LiveVLM: Efficient Online Video Understanding via Streaming-Oriented KV Cache and Retrieval
Pith reviewed 2026-05-22 14:22 UTC · model grok-4.3
The pith
LiveVLM uses vision attention scores to bucket and compress the KV cache for efficient real-time video understanding in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
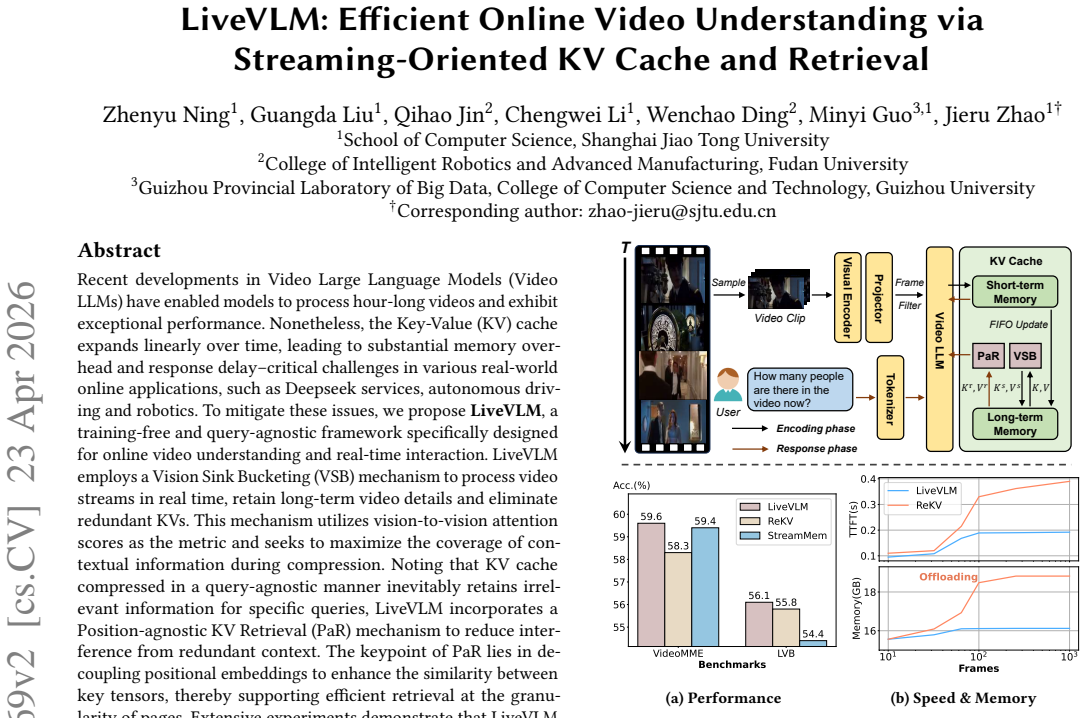
LiveVLM employs a Vision Sink Bucketing mechanism to process video streams in real time, retain long-term video details and eliminate redundant KVs using vision-to-vision attention scores as the metric to maximize contextual information coverage, and incorporates a Position-agnostic KV Retrieval mechanism that decouples positional embeddings to enhance key tensor similarity for efficient page-granularity retrieval, allowing the LLaVA-OneVision model to achieve state-of-the-art accuracy among training-free query-agnostic methods and training-based online models.
What carries the argument
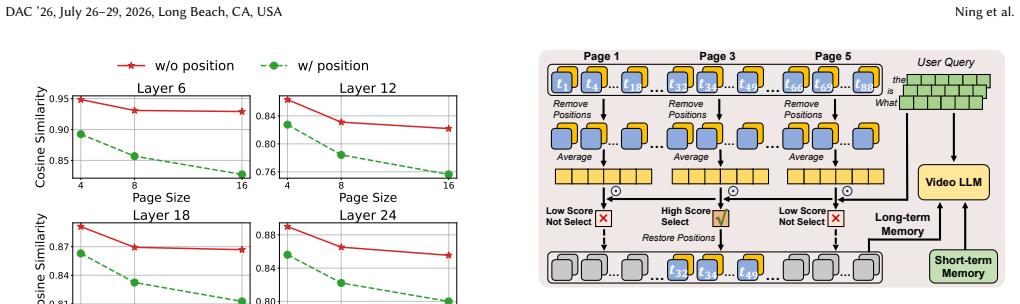
Vision Sink Bucketing (VSB) that groups frames by vision-to-vision attention to compress the KV cache, paired with Position-agnostic KV Retrieval (PaR) that removes position dependence for better similarity matching.
If this is right
- Memory requirements for processing hour-long videos stay manageable instead of growing without bound.
- Response times improve for real-time applications such as autonomous driving and robotics.
- Foundation models can be used online without specialized training for streaming scenarios.
- Redundant information is reduced while still supporting accurate answers to user queries about the video.
Where Pith is reading between the lines
- Similar compression strategies might apply to other continuous data streams like audio or text in long conversations.
- Integrating this with hardware-specific optimizations could further reduce latency on mobile or edge devices.
- Future tests could measure how well the method scales to even longer videos beyond current benchmarks.
Load-bearing premise
Vision-to-vision attention scores act as a dependable measure for keeping the most useful video context during compression, regardless of what the eventual question will be.
What would settle it
Running the model on benchmark videos with the attention-based bucketing replaced by uniform or recent-only frame selection and finding no accuracy improvement would challenge the value of the vision attention metric.
Figures



read the original abstract
Recent developments in Video Large Language Models (Video LLMs) have enabled models to process hour-long videos and exhibit exceptional performance. Nonetheless, the Key-Value (KV) cache expands linearly over time, leading to substantial memory overhead and response delay--critical challenges in various real-world online applications, such as Deepseek services, autonomous driving and robotics. To mitigate these issues, we propose $\textbf{LiveVLM}$, a training-free and query-agnostic framework specifically designed for online video understanding and real-time interaction. LiveVLM employs a Vision Sink Bucketing (VSB) mechanism to process video streams in real time, retain long-term video details and eliminate redundant KVs. This mechanism utilizes vision-to-vision attention scores as the metric and seeks to maximize the coverage of contextual information during compression. Noting that KV cache compressed in a query-agnostic manner inevitably retains irrelevant information for specific queries, LiveVLM incorporates a Position-agnostic KV Retrieval (PaR) mechanism to reduce interference from redundant context. The keypoint of PaR lies in decoupling positional embeddings to enhance the similarity between key tensors, thereby supporting efficient retrieval at the granularity of pages. Extensive experiments demonstrate that LiveVLM enables the foundation LLaVA-OneVision model to achieve state-of-the-art accuracy among both training-free query-agnostic methods and training-based online models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LiveVLM, a training-free and query-agnostic framework for online video understanding in Video LLMs. It introduces Vision Sink Bucketing (VSB) that uses vision-to-vision attention scores to compress the KV cache in a streaming setting while retaining long-term details and removing redundancies, and Position-agnostic KV Retrieval (PaR) that decouples positional embeddings to enable efficient page-granularity retrieval and reduce interference from retained but query-irrelevant context. The central claim is that these mechanisms allow the base LLaVA-OneVision model to reach state-of-the-art accuracy among both training-free query-agnostic methods and training-based online models.
Significance. If the empirical results and the core assumption hold, LiveVLM offers a practical, deployable advance for real-time long-video applications by directly mitigating KV-cache growth without requiring model retraining. The query-agnostic design and compatibility with existing foundation models are notable strengths for latency-sensitive domains such as robotics and autonomous driving.
major comments (2)
- [Abstract and §3.1] Abstract and §3.1 (Vision Sink Bucketing): The claim that vision-to-vision attention scores maximize contextual coverage without discarding details critical for arbitrary future queries is load-bearing for the SOTA result, yet the paper provides no direct evidence or ablation showing that frames evicted by this metric would not have been necessary for downstream query answering; because PaR can only operate on retained tokens, any such error is irrecoverable.
- [§4] §4 (Experiments): The SOTA accuracy claim is presented without accompanying quantitative tables, dataset specifications, baseline comparisons, or error bars in the visible summary; this prevents verification of the magnitude of improvement and the robustness of the cross-method comparison.
minor comments (2)
- [§3.2] Clarify the exact definition of a 'page' in PaR and how it differs from conventional KV cache blocks; a small diagram would improve readability.
- [Abstract] The abstract states 'extensive experiments' but does not name the evaluation datasets or video lengths used; adding these details would help readers assess applicability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, offering clarifications based on the manuscript content and indicating revisions where they strengthen the presentation without misrepresenting our results.
read point-by-point responses
-
Referee: [Abstract and §3.1] Abstract and §3.1 (Vision Sink Bucketing): The claim that vision-to-vision attention scores maximize contextual coverage without discarding details critical for arbitrary future queries is load-bearing for the SOTA result, yet the paper provides no direct evidence or ablation showing that frames evicted by this metric would not have been necessary for downstream query answering; because PaR can only operate on retained tokens, any such error is irrecoverable.
Authors: We agree that a targeted ablation isolating the necessity of evicted frames for arbitrary future queries would provide stronger direct support for the VSB design choice. The current manuscript motivates VSB through its vision-to-vision attention metric for maximizing coverage and demonstrates overall SOTA performance in query-agnostic streaming settings, with PaR mitigating interference on the retained KV cache. To address the concern explicitly, we will add an ablation in the revised §3.1 and §4 comparing VSB eviction against uniform and random baselines across held-out queries, quantifying any performance drop to show that critical information for downstream tasks is preferentially retained. This addition will also discuss the irrecoverable nature of eviction and why the empirical results support the metric's effectiveness. revision: yes
-
Referee: [§4] §4 (Experiments): The SOTA accuracy claim is presented without accompanying quantitative tables, dataset specifications, baseline comparisons, or error bars in the visible summary; this prevents verification of the magnitude of improvement and the robustness of the cross-method comparison.
Authors: The full manuscript in Section 4 contains the requested elements: detailed quantitative tables reporting accuracy on standard benchmarks (including ActivityNet, MSVD-QA, and long-video datasets), explicit dataset specifications, comparisons against both training-free query-agnostic methods and training-based online models, and the magnitude of improvements achieved by LiveVLM over LLaVA-OneVision baselines. Error bars from repeated runs are included for key results to indicate robustness. The summary excerpt may have omitted these details; we will ensure all tables and specifications are prominently referenced and expanded if needed in the revised version to facilitate verification. revision: partial
Circularity Check
No significant circularity detected; mechanisms presented as independent engineering contributions
full rationale
The paper describes LiveVLM as a training-free and query-agnostic framework using Vision Sink Bucketing (VSB) with vision-to-vision attention scores and Position-agnostic KV Retrieval (PaR) for KV cache management in online video understanding. No equations, derivations, or parameter fittings are shown that reduce by construction to the inputs or self-referential definitions. The SOTA accuracy claims rest on experimental results with the LLaVA-OneVision model rather than tautological reductions. No self-citation load-bearing steps, uniqueness theorems from prior author work, or ansatz smuggling via citations are present in the provided text. The derivation chain is self-contained as practical engineering choices validated externally through benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-to-vision attention scores are a suitable metric for maximizing contextual coverage in KV compression.
Forward citations
Cited by 10 Pith papers
-
Semantic-Aware Adaptive Visual Memory for Streaming Video Understanding
SAVEMem improves streaming video understanding scores by adding semantic awareness to memory compression and query-adaptive retrieval without any model training.
-
Don't Pause! Every prediction matters in a streaming video
SPOT-Bench tests real-time streaming video perception with timeliness metrics, exposing limitations in current models and introducing AsynKV as an improved baseline.
-
Online Reasoning Video Object Segmentation
The work introduces the ORVOS task, the ORVOSB benchmark with causal annotations across 210 videos, and a baseline using updated prompts plus a temporal token reservoir.
-
Mosaic: Cross-Modal Clustering for Efficient Video Understanding
Mosaic uses cross-modal clusters as the unit for KVCache organization in VLMs to achieve up to 1.38x speedup in streaming long-video understanding.
-
STAC: Plug-and-Play Spatio-Temporal Aware Cache Compression for Streaming 3D Reconstruction
STAC compresses KV caches in streaming 3D reconstruction transformers via temporal token preservation with decayed attention, spatial voxel compression, and chunked multi-frame optimization, delivering 10x memory redu...
-
An Efficient Streaming Video Understanding Framework with Agentic Control
R3-Streaming uses cascaded control, age-aware memory forgetting, and TB-GRPO reinforcement learning to reach SOTA scores on streaming video benchmarks while cutting visual token usage by 95-96%.
-
CodecSight: Leveraging Video Codec Signals for Efficient Streaming VLM Inference
CodecSight reuses video codec signals for online patch pruning before the vision transformer and selective KV-cache refresh in the LLM, delivering up to 3x higher throughput and 87% lower GPU compute than prior baseli...
-
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
HERMES organizes the KV cache into a hierarchical memory to enable real-time streaming video understanding in MLLMs, achieving 10x faster TTFT and up to 11.4% accuracy gains on streaming benchmarks with 68% fewer tokens.
-
MuKV: Multi-Grained KV Cache Compression for Long Streaming Video Question-Answering
MuKV adds multi-grained KV cache compression at patch-frame-segment levels plus semi-hierarchical retrieval to raise accuracy and cut memory in long video question-answering.
-
Decouple and Cache: KV Cache Construction for Streaming Video Understanding
DSCache decouples cumulative past and instant KV caches with position-agnostic encoding to adapt offline VideoVLLMs to streaming video, delivering 2.5% average accuracy gains on QA benchmarks.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. 2024. Videollm-online: Online video large language model for streaming video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 18407–18418
work page 2024
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision. Springer, 19–35
work page 2024
-
[4]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashat- tention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
work page 2022
- [5]
-
[6]
Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. 2023. Eva: Exploring the limits of masked visual representation learning at scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19358–19369
work page 2023
-
[7]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2024. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. 2024. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13504–13514
work page 2024
-
[9]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. 2024. Chat-univi: Unified visual representation empowers large language models with image and video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13700–13710
work page 2024
- [11]
-
[12]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
work page 2023
-
[14]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Informa- tion Processing Systems37 (2024), 22947–22970
work page 2024
-
[15]
Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, and Lili Qiu
Yucheng Li, Huiqiang Jiang, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, and Lili Qiu. 2025. MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention. arXiv:2504.16083 [cs.CV] https: //arxiv.org/abs/2504.16083
-
[16]
Yanwei Li, Chengyao Wang, and Jiaya Jia. 2024. Llama-vid: An image is worth 2 tokens in large language models. InEuropean Conference on Computer Vision. Springer, 323–340
work page 2024
-
[17]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2023. Video-llava: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [18]
-
[19]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26296–26306
work page 2024
-
[21]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan
-
[22]
Video-chatgpt: Towards detailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. 2023. Embodiedgpt: Vision-language pre-training via embodied chain of thought.Advances in Neural Information Processing Systems36 (2023), 25081–25094
work page 2023
-
[24]
2023.GPT-4V(ision) technical work and authors
OpenAI. 2023.GPT-4V(ision) technical work and authors. https://openai.com/ contributions/gpt-4v/
work page 2023
- [25]
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
work page 2021
-
[27]
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, and Gaoang Wang
- [28]
-
[29]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. Quest: Query-aware sparsity for efficient long-context llm inference. arXiv preprint arXiv:2406.10774(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [30]
- [31]
-
[32]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Jiaqi Wang, Enze Shi, Huawen Hu, Chong Ma, Yiheng Liu, Xuhui Wang, Yincheng Yao, Xuan Liu, Bao Ge, and Shu Zhang. 2024. Large language models for ro- botics: Opportunities, challenges, and perspectives.Journal of Automation and Intelligence(2024)
work page 2024
-
[34]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding. arXiv:2407.15754 [cs.CV] https://arxiv.org/abs/2407.15754
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. 2024. Pllava: Parameter-free llava extension from images to videos for video dense captioning.arXiv preprint arXiv:2404.16994(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [37]
- [38]
- [39]
-
[40]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. 2024. Mlvu: A comprehensive bench- mark for multi-task long video understanding.arXiv preprint arXiv:2406.04264 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.