EngiBench: A Benchmark for Evaluating Large Language Models on Engineering Problem Solving
Pith reviewed 2026-05-18 15:03 UTC · model grok-4.3
The pith
Current large language models lack the high-level reasoning needed for real-world engineering problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
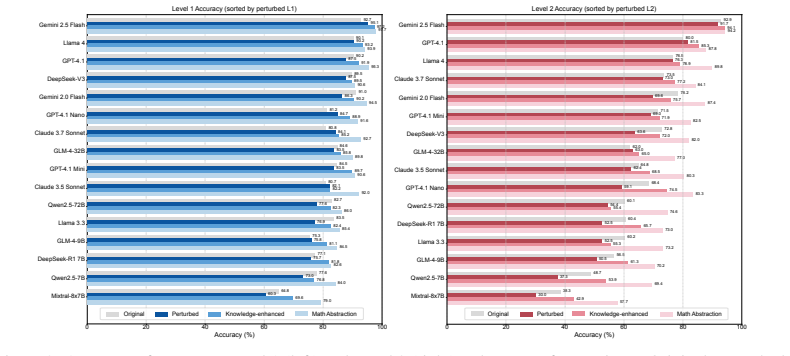
We introduce EngiBench, a hierarchical benchmark spanning foundational knowledge retrieval, contextual reasoning, and open-ended modeling across engineering subfields. Each original problem is rewritten into perturbed, knowledge-enhanced, and math-abstraction variants that isolate robustness, domain-specific knowledge, and mathematical reasoning. Experiments reveal clear performance stratification: accuracy declines with task complexity, degrades under minor perturbations, and remains substantially below human performance on high-level engineering tasks.
What carries the argument
A hierarchical benchmark with three difficulty levels and three controlled problem variants that separately measure robustness to perturbation, domain knowledge use, and mathematical abstraction.
If this is right
- Accuracy falls steadily as problems move from foundational retrieval to open-ended modeling.
- Small perturbations in problem wording cause measurable drops in model performance.
- Performance on high-level tasks stays substantially below human levels across tested models.
- Future models will require deeper integration of context handling and reliable reasoning to close the gap.
Where Pith is reading between the lines
- The controlled variants could serve as a diagnostic tool to pinpoint whether a given model's failures stem from fragility, missing facts, or weak calculation.
- Similar layered benchmarks with variants might be built for other applied domains such as medicine or policy analysis.
- Training regimes that deliberately include perturbed and open-ended engineering data could be tested to see whether they raise performance on the hardest tier.
Load-bearing premise
The chosen engineering problems and their three rewritten variants accurately capture real-world complexities and cleanly separate robustness, domain knowledge, and mathematical reasoning.
What would settle it
Demonstrating near-human accuracy on the open-ended modeling level with no drop under the perturbed variants would falsify the claim that current LLMs lack the required high-level reasoning.
Figures










read the original abstract
Large language models (LLMs) have shown strong performance on mathematical reasoning under well-defined conditions. However, real-world engineering problems involve uncertainty, context, and open-ended settings that extend beyond symbolic computation. Existing benchmarks largely focus on well-defined or abstract reasoning and therefore fail to capture these complexities. We introduce EngiBench, a hierarchical benchmark designed to evaluate LLMs on solving engineering problems. It spans three levels of increasing difficulty (foundational knowledge retrieval, contextual reasoning, and open-ended modeling) and covers diverse engineering subfields. To facilitate a deeper understanding of model performance, we systematically rewrite each problem into three controlled variants (perturbed, knowledge-enhanced, and math abstraction), enabling us to separately evaluate the model's robustness, domain-specific knowledge, and mathematical reasoning abilities. Experimental results show clear performance stratification across difficulty levels: model accuracy declines with task complexity, degrades under minor perturbations, and remains substantially below human performance on high-level engineering tasks. These findings reveal that current LLMs still lack the high-level reasoning needed for real-world engineering, highlighting the need for future models with deeper and more reliable problem-solving capabilities. Our source code and data are available at https://github.com/AI4Engi/EngiBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EngiBench, a hierarchical benchmark for LLMs on engineering problem solving spanning three difficulty levels (foundational knowledge retrieval, contextual reasoning, open-ended modeling) across diverse subfields. Each problem is rewritten into three controlled variants (perturbed, knowledge-enhanced, math abstraction) to separately probe robustness, domain knowledge, and mathematical reasoning. Experiments report performance stratification with accuracy declining as complexity increases, degradation under perturbations, and a large gap relative to human performance, supporting the claim that current LLMs lack the high-level reasoning required for real-world engineering tasks. Code and data are released at https://github.com/AI4Engi/EngiBench.
Significance. If the variants are validated to isolate the targeted factors without confounds, the benchmark would usefully highlight limitations of LLMs in handling uncertainty, context, and open-ended engineering problems beyond abstract math benchmarks. The public release of code and data is a clear strength that supports reproducibility and community adoption. The empirical stratification provides concrete data points that could inform future model development in applied domains.
major comments (2)
- [Abstract and benchmark construction] Abstract and benchmark construction section: the claim that the three variants 'separately evaluate the model's robustness, domain-specific knowledge, and mathematical reasoning abilities' is load-bearing for the central attribution of performance drops to specific deficits, yet the manuscript provides no validation, controls, or inter-rater checks confirming that rewrites affect only the intended dimension (e.g., a perturbation may simultaneously alter required domain knowledge or open-endedness).
- [Methods / Benchmark Construction] Problem selection and methods: insufficient detail is given on selection criteria, number of problems per level/subfield, and how real-world complexity is ensured, which directly affects whether observed stratification reflects engineering-specific reasoning gaps rather than generic task difficulty.
minor comments (2)
- [Experimental Results] Add explicit statistical significance tests or confidence intervals for the reported accuracy differences across levels and variants.
- [Abstract] Clarify the total number of problems and the distribution across engineering subfields in the abstract or early methods for better scope assessment.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each of the major comments point by point below, providing our responses and indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and benchmark construction] Abstract and benchmark construction section: the claim that the three variants 'separately evaluate the model's robustness, domain-specific knowledge, and mathematical reasoning abilities' is load-bearing for the central attribution of performance drops to specific deficits, yet the manuscript provides no validation, controls, or inter-rater checks confirming that rewrites affect only the intended dimension (e.g., a perturbation may simultaneously alter required domain knowledge or open-endedness).
Authors: We acknowledge the importance of validating that the variants isolate the intended factors. While the manuscript describes the systematic rewrite process, it does not include explicit controls or inter-rater checks. The rewrites were designed to be orthogonal: perturbations introduce small changes to test robustness without altering core knowledge or open-endedness; knowledge-enhanced variants add targeted domain information; and math abstraction variants reframe to emphasize symbolic reasoning. To strengthen the paper, we will add a new subsection detailing the construction guidelines, include illustrative examples showing the differences, and note any potential overlaps as a limitation. We will also consider adding a small validation study if feasible. revision: yes
-
Referee: [Methods / Benchmark Construction] Problem selection and methods: insufficient detail is given on selection criteria, number of problems per level/subfield, and how real-world complexity is ensured, which directly affects whether observed stratification reflects engineering-specific reasoning gaps rather than generic task difficulty.
Authors: We appreciate this feedback on the need for greater transparency in benchmark construction. The current manuscript provides an overview of the hierarchical levels and subfield coverage but lacks granular details. We will revise the Methods section to include: (1) explicit selection criteria, such as sourcing from accredited engineering curricula and industry reports to ensure real-world relevance; (2) the precise counts of problems (we will report the distribution, e.g., across foundational, contextual, and open-ended levels and the five subfields); and (3) the measures taken to ensure complexity, including review by domain experts for open-ended modeling tasks. A table summarizing the benchmark composition will be added to facilitate understanding of the stratification results. revision: yes
Circularity Check
No significant circularity: empirical benchmark study with direct experimental observations
full rationale
The paper introduces EngiBench as a new hierarchical benchmark with three difficulty levels and three controlled problem variants, then reports LLM performance on these tasks. No mathematical derivations, fitted parameters, or predictions are claimed; results are presented as direct experimental outcomes. The central claim that LLMs lack high-level engineering reasoning follows from observed accuracy declines across levels and variants, without any step that reduces by construction to prior inputs, self-citations, or ansatzes. The benchmark design choices are stated explicitly rather than derived from self-referential premises. This is a standard empirical evaluation whose validity rests on the quality of the constructed problems and experiments, not on circular logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Engineering problems can be hierarchically classified into foundational knowledge retrieval, contextual reasoning, and open-ended modeling with increasing difficulty.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce EngiBench, a hierarchical benchmark... three controlled variants (perturbed, knowledge-enhanced, and math abstraction), enabling us to separately evaluate the model's robustness, domain-specific knowledge, and mathematical reasoning abilities.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Engineering problems differ fundamentally from mathematical problems... open-ended, highly context-dependent, and must be achieved within real-world constraints.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
ThermoQA: A Three-Tier Benchmark for Evaluating Thermodynamic Reasoning in Large Language Models
ThermoQA benchmark shows top LLMs reach 92-94% overall on thermodynamics problems but degrade sharply on full cycle analysis, confirming that property knowledge does not equal reasoning ability.
-
IndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
IndustryBench shows top LLMs score only 2.083 out of 3 on industrial QA tasks, with safety-violation checks reshuffling rankings and extended reasoning often adding unsupported unsafe details.
-
IndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
IndustryBench shows LLMs reach only modest scores on standards-grounded industrial procurement questions and that safety-violation filtering substantially changes model rankings.
-
IndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
IndustryBench is a standards-grounded Chinese benchmark that exposes LLMs' persistent gaps in industrial terminology, safety compliance, and parameter accuracy, with safety checks reshuffling model rankings.
-
How Far Are We? Systematic Evaluation of LLMs vs. Human Experts in Mathematical Contest in Modeling
LLMs exhibit a persistent comprehension-execution gap in end-to-end mathematical modeling tasks, with a new stage-wise framework showing better alignment to human expert judgments than prior schemes.
-
Enhancing Large Language Model-Based Systems for End-to-End Circuit Analysis Problem Solving
Hybrid pipeline using YOLO vision and ngspice verification raises circuit analysis accuracy from Gemini's 79.52% baseline to 97.59%, with similar gains on hand-drawn diagrams.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, et al. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models.arXiv preprint arXiv:2502.17387, 2025
-
[3]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms.arXiv preprint arXiv:1905.13319, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[4]
Anthropic. Claude-3.5 sonnet, 2024. URL https://www.anthropic.com/news/ claude-3-5-sonnet . Available at: https://www.anthropic.com/news/ claude-3-5-sonnet
work page 2024
-
[5]
Claude-3 family: Opus, sonnet, haiku, 2024
Anthropic. Claude-3 family: Opus, sonnet, haiku, 2024. URL https://assets. anthropic.com/m/61e7d27f8c8f5919/original/Claude-3-Model-Card. pdf. Available at: https://assets.anthropic.com/m/61e7d27f8c8f5919/ original/Claude-3-Model-Card.pdf
work page 2024
-
[6]
Have llms advanced enough? a challenging problem solving benchmark for large language models
Daman Arora, Himanshu Singh, et al. Have llms advanced enough? a challenging problem solving benchmark for large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 7527–7543, 2023
work page 2023
-
[7]
Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues.arXiv preprint arXiv:2402.14762, 2024
-
[8]
A large language model for advanced power dispatch.Scientific Reports, 15(1):8925, 2025
Yuheng Cheng, Huan Zhao, Xiyuan Zhou, Junhua Zhao, Yuji Cao, Chao Yang, and Xinlei Cai. A large language model for advanced power dispatch.Scientific Reports, 15(1):8925, 2025
work page 2025
-
[9]
Anoop Cherian, Kuan-Chuan Peng, Suhas Lohit, Joanna Matthiesen, Kevin Smith, and Josh Tenenbaum. Evaluating large vision-and-language models on children’s mathematical olympiads.Advances in Neural Information Processing Systems, 37:15779–15800, 2024
work page 2024
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Investigating data contamination in modern benchmarks for large language models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. Investigating data contamination in modern benchmarks for large language models. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volum...
-
[12]
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, King Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, et al. Supergpqa: Scaling llm evaluation across 285 graduate disciplines.arXiv preprint arXiv:2502.14739, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Clive L Dym, Alice M Agogino, Ozgur Eris, Daniel D Frey, and Larry J Leifer. Engineering design thinking, teaching, and learning.Journal of engineering education, 94(1):103–120, 2005
work page 2005
-
[14]
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, et al. Omni-math: A universal olympiad level mathematic benchmark for large language models.arXiv preprint arXiv:2410.07985, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Lei Gao, Dongkai Wang, Yanjun Cui, Jun Zhao, Yi Gu, Ge Zhang, Yuxiao Dong, and Jie Tang. OmniMath: An open-source and reproducible large benchmark for llm mathematical reasoning ability evaluation, 2024
work page 2024
-
[16]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Putnam-axiom: A functional and static benchmark for measuring higher level mathematical reasoning
Aryan Gulati, Brando Miranda, Eric Chen, Emily Xia, Kai Fronsdal, Bruno de Moraes Dumont, and Sanmi Koyejo. Putnam-axiom: A functional and static benchmark for measuring higher level mathematical reasoning. InThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, 2024
work page 2024
-
[19]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Kaixuan Huang, Jiacheng Guo, Zihao Li, Xiang Ji, Jiawei Ge, Wenzhe Li, Yingqing Guo, Tianle Cai, Hui Yuan, Runzhe Wang, et al. Math-perturb: Benchmarking llms’ math reasoning abilities against hard perturbations.arXiv preprint arXiv:2502.06453, 2025
-
[22]
Competition-level problems are effective llm evaluators
Yiming Huang, Zhenghao Lin, Xiao Liu, Yeyun Gong, Shuai Lu, Fangyu Lei, Yaobo Liang, Yelong Shen, Chen Lin, Nan Duan, et al. Competition-level problems are effective llm evaluators. arXiv preprint arXiv:2312.02143, 2023
-
[23]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models. InThe Twelfth International Confer- ence on Learning Representations, 2024. URLhttps://openreview.net/forum?id= 8euJaTveKw
work page 2024
-
[25]
Ming Li, Jike Zhong, Tianle Chen, Yuxiang Lai, and Konstantinos Psounis. Eee-bench: A comprehensive multimodal electrical and electronics engineering benchmark.arXiv preprint arXiv:2411.01492, 2024
-
[26]
Unimath: A foundational and multimodal mathematical reasoner
Zhenwen Liang, Tianyu Yang, Jipeng Zhang, and Xiangliang Zhang. Unimath: A foundational and multimodal mathematical reasoner. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 7126–7133, 2023
work page 2023
-
[27]
Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, et al. Goedel-prover: A frontier model for open-source automated theorem proving.arXiv preprint arXiv:2502.07640, 2025
-
[28]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InThe Twelfth International Confer- ence on Learning Representations, 2024. URL https://openreview.net/forum? id=KUNzEQMWU7
work page 2024
-
[30]
Pingchuan Ma, Tsun-Hsuan Wang, Minghao Guo, Zhiqing Sun, Joshua B Tenenbaum, Daniela Rus, Chuang Gan, and Wojciech Matusik. Llm and simulation as bilevel optimizers: A new paradigm to advance physical scientific discovery.arXiv preprint arXiv:2405.09783, 2024
-
[31]
Yujun Mao, Yoon Kim, and Yilun Zhou. CHAMP: A competition-level dataset for fine-grained analyses of LLMs’ mathematical reasoning capabilities. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.),Findings of the Association for Computational Linguistics: ACL 2024, pp. 13256–13274, Bangkok, Thailand, August 2024. Association for Computational Linguisti...
-
[32]
GSM-symbolic: Understanding the limitations of mathematical reasoning in large language models
Seyed Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. GSM-symbolic: Understanding the limitations of mathematical reasoning in large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=AjXkRZIvjB
work page 2025
-
[33]
Arindam Mitra, Hamed Khanpour, Corby Rosset, and Ahmed Awadallah
Arindam Mitra, Hamed Khanpour, Corby Rosset, and Ahmed Awadallah. Orca-math: Unlocking the potential of slms in grade school math.arXiv preprint arXiv:2402.14830, 2024
-
[34]
FEABench: Evaluating language models on multiphysics reasoning ability,
Nayantara Mudur, Hao Cui, Subhashini Venugopalan, Paul Raccuglia, Michael P Brenner, and Peter Norgaard. Feabench: Evaluating language models on multiphysics reasoning ability. arXiv preprint arXiv:2504.06260, 2025
-
[35]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2080–2094, 2021
work page 2021
-
[36]
ZZ Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, et al. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URLhttps://openreview.net/forum?id=KivNpBsfAS
work page 2023
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
arXiv preprint arXiv:2402.19450 , year=
Saurabh Srivastava, Anto PV , Shashank Menon, Ajay Sukumar, Alan Philipose, Stevin Prince, Sooraj Thomas, et al. Functional benchmarks for robust evaluation of reasoning performance, and the reasoning gap.arXiv preprint arXiv:2402.19450, 2024
-
[40]
Usman Syed, Ethan Light, Xingang Guo, Huan Zhang, Lianhui Qin, Yanfeng Ouyang, and Bin Hu. Benchmarking the capabilities of large language models in transportation system engineering: Accuracy, consistency, and reasoning behaviors.arXiv preprint arXiv:2408.08302, 2024
-
[41]
Orlm: A customizable framework in training large models for automated optimization modeling,
Zhengyang Tang, Chenyu Huang, Xin Zheng, Shixi Hu, Zizhuo Wang, Dongdong Ge, and Benyou Wang. Orlm: Training large language models for optimization modeling.arXiv preprint arXiv:2405.17743, 2024
-
[42]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37:95095–95169, 2024
work page 2024
-
[45]
Xinlei Wang, Maike Feng, Jing Qiu, Jinjin Gu, and Junhua Zhao. From news to forecast: Integrating event analysis in llm-based time series forecasting with reflection.Advances in Neural Information Processing Systems, 37:58118–58153, 2024
work page 2024
-
[46]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[47]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[48]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and Animashree Anandkumar. Leandojo: Theorem proving with retrieval-augmented language models.Advances in Neural Information Processing Systems, 36: 21573–21612, 2023
work page 2023
-
[50]
Harp: A challenging human-annotated math reasoning benchmark.arXiv preprint arXiv:2412.08819, 2024
Albert S Yue, Lovish Madaan, Ted Moskovitz, DJ Strouse, and Aaditya K Singh. Harp: A challenging human-annotated math reasoning benchmark.arXiv preprint arXiv:2412.08819, 2024
-
[51]
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, William Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, et al. A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
work page 2024
-
[52]
minif2f: a cross-system benchmark for formal olympiad-level mathematics
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. minif2f: a cross-system benchmark for formal olympiad-level mathematics. InInternational Conference on Learning Representations,
-
[53]
URLhttps://openreview.net/forum?id=9ZPegFuFTFv
-
[54]
Xiyuan Zhou, Huan Zhao, Yuheng Cheng, Yuji Cao, Gaoqi Liang, Guolong Liu, Wenxuan Liu, Yan Xu, and Junhua Zhao. Elecbench: a power dispatch evaluation benchmark for large language models.arXiv preprint arXiv:2407.05365, 2024. APPENDIX CONTENTS A Future Works 14 B Limitations 15 C Dataset Curation- Additional Details 15 C.1 Level 1 & Level 2 Extraction Pro...
-
[55]
Problems lacking domain relevance are excluded to maintain the technical integrity of the benchmark
Engineering Relevance Filtering:Each problem is evaluated for its applicability to engi- neering scenarios. Problems lacking domain relevance are excluded to maintain the technical integrity of the benchmark. The prompt used to determine whether a problem pertains to engineering is as follows: 1"""Determine if ORIGINAL problem can be solved with ONLY math...
-
[56]
Discipline and Subfield Classification:Relevant problems are first assigned to a specific engineering discipline (e.g., Electrical, Civil, Mechanical), and then grouped into one of EngiBench’s three high-level analytical subfields: Systems & Control, Physical & Structural, or Chemical & Biological. The prompt used for assigning a problem to a specific eng...
-
[57]
Difficulty Level Assignment:Based on the complexity of the required reasoning process, tasks are categorized into Level 1 or Level 2. Level 1 includes basic knowledge recall and single-step computation, while Level 2 involves multi-step inference, contextual understand- ing, and integration of structured constraints. The prompt used for classifying the di...
work page 2010
-
[58]
Language Normalization:Non-English problems are translated into fluent English using machine translation, while preserving the original engineering semantics
-
[59]
Expression Rewriting:To minimize potential overlap with pretraining data, each problem is paraphrased by the LLM using diverse sentence structures and reasoning styles. While surface expressions are significantly altered, the core logic, numerical values, and solution paths remain unchanged. This step produces theperturbed versionof each task, which is us...
-
[60]
Multimodal Simplification:For problems containing simple figures or tables, we extract and describe the essential information using plain text or LATEX-formatted representations to support uniform text-based evaluation. LLM Prompt Template:The following instruction prompt is used to guide the LLM in modifying each problem: 1"""Assuming you are a question ...
-
[61]
Rewriting Suitability: Determine the type (0-3): 3- 0: Non-rewritable (use only when necessary) 4- 1: Modify expressions only 5- 2: Modify numerical values only 6- 3: Modify both expressions and numerical values 7// Note: All rewrites must maintain the original problem logic, engineering context, and reasoning/computational requirements 8
-
[62]
Make the answer as difficult as possible while ensuring that the answer is correct
Rewritten Problem: Rewrite the problem according to the type of rewriting suitability above. Make the answer as difficult as possible while ensuring that the answer is correct. (Please rewrite the problem in a way that is radically different from your regular logical structure by: (1) avoiding common reasoning patterns in your model, (2) simulating human ...
-
[63]
Rewritten Solution Process: Provide step-by-step explanation including all reasoning, calculations and logic. Clearly state if answer can be obtained directly through formula substitution (shortest solution path without intermediate steps). 16
-
[64]
Calculate voltage across 5 Ohm resistor with 2 A current
Rewritten Answer: Provide correct answer for rewritten problem (only types 2/3 may change)""" 18 • Knowledge-enhanced Version.In this version, relevant domain knowledge—such as formulas, constants, and conversions—is explicitly provided before the original question. This allows us to evaluate whether performance deficits are due to missing knowledge or fa...
-
[65]
For calculation-focused problems: 7- If the numerical values match, consider it correct even if units are missing 8- Focus on the mathematical reasoning and final numerical result 9- Check if the core calculation steps are correct 10- For complex calculations, allow $\pm 2\%$ tolerance in the final numerical result 11 12
-
[66]
For conceptual or unit-specific problems: 14- Units and their consistency must be considered 15- The complete answer including units is required 16
-
[67]
Consider the answer correct if: 18- The mathematical reasoning is sound 19- The final numerical value matches (within $\pm 2\%$ tolerance for complex calculations) 20- For calculation-focused problems, matching units are not mandatory 21 22Reply only with "True" or "False". """ E.2 LEVEL3 EVALUATIONDETAILS To convert open-ended modeling problems into eval...
-
[69]
[Specific criterion] - [sub-score] points: [ justification]\n
-
[70]
[Specific criterion] - [sub-score] points: [ justification]\n 17Final score: [total] points" 18}} 19 20Note: 21- Break down your scoring into specific components 22- Provide clear justification for each sub-score 23- Be objective and consistent in your evaluation 24- Consider both the technical accuracy and the methodology 25""" E.3 LEVEL3 SCORINGEXAMPLES...
-
[71]
Full Mark (Avg. Score: 9.475):The problem requires optimizing Hu sheep farm pen utilization under stochastic conditions (conception rates, gestation periods, litter sizes) while adhering to strict capacity constraints and cohabitation rules. The solution must minimize expected losses from idle pens (1 unit/day) or shortages (3 units/day) through dynamic s...
-
[72]
5 points (Avg. Score: 5.375):The problem involves modeling a team coordination exercise (“Unity Drum”) where 8 members control a drum’s tilt by pulling ropes to bounce a ball. Key tasks include: 1. Calculating the drum’s tilt angle at t=0.1s based on force/timing inputs (Table 1), accounting for initial 11cm displacement. 2. Ensuring physics-based accurac...
-
[73]
expected number of reports received. . . is4×0.8 = 3.2
1 point (Avg. Score: 1.25):The problem involves coordinating multiple meteorological units (each with 1 primary and 2 secondary stations) to ensure reliable hourly weather data collection and full data sharing under strict communication constraints. Key challenges include managing transmission reliability (80% for secondaries, 100% for primaries), mes- sa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.