Reclaim Evaluation: A Lossy Memory Is Worse Than an Empty One
Pith reviewed 2026-06-30 10:18 UTC · model grok-4.3
The pith
A lossy memory in language models leads to confident wrong answers where an empty memory would cause abstention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
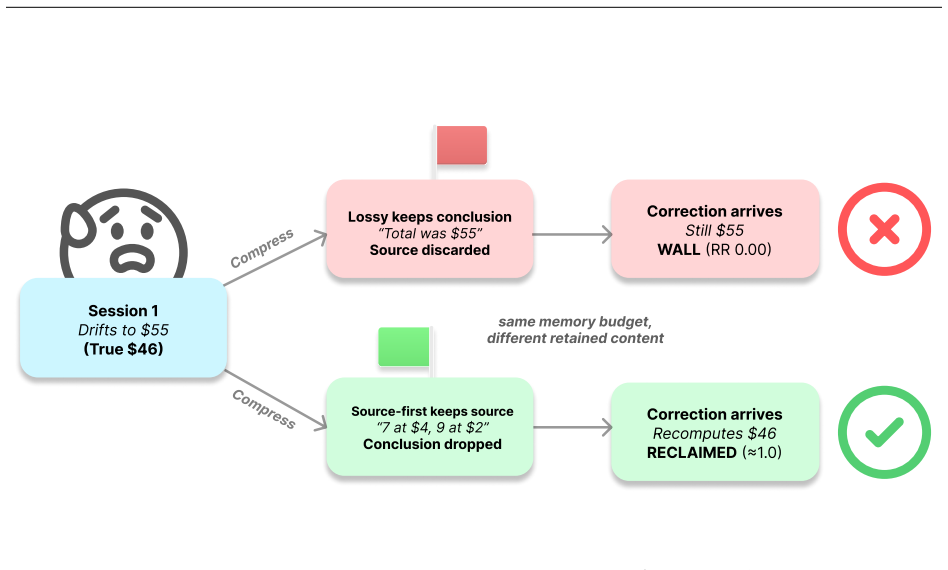
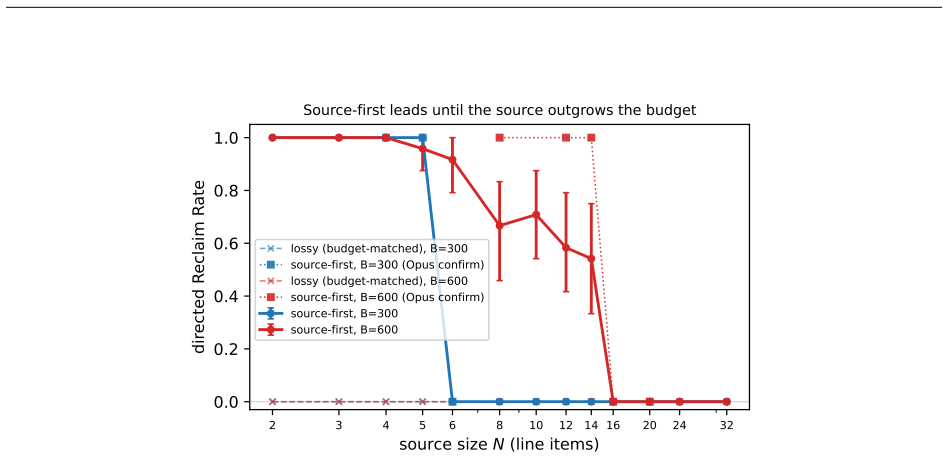
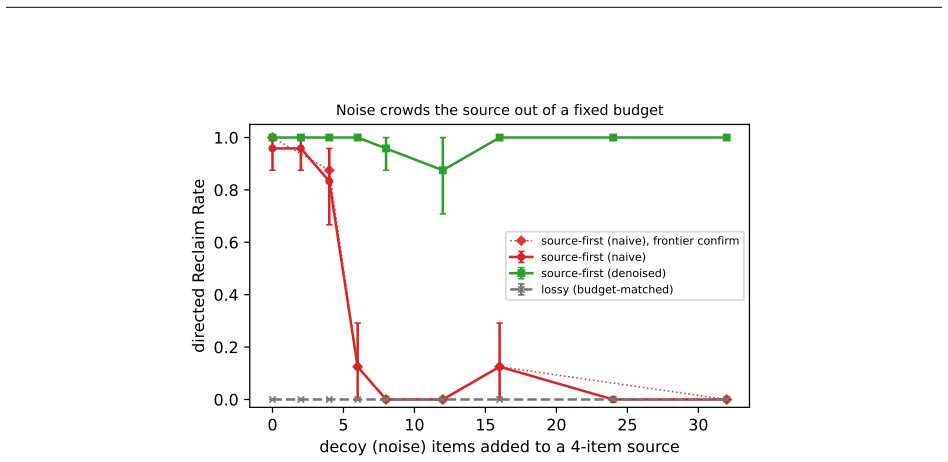
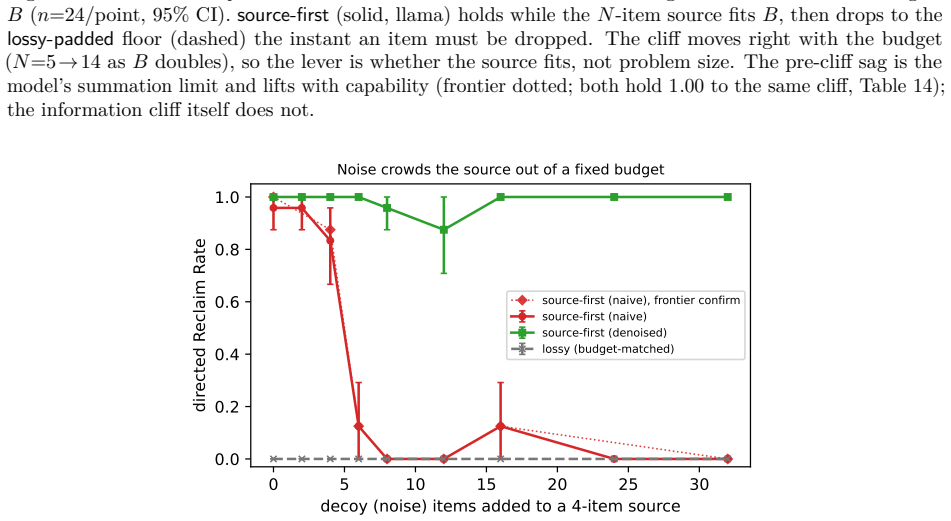
A language model's memory can be worse than no memory at all. A memory that keeps a wrong conclusion but drops the work behind it makes the model emit the stale value as a confident answer, where an empty memory would make it abstain; we call this brittle memory. We measure it with reclaim evaluation: compress a drifted interaction at a fixed budget, then test whether a correction recovers the known answer, scored against ground truth with no judge. Correctability is bottlenecked not by capability but by whether the answer-determining source survives compression, so an 8B model and a frontier one wall in the same place. A one-line source-first policy, keep the recomputable source and drop th
What carries the argument
reclaim evaluation, which compresses drifted interactions at fixed budget and checks recovery of known answers after correction to isolate brittle memory
If this is right
- Lossy memory is never better than empty memory and strictly worse on models disposed to answer rather than abstain.
- Source-first policy reclaims 0.49-0.88 correctability, rising toward the oracle's 1.00 when a frontier model writes the note.
- The failure compounds through a memory loop.
- The pattern replicates on three deployed memory systems and on real dialogue such as MultiWOZ.
- A length-matched control rules out added text and a deployable one-prompt form works.
Where Pith is reading between the lines
- Conversational systems may need explicit source tracking to prevent error compounding over multiple turns.
- Similar source-preservation rules could apply to other stateful AI components that compress history.
- Testing the boundary where notes must record their own completeness could identify safe deployment limits.
- Judge-free exact scoring on paired conditions offers a template for evaluating other memory mechanisms.
Load-bearing premise
The assumption that the answer-determining source is compact and identifiable so that a source-first policy can restore correctability at equal budget.
What would settle it
A case in which lossy memory that retains wrong conclusions recovers the known answer after correction at a higher rate than empty memory on a model that tends to answer rather than abstain.
Figures
read the original abstract
A language model's memory can be worse than no memory at all. A memory that keeps a wrong conclusion but drops the work behind it makes the model emit the stale value as a confident answer, where an empty memory would make it abstain; we call this brittle memory. We measure it with reclaim evaluation: compress a drifted interaction at a fixed budget, then test whether a correction recovers the known answer, scored against ground truth with no judge. Correctability is bottlenecked not by capability but by whether the answer-determining source survives compression, so an 8B model and a frontier one wall in the same place. Across eight models a lossy memory is never better than an empty one, and strictly worse on those disposed to answer rather than abstain. A one-line source-first policy, keep the recomputable source and drop the re-derivable conclusion, restores correctability at equal budget where the answer-determining source is compact and identifiable; a length-matched control rules out added text, and a deployable one-prompt form reclaims 0.49-0.88, rising toward the oracle's 1.00 when a frontier model writes the note. The failure compounds through a memory loop and replicates on three deployed memory systems and on real dialogue (MultiWOZ), with a located boundary past which the fix fails silently unless the note records its completeness. This is a controlled study of a mechanism: judge-free exact scoring, matched-budget controls, and validators built to come out false; we release the harness, the paired memory conditions, and these validators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that lossy memory in language models can be strictly worse than no memory because it retains incorrect conclusions while dropping supporting work, causing confident but wrong answers where an empty memory would lead to abstention. It introduces 'reclaim evaluation,' which compresses drifted interactions at fixed budget and measures whether a correction recovers the known ground-truth answer (judge-free exact scoring). Across eight models, lossy memory is never better than empty and is strictly worse for models disposed to answer rather than abstain. A one-line source-first policy (keep recomputable source, drop re-derivable conclusion) restores correctability (0.49-0.88, approaching oracle 1.00) at equal budget where the answer-determining source is compact and identifiable; this is validated with length-matched controls, a one-prompt deployable form, replication on three deployed memory systems and MultiWOZ dialogue, and a noted boundary where the fix fails unless completeness is recorded. The study emphasizes controlled design, released harness/artifacts/validators, and that correctability is limited by source survival rather than model scale.
Significance. If the results hold, the work identifies a concrete mechanism by which memory can degrade performance below the no-memory baseline, with direct implications for memory architectures in conversational and agentic systems. Strengths include the judge-free exact-match scoring against external ground truth, matched-budget controls that rule out length artifacts, released harness and paired conditions, and the observation that an 8B model and frontier model are bottlenecked at the same point by source survival. The replication on deployed systems and real dialogue adds practical relevance. The conditional nature of the source-first policy (compact/identifiable sources) limits the generality of the constructive claim but does not undermine the core empirical finding on lossy vs. empty memory.
major comments (1)
- [Abstract] Abstract: the claim that the source-first policy 'restores correctability at equal budget' is explicitly qualified by the precondition 'where the answer-determining source is compact and identifiable,' yet the experiments (controlled study, MultiWOZ) appear to operate only in regimes where sources are already short and isolatable; the matched-budget control therefore does not demonstrate that the policy works when this precondition is absent, which is load-bearing for the reported 0.49-0.88 reclamation numbers and the 'one-line' policy's advertised advantage.
minor comments (1)
- [Abstract] Abstract: the phrase 'a located boundary past which the fix fails silently unless the note records its completeness' is introduced without a precise definition or measurement protocol; adding a short operational definition or pointer to the relevant section would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the source-first policy 'restores correctability at equal budget' is explicitly qualified by the precondition 'where the answer-determining source is compact and identifiable,' yet the experiments (controlled study, MultiWOZ) appear to operate only in regimes where sources are already short and isolatable; the matched-budget control therefore does not demonstrate that the policy works when this precondition is absent, which is load-bearing for the reported 0.49-0.88 reclamation numbers and the 'one-line' policy's advertised advantage.
Authors: The abstract and body text explicitly qualify the source-first policy with the precondition that the answer-determining source is compact and identifiable; we do not claim the policy works when this precondition is absent. The controlled study and MultiWOZ experiments are conducted precisely in regimes satisfying the precondition, which are the settings in which the policy is intended to apply. The matched-budget controls therefore demonstrate the policy's effect under the stated conditions, and the 0.49-0.88 reclamation figures are reported only for those regimes. The paper already notes boundary conditions where the fix fails unless completeness is recorded. We stand by the qualified claim and do not interpret the referee's observation as requiring removal of the qualification or expansion of the tested regimes. revision: no
Circularity Check
No significant circularity; empirical claims grounded in external benchmarks and released controls
full rationale
The paper presents an empirical study using judge-free exact scoring against ground truth, matched-budget controls, and a released harness across eight models. No derivation chain, equations, or load-bearing claims reduce by construction to self-definitions, fitted inputs renamed as predictions, or self-citation. The source-first policy is introduced as a one-line heuristic and tested under explicitly stated conditions (compact identifiable sources), with failure boundaries noted; these are not tautological. Central results (lossy memory never better than empty) are falsifiable via the released validators and do not rely on internal redefinitions. This is self-contained against external benchmarks, consistent with the default non-circular outcome for controlled empirical work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Manufactured Confidence: How Memory Consolidation Turns Hearsay into Confident Facts
LLM memory consolidation turns casual hedged statements into confident facts that agents obey regardless of source or verification.
Reference graph
Works this paper leans on
-
[1]
Claude Opus 4.8.https://www.anthropic.com/news/claude-opus-4-8, 2026a
Anthropic. Claude Opus 4.8.https://www.anthropic.com/news/claude-opus-4-8, 2026a. Model announce- ment. Anthropic. Claude Sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6, 2026b. Model announcement. Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašić. MultiWOZ – a large-scale mul...
2018
-
[2]
Adapting language models to compress contexts
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2023
-
[3]
When Context Flips, Safety Breaks: Diagnosing Brittle Safety in Aligned Language Models
Dasol Choi and Alex Kwon. When context flips, safety breaks: Diagnosing brittle safety in aligned language models.arXiv preprint arXiv:2605.27851,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Lei Huang, Weijiang Yu, Weitao Ma, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.arXiv preprint arXiv:2311.05232,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LLMLingua: Compressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LLMLingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2023
-
[6]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
LLMs Get Lost In Multi-Turn Conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. LLMs get lost in multi-turn conversation. arXiv preprint arXiv:2505.06120,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
MemGPT: Towards LLMs as Operating Systems
Model card. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
C-Pack: Packed Resources For General Chinese Embeddings
Model card. Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-Pack: Packed resources for general Chinese embeddings.arXiv preprint arXiv:2309.07597,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Editing large language models: Problems, methods, and opportunities
Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. Editing large language models: Problems, methods, and opportunities. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2023
-
[11]
AgentTuning: Enabling generalized agent abilities for LLMs.arXiv preprint arXiv:2310.12823,
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. AgentTuning: Enabling generalized agent abilities for LLMs.arXiv preprint arXiv:2310.12823,
-
[12]
worse than empty
and explicitlynotan absolute coverage figure: the two labelers bracket the compact share rather than pinning it. The agreement is two LLMs labeling the same text, not a human gold standard. Human spot-check (extra verification).Because both labelers are LLMs, we add a human anchor. The first author labeled a stratified51-conversation slice (17per domain)b...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.