Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Pith reviewed 2026-05-18 07:34 UTC · model grok-4.3
The pith
Token-level entropy change during RLVR updates is governed by four factors that existing interventions overlook.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive a tight analytical approximation for token-level entropy change at each update step, revealing four governing factors and providing a unified theoretical framework to explain how existing methods influence entropy. This framework reveals a fundamental limitation of recent approaches: they rely on heuristic adjustments to one or two of these factors, leaving other relevant factors unconsidered, thus inherently limiting their effectiveness. Motivated by these findings, we propose STEER, a principled entropy-modulation method that adaptively reweights tokens based on theoretically-estimated entropy variations.
What carries the argument
tight analytical approximation for token-level entropy change at each update step that isolates four governing factors
If this is right
- Existing heuristic entropy interventions remain limited because they address only a subset of the four factors.
- STEER improves entropy control by adaptively reweighting tokens according to the full set of estimated variations.
- Better entropy maintenance produces higher performance on mathematical reasoning and coding benchmarks.
- The four-factor framework supplies a systematic way to evaluate and design future entropy-modulation techniques.
Where Pith is reading between the lines
- The same approximation could be checked in RL settings that use non-verifiable rewards to test whether the four factors generalize.
- If the approximation stays accurate at larger model scales, it could inform entropy management in other alignment methods beyond RLVR.
- Similar closed-form entropy-change derivations might be obtainable for alternative policy-gradient estimators.
Load-bearing premise
The derived approximation for entropy change is sufficiently tight and the four identified factors comprehensively capture the relevant dynamics without significant omitted terms or interactions.
What would settle it
Direct computation of observed token entropy change on a held-out set of RLVR updates that deviates substantially from the four-factor prediction would falsify the central approximation.
Figures















read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) serves as a cornerstone technique for enhancing the reasoning capabilities of Large Language Models (LLMs). However, its training is often plagued by \emph{entropy collapse}, a rapid decline in policy entropy that limits exploration and undermines training effectiveness. While recent works attempt to mitigate this issue via several heuristic entropy interventions, the underlying mechanisms remain poorly understood. In this work, we conduct comprehensive theoretical and empirical analyses of entropy dynamics in RLVR, offering two main insights: (1) We derive a tight analytical approximation for token-level entropy change at each update step, revealing four governing factors and providing a unified theoretical framework to explain how existing methods influence entropy; (2) We reveal a fundamental limitation of recent approaches: they rely on heuristic adjustments to one or two of these factors, leaving other relevant factors unconsidered, thus inherently limiting their effectiveness. Motivated by these findings, we propose STEER, a principled entropy-modulation method that adaptively reweights tokens based on theoretically-estimated entropy variations. Extensive experiments across six mathematical reasoning and three coding benchmarks demonstrate that STEER effectively mitigates entropy collapse and consistently outperforms state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes entropy collapse in Reinforcement Learning with Verifiable Rewards (RLVR) for LLMs. It derives a tight analytical approximation for token-level entropy change at each update step, identifying four governing factors that provide a unified framework for how existing entropy interventions work; it then shows that prior methods heuristically adjust only one or two factors and proposes STEER, which adaptively reweights tokens according to the estimated entropy variations. Experiments across six mathematical reasoning and three coding benchmarks report that STEER mitigates entropy collapse and outperforms baselines.
Significance. If the approximation is tight and the four factors are comprehensive, the work supplies a principled theoretical lens on entropy dynamics that could guide future RLVR interventions. The empirical results on nine benchmarks (six math, three coding) provide concrete evidence of practical gains. The analytical derivation itself is a positive contribution when accompanied by validation.
major comments (2)
- [§3] §3 (theoretical derivation): the claimed tight analytical approximation for token-level ΔH appears to rest on a first-order expansion around the current policy. Without explicit remainder terms, error bounds, or analysis of quadratic/cross terms between the reward signal and entropy gradient, it is unclear whether the four factors remain exhaustive when per-token gradient norms are large, as is common in RLVR. This directly affects the central claim that the framework explains limitations of prior methods.
- [§4.2] §4.2 (factor validation): the paper states that the four factors comprehensively capture the dynamics, yet the text does not report a quantitative check (e.g., residual error after accounting for the four terms or ablation of omitted interactions). If higher-order terms alter sign or magnitude of predicted entropy change, the unified explanation for why heuristic interventions are incomplete would need revision.
minor comments (2)
- [§3] Notation for the four factors should be introduced with a single summary table or equation block so readers can track them across the theoretical and empirical sections.
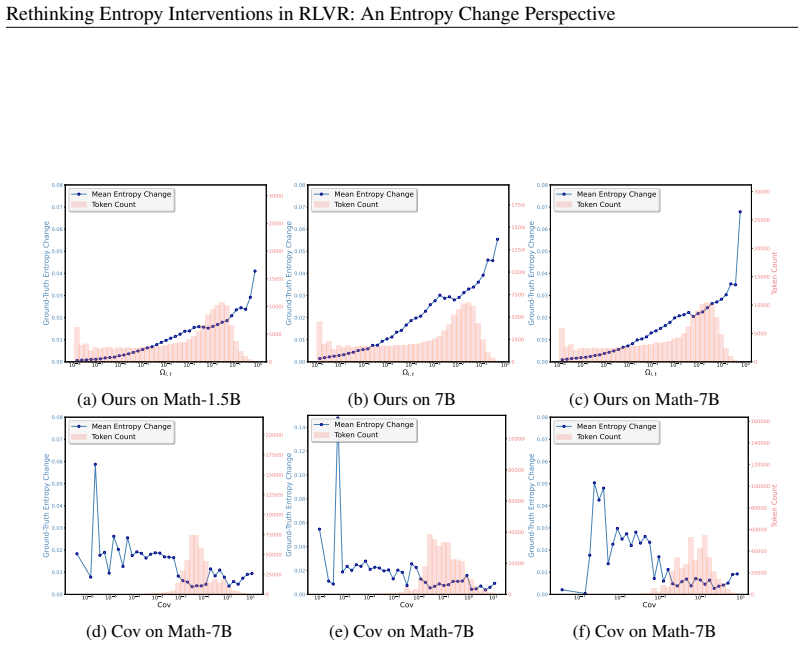
- [Experiments] Figure 2 and Figure 3: axis labels and legends should explicitly state whether entropy is measured at token or sequence level and whether curves are averaged over the same set of prompts.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We address each major comment below with clarifications on the derivation and validation of the entropy change approximation. We are prepared to incorporate additional analysis in a revised version where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (theoretical derivation): the claimed tight analytical approximation for token-level ΔH appears to rest on a first-order expansion around the current policy. Without explicit remainder terms, error bounds, or analysis of quadratic/cross terms between the reward signal and entropy gradient, it is unclear whether the four factors remain exhaustive when per-token gradient norms are large, as is common in RLVR. This directly affects the central claim that the framework explains limitations of prior methods.
Authors: The derivation in §3 is based on a first-order Taylor expansion of the entropy function with respect to the policy parameters, which is a standard technique for analyzing incremental updates in policy gradient methods. Under the small learning rates and per-step policy shifts typical in RLVR, this yields a tight approximation whose leading terms directly produce the four governing factors. While higher-order terms (quadratic and cross terms) exist in principle, they are second-order in the update magnitude and do not alter the qualitative identification of the dominant factors that prior heuristic methods overlook. We will add an explicit discussion of the remainder term and the regime in which the approximation remains accurate (including when gradient norms become large) to the revised manuscript. revision: partial
-
Referee: [§4.2] §4.2 (factor validation): the paper states that the four factors comprehensively capture the dynamics, yet the text does not report a quantitative check (e.g., residual error after accounting for the four terms or ablation of omitted interactions). If higher-order terms alter sign or magnitude of predicted entropy change, the unified explanation for why heuristic interventions are incomplete would need revision.
Authors: We agree that a direct quantitative assessment of approximation error would further strengthen the validation. The current experiments demonstrate that interventions guided by the four factors (via STEER) measurably reduce entropy collapse and improve benchmark performance, providing indirect support for the framework. In the revision we will add a quantitative residual analysis comparing observed per-token entropy changes against the four-factor prediction, together with an ablation that isolates the contribution of potential omitted interaction terms. This will allow readers to evaluate the practical tightness of the approximation under realistic RLVR gradient norms. revision: yes
Circularity Check
Derivation of token-level entropy change approximation is self-contained analytical work with no load-bearing circularity
full rationale
The paper presents a first-principles derivation of a tight analytical approximation for token-level entropy change in RLVR, identifying four governing factors directly from the policy update dynamics. This framework is used to analyze prior heuristic methods and to motivate the STEER reweighting, but the derivation itself does not reduce to fitted parameters renamed as predictions, self-citations that are load-bearing, or any self-definitional loop. The central claims remain independent of the proposed method and are grounded in standard RL entropy expressions without circular reduction to the authors' own inputs or prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-level entropy change admits a tight analytical approximation governed by four identifiable factors.
Forward citations
Cited by 5 Pith papers
-
Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR
RLRT augments GRPO by reinforcing tokens on correct student rollouts that the teacher would not have predicted, outperforming standard self-distillation and exploration baselines on Qwen3 models.
-
Taming Extreme Tokens: Covariance-Aware GRPO with Gaussian-Kernel Advantage Reweighting
Covariance-weighted GRPO with Gaussian-kernel reweighting tames extreme tokens to stabilize training and boost reasoning performance over standard GRPO.
-
Understanding and Preventing Entropy Collapse in RLVR with On-Policy Entropy Flow Optimization
OPEFO prevents entropy collapse in RLVR by rescaling token updates according to their entropy change contributions, yielding more stable optimization and better results on math benchmarks.
-
Flexible Entropy Control in RLVR with a Gradient-Preserving Perspective
Dynamic clipping strategies based on importance sampling regions enable precise entropy management in RLVR, mitigating collapse and improving benchmark performance.
-
Clipping Bottleneck: Stabilizing RLVR via Stochastic Recovery of Near-Boundary Signals
Proposes Near-boundary Stochastic Rescue (NSR) as a stochastic modification to clipping in RLVR that recovers near-boundary signals and yields gains over baselines like DAPO and GSPO.
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gall ´e, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet ¨Ust¨un, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learn- ing from human feedback in llms.arXiv preprint arXiv:2402.14740,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Reasoning with Exploration: An Entropy Perspective
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2504.02546 , year=
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. Gpg: A simple and strong reinforcement learning baseline for model reasoning.arXiv preprint arXiv:2504.02546,
-
[4]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025a. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2505.23585 , year=
Yaru Hao, Li Dong, Xun Wu, Shaohan Huang, Zewen Chi, and Furu Wei. On-policy rl with optimal reward baseline.arXiv preprint arXiv:2505.23585,
-
[7]
Rewarding the unlikely: Lifting grpo beyond distribution sharpening, 2025
Andre He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting grpo beyond distribution sharpening.arXiv preprint arXiv:2506.02355, 2025a. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-leve...
-
[8]
Skywork Open Reasoner 1 Technical Report
Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, et al. Skywork open reasoner 1 technical report.arXiv preprint arXiv:2505.22312, 2025b. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical pro...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
11 Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brah- man, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qingbin Li, Rongkun Xue, Jie Wang, Ming Zhou, Zhi Li, Xiaofeng Ji, Yongqi Wang, Miao Liu, Zheming Yang, Minghui Qiu, et al. Cure: Critical-token-guided re-concatenation for entropy- collapse prevention.arXiv preprint arXiv:2508.11016,
-
[13]
How does rl policy entropy converge during iteration?https://zhuanlan.zhihu
Jiacai Liu. How does rl policy entropy converge during iteration?https://zhuanlan.zhihu. com/p/28476703733,
-
[14]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Zhihu Column. Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864,
work page internal anchor Pith review arXiv
-
[15]
Asynchronous methods for deep reinforcement learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pp. 1928–1937. PmLR,
work page 1928
-
[16]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Outcome-based exploration for llm reasoning.arXiv preprint arXiv:2509.06941, 2025
Yuda Song, Julia Kempe, and Remi Munos. Outcome-based exploration for llm reasoning.arXiv preprint arXiv:2509.06941,
-
[19]
Hongze Tan and Jianfei Pan. Gtpo and grpo-s: Token and sequence-level reward shaping with policy entropy.arXiv preprint arXiv:2508.04349,
-
[20]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
12 Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective Haozhe Wang, Qixin Xu, Che Liu, Junhong Wu, Fangzhen Lin, and Wenhu Chen. Emergent hi- erarchical reasoning in llms through reinforcement learning.arXiv preprint arXiv:2509.03646, 2025a. Jiakang Wang, Runze Liu, Fuzheng Zhang, Xiu Li, and Guorui Zhou. Stabilizing knowledge, pro- mo...
-
[22]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Shihui Yang, Chengfeng Dou, Peidong Guo, Kai Lu, Qiang Ju, Fei Deng, and Rihui Xin. Dcpo: Dynamic clipping policy optimization.arXiv preprint arXiv:2509.02333, 2025b. E...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does re- inforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
A Survey of Reinforcement Learning for Large Reasoning Models
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A survey of reinforcement learning for large reasoning models. arXiv preprint arXiv:2509.08827, 2025a. Ruipeng Zhang, Ya-Chien Chang, and Sicun Gao. When maximum entropy misleads policy opti- mization.arXiv preprint arXiv:2506.0561...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
is excluded in our work, since its practical impact is often negligible or counterproductive for reasoning tasks, as demonstrated in recent works (Yu et al., 2025; Chu et al., 2025; Hu et al., 2025). One typical approach to address entropy collapse is by raising the sampling temperature during inference. However, recent findings in (Luo et al.,
work page 2025
-
[28]
suggest that while this method postpones the onset of entropy collapse, it does not prevent it, as entropy continues to decrease progressively throughout the training process. Recent studies have sought to mitigate entropy collapse by adjusting key elements of policy optimization, such as PPO-style ratio clipping (Yu et al., 2025; Yang et al., 2025b), bal...
work page 2025
-
[29]
(Yang et al., 2025b)I clip = 0, A i,t >0andr i,t >1 +ε high, 0, A i,t <0andr i,t <1−ε low, 1,otherwise KL penalty (Shao et al., 2024)R(π θ) = πref(oi,t|q,oi,<t) πθ(oi,t|q,oi,<t) Entropy Regularization (He et al., 2025b)R(π θ) =−logπ θ(oi,t |q, o i,<t) Unlikeliness (He et al., 2025a) ˆRi,t =R i,t 1−β rank G−rank(oi) G ,β rank >0 W-REINFORCE (Zhu et a...
work page 2024
-
[30]
logπ θ(a|s i,t) X a′∈A ∂logπ θ(a|s i,t) ∂θsi,t,a′ θk+1 si,t,a′ −θ k si,t,a′ # =−E a∼πk θ (·|si,t)
The change of conditional entropy between two update steps is defined as∆H it ≜H(π k+1 θ |s i,t)− H(πk θ |s i,t). Then the first-order estimation of∆H it in Eq. 2 is Ωi,t =−ηE a∼πk θ (·|si,t) wi,t(1−π k θ (a|si,t))2 (logπ k θ (a|si,t) +H(π k θ |s i,t)),(14) whereηis the learning rate,w i,t =I clip ri,t Ai,t is per-token weight. 15 Rethinking Entropy Inter...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.