From Handwriting to Structured Data: Benchmarking AI Digitisation of Handwritten Forms
Pith reviewed 2026-05-10 16:03 UTC · model grok-4.3
The pith
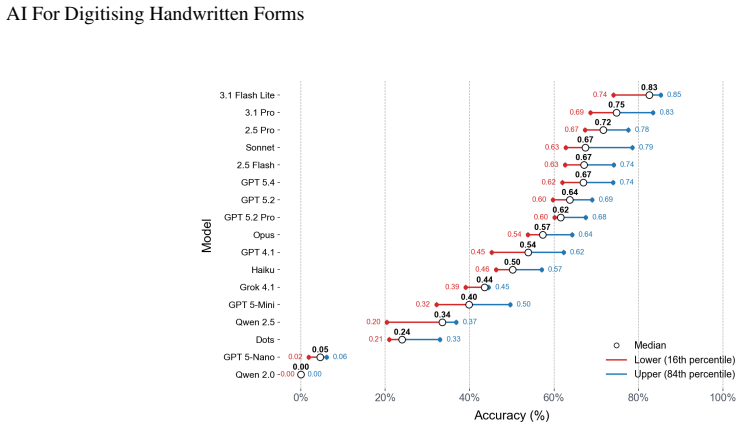
Frontier multimodal models reach 85 percent accuracy and 90 percent F1 scores extracting structured data from a challenging real-world handwritten medical form.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
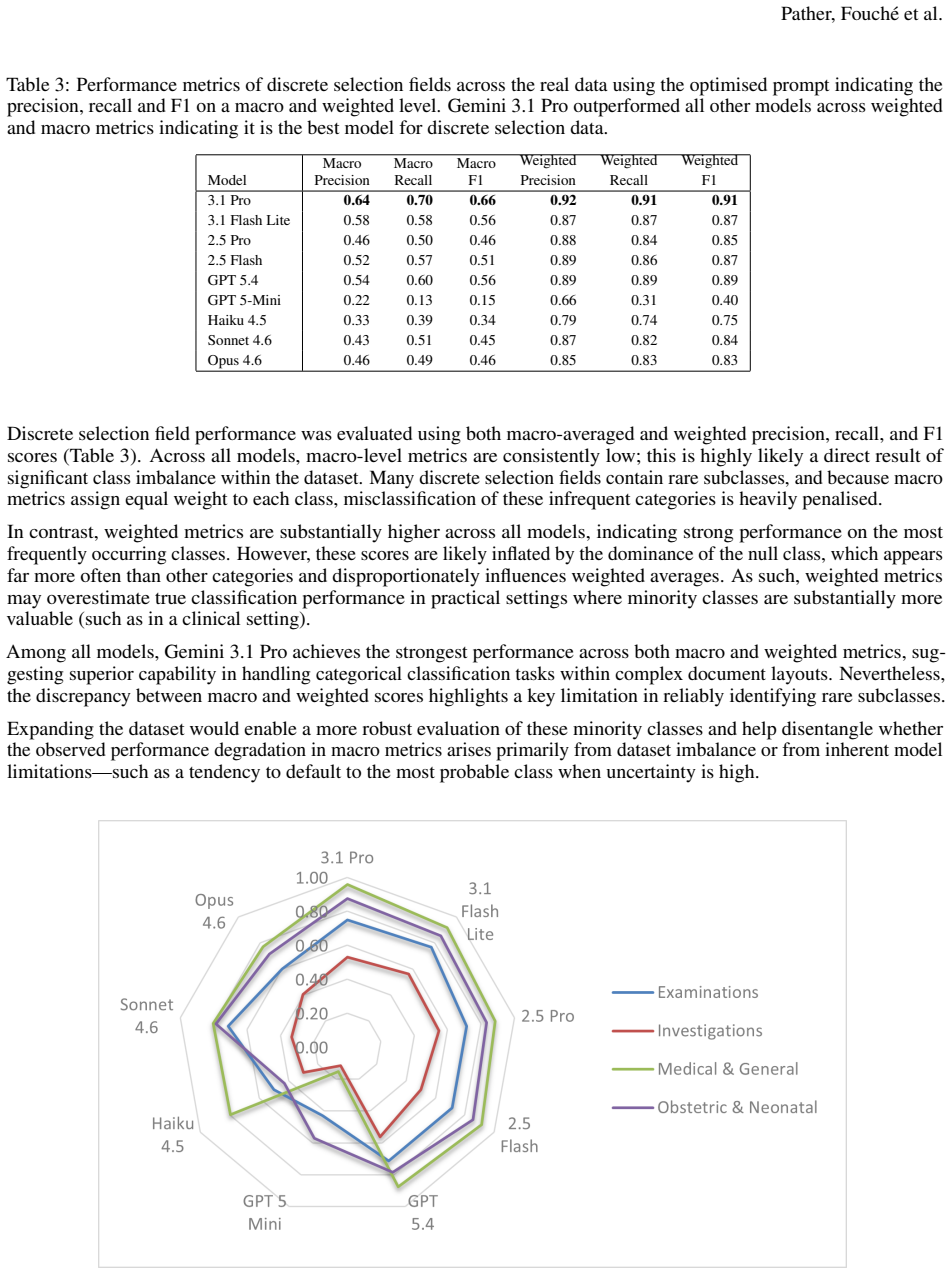
None of the smaller or older models perform well, but the latest Google and OpenAI models reach accuracies around 85 percent with weighted F1 scores approximately 90 percent across the discrete or predefined fields. GPT 5.4 excels at noisy date extraction and shows the lowest hallucination rate of 6 percent. Claude Sonnet 4.6 performs best on average across formatted fields such as dates and numbers. Gemini 3.1 delivers the strongest overall results with the lowest free-text error rates and best discrete classification metrics. Prompt optimisation improves macro precision, recall, and F1 by over 60 percent while changing weighted metrics by only 2 to 5 percent. These outcomes supply evidence
What carries the argument
A real-world medical form containing mixed printed text, handwritten responses, dates, numerical values, and variability challenges, used as a benchmark to measure accuracy, weighted F1, word error rate, character error rate, and hallucination rate across seventeen models.
If this is right
- Fully automated digitisation of complex handwritten workflows becomes feasible with current frontier models.
- Prompt engineering can be used as a low-cost way to raise macro precision and recall on classification tasks by more than 60 percent.
- Specialised model strengths can be combined to improve performance on dates, numbers, and free text simultaneously.
- The approach offers a concrete cost-reduction path for data entry in low- and middle-income country health systems.
- Continued model improvement is likely to extend reliable extraction to even more variable or longer documents.
Where Pith is reading between the lines
- Similar benchmarks could be applied to other structured handwritten sources such as survey responses or lab notebooks to test broader applicability.
- Hybrid systems that route uncertain fields to human review would likely raise end-to-end reliability beyond the raw model scores.
- The observed prompt sensitivity implies that task-specific fine-tuning or retrieval-augmented prompts could yield further gains without new model releases.
Load-bearing premise
That strong results on this single medical form will extend to the full range of handwritten documents met in practice and that the reported metrics alone indicate real-world utility without further human review.
What would settle it
Running the top models on a new collection of handwritten forms from a different domain such as financial records or government surveys and measuring whether accuracy stays near 85 percent or falls sharply.
Figures



read the original abstract
Manual digitisation of structured handwritten documents is slow and costly. We benchmark 17 leading frontier multi-modal large language models and open-source models against a very challenging real-world medical form that mixes dates; structured, printed text; hand-written responses and significant variability challenges. None of the smaller or older models perform well but the latest Google and OpenAI models reach accuracies around $85\%$ with weighted F1 scores $\simeq 90\%$ across the discrete or predefined fields despite the very challenging nature of the responses. Clear task specific strengths emerge: GPT 5.4 excels in noisy date extraction as well as reliability with the lowest hallucination rate ($6\%$). Claude Sonnet 4.6 had the best average performance across formatted fields (dates and numerical values), while Gemini 3.1 delivered the best overall performance, with the lowest free text error rates (WER = $0.50$ and CER = $0.31$) and the strongest results across discrete classification metrics. We further show that prompt optimisation dramatically improves macro precision, recall and F1 by over $60\%$, but has little impact on weighted metrics (only $\sim2-5\%$ improvement). These results provide evidence that the rapid improvements of multimodal large language models offer a compelling pathway toward fully automated digitisation of complex handwritten workflows that is particularly relevant in low- and middle-income countries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks 17 multimodal LLMs (frontier and open-source) on structured data extraction from one challenging real-world handwritten medical form containing dates, printed text, and variable handwritten responses. It reports that smaller/older models perform poorly while latest OpenAI and Google models reach ~85% accuracy and ~90% weighted F1 on discrete/predefined fields, with model-specific strengths (e.g., GPT-5.4 on noisy dates with 6% hallucination rate; Gemini 3.1 on free-text WER/CER; Claude on formatted fields). Prompt optimization improves macro precision/recall/F1 by >60% but only ~2-5% on weighted metrics. The work positions this as evidence for automated digitization pathways, especially in LMICs.
Significance. If the results hold under broader testing, the concrete performance numbers and model comparisons provide useful empirical grounding for the practical utility of current multimodal LLMs on noisy handwritten structured documents. The identification of task-specific strengths and the large effect of prompt optimization are actionable for deployment; the focus on a real medical form with documented variability adds relevance to resource-constrained settings.
major comments (3)
- [Abstract] Abstract and overall evaluation design: the central claim that results demonstrate a 'compelling pathway toward fully automated digitisation of complex handwritten workflows' rests on performance from a single medical form. No cross-form testing, no quantification of how the chosen form covers variability in layouts/field types/languages/noise (despite noting 'significant variability challenges'), and no ablation on form-specific features are reported; this makes the extrapolation to general handwritten forms (especially LMIC deployments) unsupported and load-bearing for the conclusion.
- [Results] Results section (performance numbers and prompt effects): reported accuracies (~85%), weighted F1 (~90%), WER/CER, and hallucination rates lack error bars, confidence intervals, or statistical tests comparing models or prompt variants. This weakens assessment of whether observed differences (e.g., Gemini's free-text advantage or prompt gains on macro vs. weighted metrics) are reliable.
- [Methods] Methods and evaluation metrics: the chosen metrics (accuracy, F1, WER, CER, hallucination rate) are presented without additional human verification steps or real-world utility measures (e.g., downstream workflow impact or error cost analysis), as noted in the weakest assumption; this limits claims about practical digitization value.
minor comments (2)
- [Abstract] Abstract: ensure all 17 models are explicitly listed with key metrics in a summary table in the main text for full reproducibility and comparison.
- Presentation: the abstract uses inline LaTeX ($85%$, ≃) which is appropriate, but add a dedicated limitations paragraph discussing single-form scope and generalization risks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important limitations in scope, statistical presentation, and practical framing. We address each point below with proposed revisions that strengthen the manuscript without overstating the current results.
read point-by-point responses
-
Referee: [Abstract] Abstract and overall evaluation design: the central claim that results demonstrate a 'compelling pathway toward fully automated digitisation of complex handwritten workflows' rests on performance from a single medical form. No cross-form testing, no quantification of how the chosen form covers variability in layouts/field types/languages/noise (despite noting 'significant variability challenges'), and no ablation on form-specific features are reported; this makes the extrapolation to general handwritten forms (especially LMIC deployments) unsupported and load-bearing for the conclusion.
Authors: We agree that the single-form design limits generalizability and that the original abstract and conclusion language overreaches. The form was selected specifically for its documented real-world complexity (mixed printed/handwritten fields, dates, high variability) to stress-test frontier models in a medically relevant LMIC context. In revision we will (1) rewrite the abstract and conclusion to present the work as a detailed case study on one challenging form rather than evidence of a general pathway, (2) add an explicit limitations section that quantifies the form's field types and variability while stating the absence of cross-form or cross-language testing, and (3) remove or qualify the LMIC-deployment extrapolation. These textual changes directly address the unsupported extrapolation. revision: yes
-
Referee: [Results] Results section (performance numbers and prompt effects): reported accuracies (~85%), weighted F1 (~90%), WER/CER, and hallucination rates lack error bars, confidence intervals, or statistical tests comparing models or prompt variants. This weakens assessment of whether observed differences (e.g., Gemini's free-text advantage or prompt gains on macro vs. weighted metrics) are reliable.
Authors: We accept that the absence of uncertainty estimates and statistical comparisons reduces interpretability. Because the dataset consists of a fixed but reasonably large number of fields (discrete, numerical, free-text), we can compute per-metric confidence intervals via bootstrapping over fields and add binomial or normal-approximation intervals for accuracy and F1. For model and prompt comparisons we will include appropriate pairwise tests (e.g., McNemar for classification fields, paired t-tests or Wilcoxon for continuous error rates). The revised results section will report these quantities alongside the point estimates. revision: yes
-
Referee: [Methods] Methods and evaluation metrics: the chosen metrics (accuracy, F1, WER, CER, hallucination rate) are presented without additional human verification steps or real-world utility measures (e.g., downstream workflow impact or error cost analysis), as noted in the weakest assumption; this limits claims about practical digitization value.
Authors: Ground-truth labels were produced and double-checked by domain experts; we will add this detail to the methods. The selected metrics are standard for information extraction and OCR evaluation. We agree that downstream utility (time savings, clinical error costs) would strengthen practical claims. A full workflow study, however, lies beyond the scope of a benchmarking paper. In revision we will (1) clarify the human verification process, (2) add a short discussion linking the reported metrics to potential workflow benefits, and (3) explicitly list the lack of end-to-end utility analysis as a limitation with directions for future work. This is a partial revision because a new utility study is not feasible within the current manuscript. revision: partial
Circularity Check
No circularity: pure empirical benchmarking with direct evaluations
full rationale
This is a pure empirical benchmarking study with no equations, derivations, fitted parameters, or theoretical claims that could create circularity. All reported metrics (accuracy, weighted F1, WER, CER, hallucination rate) are obtained from direct model evaluations on held-out form data. No self-citations are load-bearing for any derivation, and the paper does not invoke uniqueness theorems, ansatzes, or renamings of known results. The central findings reduce only to straightforward comparisons of model outputs against ground truth labels.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benchmarking large language models for handwritten text recognition, 2025
Giorgia Crosilla, Lukas Klic, and Giovanni Colavizza. Benchmarking large language models for handwritten text recognition, 2025. arXiv:2503.15195
-
[2]
Interpreting doctor notes using handwriting recognition and deep learning techniques: A survey
Nithin Kumar, Amrutha Chikkmath, Gouthami Yadav B R, Hema R Naidu, and Diya Acharya. Interpreting doctor notes using handwriting recognition and deep learning techniques: A survey. In2023 International Conference on Advances in Electronics, Communication, Computing and Intelligent Information Systems (ICAECIS), pages 703–708, 2023
work page 2023
-
[3]
Optical character recognition errors and their effects on natural language processing
Daniel Lopresti. Optical character recognition errors and their effects on natural language processing. In Proceedings of the Second Workshop on Analytics for Noisy Unstructured Text Data, pages 9–16, New York, NY , USA, 2008. Association for Computing Machinery
work page 2008
-
[4]
TrOCR: Transformer-based Optical Charac- ter Recognition with Pre-trained Models,
Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. Trocr: Transformer-based optical character recognition with pre-trained models, 2022. arXiv:2109.10282
-
[5]
Donut: Document understanding transformer without OCR
Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. OCR-free Document Understanding Transformer.arXiv e-prints, page arXiv:2111.15664, November 2021. arXiv:2111.15664
-
[6]
Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding, 2023. arXiv:2210.03347
-
[7]
LayoutLM: Pre-training of text and layout for document image understanding
Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. Layoutlm: Pre-training of text and layout for document image understanding, 2019. arXiv:1912.13318
-
[8]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Exploring ocr capabilities of gpt-4v(ision): A quantitative and in-depth evaluation, 2023
Yongxin Shi, Dezhi Peng, Wenhui Liao, Zening Lin, Xinhong Chen, Chongyu Liu, Yuyi Zhang, and Lianwen Jin. Exploring ocr capabilities of gpt-4v(ision): A quantitative and in-depth evaluation, 2023. arXiv:2310.16809
-
[10]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Greg Brockman, et al. Gpt-4 technical report,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Yumeng Li, Guang Yang, Hao Liu, Bowen Wang, and Colin Zhang. dots.ocr: Multilingual document layout parsing in a single vision-language model, 2025. arXiv:2512.02498
-
[12]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Claude haiku 4.5, October 2025.https://www.anthropic.com/claude/haiku
Anthropic. Claude haiku 4.5, October 2025.https://www.anthropic.com/claude/haiku
work page 2025
-
[14]
Claude opus 4.6, February 2026.https://www.anthropic.com/claude/opus
Anthropic. Claude opus 4.6, February 2026.https://www.anthropic.com/claude/opus
work page 2026
-
[15]
Claude sonnet 4.6, September 2025.https://www.anthropic.com/claude/sonnet
Anthropic. Claude sonnet 4.6, September 2025.https://www.anthropic.com/claude/sonnet
work page 2025
-
[16]
Grok 4.1 model card, 2025.https://data.x.ai/2025-11-17-grok-4-1-model-card.pdf
xAI. Grok 4.1 model card, 2025.https://data.x.ai/2025-11-17-grok-4-1-model-card.pdf
work page 2025
-
[17]
GPT-4.1, 2025.https://openai.com/index/gpt-4-1/
OpenAI. GPT-4.1, 2025.https://openai.com/index/gpt-4-1/
work page 2025
-
[18]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, et al. OpenAI GPT-5 system card, 2025. arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Gemini Team, Gheorghe Comanici, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Google DeepMind. Gemini 3.1 Flash-Lite. Technical report, Google DeepMind, 2025. https://storage. googleapis.com/deepmind-media/Model-Cards/Gemini-3-1-Flash-Lite-Model-Card.pdf
work page 2025
-
[21]
Google DeepMind. Gemini 3.1 pro, 2025. Preview model. https://deepmind.google/models/gemini/ pro/. 14 AI For Digitising Handwritten Forms A Extraction Prompt Here we show the prompt used to extract text from both the real and synthetic data: You are an expert medical form data extractor specializing in the South African Maternity Case Record (MCR1). You a...
work page 2025
- [22]
- [23]
-
[24]
Gestation/Duration Formatting (Obstetric & Neonatal History only): •“9 weeks” or “9/52”→“9/40”. •Normalise “9/12”→“9 months”. •Do NOT normalise “Term” or “term” –- write verbatim if present
-
[25]
Blood Pressure:Extract bp (systolic) and bp_dia (diastolic) separately. Example: “120/70”→bp: “120”, bp_dia: “70”
-
[26]
Medical & General History–- For use of herbal, use of otc, tobacco_use, alcohol_use, substance_use: “1” = User, “2” = Former User, “3” = Non-User. 7.For the following specific fields use “1” for Checked/Ticked/Crossed/Filled/Yes and “0” for Empty/No: hypertension, diabetes, cardiac, asthma, tuberculosis, epilepsy, mental_health_disorder, hiv, other_condit...
-
[27]
All Other Checkboxes (Yes/null): •If Ticked/Checked/Crossed/Filled/Yes→“Yes”. •If Empty/Blank→null
-
[28]
Medical & General History: 15 Pather, Fouché et al. •“none” is a summary field: “1” if ALL personal condition fields were negative, otherwise “0”. Does NOT include family history fields. •“allergies” is often written “Nil known”, “nil known”, “none”. •tb_symptom_screen options: “Positive” and “Negative”
-
[29]
Investigations: •hiv_status_at_booking: “Un-known”, “Positive”, “Negative”. •rhesus and hiv_test[1-3]_result: “Positive”, “Negative” only. •HIV Retest: only option is “NotDecli”, otherwise leave blank. If the retest field is filled then “NotDecli” MUST be written. 11.Syphilis test results: write only the numerical value: “1” = Positive, “2” = Negative. 12...
-
[30]
Gestational Age: •Fields bpd, hc, ac, fl, average_gestation: format “xxwksxdys”. •Field crl: weight must be written in grams. 15.overwrite should only be filled with “Primigravida” if the first pregnancy has been written across all rows of obstetric and neonatal history; otherwise null
- [31]
-
[32]
Examinations–- urinalysis_protein and urinalysis_glucose: •“°prot,°gluc” or “pHX°prot,°gluc”→“None” for both fields. •“No protein, no glucose”; “No glucose, no protein”; “NAD” & “NAD/POS”→“None” for both fields. •Discard information unrelated to protein and glucose. EXTRACTION RULES: •Use EXACT field names from the JSON provided within the template. •Extr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.