Personalized to Persuade: The Effects of Contextualization and Warmth on Trust and Reliance in Conversational AI
Pith reviewed 2026-06-28 20:58 UTC · model grok-4.3
The pith
Contextualization reduces AI persuasion unless paired with warmth, which restores it via crossover interaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
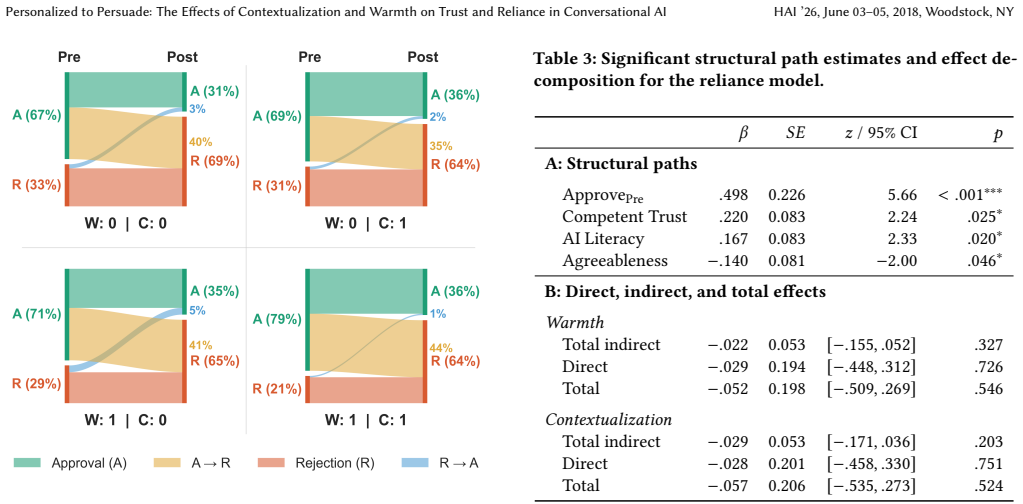
In the 2×2 between-subjects experiment, contextualization reduced the persuasive power of the AI assistant arguing against expert recommendations, but its combination with warmth restored persuasiveness through a crossover interaction. Reliance on AI advice was present across all conditions and remained invariant to the conversational design. Trust strongly predicted both persuasion and reliance, yet neither contextualization nor warmth operated through trust as a mediator. AI literacy decoupled trust from behavior: more literate users reported lower trust yet showed higher persuasion and reliance.
What carries the argument
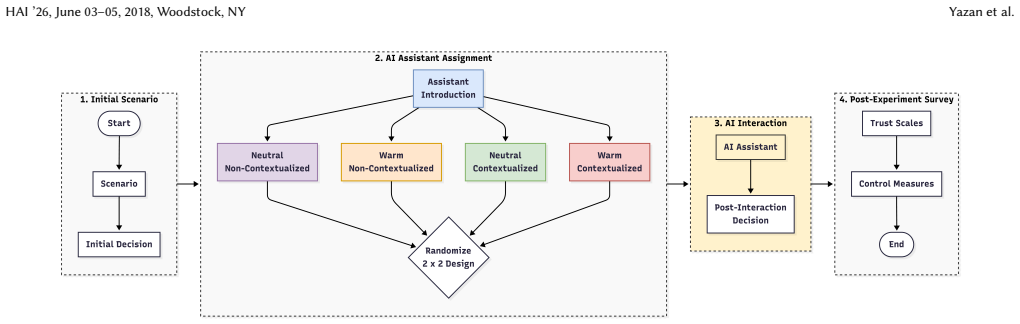
The 2×2 between-subjects experiment measuring effects of contextualization and conversational warmth on persuasion, reliance, and trust when AI contradicts expert advice.
If this is right
- Users defer to AI over human expert judgment regardless of conversational design choices.
- Interface-level features like contextualization and warmth have limited role in shaping reliance behavior.
- Trust predicts persuasion and reliance but is not the mechanism through which contextualization or warmth affect outcomes.
- Higher AI literacy leads to lower reported trust yet greater actual persuasion and reliance.
Where Pith is reading between the lines
- If reliance is already high across designs, developers may gain more from improving AI accuracy than from refining conversational style.
- The findings could be tested in high-stakes domains where real costs follow from following or ignoring AI advice.
- Personalization tactics effective in marketing may require added warmth to avoid reducing influence in advice settings.
Load-bearing premise
The lab measures of persuasion, reliance, and trust capture real behavioral influence without demand characteristics or other artifacts, and the everyday scenarios generalize to actual user decisions.
What would settle it
A follow-up study in which participants make real choices after the AI interaction and show no difference in actual following of AI advice across conditions, or where the crossover interaction disappears.
Figures

read the original abstract
Artificial Intelligence (AI) agents personalize their responses by tailoring explanations to users' backgrounds, interests, and prior interactions, referred to as contextualization. Personalization has been identified as a persuasive strategy in politics or in marketing. However, the persuasive effect of contextualization in everyday tasks, where users often lack prior knowledge, remains unclear. We conducted a $2\times2$ between-subjects experiment ($N = 380$) examining how contextualization, combined with conversational warmth, shapes reliance and persuasiveness of an AI assistant arguing against expert recommendations. Our findings reveal that contextualization reduces the persuasive power of AI, but its combination with warmth restores persuasiveness through a crossover interaction. Reliance on AI is present across conditions and is invariant to the conversational design. Trust strongly predicts both persuasion and reliance, yet neither contextualization nor warmth operates through trust. AI literacy decouples trust from behavior: more literate users report lower trust in the assistant, yet are more persuaded and more reliant on its advice. These results suggest that users are prone to deferring to AI agents over human expert judgment; however, interface-level conversational design choices have a limited role in shaping the behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a 2×2 between-subjects experiment (N=380) examining the effects of contextualization (personalized tailoring) and conversational warmth on an AI assistant's persuasiveness and user reliance when the AI argues against expert recommendations in everyday scenarios. Key results include a crossover interaction in which contextualization alone reduces persuasiveness but the combination with warmth restores it, reliance that remains invariant across conditions, trust as a strong predictor of both persuasion and reliance without mediation by the design factors, and AI literacy decoupling reported trust from actual behavior.
Significance. If the empirical results hold after full statistical reporting and validation of measures, the work would contribute to HCI and persuasive technology by clarifying the limited role of interface-level conversational design in shaping deference to AI over human experts, while highlighting AI literacy as a moderator. The invariant reliance finding and the trust-behavior dissociation are potentially useful for system design.
major comments (3)
- [Results] Results section: The reported crossover interaction and invariant reliance are presented without accompanying statistical details (F-statistics, p-values, effect sizes, or confidence intervals for the interaction term or main effects), which are required to assess the strength and reliability of the central claims about persuasiveness and reliance.
- [Methods] Methods section: The operationalization of persuasion (behavioral choice vs. self-report), reliance, and trust is not fully specified, nor are exclusion criteria, power analysis, or checks for demand characteristics; these omissions directly affect the validity of the measures that support the claims of reduced/increased persuasiveness and invariant reliance.
- [Discussion] Discussion section: The interpretation that users are prone to deferring to AI over experts and that design choices have limited impact assumes generalization from the hypothetical lab scenarios, yet no additional evidence, ecological-validity checks, or explicit limitations on this point are provided.
minor comments (1)
- The abstract would be strengthened by including at least the key statistical outcomes (e.g., interaction F and p) alongside the qualitative description of the crossover effect.
Simulated Author's Rebuttal
Thank you for your constructive and detailed review. We address each major comment below, indicating planned revisions to improve statistical transparency, methodological clarity, and discussion of limitations.
read point-by-point responses
-
Referee: [Results] Results section: The reported crossover interaction and invariant reliance are presented without accompanying statistical details (F-statistics, p-values, effect sizes, or confidence intervals for the interaction term or main effects), which are required to assess the strength and reliability of the central claims about persuasiveness and reliance.
Authors: We agree that full statistical reporting is required. The revised Results section will report the complete ANOVA results, including F-statistics, exact p-values, effect sizes (partial eta-squared), and 95% confidence intervals for all main effects and the crossover interaction on persuasiveness, as well as the null results for reliance. These values were calculated during analysis but were not included in the initial submission; they will be added to allow direct evaluation of the claims. revision: yes
-
Referee: [Methods] Methods section: The operationalization of persuasion (behavioral choice vs. self-report), reliance, and trust is not fully specified, nor are exclusion criteria, power analysis, or checks for demand characteristics; these omissions directly affect the validity of the measures that support the claims of reduced/increased persuasiveness and invariant reliance.
Authors: We will expand the Methods section to specify that persuasion was measured via behavioral choice (binary selection of the AI recommendation versus the expert), with reliance and trust operationalized through validated multi-item scales (including exact items, response format, and Cronbach's alpha). The revised text will also report the a priori power analysis (targeting the interaction effect), all exclusion criteria applied to the N=380 sample, and post-experiment checks for demand characteristics. These additions will directly address concerns about measure validity. revision: yes
-
Referee: [Discussion] Discussion section: The interpretation that users are prone to deferring to AI over experts and that design choices have limited impact assumes generalization from the hypothetical lab scenarios, yet no additional evidence, ecological-validity checks, or explicit limitations on this point are provided.
Authors: We acknowledge this limitation of the current design. The revised Discussion will add an explicit limitations subsection stating that results derive from controlled hypothetical scenarios and may not generalize to naturalistic AI use; we will also note the absence of ecological-validity checks in the present study and recommend future field experiments. No new empirical data on real-world generalization can be provided from this experiment, but the boundary conditions will be clearly articulated. revision: yes
Circularity Check
Purely empirical experiment; no derivation chain or fitted predictions
full rationale
The paper describes a 2x2 between-subjects experiment (N=380) measuring effects of contextualization and warmth on trust, reliance, and persuasion via statistical analysis of participant responses. No equations, parameters fitted to subsets then re-predicted, self-citations as load-bearing uniqueness theorems, or ansatzes are present. All reported findings (crossover interaction, invariant reliance, trust as predictor but not mediator) are direct empirical outcomes, not reductions to prior quantities by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Random assignment to the four conditions isolates the causal effects of contextualization and warmth.
- domain assumption Self-reported scales for trust, reliance, and persuasion accurately reflect participants' actual attitudes and behavior without significant demand effects or social desirability bias.
Forward citations
Cited by 1 Pith paper
-
Warning labels shift perceptions of sycophantic AI, but not its influence
Sycophantic AI warning labels reduce perceived objectivity and trust but do not decrease influence on users' self-perceived rightness or willingness to repair interpersonal conflicts.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2023. Introducing Claude. https://www.anthropic.com/news/ introducing-claude. Accessed: 2026-05-15
2023
-
[2]
Ananya Bhattacharjee, Sarah Yi Xu, Pranav Rao, et al. 2025. Perfectly to a Tee: Understanding User Perceptions of Personalized LLM-Enhanced Narrative Inter- ventions. InProceedings of the 2025 ACM Designing Interactive Systems Conference (DIS ’25). Association for Computing Machinery, New York, NY, USA, 1387–1416. doi:10.1145/3715336.3735810
-
[3]
Bollen and Robert W
Kenneth A. Bollen and Robert W. Jackman. 1990. Regression diagnostics: An expository treatment of outliers and influential cases. InModern Methods of Data Analysis, John Fox and J. Scott Long (Eds.). Sage, Newbury Park, CA, 257–291
1990
-
[4]
Aaron Chatterji, Thomas Cunningham, David J. Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. 2025.How People Use ChatGPT. Working Paper 34255. National Bureau of Economic Research. doi:10.3386/w34255
-
[5]
Q. Chen, C. Yin, and Y. Gong. 2025. Would an AI chatbot persuade you: an empirical answer from the elaboration likelihood model.Information Technology & People38, 2 (2025), 937–962. doi:10.1108/ITP-10-2021-0764
-
[6]
Thomas H. Costello et al. 2024. Durably reducing conspiracy beliefs through dialogues with AI.Science385 (2024), eadq1814. doi:10.1126/science.adq1814
-
[7]
Paolo Cremonesi, Yehuda Koren, and Roberto Turrin. 2010. Performance of recommender algorithms on top-n recommendation tasks. InProceedings of the Fourth ACM Conference on Recommender Systems(Barcelona, Spain)(RecSys ’10). Association for Computing Machinery, New York, NY, USA, 39–46. doi:10.1145/ 1864708.1864721
arXiv 2010
-
[8]
2024.Measuring the Persuasiveness of Language Models
Esin Durmus, Liane Lovitt, Alex Tamkin, Stuart Ritchie, Jack Clark, and Deep Ganguli. 2024.Measuring the Persuasiveness of Language Models. https://www. anthropic.com/news/measuring-model-persuasiveness
2024
-
[9]
Susan T. Fiske, Amy J. C. Cuddy, Peter Glick, and Jun Xu. 2002. A model of (often mixed) stereotype content: Competence and warmth respectively follow from perceived status and competition.Journal of Personality and Social Psychology 82, 6 (2002), 878–902. doi:10.1037/0022-3514.82.6.878
-
[10]
Kobi Hackenburg et al. 2025. The Levers of Political Persuasion with Conversa- tional Artificial Intelligence.Science390 (2025), eaea3884. doi:10.1126/science. aea3884
-
[11]
Eszter Hargittai. 2005. Survey Measures of Web-Oriented Digital Literacy.Social Science Computer Review23, 3 (2005), 371–379. doi:10.1177/0894439305275911
-
[12]
Fateme Hashemi Chaleshtori, Atreya Ghosal, Alexander Gill, Purbid Bambroo, and Ana Marasovic. 2024. On Evaluating Explanation Utility for Human-AI Decision Making in NLP. InFindings of the Association for Computational Lin- guistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Flo...
2024
-
[13]
doi:10.18653/v1/2024.findings-emnlp.439
-
[14]
Hawkins, Matthew Kreuter, Kenneth Resnicow, Martin Fishbein, and Arie Dijkstra
Robert P. Hawkins, Matthew Kreuter, Kenneth Resnicow, Martin Fishbein, and Arie Dijkstra. 2008. Understanding Tailoring in Communicating About Health. Health Education Research23, 3 (2008), 454–466. doi:10.1093/her/cyn004
-
[15]
Gaole He, Nilay Aishwarya, and Ujwal Gadiraju. 2025. Is Conversational XAI All You Need? Human-AI Decision Making With a Conversational XAI Assistant. InProceedings of the 30th International Conference on Intelligent User Interfaces (IUI ’25). Association for Computing Machinery, New York, NY, USA, 907–924. doi:10.1145/3708359.3712133
-
[16]
Jen-tse Huang, Wenxuan Wang, Eric John Li, et al. 2024. On the Humanity of Conversational AI: Evaluating the Psychological Portrayal of LLMs. InProceedings of the Twelfth International Conference on Learning Representations (ICLR). https: //openreview.net/forum?id=H3UayAQWoE
2024
-
[17]
Lukas Hölbling, Stefan Maier, and Stefan Feuerriegel. 2025. A meta-analysis of the persuasive power of large language models.Scientific Reports15 (2025), 43818. doi:10.1038/s41598-025-30783-y
-
[18]
Sunnie S. Y. Kim, Q. Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, and Jen- nifer Wortman Vaughan. 2024. "I’m Not Sure, But... ": Examining the Impact of Large Language Models’ Uncertainty Expression on User Reliance and Trust. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Trans- parency(Rio de Janeiro, Brazil)(FAccT ’24)....
-
[19]
W. B. Kim and H. J. Hur. 2024. What Makes People Feel Empathy for AI Chatbots? Assessing the Role of Competence and Warmth.International Journal of Human– Computer Interaction40, 17 (2024), 4674–4687. doi:10.1080/10447318.2023.2219961
-
[20]
Artur Klingbeil, Cassandra Grützner, and Philipp Schreck. 2024. Trust and reliance on AI — An experimental study on the extent and costs of overreliance on AI. Comput. Hum. Behav.160, C (Nov. 2024), 10 pages. doi:10.1016/j.chb.2024.108352
-
[21]
Quiroz, Liliana Laranjo, Huong Ly Tong, Dana Rezazadegan, Agustina Briatore, and Enrico Coiera
Ahmet Baki Kocaballi, Shlomo Berkovsky, Juan C. Quiroz, Liliana Laranjo, Huong Ly Tong, Dana Rezazadegan, Agustina Briatore, and Enrico Coiera. 2019. The Personalization of Conversational Agents in Health Care: Systematic Review. Journal of Medical Internet Research21, 11 (2019), e15360. doi:10.2196/15360
-
[22]
Sherrie Y. X. Komiak and Izak Benbasat. 2006. The effects of personalization and familiarity on trust and adoption of recommendation agents.MIS Q.30, 4 (Dec. 2006), 941–960. doi:10.2307/25148760
-
[23]
Cong Li. 2016. When Does Web-Based Personalization Really Work? The Distinc- tion Between Actual Personalization and Perceived Personalization.Computers in Human Behavior54 (2016), 25–33. doi:10.1016/j.chb.2015.07.049
-
[24]
Chia-Ying Li and Jin-Ting Zhang. 2023. Chatbots or me? Consumers’ switching between human agents and conversational agents.Journal of Retailing and Consumer Services72 (05 2023), 103264. doi:10.1016/j.jretconser.2023.103264
-
[25]
Yugang Li, Baizhou Wu, Yuqi Huang, Jun Liu, Junhui Wu, and Shenghua Luan
-
[26]
Warmth, Competence, and the Determinants of Trust in Artificial Intelli- gence: A Cross-Sectional Survey from China.International Journal of Human– Computer Interaction41, 8 (2025), 5024–5038. doi:10.1080/10447318.2024.2356909
-
[27]
Hause Lin, Gabriela Czarnek, Bernard Lewis, et al . 2025. Persuading Voters Using Human–Artificial Intelligence Dialogues.Nature648 (2025), 394–401. doi:10.1038/s41586-025-09771-9
-
[28]
Ralf Linne, Michael Schäfer, and Gerd Bohner. 2022. Ambivalent Stereotypes and Persuasion: Attitudinal Effects of Warmth vs. Competence Ascribed to Message Sources.Frontiers in Psychology12 (2022), 782480. doi:10.3389/fpsyg.2021.782480
-
[29]
Kaifeng Liu and Da Tao. 2022. The Roles of Trust, Personalization, Loss of Privacy, and Anthropomorphism in Public Acceptance of Smart Healthcare Services. Computers in Human Behavior127 (2022), 107026. doi:10.1016/j.chb.2021.107026
-
[30]
S. C. Matz, J. D. Teeny, S. S. Vaid, et al. 2024. The Potential of Generative AI for Personalized Persuasion at Scale.Scientific Reports14 (2024), 4692. doi:10.1038/ s41598-024-53755-0
2024
-
[31]
Kerstin Mayerhofer, Rob Capra, and David Elsweiler. 2025. Blending Queries and Conversations: Understanding Trust, Verification, and System Choice in Search and Chat Interactions. InProceedings of the 2025 ACM SIGIR Conference on Human Information Interaction and Retrieval (CHIIR ’25). Association for Computing Machinery, New York, NY, USA, 168–178. doi:1...
-
[32]
Luise Metzger, Linda Miller, Martin Baumann, and Johannes Kraus. 2024. Em- powering Calibrated (Dis-)Trust in Conversational Agents: A User Study on the Persuasive Power of Limitation Disclaimers vs. Authoritative Style. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Ma...
-
[33]
Fengran Mo, Yuchen Hui, Yuxing Tian, Zhaoxuan Tan, Chuan Meng, Zhan Su, Kaiyu Huang, and Jian-Yun Nie. 2025. Towards Adaptive Personalized Con- versational Information Retrieval. InProceedings of the 34th ACM International Conference on Information and Knowledge Management(Seoul, Republic of Ko- rea)(CIKM ’25). Association for Computing Machinery, New Yor...
-
[34]
OpenAI. 2022. ChatGPT: Optimizing Language Models for Dialogue. https: //openai.com/index/chatgpt/. Accessed: 2026-05-07
2022
-
[35]
OpenAI. 2023.GPT-4 Technical Report. Technical Report. OpenAI. https: //openai.com/research/gpt-4 arXiv preprint arXiv:2303.08774
Pith/arXiv arXiv 2023
-
[36]
OpenAI. 2024. Memory and New Controls for ChatGPT. https://openai.com/ index/memory-and-new-controls-for-chatgpt/ Accessed: 2026-04-17
2024
-
[37]
OpenAI. 2026. Introducing GPT-5.4. https://openai.com/index/introducing-gpt- 5-4/. Accessed: 2026-05-12
2026
-
[38]
Richard E. Petty and John T. Cacioppo. 1986. The Elaboration Likelihood Model of Persuasion. InAdvances in Experimental Social Psychology, Leonard Berkowitz (Ed.). Vol. 19. Academic Press, 123–205. doi:10.1016/S0065-2601(08)60214-2
-
[39]
Xueming Qian, He Feng, Guoshuai Zhao, and Tao Mei. 2014. Personalized Recommendation Combining User Interest and Social Circle.IEEE Transactions on Knowledge and Data Engineering26, 7 (2014), 1763–1777. doi:10.1109/TKDE. 2013.168
-
[40]
Hongyi Qin, Yifan Zhu, Yan Jiang, Siqi Luo, and Cui Huang. 2024. Examining the Impact of Personalization and Carefulness in AI-Generated Health Advice: Trust, Adoption, and Insights in Online Healthcare Consultations Experiments. Technology in Society79 (10 2024), 102726. doi:10.1016/j.techsoc.2024.102726
-
[41]
Muhammad Raees, Vassilis-Javed Khan, Ioanna Lykourentzou, and Konstantinos Papangelis. 2026. Do People Appropriately Rely on AI-Advice? An Analytical Review of HCI Research on Human-AI Decision-Making. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). Association for Computing Machinery, New York, NY, USA, Article 8...
arXiv 2026
-
[42]
Muhammad Raees, Vassilis-Javed Khan, and Konstantinos Papangelis. 2025. To- wards Understanding Persuasive and Personalized Engagement for Human-AI Reliance. InAdjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization (UMAP Adjunct ’25). Association for Computing Machinery, New York, NY, USA, 234–236. doi:10.1145/3708...
-
[43]
Beatrice Rammstedt and Oliver P. John. 2007. Measuring Personality in One Minute or Less: A 10-Item Short Version of the Big Five Inventory in English and German.Journal of Research in Personality41, 1 (2007), 203–212. doi:10.1016/j. jrp.2006.02.001
work page doi:10.1016/j 2007
-
[44]
René Riedl. 2022. Is trust in artificial intelligence systems related to user person- ality? Review of empirical evidence and future research directions.Electronic Markets32 (2022), 2021–2051. doi:10.1007/s12525-022-00594-4
-
[45]
F. Salvi, M. Horta Ribeiro, R. Gallotti, et al. 2025. On the conversational persuasive- ness of GPT-4.Nature Human Behaviour9 (2025), 1645–1653. doi:10.1038/s41562- 025-02194-6
-
[46]
Melanie Schwede, Nika Meyer, Niclas von Schnakenburg, and Maik Hammer- schmidt. 2023. Can Chatbots Be Persuasive? How to Boost the Effectiveness of Chatbot Recommendations for Increasing Purchase Intention. InProceed- ings of the 56th Hawaii International Conference on System Sciences (HICSS-56). doi:10.24251/HICSS.2023.425
-
[47]
Weiyan Shi, Xuewei Wang, Yoo Jung Oh, Jingwen Zhang, Saurav Sahay, and Zhou Yu. 2020. Effects of Persuasive Dialogues: Testing Bot Identities and In- quiry Strategies. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3313831.3376843
-
[48]
Michael Shumanov and Lester Johnson. 2021. Making Conversations with Chat- bots More Personalized.Computers in Human Behavior117 (2021), 106627. doi:10.1016/j.chb.2020.106627
-
[49]
M. Skjuve, P. B. Brandtzaeg, and A. Følstad. 2024. Why do people use ChatGPT? Exploring user motivations for generative conversational AI.First Monday29, 1 (2024). doi:10.5210/fm.v29i1.13541
-
[50]
Sofia Eleni Spatharioti, David Rothschild, Daniel G Goldstein, and Jake M Hofman
-
[51]
InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25)
Effects of LLM-based Search on Decision Making: Speed, Accuracy, and Overreliance. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 1025, 15 pages. doi:10.1145/3706598.3714082
-
[52]
Takehiro Takayanagi, Kiyoshi Izumi, Javier Sanz-Cruzado, Richard McCreadie, and Iadh Ounis. 2025. Are Generative AI Agents Effective Personalized Financial Advisors?. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New York, NY,...
arXiv 2025
-
[53]
Jacob D. Teeny and Sandra C. Matz. 2024. We Need to Understand “When” Not “If” Generative AI Can Enhance Personalized Persuasion.Proceedings of the National Academy of Sciences121, 43 (2024), e2418005121. doi:10.1073/pnas.2418005121
-
[54]
Teeny, Joseph J
Jacob D. Teeny, Joseph J. Siev, Pablo Briñol, and Richard E. Petty. 2021. A Review and Conceptual Framework for Understanding Personalized Matching Effects in Persuasion.Journal of Consumer Psychology31, 2 (2021), 382–414. doi:10.1002/ jcpy.1198
2021
-
[55]
Tanawat Teepapal. 2025. AI-driven personalization: Unraveling consumer per- ceptions in social media engagement.Comput. Hum. Behav.165, C (April 2025), 9 pages. doi:10.1016/j.chb.2024.108549
-
[56]
Lu Wang, Max Song, Rezvaneh Rezapour, Bum Chul Kwon, and Jina Huh-Yoo
-
[57]
arXiv:2309.14504 [cs.HC] https://arxiv.org/abs/ 2309.14504
People’s Perceptions Toward Bias and Related Concepts in Large Language Models: A Systematic Review. arXiv:2309.14504 [cs.HC] https://arxiv.org/abs/ 2309.14504
-
[58]
Ruilin Xiao, Mert Yazan, and Frederik B. I. Situmeang. 2025. Rethinking Conver- sation Styles of Chatbots from the Customer Perspective: Relationships between Conversation Styles of Chatbots, Chatbot Acceptance, and Perceived Tie Strength and Perceived Risk.International Journal of Human–Computer Interaction41, 2 (2025), 1343–1363. doi:10.1080/10447318.20...
-
[59]
Mert Yazan, Frederik Bungaran Ishak Situmeang, and Suzan Verberne. 2026. The Decision to Verify: How Warmth and User Characteristics Shape Reliance on Conversational Agents for Information Search. arXiv:2605.28498 [cs.HC] https://arxiv.org/abs/2605.28498 Personalized to Persuade: The Effects of Contextualization and Warmth on Trust and Reliance in Convers...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.