Retrieval-Augmented Generation for Large Language Models: A Survey
Pith reviewed 2026-05-24 05:08 UTC · model grok-4.3
The pith
Retrieval-Augmented Generation merges external databases with large language models to cut hallucinations and keep knowledge current.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
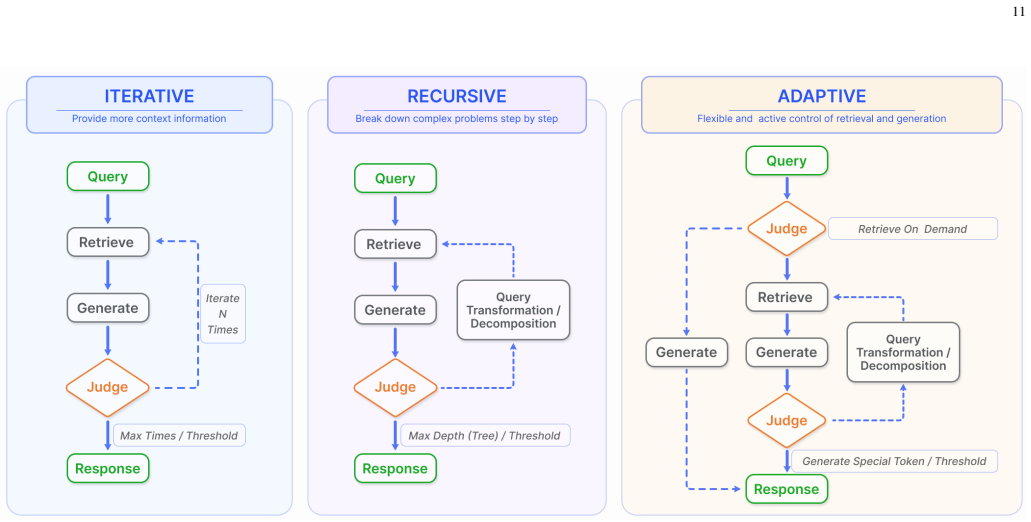
RAG synergistically merges LLMs' intrinsic knowledge with the vast, dynamic repositories of external databases. This comprehensive review examines the progression of RAG paradigms encompassing the Naive RAG, the Advanced RAG, and the Modular RAG. It scrutinizes the tripartite foundation of RAG frameworks which includes the retrieval, the generation and the augmentation techniques and highlights the state-of-the-art technologies in each component. The paper also introduces an up-to-date evaluation framework and benchmark while delineating current challenges and prospective research avenues.
What carries the argument
The tripartite categorization of RAG into Naive RAG, Advanced RAG, and Modular RAG together with the division of each system into retrieval, generation, and augmentation components.
If this is right
- RAG improves accuracy and credibility of outputs on knowledge-intensive tasks.
- RAG supports continuous knowledge updates without retraining the underlying model.
- RAG enables straightforward addition of domain-specific information.
- The introduced evaluation framework and benchmarks allow systematic comparison of different RAG implementations.
Where Pith is reading between the lines
- The three-paradigm map could serve as a checklist for engineers choosing which RAG variant to deploy for a given task.
- Documented challenges may prompt hybrid systems that combine elements from more than one paradigm.
- Widespread use of the survey's structure would make it easier to track which component improvements actually move performance.
Load-bearing premise
The chosen division of all RAG work into Naive, Advanced, and Modular paradigms plus the split into retrieval, generation, and augmentation components forms a complete and non-overlapping framework.
What would settle it
Publication of a new RAG system that cannot be placed in any of the three paradigms or that requires a fourth component outside retrieval, generation, and augmentation.
Figures





read the original abstract
Large Language Models (LLMs) showcase impressive capabilities but encounter challenges like hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases. This enhances the accuracy and credibility of the generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. RAG synergistically merges LLMs' intrinsic knowledge with the vast, dynamic repositories of external databases. This comprehensive review paper offers a detailed examination of the progression of RAG paradigms, encompassing the Naive RAG, the Advanced RAG, and the Modular RAG. It meticulously scrutinizes the tripartite foundation of RAG frameworks, which includes the retrieval, the generation and the augmentation techniques. The paper highlights the state-of-the-art technologies embedded in each of these critical components, providing a profound understanding of the advancements in RAG systems. Furthermore, this paper introduces up-to-date evaluation framework and benchmark. At the end, this article delineates the challenges currently faced and points out prospective avenues for research and development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey paper reviews Retrieval-Augmented Generation (RAG) methods for Large Language Models, organizing the literature into three paradigms (Naive RAG, Advanced RAG, Modular RAG) and dissecting the core components of retrieval, generation, and augmentation. It additionally surveys evaluation frameworks and benchmarks, identifies current challenges, and outlines future research directions.
Significance. If the proposed taxonomy functions as a useful organizing lens rather than a claimed exhaustive partition, the survey could help researchers map the RAG literature by highlighting component-level advances and evaluation practices. The absence of original derivations or empirical claims means its value rests on the clarity and coverage of the organizational framework.
minor comments (2)
- Abstract: the phrasing 'the retrieval, the generation and the augmentation techniques' is awkward and should be revised to 'retrieval, generation, and augmentation techniques' for readability.
- Abstract: the sentence 'RAG synergistically merges LLMs' intrinsic knowledge with the vast, dynamic repositories of external databases' repeats ideas already stated in the preceding sentences; consider condensing.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript and for recommending minor revision. The assessment that the taxonomy can serve as a useful organizing lens aligns with our intent.
Circularity Check
No circularity: descriptive survey with no derivations
full rationale
This paper is a literature survey whose contribution is an organizational taxonomy (Naive/Advanced/Modular RAG plus retrieval/generation/augmentation split) and a review of prior work. No equations, derivations, fitted parameters, or load-bearing self-citations appear in the abstract or described structure. The framework is explicitly presented as a lens for examining existing publications rather than a result derived from data or prior claims within the paper itself. Therefore the derivation chain is empty and the circularity score is 0.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 60 Pith papers
-
Knowledge Poisoning Attacks on Medical Multi-Modal Retrieval-Augmented Generation
M³Att poisons medical multimodal RAG by pairing covert textual misinformation with query-agnostic visual perturbations that increase retrieval of the bad content, causing LLMs to generate clinically plausible but inco...
-
Trojan Hippo: Weaponizing Agent Memory for Data Exfiltration
Trojan Hippo attacks on LLM agent memory achieve 85-100% success rates in data exfiltration across four memory backends even after 100 benign sessions, while evaluated defenses reduce success rates but impose varying ...
-
Hackers or Hallucinators? A Comprehensive Analysis of LLM-Based Automated Penetration Testing
The first SoK on LLM-based AutoPT frameworks provides a six-dimension taxonomy of agent designs and a unified empirical benchmark evaluating 15 frameworks via over 10 billion tokens and 1,500 manually reviewed logs.
-
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
AgentClinic is a multimodal agent benchmark demonstrating that LLM diagnostic accuracy on MedQA drops to below one-tenth in sequential clinical simulations, with Claude-3.5 leading and large tool-use differences acros...
-
UniPPTBench: A Unified Benchmark for Presentation Generation Across Diverse Input Settings
The paper presents UniPPTBench and UniPPTEval, a unified benchmark and scenario-aware evaluation framework for presentation generation from vague prompts, long documents, multimodal documents, and multi-source inputs.
-
Utility-Oriented Visual Evidence Selection for Multimodal Retrieval-Augmented Generation
Evidence utility is defined as information gain on the model's output distribution, with ranking by gain on a latent helpfulness variable shown equivalent to answer-space utility under mild assumptions, enabling a tra...
-
A Hybrid Framework for Natural Language Querying of IFC Models with Relational and Graph Representations
IfcLLM combines relational and graph representations of IFC models with iterative LLM reasoning to deliver 93.3-100% first-attempt accuracy on natural language queries across three test models.
-
Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
PyRAG turns multi-hop reasoning into executable Python code over retrieval tools for explicit, verifiable step-by-step RAG.
-
DeepRefine: Agent-Compiled Knowledge Refinement via Reinforcement Learning
DeepRefine refines agent-compiled knowledge bases via multi-turn abductive diagnosis and RL training with a GBD reward, yielding consistent downstream task gains.
-
EquiMem: Calibrating Shared Memory in Multi-Agent Debate via Game-Theoretic Equilibrium
EquiMem calibrates shared memory in multi-agent debate by computing a game-theoretic equilibrium from agent queries and paths, outperforming heuristics and LLM validators across benchmarks while remaining robust to ad...
-
SEM-RAG: Structure-Preserving Multimodal Graph Compilation and Entropy-Guided Retrieval for Telecommunication Standards
SEM-RAG compiles telecommunication standards into structure-preserving graphs and uses entropy-guided retrieval to reach 94.1% accuracy on TeleQnA and 93.8% on ORAN-Bench-13K while reducing indexing token usage compar...
-
MANTRA: Synthesizing SMT-Validated Compliance Benchmarks for Tool-Using LLM Agents
MANTRA automatically synthesizes SMT-validated compliance benchmarks for LLM agents from natural language manuals and tool schemas, producing 285 tasks across 6 domains with minimal human effort.
-
LatentRAG: Latent Reasoning and Retrieval for Efficient Agentic RAG
LatentRAG performs agentic RAG by generating latent tokens for thoughts and subqueries in one forward pass, matching explicit methods' accuracy on seven benchmarks while reducing latency by ~90%.
-
Stateful Agent Backdoor
A stateful backdoor for LLM agents, modeled as a Mealy machine with a decomposition framework, enables incremental malicious actions across sessions and achieves 80-95% attack success rate on four models.
-
Privacy Without Losing Place: A Paradigm for Private Retrieval in Spatial RAGs
PAS encodes locations via relative anchors and bins to deliver roughly 370-400m adversarial error in spatial RAG while retaining over half the baseline retrieval performance and keeping generation quality robust.
-
Telegraph English: Semantic Prompt Compression via Structured Symbolic Rewriting
Telegraph English compresses prompts via structured symbolic rewriting into atomic facts, achieving roughly 50% token reduction with 99.1% key-fact accuracy on LongBench-v2 and outperforming token-deletion baselines a...
-
E-MIA: Exam-Style Black-Box Membership Inference Attacks against RAG Systems
E-MIA converts document details into four types of exam questions and aggregates the RAG's answers into a membership score that separates member and non-member documents better than prior similarity-based or probe-bas...
-
ReLay: Personalized LLM-Generated Plain-Language Summaries for Better Understanding, but at What Cost?
Personalized LLM-generated plain language summaries improve lay readers' comprehension and quality ratings but increase risks of reinforcing biases and introducing hallucinations compared to static expert summaries.
-
TADI: Tool-Augmented Drilling Intelligence via Agentic LLM Orchestration over Heterogeneous Wellsite Data
TADI shows that domain-specialized tools orchestrated by an LLM over dual structured and semantic databases can convert heterogeneous wellsite data into evidence-grounded drilling intelligence, with tool design matter...
-
When to Retrieve During Reasoning: Adaptive Retrieval for Large Reasoning Models
ReaLM-Retrieve uses step-level uncertainty to trigger retrievals during reasoning, achieving 10.1% better F1 scores and 47% fewer calls on multi-hop QA benchmarks.
-
RepoDoc: A Knowledge Graph-Based Framework to Automatic Documentation Generation and Incremental Updates
RepoDoc uses a repository knowledge graph with module clustering and semantic impact propagation to generate more complete documentation 3x faster with 85% fewer tokens and handle incremental updates 73% faster than p...
-
Context-Augmented Code Generation: How Product Context Improves AI Coding Agent Decision Compliance by 49%
Adding product context retrieval to AI coding agents raises decision compliance from 46% to 95% on a new benchmark of 8 tasks with 41 weighted decision points.
-
XGRAG: A Graph-Native Framework for Explaining KG-based Retrieval-Augmented Generation
XGRAG uses graph perturbations to quantify component contributions in GraphRAG and achieves 14.81% better explanation quality than text-based baselines on QA datasets, with correlations to graph centrality.
-
Similar Users-Augmented Interest Network
SUIN improves CTR prediction by augmenting target user sequences with similar users' behaviors via embedding-based retrieval, user-specific position encoding, and user-aware target attention.
-
Uncertainty Propagation in LLM-Based Systems
This paper introduces a systems-level conceptual framing and a three-level taxonomy (intra-model, system-level, socio-technical) for uncertainty propagation in compound LLM applications, along with engineering insight...
-
A Systematic Survey of Security Threats and Defenses in LLM-Based AI Agents: A Layered Attack Surface Framework
A new 7x4 taxonomy organizes agentic AI security threats by architectural layer and persistence timescale, revealing under-explored upper layers and missing defenses after surveying 116 papers.
-
Participatory provenance as representational auditing for AI-mediated public consultation
Participatory provenance auditing of Canada's AI strategy consultation shows official AI summaries exclude 15-17% of participants more than random baselines, with 33-88% exclusion for dissent clusters.
-
Learning When Not to Decide: A Framework for Overcoming Factual Presumptuousness in AI Adjudication
A new structured prompting method (SPEC) helps AI detect insufficient evidence in adjudication tasks and defer decisions appropriately, reaching 89% accuracy on a benchmark varying information completeness from Colora...
-
ArbGraph: Conflict-Aware Evidence Arbitration for Reliable Long-Form Retrieval-Augmented Generation
ArbGraph resolves conflicts in RAG evidence by constructing a conflict-aware graph of atomic claims and applying intensity-driven iterative arbitration to suppress unreliable claims prior to generation.
-
STRIDE: Strategic Iterative Decision-Making for Retrieval-Augmented Multi-Hop Question Answering
STRIDE uses a meta-planner for entity-agnostic reasoning skeletons and a supervisor for dependency-aware execution to improve retrieval-augmented multi-hop QA.
-
Skill-RAG: Failure-State-Aware Retrieval Augmentation via Hidden-State Probing and Skill Routing
Skill-RAG detects retrieval failure states from hidden representations and routes to one of four corrective skills to raise accuracy on persistent hard cases in open-domain QA and reasoning benchmarks.
-
ASTRA: Enhancing Multi-Subject Generation with Retrieval-Augmented Pose Guidance and Disentangled Position Embedding
ASTRA disentangles subject identity from pose structure in diffusion transformers via retrieval-augmented pose guidance, asymmetric EURoPE embeddings, and a DSM adapter to improve multi-subject generation.
-
MM-Doc-R1: Training Agents for Long Document Visual Question Answering through Multi-turn Reinforcement Learning
MM-Doc-R1 combines an agentic workflow with Similarity-based Policy Optimization (SPO) to achieve 10.4% higher performance than prior baselines on long-document visual question answering.
-
Better and Worse with Scale: How Contextual Entrainment Diverges with Model Size
Contextual entrainment decreases for semantic contexts but increases for non-semantic ones as LLMs scale, following power-law trends with 4x better resistance to misinformation but 2x more copying of arbitrary tokens.
-
Exploring Knowledge Conflicts for Faithful LLM Reasoning: Benchmark and Method
ConflictQA benchmark shows LLMs fail to resolve conflicts between text and KG evidence and often default to one source, motivating the XoT explanation-based reasoning method.
-
VISOR: Agentic Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning
VISOR is a unified agentic VRAG framework with Evidence Space structuring, visual action evaluation/correction, and dynamic sliding-window trajectories trained via GRPO-based RL that achieves SOTA performance on long-...
-
Decoupling Vector Data and Index Storage for Space Efficiency
DecoupleVS decouples vector data and index storage in ANNS systems to cut storage space by up to 58.7% with competitive search and update performance.
-
ROZA Graphs: Self-Improving Near-Deterministic RAG through Evidence-Centric Feedback
ROZA graphs enable self-improving RAG by storing evidence-specific reasoning chains, yielding up to 10.6pp accuracy gains and 46% lower cost through graph traversal feedback.
-
An End-to-End Approach for Fixing Concurrency Bugs via SHB-Based Context Extractor
ConFixAgent repairs diverse concurrency bugs end-to-end by using Static Happens-Before graphs to extract relevant code context for LLMs, outperforming prior tools in benchmarks.
-
Can You Trust the Vectors in Your Vector Database? Black-Hole Attack from Embedding Space Defects
Injecting a few malicious vectors near the centroid exploits centrality-driven hubness in high-dimensional embeddings, causing them to dominate top-k retrievals in up to 99.85% of cases.
-
Architecture Without Architects: How AI Coding Agents Shape Software Architecture
AI coding agents perform vibe architecting by making prompt-driven architectural choices that produce structurally different systems for identical tasks.
-
Unified and Efficient Approach for Multi-Vector Similarity Search
MV-HNSW is the first native hierarchical graph index for multi-vector data, achieving over 90% recall with up to 14x lower search latency than prior filter-and-refine approaches across seven datasets.
-
AnnoRetrieve: Efficient Structured Retrieval for Unstructured Document Analysis
AnnoRetrieve uses auto-generated structured schemas and queries to retrieve information from unstructured documents more efficiently and accurately than embedding-based methods.
-
From PDF to RAG-Ready: Evaluating Document Conversion Frameworks for Domain-Specific Question Answering
Docling with hierarchical splitting reaches 94.1% RAG accuracy on domain documents, beating naive PDF loading but trailing manual Markdown curation at 97.1%.
-
PERMA: Benchmarking Personalized Memory Agents via Event-Driven Preference and Realistic Task Environments
PERMA is a new benchmark using temporally ordered events, text variability, and linguistic alignment to evaluate LLM memory agents on persona consistency beyond simple retrieval.
-
GraphScout: Empowering Large Language Models with Intrinsic Exploration Ability for Agentic Graph Reasoning
GraphScout trains LLMs to autonomously synthesize structured training data from knowledge graphs via flexible exploration tools, enabling a 4B model to outperform larger LLMs by 16.7% on average with fewer inference t...
-
PhysMem: Scaling Test-Time Memory for Embodied Physical Reasoning
PhysMem enables VLM-based robot planners to learn and verify physical properties through test-time interaction and hypothesis testing, raising success on a brick insertion task from 23% to 76%.
-
AtomicRAG: Atom-Entity Graphs for Retrieval-Augmented Generation
AtomicRAG replaces chunk-based and triple-based GraphRAG with atom-entity graphs that store facts as atomic units and use personalized PageRank plus relevance filtering to achieve higher retrieval accuracy and reasoni...
-
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
VideoDR is a new benchmark for open-web video deep research that tests multimodal models on cross-frame visual anchor extraction, interactive retrieval, and multi-hop reasoning over joint video-web evidence.
-
In Line with Context: Repository-Level Code Generation via Context Inlining
InlineCoder reframes repository-level code generation as function-level coding by using a draft anchor to inline the target function into its call graph for upstream usage and downstream dependency context.
-
VLegal-Bench: Cognitively Grounded Benchmark for Vietnamese Legal Reasoning of Large Language Models
VLegal-Bench supplies 10,450 expert-validated samples for evaluating LLMs on Vietnamese legal questions, retrieval, multi-step reasoning, and scenario solving.
-
MCP vs RAG vs NLWeb vs HTML: A Comparison of the Effectiveness and Efficiency of Different Agent Interfaces to the Web (Technical Report)
RAG, MCP, and NLWeb interfaces let LLM web agents achieve higher F1 scores (0.75-0.77 vs 0.67) and much lower token usage and runtime than HTML in controlled e-commerce tasks.
-
MIST: A Co-Design Framework for Heterogeneous, Multi-Stage LLM Inference
MIST is a new simulator for heterogeneous multi-stage LLM inference that combines hardware traces with analytical models to explore configuration trade-offs in hybrid CPU-accelerator systems.
-
Ex-GraphRAG: Interpretable Evidence Routing for Graph-Augmented LLMs
Ex-GraphRAG replaces GNN encoders with M-GNAN for exact node-level decomposition in graph-augmented LLMs, matching black-box performance on STaRK-Prime while exposing semantic-structural mismatches that degrade multi-...
-
Memory Grafting: Scaling Language Model Pre-training via Offline Conditional Memory
Memory Grafting improves language-model benchmarks by grafting offline hidden-state memory from a larger model into a recipient model using n-gram lookups and lightweight adapters, outperforming MoE and vanilla Engram...
-
EngiAI: A Multi-Agent Framework and Benchmark Suite for LLM-Driven Engineering Design
EngiAI is a multi-agent framework unifying topology optimization, retrieval, HPC orchestration, and manufacturing control, with benchmarks showing proprietary LLMs at 96-97% task completion on Beams2D and lower perfor...
-
DocOS: Towards Proactive Document-Guided Actions in GUI Agents
Introduces DocOS benchmark to test GUI agents on proactively locating, comprehending, and executing instructions from online documentation in interactive web settings.
-
uGen: An Agentic Framework for Generating Microarchitectural Attack PoCs
uGen is the first retrieval-augmented multi-agent LLM framework for generating functionally correct microarchitectural attack PoCs, reporting up to 100% success on Spectre-v1 and 80% on Prime+Probe at low cost.
-
Jobs' AI Exposure Should Be Measured from Evidence, Not Model Priors
The authors propose a retrieval-augmented framework that grounds AI exposure labels for 18,796 O*NET occupation-task pairs in retrieved news and academic abstracts, outperforming zero-shot prompting in 72% of disagree...
-
Why Retrieval-Augmented Generation Fails: A Graph Perspective
Attribution graphs reveal that RAG failures arise from shallow fragmented evidence flow in LLMs, enabling topology-based detection and targeted interventions that reinforce question-guided routing.
Reference graph
Works this paper leans on
-
[1]
Large language models struggle to learn long-tail knowledge,
N. Kandpal, H. Deng, A. Roberts, E. Wallace, and C. Raffel, “Large language models struggle to learn long-tail knowledge,” in Interna- tional Conference on Machine Learning . PMLR, 2023, pp. 15 696– 15 707
work page 2023
-
[2]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Y . Zhang, Y . Li, L. Cui, D. Cai, L. Liu, T. Fu, X. Huang, E. Zhao, Y . Zhang, Y . Chenet al., “Siren’s song in the ai ocean: A survey on hal- lucination in large language models,” arXiv preprint arXiv:2309.01219, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Gar-meets-rag paradigm for zero-shot information re- trieval,
D. Arora, A. Kini, S. R. Chowdhury, N. Natarajan, G. Sinha, and A. Sharma, “Gar-meets-rag paradigm for zero-shot information re- trieval,” arXiv preprint arXiv:2310.20158 , 2023
-
[4]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschel et al. , “Retrieval- augmented generation for knowledge-intensive nlp tasks,” Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
work page 2020
-
[5]
Improving language models by retrieving from trillions of tokens,
S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Milli- can, G. B. Van Den Driessche, J.-B. Lespiau, B. Damoc, A. Clarket al., “Improving language models by retrieving from trillions of tokens,” in International conference on machine learning . PMLR, 2022, pp. 2206–2240
work page 2022
-
[6]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al. , “Training language models to follow instructions with human feedback,” Advances in neural information processing systems , vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[7]
Query rewrit- ing for retrieval-augmented large language models,
X. Ma, Y . Gong, P. He, H. Zhao, and N. Duan, “Query rewrit- ing for retrieval-augmented large language models,” arXiv preprint arXiv:2305.14283, 2023
-
[8]
Advanced rag techniques: an il- lustrated overview,
I. ILIN, “Advanced rag techniques: an il- lustrated overview,” https://pub.towardsai.net/ advanced-rag-techniques-an-illustrated-overview-04d193d8fec6, 2023
work page 2023
-
[9]
Large language model based long-tail query rewriting in taobao search,
W. Peng, G. Li, Y . Jiang, Z. Wang, D. Ou, X. Zeng, E. Chen et al. , “Large language model based long-tail query rewriting in taobao search,” arXiv preprint arXiv:2311.03758 , 2023
-
[10]
Take a step back: Evoking reasoning via abstraction in large language models,
H. S. Zheng, S. Mishra, X. Chen, H.-T. Cheng, E. H. Chi, Q. V . Le, and D. Zhou, “Take a step back: Evoking reasoning via abstraction in large language models,” arXiv preprint arXiv:2310.06117 , 2023
-
[11]
Precise zero-shot dense retrieval without relevance labels,
L. Gao, X. Ma, J. Lin, and J. Callan, “Precise zero-shot dense retrieval without relevance labels,” arXiv preprint arXiv:2212.10496 , 2022
-
[12]
Enhancing rag pipelines in haystack: Introducing diver- sityranker and lostinthemiddleranker,
V . Blagojevi, “Enhancing rag pipelines in haystack: Introducing diver- sityranker and lostinthemiddleranker,” https://towardsdatascience.com/ enhancing-rag-pipelines-in-haystack-45f14e2bc9f5, 2023
work page 2023
-
[13]
Generate rather than retrieve: Large language models are strong context generators,
W. Yu, D. Iter, S. Wang, Y . Xu, M. Ju, S. Sanyal, C. Zhu, M. Zeng, and M. Jiang, “Generate rather than retrieve: Large language models are strong context generators,” arXiv preprint arXiv:2209.10063, 2022
-
[14]
Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy,
Z. Shao, Y . Gong, Y . Shen, M. Huang, N. Duan, and W. Chen, “Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy,” arXiv preprint arXiv:2305.15294 , 2023
-
[15]
Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases,
X. Wang, Q. Yang, Y . Qiu, J. Liang, Q. He, Z. Gu, Y . Xiao, and W. Wang, “Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases,” arXiv preprint arXiv:2308.11761, 2023
-
[16]
Forget rag, the future is rag-fusion,
A. H. Raudaschl, “Forget rag, the future is rag-fusion,” https://towardsdatascience.com/ forget-rag-the-future-is-rag-fusion-1147298d8ad1, 2023
work page 2023
-
[17]
Lift yourself up: Retrieval-augmented text generation with self memory,
X. Cheng, D. Luo, X. Chen, L. Liu, D. Zhao, and R. Yan, “Lift yourself up: Retrieval-augmented text generation with self memory,” arXiv preprint arXiv:2305.02437 , 2023
-
[18]
S. Wang, Y . Xu, Y . Fang, Y . Liu, S. Sun, R. Xu, C. Zhu, and M. Zeng, “Training data is more valuable than you think: A simple and effective method by retrieving from training data,” arXiv preprint arXiv:2203.08773, 2022
-
[19]
From classification to generation: Insights into crosslingual retrieval augmented icl,
X. Li, E. Nie, and S. Liang, “From classification to generation: Insights into crosslingual retrieval augmented icl,” arXiv preprint arXiv:2311.06595, 2023
-
[20]
Uprise: Universal prompt retrieval for improving zero-shot evaluation,
D. Cheng, S. Huang, J. Bi, Y . Zhan, J. Liu, Y . Wang, H. Sun, F. Wei, D. Deng, and Q. Zhang, “Uprise: Universal prompt retrieval for improving zero-shot evaluation,” arXiv preprint arXiv:2303.08518, 2023
-
[21]
Promptagator: Few-shot dense retrieval from 8 examples,
Z. Dai, V . Y . Zhao, J. Ma, Y . Luan, J. Ni, J. Lu, A. Bakalov, K. Guu, K. B. Hall, and M.-W. Chang, “Promptagator: Few-shot dense retrieval from 8 examples,” arXiv preprint arXiv:2209.11755 , 2022
-
[22]
Recitation-augmented language models,
Z. Sun, X. Wang, Y . Tay, Y . Yang, and D. Zhou, “Recitation-augmented language models,” arXiv preprint arXiv:2210.01296 , 2022
-
[23]
Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive nlp,
O. Khattab, K. Santhanam, X. L. Li, D. Hall, P. Liang, C. Potts, and M. Zaharia, “Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive nlp,” arXiv preprint arXiv:2212.14024, 2022
-
[24]
Active retrieval augmented generation,
Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y . Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” arXiv preprint arXiv:2305.06983 , 2023
-
[25]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
A. Asai, Z. Wu, Y . Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” arXiv preprint arXiv:2310.11511 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Bridging the preference gap between retrievers and llms,
Z. Ke, W. Kong, C. Li, M. Zhang, Q. Mei, and M. Bendersky, “Bridging the preference gap between retrievers and llms,” arXiv preprint arXiv:2401.06954, 2024
-
[27]
Ra-dit: Retrieval- augmented dual instruction tuning,
X. V . Lin, X. Chen, M. Chen, W. Shi, M. Lomeli, R. James, P. Ro- driguez, J. Kahn, G. Szilvasy, M. Lewis et al. , “Ra-dit: Retrieval- augmented dual instruction tuning,” arXiv preprint arXiv:2310.01352 , 2023
-
[28]
Fine-tuning or retrieval? comparing knowledge injection in llms,
O. Ovadia, M. Brief, M. Mishaeli, and O. Elisha, “Fine-tuning or retrieval? comparing knowledge injection in llms,” arXiv preprint arXiv:2312.05934, 2023
-
[29]
T. Lan, D. Cai, Y . Wang, H. Huang, and X.-L. Mao, “Copy is all you need,” in The Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[30]
Dense x retrieval: What retrieval granularity should we use?
T. Chen, H. Wang, S. Chen, W. Yu, K. Ma, X. Zhao, D. Yu, and H. Zhang, “Dense x retrieval: What retrieval granularity should we use?” arXiv preprint arXiv:2312.06648 , 2023
-
[31]
Divide & conquer for entailment-aware multi-hop evidence retrieval,
F. Luo and M. Surdeanu, “Divide & conquer for entailment-aware multi-hop evidence retrieval,” arXiv preprint arXiv:2311.02616 , 2023
-
[32]
Diversify question generation with retrieval-augmented style transfer,
Q. Gou, Z. Xia, B. Yu, H. Yu, F. Huang, Y . Li, and N. Cam-Tu, “Diversify question generation with retrieval-augmented style transfer,” arXiv preprint arXiv:2310.14503 , 2023
-
[33]
Prompt-guided re- trieval augmentation for non-knowledge-intensive tasks,
Z. Guo, S. Cheng, Y . Wang, P. Li, and Y . Liu, “Prompt-guided re- trieval augmentation for non-knowledge-intensive tasks,”arXiv preprint arXiv:2305.17653, 2023
-
[34]
Learning to filter context for retrieval-augmented generation,
Z. Wang, J. Araki, Z. Jiang, M. R. Parvez, and G. Neubig, “Learning to filter context for retrieval-augmented generation,” arXiv preprint arXiv:2311.08377, 2023
-
[35]
Retrieval-augmented data augmentation for low-resource domain tasks,
M. Seo, J. Baek, J. Thorne, and S. J. Hwang, “Retrieval-augmented data augmentation for low-resource domain tasks,” arXiv preprint arXiv:2402.13482, 2024
-
[37]
Retrieval-augmented generative question answering for event argument extraction,
X. Du and H. Ji, “Retrieval-augmented generative question answering for event argument extraction,”arXiv preprint arXiv:2211.07067, 2022
-
[38]
Learning to retrieve in-context examples for large language models,
L. Wang, N. Yang, and F. Wei, “Learning to retrieve in-context examples for large language models,”arXiv preprint arXiv:2307.07164, 2023
-
[39]
Recommender systems with generative retrieval,
S. Rajput, N. Mehta, A. Singh, R. H. Keshavan, T. Vu, L. Heldt, L. Hong, Y . Tay, V . Q. Tran, J. Samostet al., “Recommender systems with generative retrieval,” arXiv preprint arXiv:2305.05065 , 2023
-
[40]
Language models as semantic indexers,
B. Jin, H. Zeng, G. Wang, X. Chen, T. Wei, R. Li, Z. Wang, Z. Li, Y . Li, H. Lu et al. , “Language models as semantic indexers,” arXiv preprint arXiv:2310.07815, 2023
-
[41]
Context tuning for retrieval augmented generation,
R. Anantha, T. Bethi, D. V odianik, and S. Chappidi, “Context tuning for retrieval augmented generation,” arXiv preprint arXiv:2312.05708 , 2023
-
[42]
Atlas: Few-shot Learning with Retrieval Augmented Language Models
G. Izacard, P. Lewis, M. Lomeli, L. Hosseini, F. Petroni, T. Schick, J. Dwivedi-Yu, A. Joulin, S. Riedel, and E. Grave, “Few-shot learning with retrieval augmented language models,” arXiv preprint arXiv:2208.03299, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Raven: In-context learning with retrieval augmented encoder- decoder language models,
J. Huang, W. Ping, P. Xu, M. Shoeybi, K. C.-C. Chang, and B. Catan- zaro, “Raven: In-context learning with retrieval augmented encoder- decoder language models,” arXiv preprint arXiv:2308.07922 , 2023. 18
-
[44]
Shall we pretrain autoregressive language models with retrieval? a comprehensive study,
B. Wang, W. Ping, P. Xu, L. McAfee, Z. Liu, M. Shoeybi, Y . Dong, O. Kuchaiev, B. Li, C. Xiao et al. , “Shall we pretrain autoregressive language models with retrieval? a comprehensive study,”arXiv preprint arXiv:2304.06762, 2023
-
[45]
Instructretro: Instruction tuning post retrieval-augmented pre- training,
B. Wang, W. Ping, L. McAfee, P. Xu, B. Li, M. Shoeybi, and B. Catan- zaro, “Instructretro: Instruction tuning post retrieval-augmented pre- training,” arXiv preprint arXiv:2310.07713 , 2023
-
[46]
S. Siriwardhana, R. Weerasekera, E. Wen, T. Kaluarachchi, R. Rana, and S. Nanayakkara, “Improving the domain adaptation of retrieval augmented generation (rag) models for open domain question answer- ing,” Transactions of the Association for Computational Linguistics , vol. 11, pp. 1–17, 2023
work page 2023
-
[47]
Augmentation-adapted retriever improves generalization of language models as generic plug-in,
Z. Yu, C. Xiong, S. Yu, and Z. Liu, “Augmentation-adapted retriever improves generalization of language models as generic plug-in,” arXiv preprint arXiv:2305.17331, 2023
-
[49]
Understanding re- trieval augmentation for long-form question answering,
H.-T. Chen, F. Xu, S. A. Arora, and E. Choi, “Understanding re- trieval augmentation for long-form question answering,” arXiv preprint arXiv:2310.12150, 2023
-
[50]
Chain-of-note: Enhancing robustness in retrieval-augmented language models,
W. Yu, H. Zhang, X. Pan, K. Ma, H. Wang, and D. Yu, “Chain-of-note: Enhancing robustness in retrieval-augmented language models,” arXiv preprint arXiv:2311.09210, 2023
-
[51]
S. Xu, L. Pang, H. Shen, X. Cheng, and T.-S. Chua, “Search-in-the- chain: Towards accurate, credible and traceable large language models for knowledgeintensive tasks,” CoRR, vol. abs/2304.14732 , 2023
-
[52]
Optimizing retrieval-augmented reader models via token elimination,
M. Berchansky, P. Izsak, A. Caciularu, I. Dagan, and M. Wasserblat, “Optimizing retrieval-augmented reader models via token elimination,” arXiv preprint arXiv:2310.13682 , 2023
-
[53]
Paperqa: Retrieval-augmented generative agent for scientific research,
J. L ´ala, O. O’Donoghue, A. Shtedritski, S. Cox, S. G. Rodriques, and A. D. White, “Paperqa: Retrieval-augmented generative agent for scientific research,” arXiv preprint arXiv:2312.07559 , 2023
-
[54]
The power of noise: Redefining retrieval for rag systems,
F. Cuconasu, G. Trappolini, F. Siciliano, S. Filice, C. Campagnano, Y . Maarek, N. Tonellotto, and F. Silvestri, “The power of noise: Redefining retrieval for rag systems,”arXiv preprint arXiv:2401.14887, 2024
-
[55]
Iag: Induction-augmented generation framework for answer- ing reasoning questions,
Z. Zhang, X. Zhang, Y . Ren, S. Shi, M. Han, Y . Wu, R. Lai, and Z. Cao, “Iag: Induction-augmented generation framework for answer- ing reasoning questions,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , 2023, pp. 1–14
work page 2023
-
[56]
Nomiracl: Knowing when you don’t know for robust multilingual retrieval-augmented generation,
N. Thakur, L. Bonifacio, X. Zhang, O. Ogundepo, E. Kamalloo, D. Alfonso-Hermelo, X. Li, Q. Liu, B. Chen, M. Rezagholizadeh et al., “Nomiracl: Knowing when you don’t know for robust multilingual retrieval-augmented generation,” arXiv preprint arXiv:2312.11361 , 2023
-
[57]
G. Kim, S. Kim, B. Jeon, J. Park, and J. Kang, “Tree of clarifica- tions: Answering ambiguous questions with retrieval-augmented large language models,” arXiv preprint arXiv:2310.14696 , 2023
-
[58]
Self-knowledge guided retrieval augmentation for large language models,
Y . Wang, P. Li, M. Sun, and Y . Liu, “Self-knowledge guided retrieval augmentation for large language models,” arXiv preprint arXiv:2310.05002, 2023
-
[59]
Retrieval- generation synergy augmented large language models,
Z. Feng, X. Feng, D. Zhao, M. Yang, and B. Qin, “Retrieval- generation synergy augmented large language models,” arXiv preprint arXiv:2310.05149, 2023
-
[61]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Interleav- ing retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions,” arXiv preprint arXiv:2212.10509 , 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
Investigating the factual knowledge boundary of large language models with retrieval augmentation,
R. Ren, Y . Wang, Y . Qu, W. X. Zhao, J. Liu, H. Tian, H. Wu, J.- R. Wen, and H. Wang, “Investigating the factual knowledge boundary of large language models with retrieval augmentation,” arXiv preprint arXiv:2307.11019, 2023
-
[63]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, and C. D. Manning, “Raptor: Recursive abstractive processing for tree-organized retrieval,” arXiv preprint arXiv:2401.18059 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
In-context retrieval-augmented language models
O. Ram, Y . Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton- Brown, and Y . Shoham, “In-context retrieval-augmented language models,” arXiv preprint arXiv:2302.00083 , 2023
-
[65]
Retrieve-and- sample: Document-level event argument extraction via hybrid retrieval augmentation,
Y . Ren, Y . Cao, P. Guo, F. Fang, W. Ma, and Z. Lin, “Retrieve-and- sample: Document-level event argument extraction via hybrid retrieval augmentation,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 2023, pp. 293–306
work page 2023
-
[66]
Zemi: Learning zero-shot semi-parametric language models from multiple tasks,
Z. Wang, X. Pan, D. Yu, D. Yu, J. Chen, and H. Ji, “Zemi: Learning zero-shot semi-parametric language models from multiple tasks,” arXiv preprint arXiv:2210.00185, 2022
-
[67]
Corrective Retrieval Augmented Generation
S.-Q. Yan, J.-C. Gu, Y . Zhu, and Z.-H. Ling, “Corrective retrieval augmented generation,” arXiv preprint arXiv:2401.15884 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
1-pager: One pass answer generation and evidence retrieval,
P. Jain, L. B. Soares, and T. Kwiatkowski, “1-pager: One pass answer generation and evidence retrieval,” arXiv preprint arXiv:2310.16568 , 2023
-
[69]
H. Yang, Z. Li, Y . Zhang, J. Wang, N. Cheng, M. Li, and J. Xiao, “Prca: Fitting black-box large language models for retrieval question answer- ing via pluggable reward-driven contextual adapter,” arXiv preprint arXiv:2310.18347, 2023
-
[70]
Open-source large language models are strong zero-shot query likelihood models for document ranking,
S. Zhuang, B. Liu, B. Koopman, and G. Zuccon, “Open-source large language models are strong zero-shot query likelihood models for document ranking,” arXiv preprint arXiv:2310.13243 , 2023
-
[71]
Recomp: Improving retrieval-augmented lms with compression and selective augmentation,
F. Xu, W. Shi, and E. Choi, “Recomp: Improving retrieval-augmented lms with compression and selective augmentation,” arXiv preprint arXiv:2310.04408, 2023
-
[72]
REPLUG: Retrieval-Augmented Black-Box Language Models
W. Shi, S. Min, M. Yasunaga, M. Seo, R. James, M. Lewis, L. Zettle- moyer, and W.-t. Yih, “Replug: Retrieval-augmented black-box lan- guage models,” arXiv preprint arXiv:2301.12652 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
E. Melz, “Enhancing llm intelligence with arm-rag: Auxiliary ra- tionale memory for retrieval augmented generation,” arXiv preprint arXiv:2311.04177, 2023
-
[74]
Unims-rag: A unified multi-source retrieval-augmented generation for personalized dialogue systems,
H. Wang, W. Huang, Y . Deng, R. Wang, Z. Wang, Y . Wang, F. Mi, J. Z. Pan, and K.-F. Wong, “Unims-rag: A unified multi-source retrieval-augmented generation for personalized dialogue systems,” arXiv preprint arXiv:2401.13256 , 2024
-
[75]
Augmented large language models with parametric knowledge guid- ing,
Z. Luo, C. Xu, P. Zhao, X. Geng, C. Tao, J. Ma, Q. Lin, and D. Jiang, “Augmented large language models with parametric knowledge guid- ing,” arXiv preprint arXiv:2305.04757 , 2023
-
[76]
Structure- aware language model pretraining improves dense retrieval on struc- tured data,
X. Li, Z. Liu, C. Xiong, S. Yu, Y . Gu, Z. Liu, and G. Yu, “Structure- aware language model pretraining improves dense retrieval on struc- tured data,” arXiv preprint arXiv:2305.19912 , 2023
-
[77]
Knowledge graph-augmented language models for knowledge-grounded dialogue generation,
M. Kang, J. M. Kwak, J. Baek, and S. J. Hwang, “Knowledge graph-augmented language models for knowledge-grounded dialogue generation,” arXiv preprint arXiv:2305.18846 , 2023
-
[78]
Retrieval- generation alignment for end-to-end task-oriented dialogue system,
W. Shen, Y . Gao, C. Huang, F. Wan, X. Quan, and W. Bi, “Retrieval- generation alignment for end-to-end task-oriented dialogue system,” arXiv preprint arXiv:2310.08877 , 2023
-
[79]
Dual-feedback knowledge retrieval for task-oriented dialogue systems,
T. Shi, L. Li, Z. Lin, T. Yang, X. Quan, and Q. Wang, “Dual-feedback knowledge retrieval for task-oriented dialogue systems,” arXiv preprint arXiv:2310.14528, 2023
-
[80]
Fabula: Intelligence report generation using retrieval-augmented narrative construction,
P. Ranade and A. Joshi, “Fabula: Intelligence report generation using retrieval-augmented narrative construction,” arXiv preprint arXiv:2310.13848, 2023
-
[81]
Think and retrieval: A hypothesis knowledge graph enhanced medical large language models,
X. Jiang, R. Zhang, Y . Xu, R. Qiu, Y . Fang, Z. Wang, J. Tang, H. Ding, X. Chu, J. Zhao et al. , “Think and retrieval: A hypothesis knowledge graph enhanced medical large language models,” arXiv preprint arXiv:2312.15883, 2023
-
[82]
Knowledge-augmented language model verification,
J. Baek, S. Jeong, M. Kang, J. C. Park, and S. J. Hwang, “Knowledge-augmented language model verification,” arXiv preprint arXiv:2310.12836, 2023
-
[83]
Reasoning on graphs: Faithful and interpretable large language model reasoning,
L. Luo, Y .-F. Li, G. Haffari, and S. Pan, “Reasoning on graphs: Faithful and interpretable large language model reasoning,” arXiv preprint arXiv:2310.01061, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.