CoLD: Counterfactually-Guided Length Debiasing for Process Reward Models in Mathematical Reasoning
Pith reviewed 2026-05-21 23:21 UTC · model grok-4.3
The pith
CoLD reduces length bias in process reward models so they favor concise, logically valid math reasoning steps over verbose ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Process reward models exhibit a pervasive length bias in which longer reasoning steps receive higher scores even when semantic content and logical validity remain unchanged. CoLD mitigates this bias through an explicit length-penalty adjustment, a learned bias estimator trained on spurious length signals, and a joint training strategy that enforces length-invariance in reward predictions. The framework is grounded in counterfactual reasoning and causal graph analysis. Experiments on MATH500 and GSM-Plus show gains in step-selection accuracy, more concise yet valid reasoning chains, and consistent improvements in downstream reinforcement learning with cross-domain generalization.
What carries the argument
The CoLD framework that combines explicit length-penalty adjustment, a learned bias estimator for spurious signals, and joint training to enforce length-invariant reward predictions via counterfactual guidance and causal graph analysis.
If this is right
- Higher accuracy when selecting the correct next reasoning step during inference.
- Production of shorter yet logically valid solution chains on benchmarks such as MATH500 and GSM-Plus.
- Measurable gains in final answer accuracy after reinforcement learning that uses the debiased rewards.
- Improved performance when the same model is applied to reasoning tasks outside the original training domain.
Where Pith is reading between the lines
- The same counterfactual separation technique could be tested on other spurious preferences in reward models, such as format or verbosity unrelated to correctness.
- Reducing length bias may lower the token cost of inference by discouraging unnecessarily long chains without extra prompting.
- Causal-graph analysis of reward models might reveal additional hidden confounders beyond length that affect multi-step reasoning quality.
Load-bearing premise
Length bias is a separable spurious signal that can be removed through counterfactual adjustments and joint training without lowering the model's accuracy at recognizing genuinely valid reasoning steps.
What would settle it
On held-out math problems, apply CoLD-trained models and check whether reward scores still rise reliably with step length even when logical validity is held constant; if the correlation remains strong or concise solutions do not improve, the debiasing claim fails.
Figures




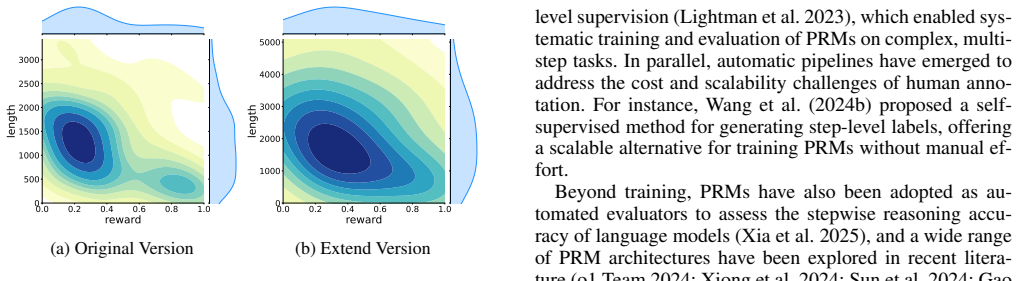

read the original abstract
Process Reward Models (PRMs) play a central role in evaluating and guiding multi-step reasoning in large language models (LLMs), especially for mathematical problem solving. However, we identify a pervasive length bias in existing PRMs: they tend to assign higher scores to longer reasoning steps, even when the semantic content and logical validity are unchanged. This bias undermines the reliability of reward predictions and leads to overly verbose outputs during inference. To address this issue, we propose CoLD(Counterfactually-Guided Length Debiasing), a unified framework that mitigates length bias through three components: an explicit length-penalty adjustment, a learned bias estimator trained to capture spurious length-related signals, and a joint training strategy that enforces length-invariance in reward predictions. Our approach is grounded in counterfactual reasoning and informed by causal graph analysis. Extensive experiments on MATH500 and GSM-Plus show that CoLD improves accuracy in step selection, and encourages more concise, logically valid reasoning. Furthermore, it consistently improves downstream RL performance and generalizes across domains by mitigating length bias, demonstrating CoLD's strong generalization capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a length bias in Process Reward Models (PRMs) for mathematical reasoning, where longer steps receive higher scores despite unchanged semantics and validity. It proposes CoLD, a framework using counterfactual reasoning, causal graph analysis, an explicit length penalty, a learned bias estimator, and joint training (Eq. 4) to enforce length-invariance. Experiments on MATH500 and GSM-Plus report improved step-selection accuracy, more concise valid reasoning, and gains in downstream RL with cross-domain generalization.
Significance. If the counterfactual pairs successfully isolate length from validity and the empirical gains hold under proper controls, CoLD could improve PRM reliability for guiding LLM reasoning, reducing verbosity while preserving logical correctness, and enhancing RL outcomes in math domains.
major comments (2)
- [§3.2] §3.2: The counterfactual generation procedure (via editing or prompting) must be shown to preserve semantic content, logical validity, and applicable theorems exactly while only varying token count; if it inadvertently alters reasoning structure or introduces subtle errors, the bias estimator trained in the joint objective will suppress valid features rather than pure length signals, violating the length-invariance guarantee.
- [Experiments] Experiments section: The reported accuracy improvements and RL gains on MATH500 and GSM-Plus lack explicit details on baselines, statistical tests, ablation controls isolating the bias estimator, or exact metrics; without these, it is unclear whether the gains stem from successful length debiasing or from other factors.
minor comments (1)
- [Abstract] Abstract: Provide at least one concrete metric (e.g., accuracy delta or RL reward improvement) to support the claims of improved step selection and RL performance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below with clarifications and indicate the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [§3.2] §3.2: The counterfactual generation procedure (via editing or prompting) must be shown to preserve semantic content, logical validity, and applicable theorems exactly while only varying token count; if it inadvertently alters reasoning structure or introduces subtle errors, the bias estimator trained in the joint objective will suppress valid features rather than pure length signals, violating the length-invariance guarantee.
Authors: We agree that explicit verification of semantic and logical preservation in the counterfactual pairs is essential to support the length-invariance claim. In the revised manuscript, we will expand Section 3.2 to include a new analysis subsection with both qualitative examples and quantitative checks (e.g., semantic similarity via embedding cosine scores and manual validity annotations on a held-out sample of pairs). These additions will demonstrate that edits modify only token count while retaining reasoning structure, theorems, and correctness. revision: yes
-
Referee: [Experiments] Experiments section: The reported accuracy improvements and RL gains on MATH500 and GSM-Plus lack explicit details on baselines, statistical tests, ablation controls isolating the bias estimator, or exact metrics; without these, it is unclear whether the gains stem from successful length debiasing or from other factors.
Authors: We acknowledge that greater transparency in experimental reporting is needed. In the revised Experiments section, we will add: (i) a complete enumeration of baselines with citations, (ii) statistical significance tests (paired t-tests with p-values) for all reported improvements, (iii) targeted ablations that isolate the bias estimator component, and (iv) expanded tables containing exact metric definitions and numerical values. These changes will clarify the source of the observed gains. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents CoLD as a framework with three explicitly defined components—an explicit length-penalty adjustment, a learned bias estimator, and a joint training objective—grounded in counterfactual reasoning and causal graph analysis. These are introduced independently in the method section and validated through experiments on external public benchmarks (MATH500, GSM-Plus) and downstream RL tasks. No equation or claim reduces by construction to a fitted parameter renamed as a prediction, nor does any load-bearing premise collapse to a self-citation chain or self-referential definition. The central length-invariance guarantee is supported by the counterfactual construction and training procedure rather than being presupposed by the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Length bias is a spurious correlation independent of logical validity and semantic content
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt a counterfactual formulation of debiasing: for any input S, we define the length bias as the change in prediction under a hypothetical intervention on L: Bias(S) := r(S) − r(SL← ˜L)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
r∗(x) = r(x) − αℓ(x)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
ToolPRM: Fine-Grained Inference Scaling of Structured Outputs for Function Calling
ToolPRM provides fine-grained intra-call process supervision via a new dataset and reward model, outperforming outcome and coarse-grained alternatives on function-calling benchmarks.
-
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
The paper introduces the Proxy Compression Hypothesis as a unifying framework explaining reward hacking in RLHF as an emergent result of compressing high-dimensional human objectives into proxy reward signals under op...
Reference graph
Works this paper leans on
-
[1]
Qwen technical report. arXiv preprint arXiv:2309.16609. Chen, L.; Zhu, C.; Soselia, D.; Chen, J.; Zhou, T.; Gold- stein, T.; Huang, H.; Shoeybi, M.; and Catanzaro, B
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Odin: Disentangled reward mitigates hacking in rlhf.arXiv preprint arXiv:2402.07319, 2024
Odin: Disentangled reward mitigates hacking in rlhf. arXiv preprint arXiv:2402.07319. Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al
-
[3]
The llama 3 herd of models. arXiv preprint arXiv:2407.21783. Eisenstein, J.; Nagpal, C.; Agarwal, A.; Beirami, A.; D’Amour, A.; Dvijotham, D.; Fisch, A.; Heller, K.; Pfohl, S.; Ramachandran, D.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
J., Fisch, A., Heller, K., Pfohl, S., Ramachandran, D., Shaw, P., and Berant, J
Helping or herding? re- ward model ensembles mitigate but do not eliminate reward hacking. arXiv preprint arXiv:2312.09244. Gao, B.; Cai, Z.; Xu, R.; Wang, P.; Zheng, C.; Lin, R.; Lu, K.; Liu, D.; Zhou, C.; Xiao, W.; Hu, J.; Liu, T.; and Chang, B
-
[5]
LLM Critics Help Catch Bugs in Mathematics: To- wards a Better Mathematical Verifier with Natural Language Feedback. arXiv:2406.14024. Hendrycks, D.; Burns, C.; Kadavath, S.; Arora, A.; Basart, S.; Tang, E.; Song, D.; and Steinhardt, J
-
[6]
Measuring Mathematical Problem Solving With the MATH Dataset
URL https://arxiv. org/abs/2103.03874. Huang, Z.; Qiu, Z.; Wang, Z.; Ponti, E. M.; and Titov, I
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2409.17407
Post-hoc reward calibration: A case study on length bias. arXiv preprint arXiv:2409.17407. Li, Q.; Cui, L.; Zhao, X.; Kong, L.; and Bi, W
-
[8]
Gsm- plus: A comprehensive benchmark for evaluating the robust- ness of llms as mathematical problem solvers.arXiv preprint arXiv:2402.19255. Li, W.; and Li, Y
-
[9]
arXiv preprint arXiv:2410.11287
Process reward model with q-value rankings. arXiv preprint arXiv:2410.11287. Lightman, H.; Kosaraju, V .; Burda, Y .; Edwards, H.; Baker, B.; Lee, T.; Leike, J.; Schulman, J.; Sutskever, I.; and Cobbe, K
-
[10]
Let’s verify step by step. arXiv preprint arXiv:2305.20050. Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437. Luo, L.; Liu, Y .; Liu, R.; Phatale, S.; Guo, M.; Lara, H.; Li, Y .; Shu, L.; Zhu, Y .; Meng, L.; Sun, J.; and Rastogi, A
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Improve Mathematical Reasoning in Language Models by Automated Process Supervision. arXiv:2406.06592. McAleese, N.; Pokorny, R. M.; Uribe, J. F. C.; Nitishin- skaya, E.; Trebacz, M.; and Leike, J
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
LLM Critics Help Catch LLM Bugs,
LLM Critics Help Catch LLM Bugs. arXiv:2407.00215. o1 Team, S
-
[14]
Gpt-4 technical report. arxiv 2303.08774. View in Article, 2(5). Pearl, J
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Ram´e, A.; Ferret, J.; Vieillard, N.; Dadashi, R.; Hussenot, L.; Cedoz, P.-L.; Sessa, P
arXiv:2410.18982. Ram´e, A.; Ferret, J.; Vieillard, N.; Dadashi, R.; Hussenot, L.; Cedoz, P.-L.; Sessa, P. G.; Girgin, S.; Douillard, A.; and Bachem, O
-
[16]
arXiv preprint arXiv:2406.16768
Warp: On the benefits of weight averaged rewarded policies. arXiv preprint arXiv:2406.16768. Shao, Z.; Wang, P.; Zhu, Q.; Xu, R.; Song, J.; Bi, X.; Zhang, H.; Zhang, M.; Li, Y .; Wu, Y .; et al
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open lan- guage models. arXiv preprint arXiv:2402.03300. Shen, W.; Zheng, R.; Zhan, W.; Zhao, J.; Dou, S.; Gui, T.; Zhang, Q.; and Huang, X
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2310.05199
Loose lips sink ships: Mit- igating length bias in reinforcement learning from human feedback. arXiv preprint arXiv:2310.05199. Singhal, P.; Goyal, T.; Xu, J.; and Durrett, G
-
[19]
A long way to go: Investigating length correlations in rlhf,
A long way to go: Investigating length correlations in rlhf. arXiv preprint arXiv:2310.03716. Snell, C.; Lee, J.; Xu, K.; and Kumar, A
-
[20]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scal- ing model parameters. arXiv preprint arXiv:2408.03314. Sun, Z.; Yu, L.; Shen, Y .; Liu, W.; Yang, Y .; Welleck, S.; and Gan, C
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision. arXiv:2403.09472. Wang, J.; Fang, M.; Wan, Z.; Wen, M.; Zhu, J.; Liu, A.; Gong, Z.; Song, Y .; Chen, L.; Ni, L. M.; Yang, L.; Wen, Y .; and Zhang, W. 2024a. OpenR: An Open Source Frame- work for Advanced Reasoning with Large Language Mod- els. arXiv:2410.09671. Wang, P.; Li, L.; Sha...
-
[22]
Inference scaling laws: An empirical analysis of compute- optimal inference for problem-solving with language mod- els. arXiv preprint arXiv:2408.00724. Xia, S.; Li, X.; Liu, Y .; Wu, T.; and Liu, P
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Evaluating mathematical reasoning beyond accuracy
Evaluating Mathematical Reasoning Beyond Accuracy. arXiv:2404.05692. Xiong, W.; Zhang, H.; Jiang, N.; and Zhang, T
-
[24]
Qwen3 technical report. arXiv preprint arXiv:2505.09388. Zhang, L.; Hosseini, A.; Bansal, H.; Kazemi, M.; Kumar, A.; and Agarwal, R
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Generative Verifiers: Reward Mod- eling as Next-Token Prediction. arXiv:2408.15240. Zhao, J.; Liu, R.; Zhang, K.; Zhou, Z.; Gao, J.; Li, D.; Lyu, J.; Qian, Z.; Qi, B.; Li, X.; et al
-
[26]
arXiv preprint arXiv:2504.00891
Genprm: Scaling test-time compute of process reward models via generative reasoning. arXiv preprint arXiv:2504.00891. Zheng, C.; Zhang, Z.; Zhang, B.; Lin, R.; Lu, K.; Yu, B.; Liu, D.; Zhou, J.; and Lin, J
-
[27]
Processbench: Identifying process errors in mathematical reasoning
Processbench: Identifying process errors in mathematical reasoning. arXiv preprint arXiv:2412.06559. Zhu, J.; Zheng, C.; Lin, J.; Du, K.; Wen, Y .; Yu, Y .; Wang, J.; and Zhang, W
-
[28]
arXiv preprint arXiv:2502.14361
Retrieval-Augmented Process Reward Model for Generalizable Mathematical Reasoning. arXiv preprint arXiv:2502.14361. Zhu, Q.; Guo, D.; Shao, Z.; Yang, D.; Wang, P.; Xu, R.; Wu, Y .; Li, Y .; Gao, H.; Ma, S.; et al
-
[29]
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
DeepSeek-Coder- V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. arXiv preprint arXiv:2406.11931. Experiment Details Example of Semi-synthetic Solution We generate extended variants either by duplicating the orig- inal step or by prompting DeepSeek (Liu et al
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.