Recognition: no theorem link
FastDSAC: Unlocking the Potential of Maximum Entropy RL in High-Dimensional Humanoid Control
Pith reviewed 2026-05-15 12:14 UTC · model grok-4.3
The pith
FastDSAC shows maximum entropy RL can match or beat deterministic policies in high-dimensional humanoid control
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FastDSAC unlocks maximum entropy stochastic policies for high-dimensional humanoid control by using dimension-wise entropy modulation to dynamically allocate the exploration budget and a continuous distributional critic to deliver accurate value estimates free of high-dimensional overestimation and quantization artifacts, yielding state-of-the-art results for stochastic policies that compete with or exceed deterministic baselines.
What carries the argument
Dimension-wise Entropy Modulation (DEM) that reallocates exploration across dimensions, combined with a continuous distributional critic that mitigates overestimation and discretization artifacts during value estimation.
If this is right
- High-dimensional stochastic policies become viable alternatives to deterministic policy gradients in humanoid control settings.
- Maximum entropy RL can achieve competitive or superior sample efficiency on challenging continuous control benchmarks.
- Performance advantages appear on specific difficult tasks such as basketball and hard balance maintenance.
Where Pith is reading between the lines
- The critic and modulation design may transfer to other high-dimensional RL problems that suffer from similar exploration and estimation issues.
- Real-robot deployment could benefit from the improved adaptability that entropy-driven exploration provides once the method is stabilized.
- Further reductions in the need for deterministic baselines may occur if the same principles are applied to related entropy-regularized algorithms.
Load-bearing premise
That dimension-wise entropy modulation and the continuous distributional critic together remove the main barriers of the curse of dimensionality and overestimation in maximum entropy RL without creating fresh instabilities or demanding extensive per-task retuning.
What would settle it
A set of training runs on the Basketball or Balance Hard tasks in which FastDSAC fails to produce the reported performance gains over deterministic baselines or shows increased instability relative to them.
Figures
















read the original abstract
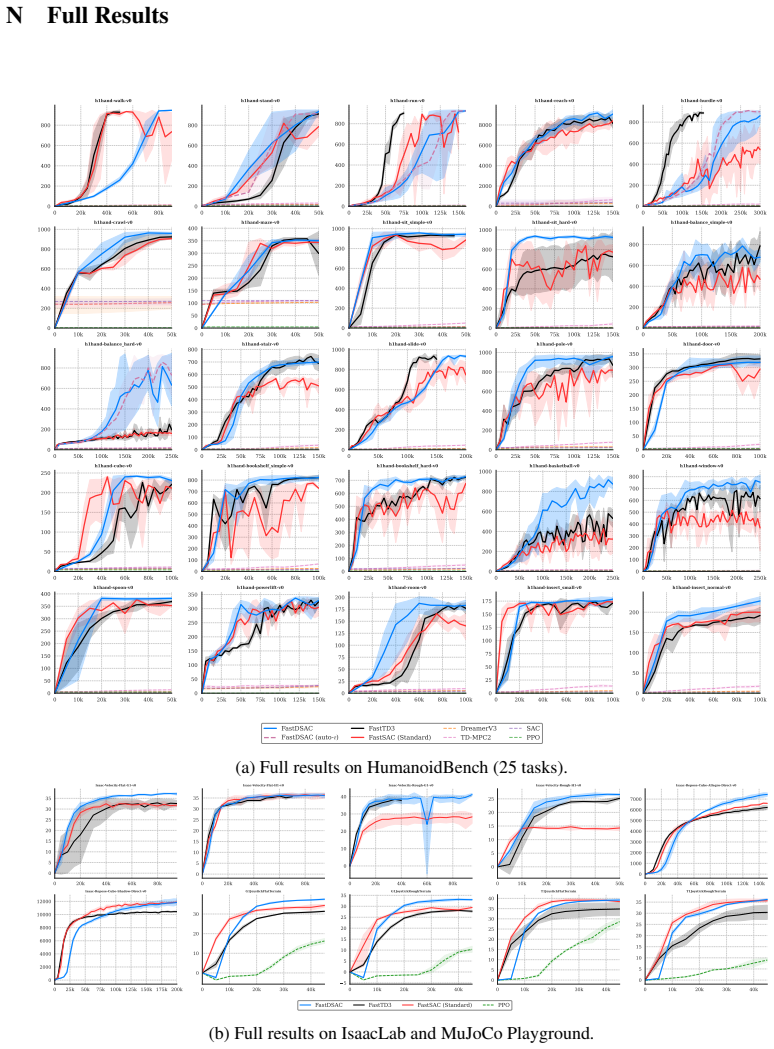
Scaling Maximum Entropy Reinforcement Learning (RL) to high-dimensional humanoid control remains a fundamental challenge, as the ''curse of dimensionality'' induces severe exploration inefficiency and training instability. Consequently, highly optimized deterministic policy gradients currently dominate high-throughput regimes. We address this limitation with FastDSAC, a framework that effectively unlocks the potential of maximum entropy stochastic policies for complex continuous control. We introduce Dimension-wise Entropy Modulation (DEM) to dynamically redistribute the exploration budget, alongside a continuous distributional critic tailored to ensure accurate value estimation by mitigating both high-dimensional overestimation and discrete quantization artifacts. Extensive evaluations on HumanoidBench and a diverse set of continuous control tasks demonstrate that FastDSAC establishes state-of-the-art performance for high-dimensional stochastic policies on the evaluated benchmarks. Our method is competitive with and often outperforms strong deterministic baselines, with gains of 180% and 350% on the challenging Basketball and Balance Hard tasks, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FastDSAC, a framework for scaling maximum-entropy RL to high-dimensional humanoid control. It proposes Dimension-wise Entropy Modulation (DEM) to dynamically allocate exploration and a continuous distributional critic to reduce overestimation and quantization errors. Evaluations on HumanoidBench and other continuous-control benchmarks claim state-of-the-art results among stochastic policies, with the method being competitive with or outperforming strong deterministic baselines (gains of 180% on Basketball and 350% on Balance Hard).
Significance. If the reported gains prove robust, the work would be significant because it supplies concrete evidence that maximum-entropy stochastic policies can match or exceed deterministic policy gradients on challenging high-dimensional tasks, potentially reopening exploration of entropy-regularized methods for robotics where robustness to uncertainty is valuable.
major comments (1)
- [Abstract and §4] Abstract and §4 (Experiments): the central SOTA and percentage-gain claims (180% Basketball, 350% Balance Hard) are presented without accompanying ablation studies that isolate the contribution of DEM versus the distributional critic, without reported standard deviations or statistical tests across the stated multiple seeds, and without implementation-level details (network architectures, hyper-parameter schedules, or code release). These omissions make the empirical support for the headline claims unverifiable from the supplied text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical verification. We address the major comment below and will revise the manuscript accordingly to improve verifiability.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central SOTA and percentage-gain claims (180% Basketball, 350% Balance Hard) are presented without accompanying ablation studies that isolate the contribution of DEM versus the distributional critic, without reported standard deviations or statistical tests across the stated multiple seeds, and without implementation-level details (network architectures, hyper-parameter schedules, or code release). These omissions make the empirical support for the headline claims unverifiable from the supplied text.
Authors: We agree that the current presentation lacks sufficient detail to allow full verification. In the revised version we will add ablation studies that separately disable DEM and the continuous distributional critic to quantify their individual contributions. All reported results will include mean performance plus standard deviations over at least five independent random seeds, together with appropriate statistical significance tests. Network architectures, hyper-parameter schedules, and training details will be expanded in a new appendix section. We will also release the full implementation code upon acceptance. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents FastDSAC as an empirical framework introducing Dimension-wise Entropy Modulation (DEM) and a continuous distributional critic to address exploration and overestimation issues in high-dimensional maximum-entropy RL. No equations, derivations, or load-bearing steps are described that reduce by construction to fitted inputs, self-definitions, or self-citation chains; the central claims rest on explicit update rules and benchmark results (HumanoidBench, multiple seeds) that remain externally falsifiable. The performance gains are reported as experimental outcomes rather than forced by internal renaming or uniqueness theorems imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Td-mpc2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations, 2024
work page 2024
-
[2]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Hu- manoidbench: Simulated humanoid benchmark for whole-body locomotion and manipulation
Carmelo Sferrazza, Dun-Ming Huang, Xingyu Lin, Youngwoon Lee, and Pieter Abbeel. Hu- manoidbench: Simulated humanoid benchmark for whole-body locomotion and manipulation. InRobotics: Science and Systems, 2024
work page 2024
-
[4]
Tdmpbc: Self-imitative reinforcement learning for humanoid robot control
Zifeng Zhuang, Diyuan Shi, Runze Suo, Xiao He, Hongyin Zhang, Ting Wang, Shangke Lyu, and Donglin Wang. Tdmpbc: Self-imitative reinforcement learning for humanoid robot control. arXiv preprint arXiv:2502.17322, 2025
-
[5]
Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control.arXiv preprint arXiv:2505.22642, 2025
-
[6]
Learning to walk in minutes using massively parallel deep reinforcement learning
Nikita Rudin, David Hoeller, Philipp Reist, and Marco Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InProceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 91–100. PMLR, 2022. URLhttps://proceedings.mlr.press/v164/rudin22a.html
work page 2022
-
[7]
Champion-level drone racing using deep reinforcement learning.Nature, 620(7976):982–987, 2023
Elia Kaufmann, Leonard Bauersfeld, Antonio Loquercio, Matthias Müller, Vladlen Koltun, and Davide Scaramuzza. Champion-level drone racing using deep reinforcement learning.Nature, 620(7976):982–987, 2023
work page 2023
-
[8]
Parallelq-learning: Scaling off-policy reinforcement learning under massively parallel simulation
Zechu Li, Tao Chen, Zhang-Wei Hong, Anurag Ajay, and Pulkit Agrawal. Parallelq-learning: Scaling off-policy reinforcement learning under massively parallel simulation. InInternational Conference on Machine Learning, pages 19440–19459. PMLR, 2023
work page 2023
-
[9]
Speeding up sac with massively parallel simulation
Arth Shukla. Speeding up sac with massively parallel simulation. https://arthshukla.substack.com, Mar 2025. URL https://arthshukla.substack. com/p/speeding-up-sac-with-massively-parallel
work page 2025
-
[10]
Simplifying deep temporal difference learning
Matteo Gallici, Mattie Fellows, Benjamin Ellis, Bartomeu Pou, Ivan Masmitja, Jakob Nicolaus Foerster, and Mario Martin. Simplifying deep temporal difference learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=7IzeL0kflu
work page 2025
-
[11]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Anto- nio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Kevin Zakka, Baruch Tabanpour, Qiayuan Liao, Mustafa Haiderbhai, Samuel Holt, Jing Yuan Luo, Arthur Allshire, Erik Frey, Koushil Sreenath, Lueder A Kahrs, et al. Mujoco playground. arXiv preprint arXiv:2502.08844, 2025
-
[13]
FlashSAC: Fast and Stable Off-Policy Reinforcement Learning for High-Dimensional Robot Control
Donghu Kim, Youngdo Lee, Minho Park, Kinam Kim, I Made Aswin Nahendra, Takuma Seno, Sehee Min, Daniel Palenicek, Florian V ogt, Danica Kragic, Jan Peters, Jaegul Choo, and Hojoon Lee. Flashsac: Fast and stable off-policy reinforcement learning for high-dimensional robot control.arXiv preprint arXiv:2604.04539, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
work page 2018
-
[15]
Mario Köppen. The curse of dimensionality. In5th Online World Conference on Soft Computing in Industrial Applications (WSC5), volume 1, pages 4–8, 2000
work page 2000
-
[16]
On high-dimensional action selection for deep reinforcement learning, 2024
Wenbo Zhang and Hengrui Cai. On high-dimensional action selection for deep reinforcement learning, 2024. URLhttps://openreview.net/forum?id=rto6aU453A
work page 2024
-
[17]
Pierre Schumacher, Thomas Geijtenbeek, Vittorio Caggiano, Vikash Kumar, Syn Schmitt, Georg Martius, and Daniel F. B. Haeufle. Natural and robust walking using reinforcement learning without demonstrations in high-dimensional musculoskeletal models, 2023. URL https://arxiv.org/abs/2309.02976
-
[18]
Scalable exploration for high-dimensional continuous control via value-guided flow, 2026
Yunyue Wei, Chenhui Zuo, and Yanan Sui. Scalable exploration for high-dimensional continuous control via value-guided flow, 2026. URLhttps://arxiv.org/abs/2601.19707
-
[19]
Zilin Kang, Chonghua Liao, Tingqiang Xu, and Huazhe Xu. Entropy regularizing activation: Boosting continuous control, large language models, and image classification with activation as entropy constraints. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=Cqdsw3yteP
work page 2026
- [20]
-
[21]
Vlearn: Off-policy learning with efficient state-value function estimation, 2024
Gerhard Neumann, Fabian Otto, Philipp Becker, and Ngo Anh Vien. Vlearn: Off-policy learning with efficient state-value function estimation, 2024. URL https://arxiv.org/abs/2403. 04453
work page 2024
-
[22]
Coarse-to-fine q-network with action sequence for data- efficient reinforcement learning, 2025
Younggyo Seo and Pieter Abbeel. Coarse-to-fine q-network with action sequence for data- efficient reinforcement learning, 2025. URLhttps://arxiv.org/abs/2411.12155
-
[23]
Arsenii Kuznetsov, Pavel Shvechikov, Alexander Grishin, and Dmitry Vetrov. Controlling overestimation bias with truncated mixture of continuous distributional quantile critics, 2020. URLhttps://arxiv.org/abs/2005.04269
-
[24]
Li, Yangang Ren, Qi Sun, and B
Jingliang Duan, Yang Guan, S. Li, Yangang Ren, Qi Sun, and B. Cheng. Distributional soft actor-critic: Off-policy reinforcement learning for addressing value estimation errors.IEEE Transactions on Neural Networks and Learning Systems, 33:6584–6598, 2020
work page 2020
-
[25]
Simplicial embeddings improve sample efficiency in actor-critic agents,
Johan Obando-Ceron, Walter Mayor, Samuel Lavoie, Scott Fujimoto, Aaron Courville, and Pablo Samuel Castro. Simplicial embeddings improve sample efficiency in actor-critic agents,
- [26]
-
[27]
Distributional soft actor-critic with three refinements
Jingliang Duan, Wenxuan Wang, Liming Xiao, Jiaxin Gao, Shengbo Eben Li, Chang Liu, Ya-Qin Zhang, Bo Cheng, and Keqiang Li. Distributional soft actor-critic with three refinements. IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(5):3935–3946, 2025. doi: 10.1109/TPAMI.2025.3537087
-
[28]
A Distributional Perspective on Reinforcement Learning
Marc G. Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforce- ment learning, 2017. URLhttps://arxiv.org/abs/1707.06887. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Learning sim-to-real humanoid locomotion in 15 minutes, 2025
Younggyo Seo, Carmelo Sferrazza, Juyue Chen, Guanya Shi, Rocky Duan, and Pieter Abbeel. Learning sim-to-real humanoid locomotion in 15 minutes, 2025. URL https://arxiv.org/ abs/2512.01996
-
[30]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, 2023
work page 2023
-
[31]
Bigger, regularized, optimistic: scaling for compute and sample-efficient continuous control
Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miło´s, and Marek Cygan. Bigger, regularized, optimistic: scaling for compute and sample-efficient continuous control. In Advances in Neural Information Processing Systems, 2024. 12 APPENDIXCONTENTS AImplementation Details and Hyperparameters 14 A.1 High-Throughput Training Protocol 14 A.2 Uni...
work page 2024
-
[32]
Layer Normalization (LayerNorm).We apply LayerNorm in the actor and critic networks exclusively for the ultra-high-dimensional HumanoidBench domain ( |A|= 61 ). Consistent with recent findings [29, 30, 28], this regularization is critical for maintaining stable gradient flow in expansive action spaces. Conversely, for the MuJoCo Playground and IsaacLab ta...
-
[33]
Target Entropy.Following recent work [ 28], we set the target entropy H= 0 across all tasks. In high-dimensional spaces, the standard heuristic (H=−|A| ) enforces aggressive variance decay, forcing the policy to prematurely drop its exploration budget and exacerbating the “vanishing exploration” problem. By setting H= 0 , we explicitly maintain a generous...
-
[34]
Adaptive Temperature Optimization (auto-τ).The unified default DEM temperature ( τ= 1.0 ) yields strong and robust performance across the vast majority of evaluated tasks and remains our primary recommendation for general use. However, a small subset of highly dynamic tasks requiring extreme whole-body coordination (e.g.,HurdleandBalance Hard) intrinsical...
-
[35]
High-Precision Critic Stability.Unlike the original DSAC-T [ 26], which requires a large numerical stabilizer (bias = 0.1) to prevent division-by-zero during continuous distribution modeling, the inherently stable statistics derived from our large-batch, high-throughput regime allow us to reduce this bias significantly to 10−6. This crucial reduction enab...
-
[36]
Implementation Notes.In implementation, the temperature-scaled DEM logits are clipped to a bounded range before the Softmax for numerical stability, and the base log-standard deviation is mapped to fixed bounds via a tanh parameterization. For heterogeneous exploration, the environment- specific scaling factor is kept fixed within each episode and resampl...
work page 2000
-
[37]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.