, 2023
work page 2023
-
[59]
X. Liang et al. Real-time semantic octree mapping under aerial-ground cooperative system. Intelligent Service Robotics , 18(3):567–578, 2025
work page 2025
-
[60]
H. Shi et al. DAgger Diffusion Navigation: DAgger Boosted Diffusion Policy for Vision-Language Navigation. arXiv preprint arXiv:2508.09444, 2025
- [61]
-
[62]
X. Wang et al. UA V-Flow Colosseo: A Real-World Benchmark for Flying-on-a-Word UA V Imitation Learning. In Thirty- ninth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , 2025
work page 2025
-
[63]
X. Song et al. Towards long-horizon vision-language navigation: Platform, benchmark and method. In Proceedings of the IEEE/ CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12078–12088, 2025
work page 2025
-
[64]
P. Saxena et al. UA V-VLN: End-to-end vision language guided navigation for UA Vs. In 2025 European Conference on Mobile Robots (ECMR), pp. 1–6, 2025
work page 2025
-
[65]
J. Krantz et al. Waypoint models for instruction-guided naviga- tion in continuous environments. In Proceedings of the IEEE/ CVF International Conference on Computer Vision (ICCV) , pp. 15162–15171, 2021
work page 2021
-
[66]
O. Sautenkov et al. UA V-VLA: Vision-language-action sys- tem for large scale aerial mission generation. arXiv preprint arXiv:2501.05014, 2025
-
[67]
T. Manjunath et al. Reprohrl: Towards multi-goal navigation in the real world using hierarchical agents. In AAAI Conference on Artificial Intelligence, RL Ready for Production Workshop , 2023
work page 2023
-
[68]
F. Zhao et al. Autonomous localized path planning algorithm for UA Vs based on TD3 strategy. Scientific Reports, 14(1):763, 2024
work page 2024
-
[69]
L. Jiang et al. Improving multi-UA V cooperative path-finding through multiagent experience learning. Applied Intelligence , 54:11103–11119, 2024
work page 2024
- [70]
-
[71]
S. Sanyal and K. Roy. Asma: An adaptive safety margin algorithm for vision-language drone navigation via scene-aware 32 control barrier functions. IEEE Robotics and Automation Letters, 10(8):7536–7543, 2025
work page 2025
-
[72]
M. Ramezani and J. L. Sanchez-Lopez. Human-Centric Aware UA V Trajectory Planning in Search and Rescue Mis- sions Employing Multi-Objective Reinforcement Learning with AHP and Similarity-Based Experience Replay. arXiv preprint arXiv:2402.18487, 2024
-
[73]
C. Wang et al. Uav path planning in multi-task environments with risks through natural language understanding. Drones, 7(3):147, 2023
work page 2023
-
[74]
GPS denied IBVS-based navigation and collision avoidance of UA V using a low-cost RGB camera,
X. Wang et al. GPS denied IBVS-based navigation and collision avoidance of UA V using a low-cost RGB camera.arXiv preprint arXiv:2509.17435, 2025
- [75]
-
[76]
S. Chen et al. History aware multimodal transformer for vision- and-language navigation. In Advances in Neural Information Processing Systems, 2021
work page 2021
- [77]
-
[78]
Target-grounded graph- aware transformer for aerial vision-and-dialog navigation,
Y. Su et al. Target-grounded graph-aware transformer for aerial vision-and-dialog navigation. arXiv preprint arXiv:2308.11561, 2023
-
[79]
Z. Liu et al. Trivla: A triple-system-based unified vision- language-action model with episodic world modeling for general robot control. arXiv preprint arXiv:2507.01424 , 2025
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.