GroupRank: A Groupwise Paradigm for Effective and Efficient Passage Reranking with LLMs
Pith reviewed 2026-05-17 23:38 UTC · model grok-4.3
The pith
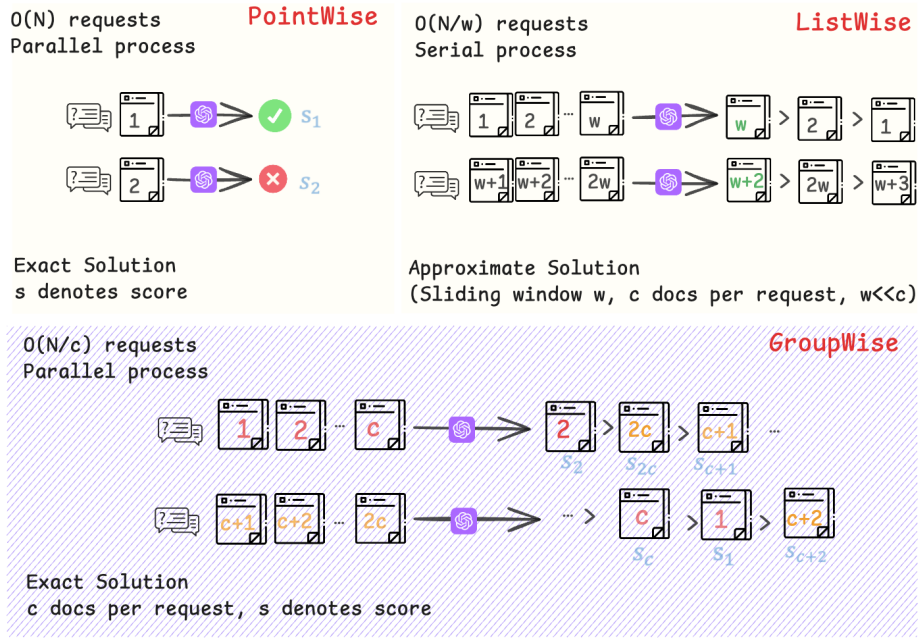
GroupRank proposes a groupwise reranking method for LLMs that fuses pointwise and listwise signals to achieve higher accuracy and faster inference in passage retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GroupRank is a groupwise paradigm that processes passages in manageable groups to capture inter-document comparisons efficiently. It employs an answer-free data synthesis pipeline to fuse pointwise signals with listwise rankings for creating training samples. These are used for supervised fine-tuning and then reinforcement learning optimized by a group-ranking reward with ranking-utility and group-alignment components. This synergy improves document ordering and score calibration, leading to superior performance on retrieval benchmarks.
What carries the argument
The group-ranking reward consisting of ranking-utility and group-alignment terms, which together optimize ordering and calibration in the groupwise setting.
If this is right
- GroupRank achieves a state-of-the-art 65.2 NDCG@10 on the BRIGHT benchmark.
- It surpasses baselines by 2.1 points on the R2MED dataset.
- The method provides a 6.4 times inference speedup compared to previous approaches.
- Document ordering and score calibration are optimized to better reflect query-document relevance.
Where Pith is reading between the lines
- Applying groupwise processing could extend to other LLM tasks requiring comparison across multiple items, such as summarization or recommendation.
- Scaling the group size might further improve performance if hardware allows larger contexts without latency penalties.
- The synthesis pipeline could be adapted for other ranking problems where labeled data is scarce.
- Production search engines might integrate this to handle more complex user queries with reasonable compute costs.
Load-bearing premise
The answer-free data synthesis pipeline successfully fuses pointwise and listwise signals into high-quality training data, and the group-ranking reward produces well-calibrated orderings without introducing bias or overfitting.
What would settle it
Running GroupRank on a held-out test set with queries that demand broad context and checking if the accuracy gains disappear while the speedup remains.
Figures


read the original abstract
Large Language Models (LLMs) have emerged as powerful tools for passage reranking in information retrieval, leveraging their superior reasoning capabilities to address the limitations of conventional models on complex queries. However, current LLM-based reranking paradigms are fundamentally constrained by an efficiency-accuracy trade-off: (1) pointwise methods are efficient but ignore inter-document comparison, yielding suboptimal accuracy; (2) listwise methods capture global context but suffer from context-window constraints and prohibitive inference latency. To address these issues, we propose GroupRank, a novel paradigm that balances flexibility and context awareness. To unlock the full potential of groupwise reranking, we propose an answer-free data synthesis pipeline that fuses local pointwise signals with global listwise rankings. These samples facilitate supervised fine-tuning and reinforcement learning, with the latter guided by a specialized group-ranking reward comprising ranking-utility and group-alignment. These complementary components synergistically optimize document ordering and score calibration to reflect intrinsic query-document relevance. Experimental results show GroupRank achieves a state-of-the-art 65.2 NDCG@10 on BRIGHT and surpasses baselines by 2.1 points on R2MED, while delivering a 6.4$\times$ inference speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GroupRank, a novel groupwise paradigm for LLM-based passage reranking that aims to balance efficiency and accuracy. It introduces an answer-free data synthesis pipeline fusing pointwise and listwise signals to generate training data for supervised fine-tuning and reinforcement learning, with the latter using a group-ranking reward that combines ranking-utility and group-alignment terms. The central empirical claims are state-of-the-art performance of 65.2 NDCG@10 on BRIGHT, a 2.1-point improvement over baselines on R2MED, and a 6.4× inference speedup.
Significance. If the results and ablations hold under detailed scrutiny, GroupRank could meaningfully advance practical LLM reranking in information retrieval by providing a scalable middle ground between pointwise efficiency and listwise context modeling. The emphasis on answer-free synthesis and a composite reward for ordering plus calibration is a constructive contribution to the efficiency-accuracy trade-off literature.
major comments (2)
- [Abstract] Abstract: the reported benchmark numbers (65.2 NDCG@10 on BRIGHT, 2.1-point gain on R2MED) are presented without any accompanying experimental details, baselines, error bars, statistical significance tests, or ablation studies. This absence directly undermines evaluation of the central claim that the synthesis pipeline and group-ranking reward are responsible for the gains rather than data-construction artifacts.
- [Method overview / data synthesis] Data synthesis pipeline (as described in the abstract and method overview): the fusion of pointwise and listwise signals is asserted to produce high-quality, unbiased training samples, yet no mechanism details, bias-mitigation steps, or isolating ablations are supplied. Because this pipeline is load-bearing for both the SFT and RL stages that produce the reported ordering improvements, the lack of verification leaves the attribution of the 6.4× speedup and accuracy gains insecure.
minor comments (1)
- [Abstract] The speedup is written as 6.4$×$; this LaTeX fragment may not render cleanly in all formats and should be replaced by the Unicode × or proper math mode.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential of GroupRank to advance practical LLM reranking. We have carefully revised the manuscript to address the concerns regarding experimental transparency and the data synthesis pipeline, while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported benchmark numbers (65.2 NDCG@10 on BRIGHT, 2.1-point gain on R2MED) are presented without any accompanying experimental details, baselines, error bars, statistical significance tests, or ablation studies. This absence directly undermines evaluation of the central claim that the synthesis pipeline and group-ranking reward are responsible for the gains rather than data-construction artifacts.
Authors: We agree that the abstract's brevity can limit immediate assessment of the claims. The full manuscript already contains the requested details in Sections 4 (experimental setup and baselines) and 5 (ablations, error bars, and results). To strengthen the abstract itself, we have revised it to include a concise reference to the evaluation protocol, the use of statistical significance testing, and the presence of ablations that isolate the contributions of the synthesis pipeline and group-ranking reward. We have additionally inserted paired statistical significance tests for the reported gains in the main results tables. revision: partial
-
Referee: [Method overview / data synthesis] Data synthesis pipeline (as described in the abstract and method overview): the fusion of pointwise and listwise signals is asserted to produce high-quality, unbiased training samples, yet no mechanism details, bias-mitigation steps, or isolating ablations are supplied. Because this pipeline is load-bearing for both the SFT and RL stages that produce the reported ordering improvements, the lack of verification leaves the attribution of the 6.4× speedup and accuracy gains insecure.
Authors: We acknowledge that additional explicit documentation of the pipeline would improve verifiability. In the revised manuscript we have expanded Section 3.2 with the precise fusion mechanism (including prompting templates, scoring aggregation rules, and sample selection criteria), a dedicated paragraph on bias mitigation (query diversification, relevance calibration, and duplicate filtering), and new isolating ablation experiments that separately quantify the contribution of the pointwise and listwise signals to both NDCG@10 and inference latency. These additions directly support attribution of the observed accuracy and speedup gains to the proposed components rather than artifacts. revision: yes
Circularity Check
No circularity: performance metrics presented as independent empirical outcomes
full rationale
The paper introduces GroupRank as a groupwise reranking paradigm, describes an answer-free data synthesis pipeline that fuses pointwise and listwise signals, applies supervised fine-tuning plus RL with a composite group-ranking reward, and reports benchmark results (65.2 NDCG@10 on BRIGHT, 2.1-point gain on R2MED, 6.4× speedup). These outcomes are framed as experimental measurements on external datasets rather than quantities obtained by fitting parameters inside the same equations or by self-citation chains that presuppose the target result. No load-bearing derivation step reduces a claimed prediction to its own inputs by construction, and the central claims rest on observable performance rather than definitional equivalence. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- group-ranking reward weights
Forward citations
Cited by 3 Pith papers
-
LeanSearch v2: Global Premise Retrieval for Lean 4 Theorem Proving
LeanSearch v2 recovers 46.1% of ground-truth premise groups on research-level Mathlib theorems and raises fixed-loop proof success from 4% to 20% via embedding-reranker plus iterative sketch-retrieve-reflect retrieval.
-
LeanSearch v2: Global Premise Retrieval for Lean 4 Theorem Proving
LeanSearch v2 recovers 46.1% of ground-truth premise groups for research-level Lean 4 theorems within 10 candidates and raises fixed-loop proof success to 20%.
-
A Survey of Reasoning-Intensive Retrieval: Progress and Challenges
A survey that categorizes RIR benchmarks by domain and modality, proposes a taxonomy for integrating reasoning into retrieval pipelines, and outlines key challenges.
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” 2024. [Online]. Available: https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W. tau Yih, T. Rockt ¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” 2021. [Online]. Available: https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
A survey on knowledge-oriented retrieval-augmented generation,
M. Cheng, Y . Luo, J. Ouyang, Q. Liu, H. Liu, L. Li, S. Yu, B. Zhang, J. Cao, J. Ma, D. Wang, and E. Chen, “A survey on knowledge-oriented retrieval-augmented generation,” 2025. [Online]. Available: https://arxiv.org/abs/2503.10677
-
[4]
Similarity is not all you need: Endowing retrieval augmented generation with multi layered thoughts,
C. Gan, D. Yang, B. Hu, H. Zhang, S. Li, Z. Liu, Y . Shen, L. Ju, Z. Zhang, J. Guet al., “Similarity is not all you need: Endowing retrieval augmented generation with multi layered thoughts,”arXiv preprint arXiv:2405.19893, 2024
-
[5]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning
D. G. DeepSeek-AI, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xuet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.” arxiv,”Preprint posted online on, vol. 22, pp. 13–14, 2025
work page 2025
-
[7]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Yang, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
F. Xu, Q. Hao, Z. Zong, J. Wang, Y . Zhang, J. Wang, X. Lan, J. Gong, T. Ouyang, F. Meng, C. Shao, Y . Yan, Q. Yang, Y . Song, S. Ren, X. Hu, Y . Li, J. Feng, C. Gao, and Y . Li, “Towards large reasoning models: A survey of reinforced reasoning with large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2501.09686
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Polyrag: Integrating polyviews into retrieval-augmented generation for medical applications,
C. Gan, D. Yang, B. Huet al., “Polyrag: Integrating polyviews into retrieval-augmented generation for medical applications,”
-
[11]
Available: https://arxiv.org/abs/2504.14917
[Online]. Available: https://arxiv.org/abs/2504.14917
-
[12]
Retrieval-augmented generation for knowledge- intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge- intensive nlp tasks,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associa...
work page 2020
-
[13]
Learning to plan for retrieval-augmented large language models from knowledge graphs,
J. Wang, M. Chen, B. Hu, D. Yanget al., “Learning to plan for retrieval-augmented large language models from knowledge graphs,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 7813–7835. [Online]. Availab...
work page 2024
-
[14]
Retrieval-based language models and applications,
A. Asai, S. Min, Z. Zhong, and D. Chen, “Retrieval-based language models and applications,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts), Y .-N. V . Chen, M. Margot, and S. Reddy, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 41–46. [Online]. Avai...
work page 2023
-
[15]
Hirag: Hierarchical-thought instruction-tuning retrieval-augmented generation,
Y . Jiao, Z. Tan, D. Yang, D. Sun, J. Feng, Y . Shen, J. Wang, and P. Wei, “Hirag: Hierarchical-thought instruction-tuning retrieval-augmented generation,” 2025. [Online]. Available: https://arxiv.org/abs/2507.05714
-
[16]
Z. Tan, Y . Jiao, D. Yang, L. Liuet al., “Prgb benchmark: A robust placeholder-assisted algorithm for benchmarking retrieval-augmented generation,” 2025. [Online]. Available: https://arxiv.org/abs/2507.22927
-
[17]
A survey on rag meeting llms: Towards retrieval-augmented large language models,
W. Fan, Y . Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, and Q. Li, “A survey on rag meeting llms: Towards retrieval-augmented large language models,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 6491–6501. [Online]. Available: ...
-
[18]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024. [Online]. Available: https://aclanthology.org/2024.tacl-1.9/
work page 2024
-
[19]
A. Abdallah, J. Mozafari, B. Piryani, M. M. Abdelgwad, and A. Jatowt, “DynRank: Improve passage retrieval with dynamic zero-shot prompting based on question classification,” inProceedings of the 31st International Conference on Computational Linguistics, O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, Eds. Abu Dhabi, ...
work page 2025
-
[20]
Rankrag: unifying context ranking with retrieval-augmented generation in llms,
Y . Yu, W. Ping, Z. Liu, B. Wang, J. You, C. Zhang, M. Shoeybi, and B. Catanzaro, “Rankrag: unifying context ranking with retrieval-augmented generation in llms,” inProceedings of the 38th International Conference on Neural Information Processing Systems, ser. NIPS ’24. Red Hook, NY , USA: Curran Associates Inc., 2025
work page 2025
-
[21]
Rankt5: Fine-tuning t5 for text ranking with ranking losses,
H. Zhuang, Z. Qin, R. Jagerman, K. Hui, J. Ma, J. Lu, J. Ni, X. Wang, and M. Bendersky, “Rankt5: Fine-tuning t5 for text ranking with ranking losses,” 2022. [Online]. Available: https://arxiv.org/abs/2210.10634
-
[22]
Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze!
R. Pradeep, S. Sharifymoghaddam, and J. Lin, “Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze!”
-
[23]
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze!
[Online]. Available: https://arxiv.org/abs/2312.02724
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Rank-r1: Enhancing reasoning in llm-based document rerankers via reinforcement learning,
S. Zhuang, X. Ma, B. Koopman, J. Lin, and G. Zuccon, “Rank-r1: Enhancing reasoning in llm-based document rerankers via reinforcement learning,” 2025. [Online]. Available: https: //arxiv.org/abs/2503.06034
-
[25]
Y . Cai, Y . Zhang, D. Long, M. Li, P. Xie, and W. Zheng, “Erank: Fusing supervised fine-tuning and reinforcement learning for effective and efficient text reranking,” 2025. [Online]. Available: https://arxiv.org/abs/2509.00520
-
[26]
Tfrank: Think-free reasoning enables practical pointwise llm ranking,
Y . Fan, X. Chen, D. Ye, J. Liu, H. Liang, J. Ma, B. He, Y . Sun, and T. Ruan, “Tfrank: Think-free reasoning enables practical pointwise llm ranking,” 2025. [Online]. Available: https://arxiv.org/abs/2508.09539
-
[27]
Coranking: Collaborative ranking with small and large ranking agents,
W. Liu, X. Ma, Y . Zhu, L. Su, S. Wang, D. Yin, and Z. Dou, “Coranking: Collaborative ranking with small and large ranking agents,” 2025. [Online]. Available: https: //arxiv.org/abs/2503.23427
-
[28]
Large language models are effective text rankers with pairwise ranking prompting,
Z. Qin, R. Jagerman, K. Hui, H. Zhuang, J. Wu, L. Yan, J. Shen, T. Liu, J. Liu, D. Metzler, X. Wang, and M. Bendersky, “Large language models are effective text rankers with pairwise ranking prompting,” inFindings of the Association for Computational Linguistics: NAACL 2024, K. Duh, H. Gomez, and S. Bethard, Eds. Mexico City, Mexico: Association for Compu...
work page 2024
-
[29]
Tongsearch-qr: Reinforced query reasoning for retrieval,
X. Qin, J. Bai, J. Li, Z. Jia, and Z. Zheng, “Tongsearch-qr: Reinforced query reasoning for retrieval,” 2025. [Online]. Available: https://arxiv.org/abs/2506.11603
-
[30]
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
W. Liu, X. Ma, W. Sun, Y . Zhu, Y . Li, D. Yin, and Z. Dou, “Reasonrank: Empowering passage ranking with strong reasoning ability,” 2025. [Online]. Available: https: //arxiv.org/abs/2508.07050
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Zero-shot listwise document reranking with a large language model,
X. Ma, X. Zhang, R. Pradeep, and J. Lin, “Zero-shot listwise document reranking with a large language model,” 2023. [Online]. Available: https://arxiv.org/abs/2305.02156
-
[32]
Diver: A multi-stage approach for reasoning-intensive information retrieval,
M. Long, D. Sun, D. Yang, J. Wang, Y . Shen, J. Wang, P. Wei, J. Gu, and J. Wang, “Diver: A multi-stage approach for reasoning-intensive information retrieval,” 2025. [Online]. Available: https://arxiv.org/abs/2508.07995
-
[33]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
[Online]. Available: https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Bright: A realistic and challenging benchmark for reasoning-intensive retrieval,
H. Su, H. Yen, M. Xia, W. Shi, N. Muennighoff, H. yu Wang, H. Liu, Q. Shi, Z. S. Siegel, M. Tang, R. Sun, J. Yoon, S. O. Arik, D. Chen, and T. Yu, “Bright: A realistic and challenging benchmark for reasoning-intensive retrieval,” 2025. [Online]. Available: https://arxiv.org/abs/2407.12883
-
[36]
R2MED: A Benchmark for Reasoning-Driven Medical Retrieval
L. Li, X. Zhou, and Z. Liu, “R2med: A benchmark for reasoning-driven medical retrieval,” 2025. [Online]. Available: https://arxiv.org/abs/2505.14558
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
N. Thakur, N. Reimers, A. R ¨uckl´e, A. Srivastava, and I. Gurevych, “Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models,” 2021. [Online]. Available: https://arxiv.org/abs/2104.08663
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Rank-k: Test-time reasoning for listwise reranking,
E. Yang, A. Yates, K. Ricci, O. Weller, V . Chari, B. V . Durme, and D. Lawrie, “Rank-k: Test-time reasoning for listwise reranking,”
-
[39]
Available: https://arxiv.org/abs/2505.14432
[Online]. Available: https://arxiv.org/abs/2505.14432
-
[40]
Ms-swift: A comprehensive framework for training and deploying large language and multimodal models,
M. Community, “Ms-swift: A comprehensive framework for training and deploying large language and multimodal models,”
-
[41]
Available: https://github.com/modelscope/ ms-swift
[Online]. Available: https://github.com/modelscope/ ms-swift
-
[42]
HybridFlow: A Flexible and Efficient RLHF Framework
G. Sheng, C. Zhang, Z. Yeet al., “Hybridflow: A flexible and efficient rlhf framework,”arXiv preprint, 2024. [Online]. Available: https://arxiv.org/pdf/2409.19256
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” 2021. [Online]. Available: https: //arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
D. Sun, D. Yang, Y . Shen, Y . Jiaoet al., “Hanrag: Heuristic accurate noise-resistant retrieval-augmented generation for multi-hop question answering,” 2025. [Online]. Available: https://arxiv.org/abs/2509.09713 X. APENDIX Prompt 1: Prompt of Listwise Labeling use Gemini2.5-Pro You are an expert passage reranker. Your task is to rank the provided passage...
-
[45]
**Understand the Query:** Identify the core question or intent behind the user’s query
-
[46]
A passage is **valuable** if it directly and effectively helps answer the query
**Evaluate Passages:** Think step-by-step to assess each passage. A passage is **valuable** if it directly and effectively helps answer the query. It is **not valuable** if it merely discusses similar topics without providing a direct answer
-
[47]
* Then, output a single JSON array containing the integer IDs of **all** provided passages
**Rank & Output:** * First, briefly explain your reasoning process for the ranking. * Then, output a single JSON array containing the integer IDs of **all** provided passages. The array must be sorted from the most valuable passage to the least valuable. The final output should look like this: <Your reasoning here> “‘json ...integeridshere... “‘ The user’...
-
[48]
PRIMARY: Usefulness & Helpfulness - Does the document provide actionable information, solutions, or direct answers that help address the user’s needs?
-
[49]
SECONDARY: Relevance - Does the document contain information related to the query topic? Evaluation Process:
-
[50]
First, identify the user’s core intent and what kind of help they need from the query
-
[51]
For each document, assess: - How directly it addresses the user’s intent - What actionable information or answers it provides - How much it helps solve the user’s problem or need
-
[52]
Compare documents against each other to ensure proper ranking
-
[53]
Assign scores that reflect the relative usefulness ranking Scoring Scale (0-10): - 9-10: Extremely helpful, directly answers the query with actionable information - 7-8: Very helpful, provides substantial useful information for the query - 5-6: Moderately helpful, contains some useful information but incomplete - 3-4: Minimally helpful, limited useful inf...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.