Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
Pith reviewed 2026-06-27 14:03 UTC · model grok-4.3
The pith
Value gradients guide pre-trained flow policies to higher-value actions at test time without further training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QGF pre-trains a flow policy via behavioral cloning and a value critic, then at test time adds the value gradient to the flow sampling dynamics so that generated actions have higher expected value. No policy parameters are updated after pre-training. The method outperforms earlier test-time baselines on single-task and goal-conditioned offline RL benchmarks with high-dimensional actions and remains competitive with state-of-the-art training-time algorithms while using less compute and exhibiting better scaling with model size.
What carries the argument
Value-gradient guidance of the flow sampling process at inference time, which steers a fixed reference flow policy toward higher-value actions without retraining.
If this is right
- Expressive policies can receive policy improvement entirely after supervised training ends.
- Avoiding backpropagation through denoising removes a major source of training instability.
- The same pre-trained flow and critic pair works for both single-task and goal-conditioned settings.
- Computational cost drops because no actor-critic updates occur at training time.
- Larger models become practical because scaling is no longer limited by joint training instabilities.
Where Pith is reading between the lines
- The separation of generative modeling from value-based steering may extend to other families of expressive policies beyond flows.
- Test-time guidance could serve as a lightweight way to adapt a single pre-trained policy to new reward functions without retraining.
- If value estimates remain useful far from the training distribution, the method may reduce reliance on conservative offline RL objectives.
Load-bearing premise
The value function supplies a gradient that reliably improves sampled actions when added to the flow dynamics, without introducing new instabilities or requiring the critic to be accurate over the entire action distribution.
What would settle it
An experiment in which adding the value gradient to the flow sampler produces lower average returns than the unguided reference policy or causes the sampling process to diverge on a standard offline RL benchmark.
Figures

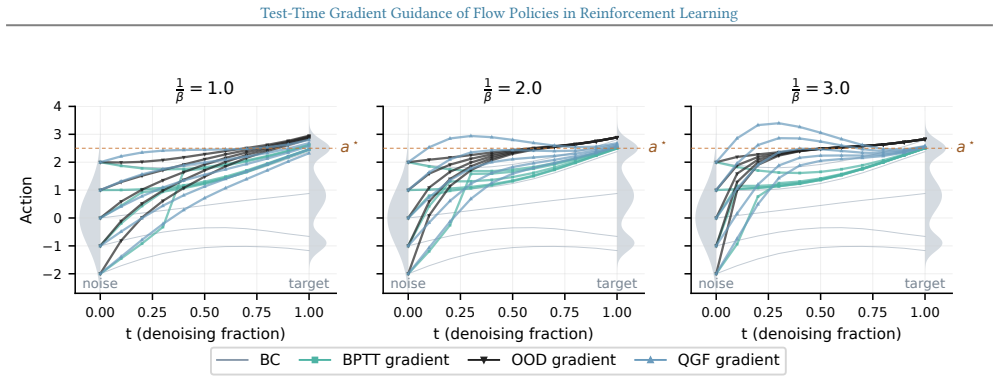


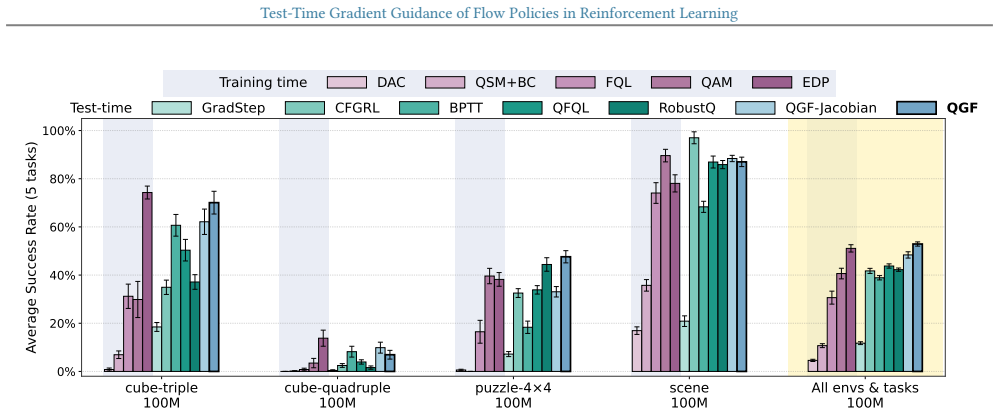
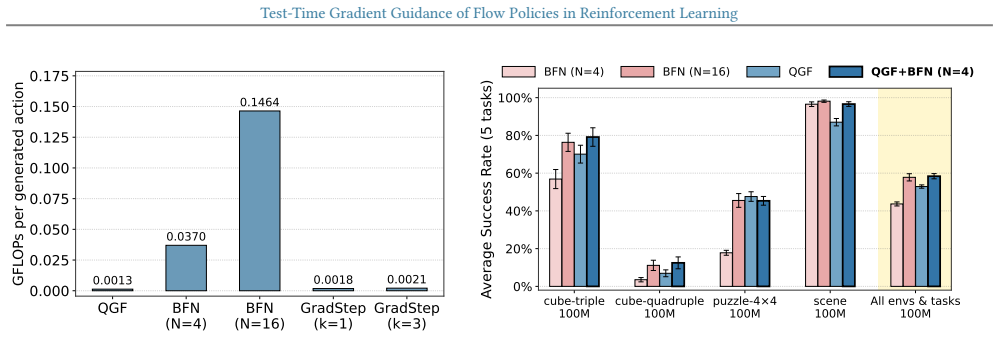
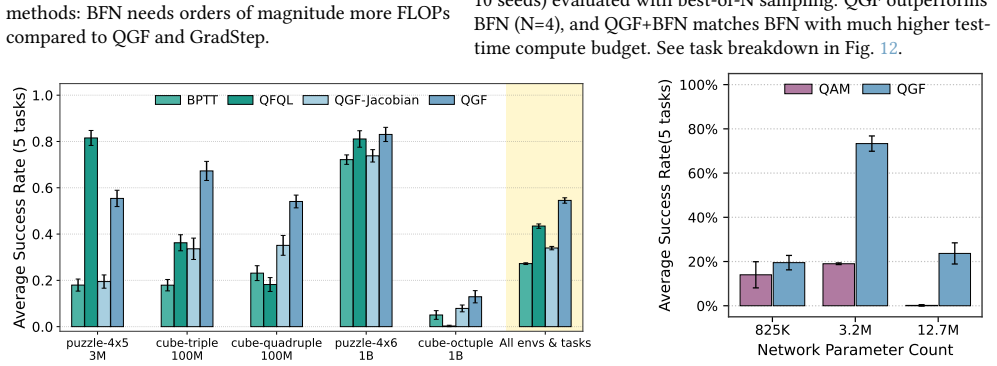
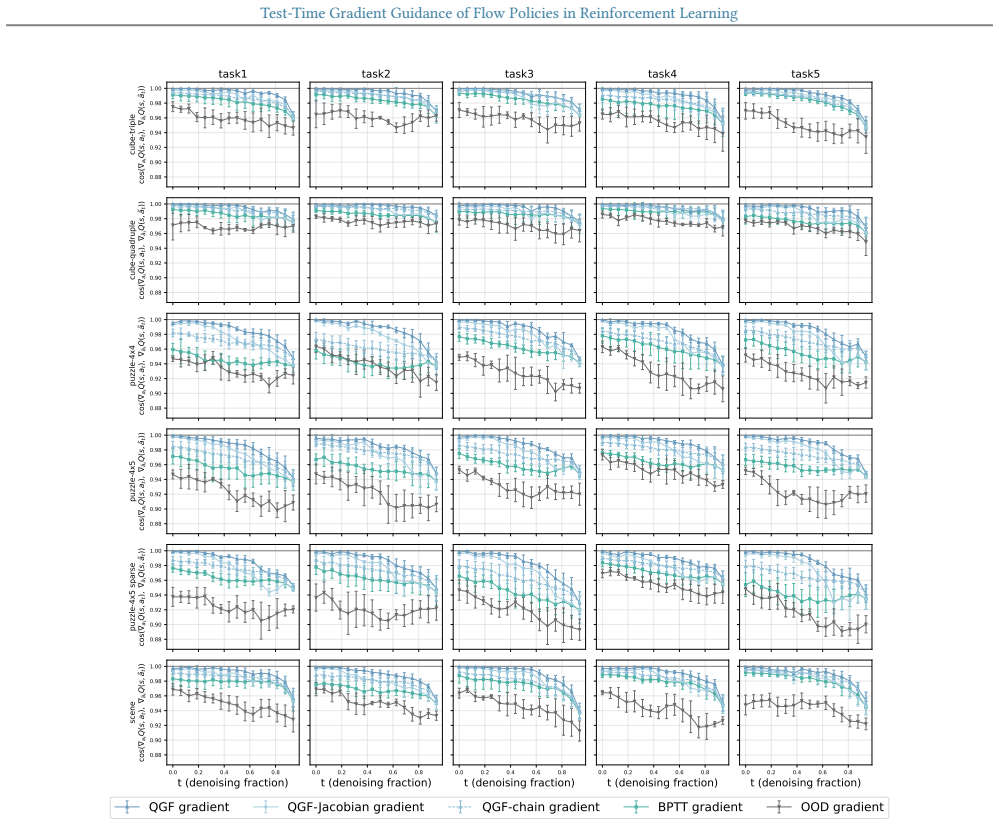
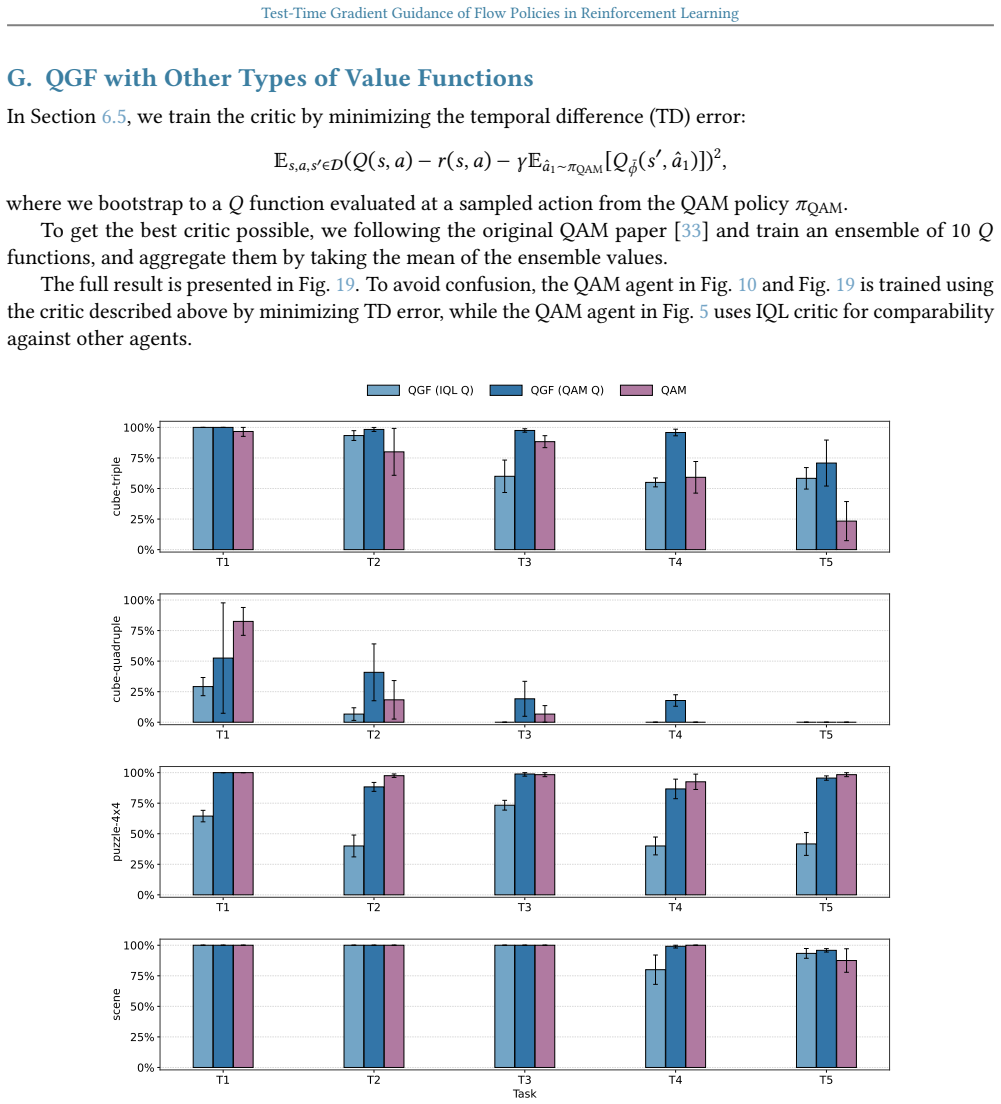
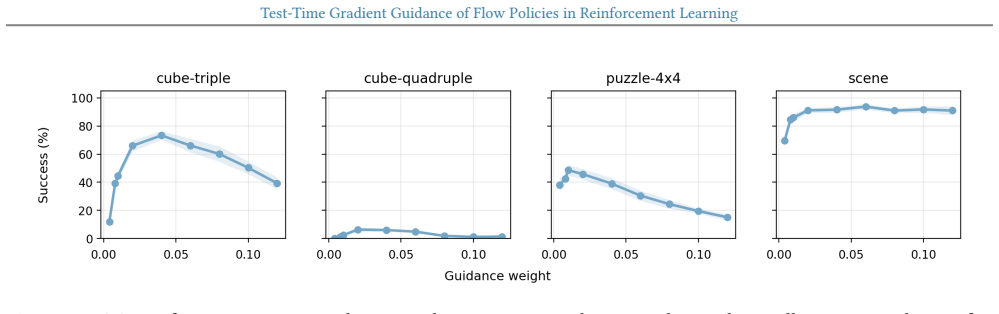
read the original abstract
Expressive continuous control policies, such as diffusion and flow models, form the backbone of recent advances in scaling imitation learning for simulated and real robot control. While they are known to scale stably in the supervised imitation learning setting, incorporating them into reinforcement learning (RL) pipelines for policy improvement has proven more difficult. It often requires specialized training objectives or backpropagating through denoising processes, which cause well-known issues with stability and affect scalability. In this paper we study the question of whether simple policy improvement schemes at test time alone, leaving stable supervised policy training intact, can be a competitive alternative which sidesteps these issues. To this end, we propose QGF (Q-Guided Flow), an RL algorithm that performs policy optimization entirely at test time. QGF works by pre-training both a reference flow policy (via a standard behavioral cloning objective) and a value function critic and, at test time, using the value gradient to guide the reference policy to generate higher-value actions without any additional policy learning. Empirically, QGF outperforms prior test-time RL methods on single-task and goal-conditioned offline RL benchmarks with high-dimensional action spaces, and is competitive with state-of-the-art training-time algorithms while being much cheaper to run. Moreover, it exhibits favorable scaling with model size by avoiding the instability of actor-critic training, offering a practical and effective alternative RL algorithm with expressive policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QGF (Q-Guided Flow), an RL method that pre-trains a flow-based policy via standard behavioral cloning and a separate value critic, then performs all policy improvement at test time by using the critic's value gradient to steer the reference flow sampling process toward higher-value actions. The central empirical claim is that QGF outperforms prior test-time RL methods on single-task and goal-conditioned offline RL benchmarks with high-dimensional action spaces, remains competitive with state-of-the-art training-time algorithms, and exhibits better scaling with model size by avoiding actor-critic training instabilities.
Significance. If the empirical results hold under rigorous evaluation, the work is significant for providing a stable, scalable way to incorporate expressive flow policies into RL without backpropagating through the sampling process or using specialized training objectives. By cleanly separating supervised pre-training from test-time guidance, it offers a practical alternative that could reduce computational cost and instability in high-dimensional control tasks.
major comments (2)
- [Section 3 (Method) and Section 4 (Experiments)] The central claim depends on the pre-trained critic's gradient reliably steering the flow toward higher-value actions at test time. However, in offline RL the critic is trained only on the behavior data distribution; any overestimation on OOD actions reachable by the guided flow would directly propagate into the generated policy without correction. The manuscript should include a dedicated analysis or ablation (e.g., in the experiments section) measuring critic error on actions produced by guided versus unguided sampling and showing that guidance remains beneficial even under realistic critic inaccuracies.
- [Section 4 (Experiments)] The abstract and introduction assert empirical superiority and favorable scaling, yet the provided description contains no quantitative details on experimental setup, number of seeds, statistical significance, or failure cases. Without these, the load-bearing claim that QGF is "competitive with state-of-the-art training-time algorithms while being much cheaper" cannot be assessed. The experiments section must report full protocol, baselines, and variance.
minor comments (2)
- [Section 3.2] Notation for the flow sampling process and the exact form of the gradient guidance step should be made fully explicit with equations, including any step-size or normalization hyperparameters.
- [Section 3] The paper should clarify whether the value function is frozen during test-time guidance or allowed any light adaptation, as this affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that additional analysis on critic behavior and fuller experimental reporting will strengthen the paper, and we will incorporate these changes in the revision.
read point-by-point responses
-
Referee: [Section 3 (Method) and Section 4 (Experiments)] The central claim depends on the pre-trained critic's gradient reliably steering the flow toward higher-value actions at test time. However, in offline RL the critic is trained only on the behavior data distribution; any overestimation on OOD actions reachable by the guided flow would directly propagate into the generated policy without correction. The manuscript should include a dedicated analysis or ablation (e.g., in the experiments section) measuring critic error on actions produced by guided versus unguided sampling and showing that guidance remains beneficial even under realistic critic inaccuracies.
Authors: We agree this is a valid concern for offline RL methods relying on test-time guidance. The current experiments emphasize end-to-end performance, but we will add a dedicated ablation subsection (new Figure or Table in Section 4) that measures critic prediction error and value estimates on actions from guided vs. unguided flow sampling. This will include quantitative comparison of critic inaccuracies and confirmation that guidance yields net benefit under realistic overestimation. revision: yes
-
Referee: [Section 4 (Experiments)] The abstract and introduction assert empirical superiority and favorable scaling, yet the provided description contains no quantitative details on experimental setup, number of seeds, statistical significance, or failure cases. Without these, the load-bearing claim that QGF is "competitive with state-of-the-art training-time algorithms while being much cheaper" cannot be assessed. The experiments section must report full protocol, baselines, and variance.
Authors: We acknowledge that the initial submission omitted some protocol details in the main text. In the revised manuscript we will expand Section 4 with a full experimental protocol subsection: number of random seeds (5-10 per task), statistical significance testing (e.g., Welch t-tests with p-values), complete baseline implementations and hyperparameters, per-task variance (mean ± std), and discussion of any observed failure modes or edge cases. This will make the competitiveness and cost claims fully verifiable. revision: yes
Circularity Check
No circularity: test-time guidance is independent of pre-training fit
full rationale
The paper separates pre-training (standard BC on flow policy plus independent critic) from test-time gradient guidance. No equations or self-citations reduce the claimed performance to a quantity defined by the method itself; the guidance step uses the critic gradient as an external steering signal rather than re-deriving or fitting the same objective. This matches the default non-circular case for a method whose central claim rests on empirical separation of training and inference phases.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A pre-trained value function provides a useful gradient signal for improving actions sampled from a flow policy.
Forward citations
Cited by 1 Pith paper
-
Guided Action Flow: Q-Guided Inference for Flow-Matching Vision-Language-Action Policies
Guided Action Flow applies a rollout-trained critic to steer frozen flow-matching VLA policies at inference time via action gradients, reporting success rate gains on LIBERO manipulation tasks.
Reference graph
Works this paper leans on
-
[1]
Maximum a posteriori policy optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Ried- miller. Maximum a posteriori policy optimisation. InInternational Conference on Learning Representations, 2018
2018
-
[2]
Uncertainty-based offline reinforcement learning with diversified q-ensemble.Advances in neural information processing systems, 34:7436–7447, 2021
Gaon An, Seungyong Moon, Jang-Hyun Kim, and Hyun Oh Song. Uncertainty-based offline reinforcement learning with diversified q-ensemble.Advances in neural information processing systems, 34:7436–7447, 2021
2021
-
[3]
Huayu Chen, Cheng Lu, Chengyang Ying, Hang Su, and Jun Zhu. Offline reinforcement learning via high-fidelity generative behavior modeling.arXiv preprint arXiv:2209.14548, 2022
-
[4]
One-step flow policy mirror descent.arXiv preprint arXiv:2507.23675, 2025
Tianyi Chen, Haitong Ma, Na Li, Kai Wang, and Bo Dai. One-step flow policy mirror descent.arXiv preprint arXiv:2507.23675, 2025
-
[5]
Diffusion policies creating a trust region for offline reinforcement learning.Advances in Neural Information Processing Systems, 37:50098–50125, 2024
Tianyu Chen, Zhendong Wang, and Mingyuan Zhou. Diffusion policies creating a trust region for offline reinforcement learning.Advances in Neural Information Processing Systems, 37:50098–50125, 2024
2024
-
[6]
Feudal reinforcement learning.Advances in neural information processing systems, 5, 1992
Peter Dayan and Geoffrey E Hinton. Feudal reinforcement learning.Advances in neural information processing systems, 5, 1992
1992
-
[7]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[8]
Diffusion-based reinforcement learning via q-weighted variational policy optimization.Advances in Neural Information Processing Systems, 37:53945–53968, 2024
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization.Advances in Neural Information Processing Systems, 37:53945–53968, 2024
2024
-
[9]
Zihan Ding and Chi Jin. Consistency models as a rich and efficient policy class for reinforcement learning. arXiv preprint arXiv:2309.16984, 2023
-
[10]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control, 2025
2025
-
[11]
Nicolas Espinosa-Dice, Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, Gokul Swamy, Kiante Brantley, and Wen Sun. Scaling offline rl via efficient and expressive shortcut models.arXiv preprint arXiv:2505.22866, 2025
-
[12]
Online reward-weighted fine-tuning of flow matching with wasserstein regularization
Jiajun Fan, Shuaike Shen, Chaoran Cheng, Yuxin Chen, Chumeng Liang, and Ge Liu. Online reward-weighted fine-tuning of flow matching with wasserstein regularization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[13]
Linjiajie Fang, Ruoxue Liu, Jing Zhang, Wenjia Wang, and Bing-Yi Jing. Diffusion actor-critic: Formulating constrained policy iteration as diffusion noise regression for offline reinforcement learning.arXiv preprint arXiv:2405.20555, 2024
- [14]
-
[15]
A minimalist approach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021
2021
-
[16]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
2018
-
[17]
Extreme q-learning: Maxent rl without entropy.arXiv preprint arXiv:2301.02328, 2023
Divyansh Garg, Joey Hejna, Matthieu Geist, and Stefano Ermon. Extreme q-learning: Maxent rl without entropy.arXiv preprint arXiv:2301.02328, 2023. 11 Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
-
[18]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. PMLR, 2018
2018
-
[19]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. IDQL: Implicit Q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Longxiang He, Li Shen, Linrui Zhang, Junbo Tan, and Xueqian Wang. Diffcps: Diffusion model based constrained policy search for offline reinforcement learning.arXiv preprint arXiv:2310.05333, 2023
-
[21]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[22]
Adversarial examples are not bugs, they are features.Advances in neural information processing systems, 32, 2019
Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. Adversarial examples are not bugs, they are features.Advances in neural information processing systems, 32, 2019
2019
-
[23]
Decoupled neural interfaces using synthetic gradients
Max Jaderberg, Wojciech Marian Czarnecki, Simon Osindero, Oriol Vinyals, Alex Graves, David Silver, and Koray Kavukcuoglu. Decoupled neural interfaces using synthetic gradients. InInternational conference on machine learning, pages 1627–1635. PMLR, 2017
2017
-
[24]
Q-guided flow q-learning
Yejun Jang, Hong Chul Nam, Jeong Min Park, Gimin Bae, and Hyun Kwon. Q-guided flow q-learning. In CoRL 2025 Workshop RemembeRL
2025
-
[25]
Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36:67195–67212, 2023
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36:67195–67212, 2023
2023
-
[26]
Bahjat Kawar, Roy Ganz, and Michael Elad. Enhancing diffusion-based image synthesis with robust classifier guidance.arXiv preprint arXiv:2208.08664, 2022
-
[27]
Understanding diffusion objectives as the elbo with simple data augmenta- tion
Diederik Kingma and Ruiqi Gao. Understanding diffusion objectives as the elbo with simple data augmenta- tion. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 65484–65516, 2023
2023
-
[28]
Prajwal Koirala and Cody Fleming. Flow-based single-step completion for efficient and expressive policy learning.arXiv preprint arXiv:2506.21427, 2025
-
[29]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit Q-learning. arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Reward-conditioned policies.arXiv preprint arXiv:1912.13465, 2019
Aviral Kumar, Xue Bin Peng, and Sergey Levine. Reward-conditioned policies.arXiv preprint arXiv:1912.13465, 2019
-
[31]
Conservative Q-learning for offline reinforcement learning.Advances in Neural Information Processing Systems, 33:1179–1191, 2020
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-learning for offline reinforcement learning.Advances in Neural Information Processing Systems, 33:1179–1191, 2020
2020
-
[32]
Direct feedback alignment scales to modern deep learning tasks and architectures.Advances in neural information processing systems, 33:9346– 9360, 2020
Julien Launay, Iacopo Poli, François Boniface, and Florent Krzakala. Direct feedback alignment scales to modern deep learning tasks and architectures.Advances in neural information processing systems, 33:9346– 9360, 2020
2020
-
[33]
Q-learning with Adjoint Matching
Qiyang Li and Sergey Levine. Q-learning with adjoint matching.arXiv preprint arXiv:2601.14234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Decoupled q-chunking.arXiv preprint arXiv:2512.10926, 2025
Qiyang Li, Seohong Park, and Sergey Levine. Decoupled q-chunking.arXiv preprint arXiv:2512.10926, 2025
-
[35]
Reinforcement Learning with Action Chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking.arXiv preprint arXiv:2507.07969, 2025. 12 Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Learning multimodal behaviors from scratch with diffusion policy gradient.Advances in Neural Information Processing Systems, 37:38456–38479, 2024
Zechu Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, and Georgia Chalvatzaki. Learning multimodal behaviors from scratch with diffusion policy gradient.Advances in Neural Information Processing Systems, 37:38456–38479, 2024
2024
-
[37]
Random feedback weights support learning in deep neural networks
Timothy P Lillicrap, Daniel Cownden, Douglas B Tweed, and Colin J Akerman. Random feedback weights support learning in deep neural networks.arXiv preprint arXiv:1411.0247, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[38]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[39]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Flow-based policy for online reinforcement learning.arXiv preprint arXiv:2506.12811, 2025
Lei Lv, Yunfei Li, Yu Luo, Fuchun Sun, Tao Kong, Jiafeng Xu, and Xiao Ma. Flow-based policy for online reinforcement learning.arXiv preprint arXiv:2506.12811, 2025
-
[41]
Max Sobol Mark, Tian Gao, Georgia Gabriela Sampaio, Mohan Kumar Srirama, Archit Sharma, Chelsea Finn, and Aviral Kumar. Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone. arXiv preprint arXiv:2412.06685, 2024
-
[42]
Finite Difference Flow Optimization for RL Post-Training of Text-to-Image Models
David McAllister, Miika Aittala, Tero Karras, Janne Hellsten, Angjoo Kanazawa, Timo Aila, and Samuli Laine. Finite difference flow optimization for rl post-training of text-to-image models.arXiv preprint arXiv:2603.12893, 2026
work page internal anchor Pith review arXiv 2026
-
[43]
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
-
[44]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[45]
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. Steering your generalists: Improving robotic foundation models via value guidance.arXiv preprint arXiv:2410.13816, 2024
-
[46]
Direct feedback alignment provides learning in deep neural networks.Advances in neural information processing systems, 29, 2016
Arild Nøkland. Direct feedback alignment provides learning in deep neural networks.Advances in neural information processing systems, 29, 2016
2016
-
[47]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092, 2024
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092, 2024
-
[48]
Is value learning really the main bottleneck in offline rl?Advances in Neural Information Processing Systems, 37:79029–79056, 2024
Seohong Park, Kevin Frans, Sergey Levine, and Aviral Kumar. Is value learning really the main bottleneck in offline rl?Advances in Neural Information Processing Systems, 37:79029–79056, 2024
2024
-
[49]
Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168, 2025
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168, 2025
-
[50]
Flow q-learning.arXiv preprint arXiv:2502.02538,
Seohong Park, Qiyang Li, and Sergey Levine. Flow Q-learning.arXiv preprint arXiv:2502.02538, 2025
-
[51]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[52]
Reinforcement learning for flow-matching policies
Samuel Pfrommer, Yixiao Huang, and Somayeh Sojoudi. Reinforcement learning for flow-matching policies. arXiv preprint arXiv:2507.15073, 2025
-
[53]
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching.arXiv preprint arXiv:2312.11752, 2023. 13 Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
-
[54]
Diffusion Policy Policy Optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Ben- jamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Image synthesis with a single (robust) classifier.Advances in neural information processing systems, 32, 2019
Shibani Santurkar, Andrew Ilyas, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. Image synthesis with a single (robust) classifier.Advances in neural information processing systems, 32, 2019
2019
-
[56]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[58]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[59]
Revisiting the minimalist approach to offline reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[60]
Robustness may be at odds with accuracy.arXiv preprint arXiv:1805.12152, 2018
Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy.arXiv preprint arXiv:1805.12152, 2018
-
[61]
Analysis of temporal-diffference learning with function approximation
John Tsitsiklis and Benjamin Van Roy. Analysis of temporal-diffference learning with function approximation. Advances in neural information processing systems, 9, 1996
1996
-
[62]
Diffusion actor-critic with entropy regulator.Advances in Neural Information Processing Systems, 37:54183–54204, 2024
Yinuo Wang, Likun Wang, Yuxuan Jiang, Wenjun Zou, Tong Liu, Xujie Song, Wenxuan Wang, Liming Xiao, Jiang Wu, Jingliang Duan, et al. Diffusion actor-critic with entropy regulator.Advances in Neural Information Processing Systems, 37:54183–54204, 2024
2024
-
[63]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning.arXiv preprint arXiv:2208.06193, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Behavior Regularized Offline Reinforcement Learning
Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning.arXiv preprint arXiv:1911.11361, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[65]
Reinforcement learning via value gradient flow
Haoran Xu, Kaiwen Hu, Somayeh Sojoudi, and Amy Zhang. Reinforcement learning via value gradient flow. InThe Fourteenth International Conference on Learning Representations
-
[66]
Haoran Xu, Li Jiang, Jianxiong Li, Zhuoran Yang, Zhaoran Wang, Victor Wai Kin Chan, and Xianyuan Zhan. Offline rl with no ood actions: In-sample learning via implicit value regularization.arXiv preprint arXiv:2303.15810, 2023
-
[67]
Shuchen Xue, Chongjian Ge, Shilong Zhang, Yichen Li, and Zhi-Ming Ma. Advantage weighted matching: Aligning rl with pretraining in diffusion models.arXiv preprint arXiv:2509.25050, 2025
-
[68]
Policy representation via diffusion probability model for reinforcement learning
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning. arXiv preprint arXiv:2305.13122, 2023
-
[69]
Entropy-regularized diffusion policy with q-ensembles for offline reinforcement learning.Advances in neural information processing systems, 37:98871–98897, 2024
Ruoqi Zhang, Ziwei Luo, Jens Sjölund, Thomas B Schön, and Per Mattsson. Entropy-regularized diffusion policy with q-ensembles for offline reinforcement learning.Advances in neural information processing systems, 37:98871–98897, 2024
2024
-
[70]
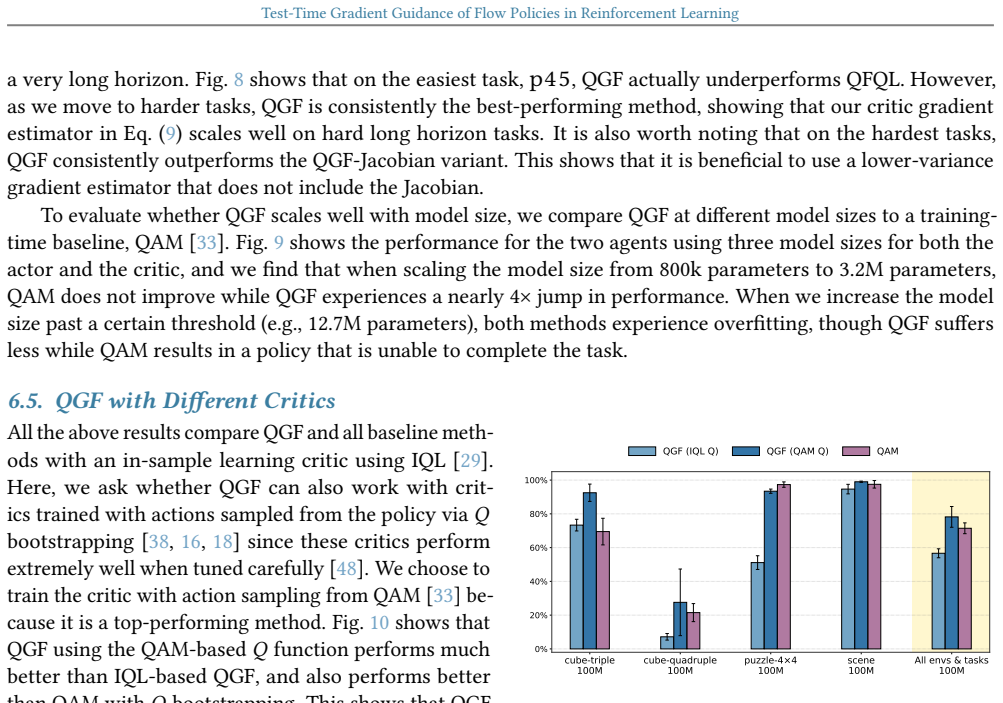
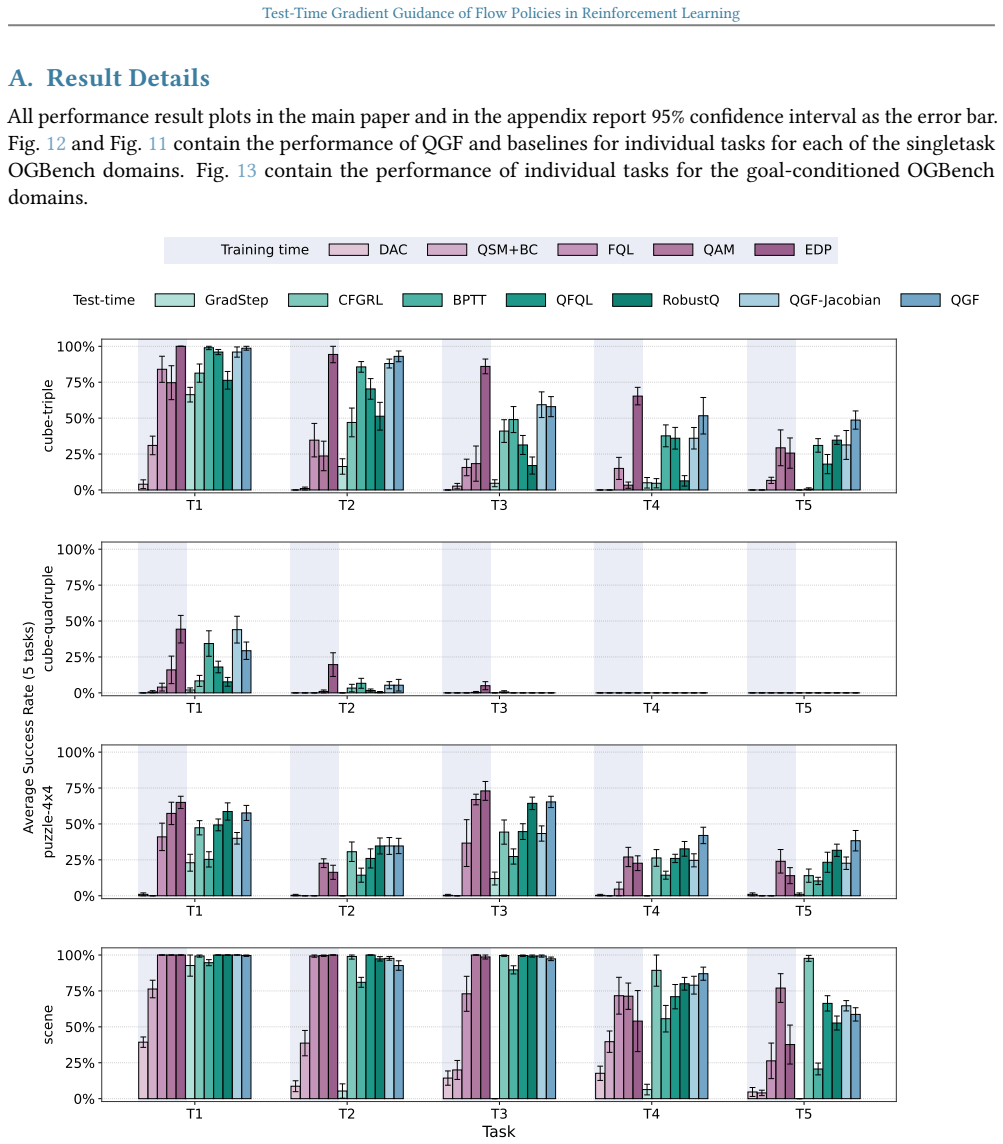
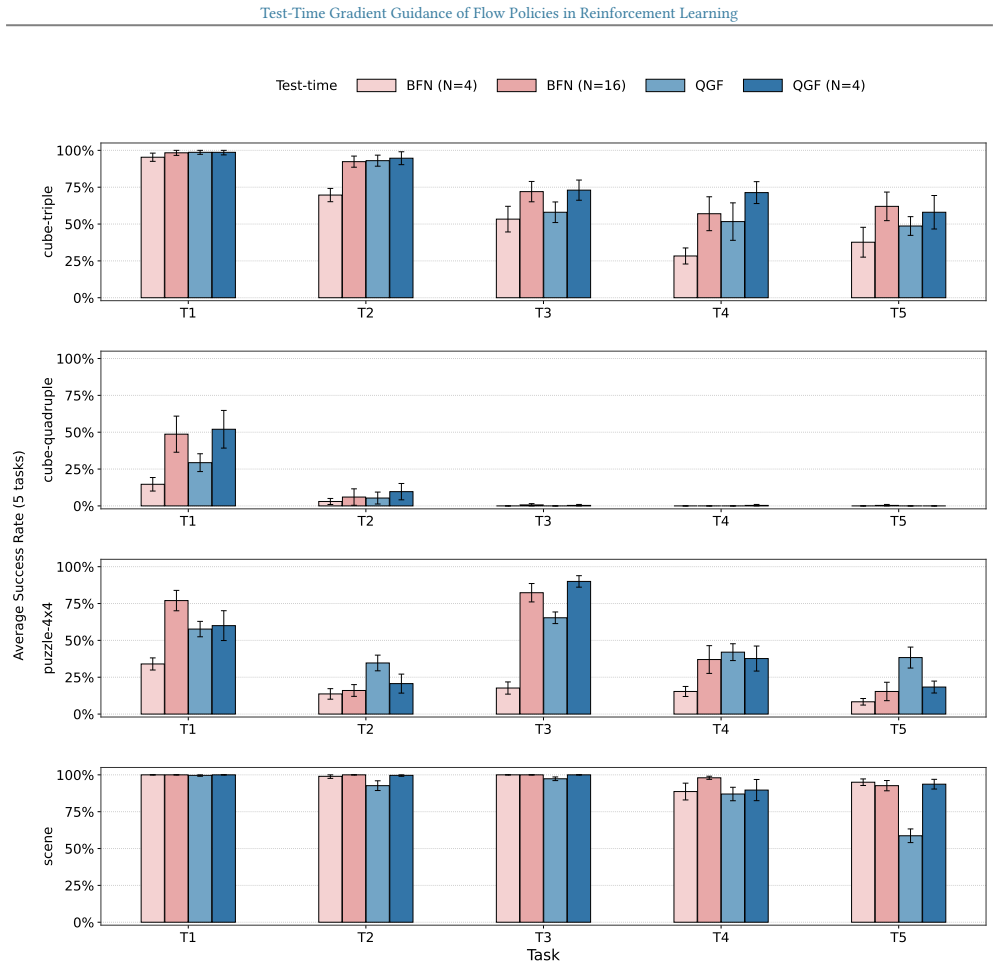
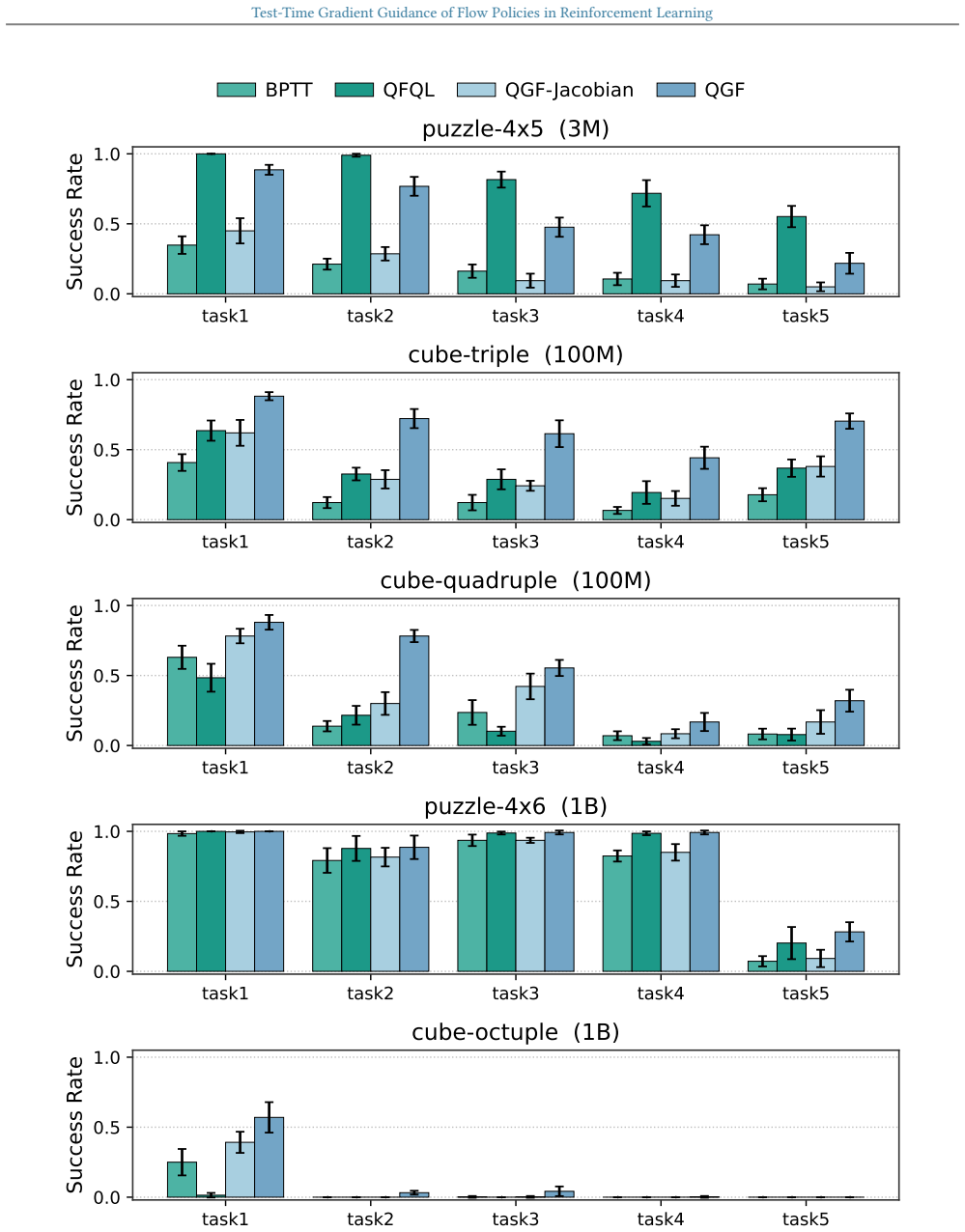
Shiyuan Zhang, Weitong Zhang, and Quanquan Gu. Energy-weighted flow matching for offline reinforce- ment learning.arXiv preprint arXiv:2503.04975, 2025. 14 Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning A. Result Details All performance result plots in the main paper and in the appendix report 95% confidence interval as the error b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.