Quickest Detection of Hallucination Onset: Delay Bounds and Learned CUSUM Statistics
Pith reviewed 2026-06-27 10:34 UTC · model grok-4.3
The pith
A causal recurrent labeler detects hallucination onset after 11-13 tokens by acting as a learned CUSUM, versus 31 tokens for a linear per-token baseline at matched false-alarm rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
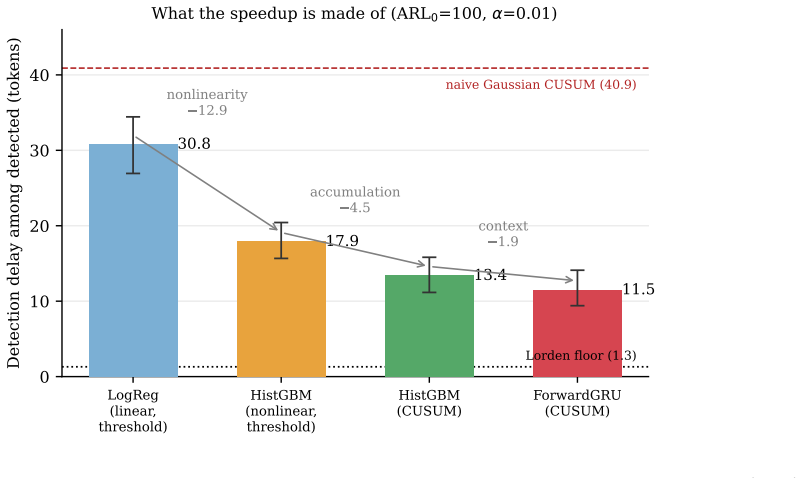
The paper claims that by treating hallucination onset as a change-point problem under a Markov model of the latent state, one can derive delay bounds and interpret a causal recurrent labeler as a CUSUM with learned increment. At matched false-alarm rates, this detector reacts in 11-13 tokens versus 31 for a per-token linear baseline. A controlled decomposition shows the advantage is primarily from a better per-token score. An information-rate optimality theorem of Donsker-Varadhan type shows the learned score realizes only 1/4.5 of the divergence carried by the features.
What carries the argument
Causal recurrent labeler acting as a CUSUM with a learned increment for change-point detection of the latent faithful/hallucinated state.
If this is right
- At a false-alarm rate of 0.01 the theoretical minimum detection delay is about 1.3 tokens under the Markov model.
- The recurrent detector's advantage over the linear baseline is largely attributable to superior per-token scoring rather than temporal accumulation.
- The learned score captures only roughly one-fourth of the divergence available from the features, leaving a gap that recalibration cannot close.
- Classification metrics such as AUC conceal the sequential delay structure that quickest-detection analysis makes measurable.
Where Pith is reading between the lines
- Further gains in per-token scoring could narrow the remaining gap to the theoretical delay bound.
- The same change-point framing could be tested on other streaming token-level tasks such as detecting factual drift or stylistic shifts.
- Finite-horizon effects in the optimality gap imply that performance on longer generations may differ from the reported short-horizon results.
Load-bearing premise
The latent state switches between faithful and hallucinated regimes according to a first-order Markov process.
What would settle it
A new dataset or controlled experiment in which the first-order Markov assumption on the latent state is violated while keeping the recurrent labeler fixed would show whether the reported delay bounds and performance attribution hold.
Figures
read the original abstract
Token-level hallucination detectors are evaluated as classifiers, by AUC over all tokens, yet a streaming monitor is judged by its reaction time: the number of tokens that pass between the onset of a hallucination and the alarm. We formulate hallucination onset detection as a quickest change detection problem. A first-order Markov model of the latent faithful/hallucinated state, validated on RAGTruth, places the task inside classical change-point theory and yields Lorden's lower bound on detection delay: about 1.3 tokens at a false-alarm rate of 0.01. We then show that a causal recurrent labeler acts as a CUSUM with a learned increment; at a matched false-alarm rate it detects in 11-13 tokens, against 31 for a linear per-token baseline, and a controlled decomposition attributes most of this advantage to a better per-token score rather than to temporal accumulation. An information-rate optimality theorem of Donsker-Varadhan type explains the remaining order-of-magnitude gap: the learned score realizes only 1/4.5 of the divergence the features carry, a deficit that recalibration cannot remove, with the remainder a finite-horizon effect. Classification metrics conceal this delay structure; sequential analysis makes it measurable
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates hallucination onset detection as a quickest change detection problem under an explicit first-order Markov model of the latent faithful/hallucinated state (validated on RAGTruth). It invokes Lorden's bound to obtain a theoretical delay floor of ~1.3 tokens at false-alarm rate 0.01, shows that a causal recurrent labeler realizes a CUSUM with learned increment and achieves 11-13 token empirical delay (vs. 31 for a linear per-token baseline), decomposes the gain as arising primarily from the per-token score rather than temporal accumulation, and appeals to a Donsker-Varadhan-type information-rate result to attribute the remaining gap to realizing only 1/4.5 of the available divergence plus finite-horizon effects.
Significance. If the Markov model and decomposition hold, the work supplies a principled sequential-analysis lens for streaming hallucination monitors that AUC-based evaluation obscures, together with concrete delay numbers and an optimality-gap diagnosis. The controlled decomposition separating score quality from accumulation and the explicit invocation of classical bounds are positive features that could guide future detector design.
major comments (3)
- [Abstract / validation section] Abstract and the validation paragraph: the first-order Markov assumption is load-bearing for both the Lorden bound of 1.3 tokens and the CUSUM optimality framing, yet the manuscript supplies no quantitative validation statistics (transition-matrix estimates, likelihood-ratio test against higher-order models, residual autocorrelation, or out-of-sample predictive fit on RAGTruth). Without these, it is impossible to assess whether the model is misspecified and whether the cited lower bound applies.
- [optimality theorem paragraph] The Donsker-Varadhan-style optimality theorem invoked to explain the 1/4.5 divergence ratio: the abstract states the learned score realizes only 1/4.5 of the divergence carried by the features, but the derivation, the precise definition of the divergence, and the finite-horizon correction are not visible in the provided text, leaving the claim that recalibration cannot close the gap uncheckable.
- [empirical results paragraph] The controlled decomposition attributing most of the 11-13 vs. 31 token advantage to the per-token score: the abstract asserts this attribution, but without the explicit experimental protocol (how the linear baseline and recurrent labeler are matched on false-alarm rate, the precise definition of the decomposition, or error bars on the delay numbers), the claim that temporal accumulation contributes little cannot be verified.
minor comments (1)
- [Abstract] The abstract states the 1.3-token bound and 11-13 token empirical claim without visible derivations, dataset splits, or confidence intervals; these numbers should be accompanied by the relevant equations or tables in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional detail will strengthen the manuscript. We address each major comment below and will incorporate the requested clarifications and supporting statistics in the revision.
read point-by-point responses
-
Referee: [Abstract / validation section] Abstract and the validation paragraph: the first-order Markov assumption is load-bearing for both the Lorden bound of 1.3 tokens and the CUSUM optimality framing, yet the manuscript supplies no quantitative validation statistics (transition-matrix estimates, likelihood-ratio test against higher-order models, residual autocorrelation, or out-of-sample predictive fit on RAGTruth). Without these, it is impossible to assess whether the model is misspecified and whether the cited lower bound applies.
Authors: We agree that quantitative validation statistics are required to substantiate the first-order Markov model. The current text states that the model is validated on RAGTruth but does not report the specific estimates or tests. In revision we will add the estimated transition matrix, likelihood-ratio tests against second-order alternatives, residual autocorrelation plots, and out-of-sample predictive log-likelihood on held-out RAGTruth sequences. This will allow direct assessment of model adequacy and applicability of Lorden's bound. revision: yes
-
Referee: [optimality theorem paragraph] The Donsker-Varadhan-style optimality theorem invoked to explain the 1/4.5 divergence ratio: the abstract states the learned score realizes only 1/4.5 of the divergence carried by the features, but the derivation, the precise definition of the divergence, and the finite-horizon correction are not visible in the provided text, leaving the claim that recalibration cannot close the gap uncheckable.
Authors: The full statement and proof of the information-rate result appear in Section 4 and the supplementary material. The divergence is the Donsker-Varadhan variational representation of the KL rate between the pre- and post-change measures. We will move a concise theorem statement, the exact definition of the realized divergence, and the finite-horizon correction argument into the main text so that the 1/4.5 factor and the claim that recalibration cannot close the gap are directly verifiable. revision: yes
-
Referee: [empirical results paragraph] The controlled decomposition attributing most of the 11-13 vs. 31 token advantage to the per-token score: the abstract asserts this attribution, but without the explicit experimental protocol (how the linear baseline and recurrent labeler are matched on false-alarm rate, the precise definition of the decomposition, or error bars on the delay numbers), the claim that temporal accumulation contributes little cannot be verified.
Authors: We accept that the experimental protocol must be stated explicitly. Thresholds for both detectors are set to achieve an empirical false-alarm rate of 0.01 on the validation stream; the decomposition compares the full recurrent CUSUM against an ablated version that uses the same per-token scores but resets the accumulator at every token. We will add a dedicated experimental subsection describing the matching procedure, the precise definition of the score-versus-accumulation split, and report mean delay with standard errors across five random seeds. revision: yes
Circularity Check
No circularity: derivation relies on external classical theory and direct empirical measurement
full rationale
The paper assumes a first-order Markov model of the latent state (validated on RAGTruth) to embed the task in classical quickest-detection theory and obtain Lorden's bound; it then empirically shows a recurrent labeler realizes a CUSUM statistic with learned increment, measures detection delays on data, and invokes an external Donsker-Varadhan-type theorem to interpret the observed gap. None of these steps reduce by construction to the paper's own fitted values or self-citations; the 11-13 token delay and 1/4.5 divergence ratio are reported as measured quantities, the bound follows from the stated model plus standard results, and no load-bearing premise collapses to a renaming or ansatz imported from the authors' prior work.
Axiom & Free-Parameter Ledger
free parameters (1)
- false-alarm rate
axioms (1)
- domain assumption first-order Markov model of the latent faithful/hallucinated state
Forward citations
Cited by 1 Pith paper
-
Delayed Verification Destabilizes Multi-Agent LLM Belief: Instability Thresholds and Optimal Corrector Placement
Models delayed verification in multi-agent LLMs as graph consensus, derives stability thresholds (inverse golden ratio for delay two) via grounded Laplacian, and gives a supermodular greedy rule for corrector placemen...
Reference graph
Works this paper leans on
-
[1]
G. Aytug Akarlar. Hallucination as trajectory commitment: Causal evidence for asymmetric attractor dynamics in transformer generation.arXiv preprint arXiv:2604.15400, 2026
Pith/arXiv arXiv 2026
-
[2]
Tyler Alvarez and Ali Baheri. Where does reasoning break? step-level hallucination detection via hidden-state transport geometry.arXiv preprint arXiv:2605.13772, 2026
Pith/arXiv arXiv 2026
-
[3]
Bishop and Edwin V
Adrian N. Bishop and Edwin V. Bonilla. Recurrent neural networks and universal approximation of bayesian filters. InProceedings of the 26th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 206 ofPMLR, 2023
2023
-
[4]
Ford, Jasmin James, and Timothy L
Jason J. Ford, Jasmin James, and Timothy L. Molloy. Exactly optimal bayesian quickest change detection for hidden markov models.Automatica, 157:111228, 2023
2023
-
[5]
Neural network-based CUSUM for online change-point detection.arXiv preprint arXiv:2210.17312, 2022
Tingnan Gong, Junghwan Lee, Xiuyuan Cheng, and Yao Xie. Neural network-based CUSUM for online change-point detection.arXiv preprint arXiv:2210.17312, 2022
arXiv 2022
-
[6]
Information bounds and quick detection of parameter changes in stochastic systems.IEEE Transactions on Information Theory, 44(7):2917–2929, 1998
Tze Leung Lai. Information bounds and quick detection of parameter changes in stochastic systems.IEEE Transactions on Information Theory, 44(7):2917–2929, 1998
1998
-
[7]
Procedures for reacting to a change in distribution.The Annals of Mathematical Statistics, 42(6):1897–1908, 1971
Gary Lorden. Procedures for reacting to a change in distribution.The Annals of Mathematical Statistics, 42(6):1897–1908, 1971
1908
-
[8]
Moustakides
George V. Moustakides. Optimal stopping times for detecting changes in distributions.The Annals of Statistics, 14(4):1379–1387, 1986
1986
-
[9]
RAGTruth: A hallucination corpus for developing trustworthy retrieval- augmented language models
Cheng Niu et al. RAGTruth: A hallucination corpus for developing trustworthy retrieval- augmented language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024. 13
2024
-
[10]
Oscar Obeso, Andy Arditi, Javier Ferrando, Joshua Freeman, Cameron Holmes, and Neel Nanda. Real-time detection of hallucinated entities in long-form generation.arXiv preprint arXiv:2509.03531, 2025
arXiv 2025
-
[11]
E. S. Page. Continuous inspection schemes.Biometrika, 41(1/2):100–115, 1954
1954
-
[12]
Optimal detection of a change in distribution.The Annals of Statistics, 13(1): 206–227, 1985
Moshe Pollak. Optimal detection of a change in distribution.The Annals of Statistics, 13(1): 206–227, 1985
1985
-
[13]
HALT: Hallucination assessment via log-probs as time series.arXiv preprint arXiv:2602.02888, 2026
Ahmad Shapiro, Karan Taneja, and Ashok Goel. HALT: Hallucination assessment via log-probs as time series.arXiv preprint arXiv:2602.02888, 2026
arXiv 2026
-
[14]
Shiryaev
Albert N. Shiryaev. On optimum methods in quickest detection problems.Theory of Probability & Its Applications, 8(1):22–46, 1963
1963
-
[15]
Springer, 1985
David Siegmund.Sequential Analysis: Tests and Confidence Intervals. Springer, 1985
1985
-
[16]
First hallucination tokens are different from conditional ones.arXiv preprint arXiv:2507.20836, 2025
Snel et al. First hallucination tokens are different from conditional ones.arXiv preprint arXiv:2507.20836, 2025
arXiv 2025
-
[17]
Veeravalli
Liyan Xie, Shaofeng Zou, Yao Xie, and Venugopal V. Veeravalli. Sequential (quickest) change detection: Classical results and new directions.IEEE Journal on Selected Areas in Information Theory, 2(2):494–514, 2021
2021
-
[18]
Yao Xie. Sequential statistical inference for large language models: Representation, validity, and monitoring.arXiv preprint arXiv:2606.07624, 2026. 14
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.