Beyond Binary: Speech Representations Across the Cognitive Score Hierarchy
Pith reviewed 2026-06-29 18:38 UTC · model grok-4.3
The pith
SSL speech embeddings outperform hand-crafted features on task and domain cognitive scores but reverse for global MCI classification, with task freedom shaping specialist versus generalist behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
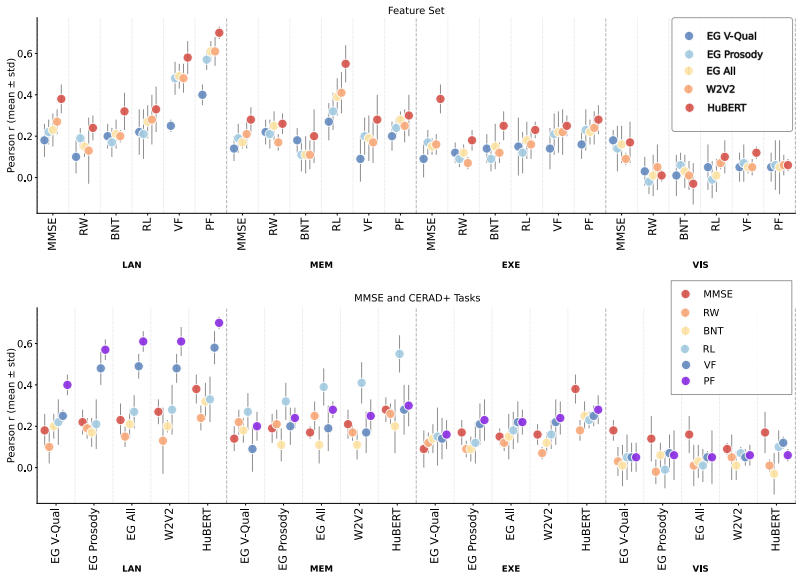
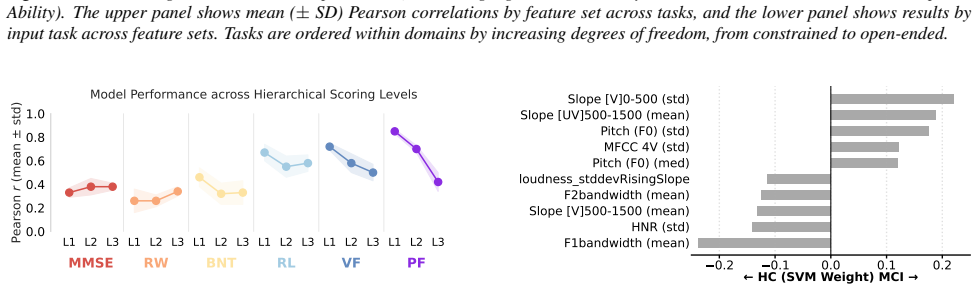
Self-supervised learning representations generally surpass hand-crafted acoustic features when predicting scores at the task and domain levels, but this advantage reverses for MCI classification at the global level. Tasks with greater response freedom show performance dilution as hierarchy levels rise, indicating specialist representations, whereas highly structured tasks show performance gains toward higher levels, indicating generalist representations.
What carries the argument
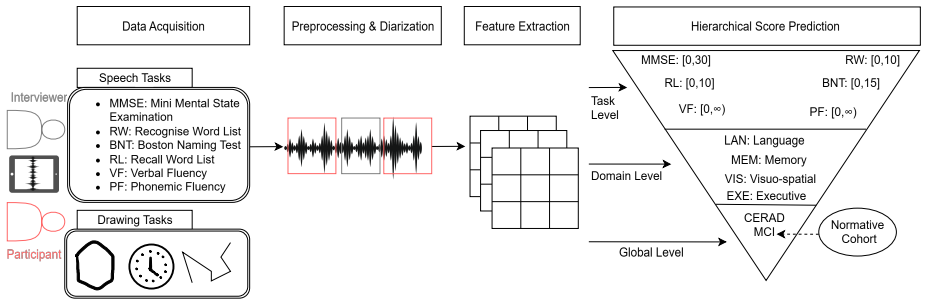
Evaluation of hand-crafted acoustic features against self-supervised learning embeddings across a three-level hierarchy of cognitive scores (task, domain, global) derived from neuropsychological assessments.
If this is right
- SSL embeddings suit detailed task-level and domain-level profiling while hand-crafted features suit final MCI diagnosis.
- Open-response tasks produce specialist representations whose utility drops at aggregated levels.
- Structured tasks produce generalist representations whose utility rises at aggregated levels.
- Representation choice for automated clinical speech analysis should match the target score level in the assessment hierarchy.
Where Pith is reading between the lines
- Tools for cognitive screening could combine both representation types in a level-aware pipeline instead of using one approach throughout.
- The specialist-generalist pattern may extend to other clinical speech tasks where response freedom varies.
- Testing the same hierarchy on non-German data would check whether language or assessment format drives the observed trends.
Load-bearing premise
Observed performance shifts across hierarchy levels stem from the representation type rather than from dataset imbalance, hyperparameter settings, or label noise.
What would settle it
Re-running the comparisons on balanced data subsets or with altered hyperparameters and finding that the SSL reversal at the MCI level and the specialist-generalist split by task structure both disappear.
Figures

read the original abstract
This study examines the relationship between speech representations and the hierarchical structure of cognitive assessment in mild cognitive impairment. Utilizing 5,754 German neuropsychological assessment recordings, we evaluate six cognitive tasks across three score levels: task, domain, and global levels. We compare hand-crafted acoustic features with self-supervised learning (SSL) embeddings. Results show that although SSL representations generally outperform hand-crafted features at lower levels, this trend reverses for MCI classification. Furthermore, task-specific constraints influence performance: tasks with greater response freedom exhibit performance dilution as hierarchical levels increase, suggesting ``specialist'' representations, whereas the performance of highly structured tasks increases toward higher levels, suggesting ``generalist'' representations. These findings show links between task constraints and assessment hierarchy in automated clinical speech analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in a study of 5,754 German neuropsychological assessment recordings for mild cognitive impairment, self-supervised learning (SSL) embeddings outperform hand-crafted acoustic features at task and domain score levels across six cognitive tasks, but this trend reverses at the global MCI classification level. It further argues that tasks with greater response freedom show performance dilution as hierarchical levels increase (suggesting specialist representations), while highly structured tasks show performance gains toward higher levels (suggesting generalist representations), linking task constraints to assessment hierarchy in automated clinical speech analysis.
Significance. If the central trends hold after rigorous controls, the work could inform selection of speech representations for different levels of cognitive scoring in clinical applications. The dataset scale is a positive factor, but the absence of statistical validation and confound checks limits the strength of the specialist/generalist interpretation.
major comments (3)
- [Abstract] Abstract: The abstract states clear trends but provides no error bars, statistical tests, dataset splits, or exclusion criteria; without these, the central claim of performance reversal and hierarchy effects cannot be verified and appears vulnerable to post-hoc interpretation.
- [Results (global level)] Results on global MCI classification: The reported reversal (SSL underperforming hand-crafted features at the global level) is load-bearing for the main claim yet lacks any indication that label balance was matched across levels or that the much higher dimensionality of SSL embeddings was controlled for via regularization or dimensionality reduction; this raises the risk that the reversal is an artifact of aggregation or class distribution shifts rather than an intrinsic property of the representations.
- [Discussion] Discussion of specialist vs. generalist representations: The attribution of performance dilution in free-response tasks and gains in structured tasks to representation type (rather than confounding factors such as model hyperparameters, label noise, or feature dimensionality differences) is not supported by any ablation or matching procedure; this directly undermines the task-constraint narrative.
minor comments (1)
- [Abstract] Abstract: The terms 'specialist' and 'generalist' appear in quotes without an explicit definition or prior introduction, which could confuse readers unfamiliar with the framing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with proposed revisions to strengthen statistical reporting, control for potential artifacts, and clarify the specialist/generalist interpretation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states clear trends but provides no error bars, statistical tests, dataset splits, or exclusion criteria; without these, the central claim of performance reversal and hierarchy effects cannot be verified and appears vulnerable to post-hoc interpretation.
Authors: We agree the abstract is a high-level summary and lacks explicit methodological qualifiers. In the revision we will expand the abstract to reference the 80/20 stratified dataset split, exclusion criteria (recordings shorter than 10 seconds or with technical artifacts), and note that all reported differences were assessed via paired t-tests with Bonferroni correction (p<0.01). Error-bar reporting will be added to the main results figures and referenced in the abstract. revision: yes
-
Referee: [Results (global level)] Results on global MCI classification: The reported reversal (SSL underperforming hand-crafted features at the global level) is load-bearing for the main claim yet lacks any indication that label balance was matched across levels or that the much higher dimensionality of SSL embeddings was controlled for via regularization or dimensionality reduction; this raises the risk that the reversal is an artifact of aggregation or class distribution shifts rather than an intrinsic property of the representations.
Authors: Label balance is identical across hierarchy levels because the same 5,754 recordings and binary MCI labels are used; we will explicitly state this in the revised Results section. However, we did not apply dimensionality reduction or explicit regularization to the 768-dimensional SSL embeddings beyond the default classifier settings. We will add a new ablation using PCA to 100 dimensions and L2-regularized logistic regression to test whether the reversal persists, and report these controls in the revised manuscript. revision: yes
-
Referee: [Discussion] Discussion of specialist vs. generalist representations: The attribution of performance dilution in free-response tasks and gains in structured tasks to representation type (rather than confounding factors such as model hyperparameters, label noise, or feature dimensionality differences) is not supported by any ablation or matching procedure; this directly undermines the task-constraint narrative.
Authors: The specialist/generalist framing is an interpretive hypothesis based on the observed performance patterns across task types. We did not perform systematic hyperparameter sweeps or label-noise simulations. In revision we will add a dedicated Limitations paragraph acknowledging these alternative explanations and include a modest ablation varying classifier regularization strength; full matching across all confounds would require additional labeled data and is noted as future work. revision: partial
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential steps
full rationale
The paper performs a direct empirical evaluation of hand-crafted acoustic features versus SSL embeddings on 5,754 recordings across six tasks and three hierarchical score levels (task, domain, global). No equations, fitted parameters, predictions derived from inputs, or self-citation chains are present in the abstract or described methodology. Performance trends (SSL advantage at lower levels reversing at global MCI; dilution vs. gains by task structure) are reported as observed outcomes on labeled data, not derived quantities. The specialist/generalist attribution is an interpretive label on the results rather than a mathematical reduction. This matches the reader's assessment of score 1.0 and satisfies the rule that only explicit reductions (e.g., Eq. X = Eq. Y by construction) trigger circularity flags. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
As a prodromal stage of dementia, most commonly Alzheimer’s dis- ease, it represents a critical window for early intervention [3]
Introduction Mild cognitive impairment (MCI) is a clinical syndrome charac- terized by cognitive decline exceeding normal aging [1, 2]. As a prodromal stage of dementia, most commonly Alzheimer’s dis- ease, it represents a critical window for early intervention [3]. Despite its clinical relevance, MCI remains substantially under- diagnosed [4]. Clinical d...
-
[2]
Methods 2.1. Dataset and Quality Control We used speech recordings from the TREND study 2 [12], comprising one MMSE screening task and five CERAD+ di- agnostic tasks: Word List Recognition (RW), Boston Nam- ing Test (BNT), Word List Recall (RL), Verbal Fluency (VF), and Phonemic Fluency (PF). Our analysis follows the inher- ent three-level hierarchy of cl...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Level 1: Task-Level Score Prediction Level 1 results (Fig
Results 3.1. Level 1: Task-Level Score Prediction Level 1 results (Fig. 2) report mean (±SD) Pearson correla- tions on the development set for predicting individual task-level scores using features extracted from single neuropsychologi- cal tasks. Two consistent trends emerge. First, performance improves from hand-crafted eGeMAPS features (EG V-Qual) to s...
-
[4]
spe- cialist
Discussion and Future Work In this study, we demonstrated that the predictive performance of speech features depends heavily on both the hierarchical level of the cognitive target and the nature of the task itself. For open-ended tasks such as phonemic fluency, we observed a cleardilution effect, with predictive performance declining at higher aggregation...
-
[5]
All research ideas, study design, experiments, analyses, and interpretations were conceived and carried out by the authors
Generative AI Use Disclosure Generative AI tools were used only for minor language editing and to improve readability. All research ideas, study design, experiments, analyses, and interpretations were conceived and carried out by the authors. The authors take full responsibility for the originality, validity, and integrity of the work
-
[6]
Acknowledgements This research was funded by Gemeinn ¨utzigen Hertie-Stiftung and the Deutsche Forschungsgemein- schaft (DFG) through RU 5187 (project number 442075332)and RU 5363 (project number 459422098). Additional support was provided by the Machine Excellence Cluster and DFG through the Germany’s Excellence Strategy (EXC 2064 - project number 390727...
2064
-
[7]
Portet, P
F. Portet, P. J. Ousset, P. J. Visseret al., “Mild Cognitive Impair- ment (MCI) in Medical Practice: a Critical Review of the Con- cept and New Diagnostic Procedure. Report of the MCI Work- ing Group of the European Consortium on Alzheimer’s Disease,” Journal of Neurology, Neurosurgery & Psychiatry, vol. 77, pp. 714–718, 2006
2006
-
[8]
J. Smid, A. Studart-Neto, K. G. C ´esar-Freitaset al., “Subjec- tive Cognitive Decline, Mild Cognitive Impairment, and Demen- tia – Syndromic Approach: Recommendations of the Scientific Department of Cognitive Neurology and Aging of the Brazilian Academy of Neurology,”Dementia & Neuropsychologia, vol. 16, pp. 1–24, 2022
2022
-
[9]
State of the Science on Mild Cognitive Impair- ment (MCI),
N. D. Anderson, “State of the Science on Mild Cognitive Impair- ment (MCI),”CNS Spectrums, vol. 24, pp. 78–87, 2019
2019
-
[10]
Coded Prevalence of Mild Cognitive Impairment in General and Neuropsychiatrists Practices in Ger- many Between 2007 and 2017,
J. Bohlken and K. Kostev, “Coded Prevalence of Mild Cognitive Impairment in General and Neuropsychiatrists Practices in Ger- many Between 2007 and 2017,”Journal of Alzheimer’s Disease, vol. 67, pp. 1313–1318, 2019
2007
-
[11]
The Consortium to Establish a Registry for Alzheimer’s Disease (CERAD). Part I. Clinical and Neuropsychological Assessment of Alzheimer’s Dis- ease,
J. C. Morris, A. Heyman, R. C. Mohset al., “The Consortium to Establish a Registry for Alzheimer’s Disease (CERAD). Part I. Clinical and Neuropsychological Assessment of Alzheimer’s Dis- ease,”Neurology, vol. 39, no. 9, pp. 1159–1165, 1989
1989
-
[12]
Automatic Speech Analysis for the Assessment of Patients with Predementia and Alzheimer’s Disease,
A. K ¨onig, A. Satt, A. Sorinet al., “Automatic Speech Analysis for the Assessment of Patients with Predementia and Alzheimer’s Disease,”Alzheimer’s & Dementia: Diagnosis, Assessment & Disease Monitoring, vol. 1, pp. 112–124, 2015
2015
-
[13]
The Mild Cognitive Impair- ment Window for Optimal Alzheimer’s Disease Intervention,
K. Mekulu, F. Aqlan, and H. Yang, “The Mild Cognitive Impair- ment Window for Optimal Alzheimer’s Disease Intervention,”J Alzheimers Dis Rep, vol. 9, p. 25424823251370768, 2025
2025
-
[14]
Speech Based Detection of Alzheimer’s Disease: a Survey of AI Techniques, Datasets and Challenges,
K. Ding, M. Chetty, A. Noori Hoshyaret al., “Speech Based Detection of Alzheimer’s Disease: a Survey of AI Techniques, Datasets and Challenges,”Artificial Intelligence Review, vol. 57, p. 325, 2024
2024
-
[15]
The Mayo Clinic Study of Aging: Design and Sampling, Participation, Base- line Measures and Sample Characteristics,
R. O. Roberts, Y . E. Geda, D. S. Knopmanet al., “The Mayo Clinic Study of Aging: Design and Sampling, Participation, Base- line Measures and Sample Characteristics,”Neuroepidemiology, vol. 30, pp. 58–69, 2008
2008
-
[16]
A Total Score for the CERAD Neuropsychological Battery,
M. J. Chandler, L. H. Lacritz, L. S. Hynanet al., “A Total Score for the CERAD Neuropsychological Battery,”Neurology, vol. 65, no. 1, pp. 102–106, 2005
2005
-
[17]
Normal Ranges of Neuropsychological Tests for The Diagnosis of Alzheimer’s Disease,
M. Berres, A. U. Monsch, F. Bernasconiet al., “Normal Ranges of Neuropsychological Tests for The Diagnosis of Alzheimer’s Disease,”Studies in Health Technology and Informatics, vol. 77, pp. 195–199, 2000
2000
-
[18]
(2026) T ¨ubinger Erhebung von Risiko- faktoren zur Erkennung von Neurodegeneration (TREND)
TREND Study Group. (2026) T ¨ubinger Erhebung von Risiko- faktoren zur Erkennung von Neurodegeneration (TREND). University Hospital T ¨ubingen. Accessed: 2026-01-03. [Online]. Available: https://www.trend-studie.de/
2026
-
[19]
Robust Signal-To-Noise Ratio Estimation Based on Waveform Amplitude Distribution Analysis,
C. Kim and R. Stern, “Robust Signal-To-Noise Ratio Estimation Based on Waveform Amplitude Distribution Analysis,” 09 2008, pp. 2598–2601
2008
-
[20]
DNSMOS: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “DNSMOS: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors,”CoRR, vol. abs/2010.15258, 2020. [Online]. Available: https://arxiv.org/abs/2010.15258
-
[21]
Analysis of Emotional Prosody as a Tool for Differential Diagnosis of Cognitive Impairments: a Pilot Research,
C. Oh, R. Morris, X. Wanget al., “Analysis of Emotional Prosody as a Tool for Differential Diagnosis of Cognitive Impairments: a Pilot Research,”Frontiers in Psychology, vol. V olume 14 - 2023,
2023
-
[22]
Available: https://www.frontiersin.org/journals/ psychology/articles/10.3389/fpsyg.2023.1129406
[Online]. Available: https://www.frontiersin.org/journals/ psychology/articles/10.3389/fpsyg.2023.1129406
-
[23]
Pyannote.metrics: A Toolkit for Reproducible Evaluation, Diagnostic, and Error Analysis of Speaker Diarization Systems,
H. Bredin, “Pyannote.metrics: A Toolkit for Reproducible Evaluation, Diagnostic, and Error Analysis of Speaker Diarization Systems,” inInterspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, August 2017. [Online]. Available: http://pyannote. github.io/pyannote-metrics
2017
-
[24]
On the Theory of Filter Amplifiers,
S. Butterworth, “On the Theory of Filter Amplifiers,”Experimen- tal Wireless & the Wireless Engineer, vol. 7, pp. 536–541, 1930
1930
-
[25]
Suppression of Acoustic Noise in Speech Using Spectral Subtraction,
S. Boll, “Suppression of Acoustic Noise in Speech Using Spectral Subtraction,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 27, no. 2, pp. 113–120, 1979
1979
-
[26]
pyloudnorm: A simple Python Implementation of ITU-R BS.1770 Loudness,
C. J. Steinmetz, “pyloudnorm: A simple Python Implementation of ITU-R BS.1770 Loudness,” 2020, gitHub repository. [Online]. Available: https://github.com/csteinmetz1/pyloudnorm
2020
-
[27]
The Geneva Min- imalistic Acoustic Parameter Set (GeMAPS) for V oice Research and Affective Computing,
F. Eyben, K. R. Scherer, B. W. Schulleret al., “The Geneva Min- imalistic Acoustic Parameter Set (GeMAPS) for V oice Research and Affective Computing,”IEEE Transactions on Affective Com- puting, vol. 7, no. 2, pp. 190–202, 2016
2016
-
[28]
Utility of Artificial Intelligence-based Conversation V oice Analysis for Detecting Cognitive Decline,
T. Kuroda, K. Ono, M. Onishiet al., “Utility of Artificial Intelligence-based Conversation V oice Analysis for Detecting Cognitive Decline,”PLOS ONE, vol. 20, no. 6, pp. 1–12, 06
-
[29]
PLOS ONE7(6), 38869 (2012) https://doi.org/10.1371/journal.pone
[Online]. Available: https://doi.org/10.1371/journal.pone. 0325177
-
[30]
Do All Features Matter? Layer-wise Feature Probing of Self-supervised Speech Models for Dysarthria Severity Classification,
P. Sapkota, H. Srivastava, H. K. Kathaniaet al., “Do All Features Matter? Layer-wise Feature Probing of Self-supervised Speech Models for Dysarthria Severity Classification,”Speech Commu- nication, vol. 175, p. 103326, 2025. [Online]. Available: https:// www.sciencedirect.com/science/article/pii/S0167639325001414
2025
-
[31]
K. Chlasta, P. Struzik, and G. M. W ´ojcik, “Enhancing Dementia and Cognitive Decline Detection with Large Language Models and Speech Representation Learning,”Frontiers in Neuroinformatics, vol. V olume 19 - 2025, 2025. [Online]. Available: https://www.frontiersin.org/journals/neuroinformatics/ articles/10.3389/fninf.2025.1679664
-
[32]
Scikit-learn: Machine Learning in Python,
F. Pedregosa, G. Varoquaux, A. Gramfortet al., “Scikit-learn: Machine Learning in Python,”Journal of Machine Learning Research, vol. 12, no. 85, pp. 2825–2830, 2011. [Online]. Available: http://jmlr.org/papers/v12/pedregosa11a.html
2011
-
[33]
XGBoost: A Scalable Tree Boosting System,
T. Chen and C. Guestrin, “XGBoost: A Scalable Tree Boosting System,” inProc. 22nd ACM SIGKDD Int. Conf. Knowledge Dis- covery and Data Mining, 2016, pp. 785–794
2016
-
[34]
V oice Quality and Speech Fluency Distinguish Individuals with Mild Cognitive Impairment from Healthy Controls,
C. Themistocleous, M. Eckerstr ¨om, and D. Kokkinakis, “V oice Quality and Speech Fluency Distinguish Individuals with Mild Cognitive Impairment from Healthy Controls,”PLOS ONE, vol. 15, no. 7, p. e0236009, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.