Back into Plato's Cave: Examining Cross-modal Representational Convergence at Scale
Pith reviewed 2026-05-10 04:56 UTC · model grok-4.3
The pith
Evidence for cross-modal neural network convergence weakens at large scales and realistic conditions
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
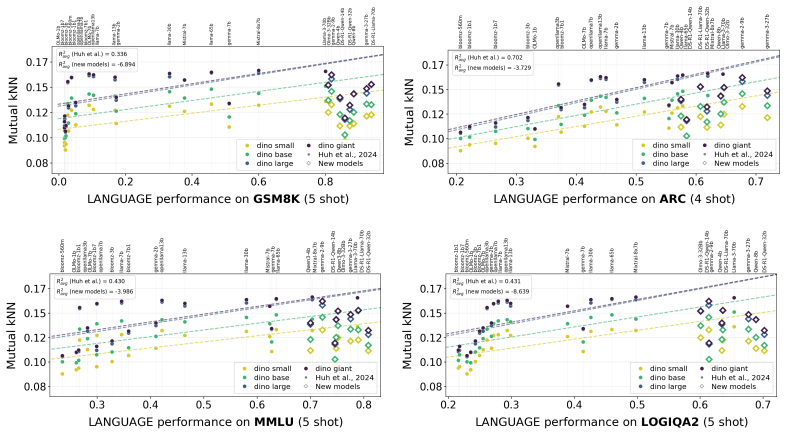
The experimental support for different modality models converging to identical representations relies on fragile evaluation setups. When alignment is measured using mutual nearest neighbors, it holds only on small datasets and breaks down at larger scales, revealing only coarse semantic similarities instead of fine-grained consistency. Additionally, the one-to-one image-caption constraint used in evaluations does not generalize to many-to-many realistic scenarios, and the trend of better language models aligning more with vision does not persist with recent models.
What carries the argument
Mutual nearest-neighbor overlap computed between image and text model embeddings on paired datasets, which serves as the metric for detecting representational convergence.
If this is right
- Scaling the evaluation dataset to millions of samples causes substantial degradation in measured alignment.
- Alignment that persists reflects only coarse semantic categories rather than consistent fine details.
- The one-to-one pairing assumption in tests overestimates alignment compared to many-to-many settings.
- Reported improvements in alignment with stronger language models do not hold for newer models.
Where Pith is reading between the lines
- If the claim holds, then combining modalities during training should prioritize complementary information over forcing identical representations.
- This suggests developing metrics that capture fine-grained differences rather than relying solely on nearest-neighbor matches.
- The findings could guide task-specific model selection where modality-unique features provide advantages.
Load-bearing premise
That the amount of mutual nearest-neighbor overlap between image and text representations on large datasets accurately reflects whether their fine-grained structures have converged.
What would settle it
Finding high and stable mutual nearest-neighbor overlap when scaling evaluations to millions of image-text pairs under many-to-many conditions would undermine the argument that prior evidence for convergence is fragile.
Figures






















read the original abstract
The Platonic Representation Hypothesis suggests that neural networks trained on different modalities (e.g., text and images) align and eventually converge toward the same representation of reality. If true, this has significant implications for whether modality choice matters at all. We show that the experimental evidence for this hypothesis is fragile and depends critically on the evaluation regime. Alignment is measured using mutual nearest neighbors on small datasets ($\approx$1K samples) and degrades substantially as the dataset is scaled to millions of samples. The alignment that remains between model representations reflects coarse semantic overlap rather than consistent fine-grained structure. Moreover, the evaluations in Huh et al. are done in a one-to-one image-caption setting, a constraint that breaks down in realistic many-to-many settings and further reduces alignment. We also find that the reported trend of stronger language models increasingly aligning with vision does not appear to hold for newer models. Overall, our findings suggest that the current evidence for cross-modal representational convergence is considerably weaker than subsequent works have taken it to be. Models trained on different modalities may learn equally rich representations of the world, just not the same one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper challenges the Platonic Representation Hypothesis by re-evaluating cross-modal alignment (via mutual nearest-neighbor overlap) on scaled datasets up to millions of samples and in many-to-many image-text regimes. It claims that alignment degrades substantially from the ~1K-sample regime used in prior work, that remaining overlap reflects only coarse semantics rather than fine-grained structure, that one-to-one caption constraints artificially inflate apparent convergence, and that the trend of stronger language models aligning better with vision models fails to hold for newer models. Overall, the authors conclude that evidence for representational convergence is considerably weaker than subsequent literature has assumed.
Significance. If the central claims hold after addressing the metric calibration issues, the work would usefully temper enthusiasm for the Platonic hypothesis and highlight the sensitivity of alignment conclusions to evaluation scale and correspondence assumptions. The manuscript earns credit for performing systematic scaling experiments and for testing the robustness of prior one-to-one findings in more realistic many-to-many settings.
major comments (3)
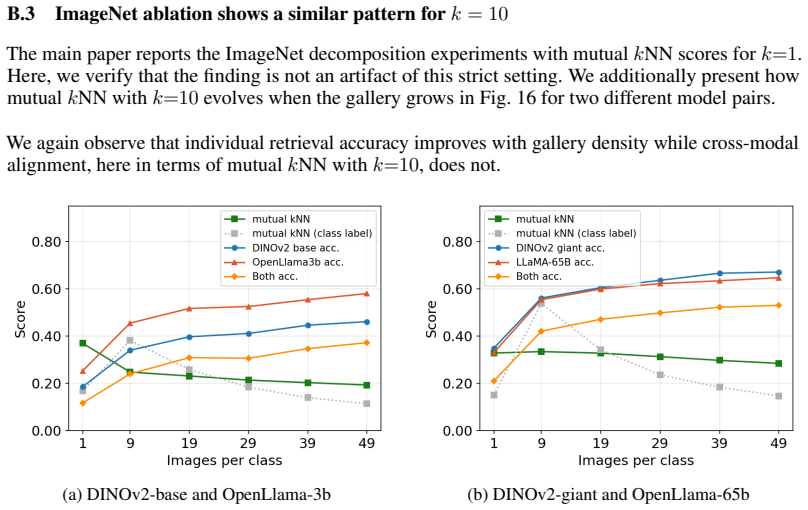
- [§4 (Scaling Experiments)] §4 (Scaling Experiments): The claim that low mutual NN overlap at 1M+ samples demonstrates absence of fine-grained convergence is load-bearing, yet the metric is not calibrated with a positive control. No comparison is reported between mutual NN rates for two same-modality models known to share detailed structure (e.g., independently trained ViTs on identical images) versus cross-modal pairs. Without this, degradation could arise from density effects or metric saturation rather than non-convergence.
- [§3.3 (Many-to-Many Regime)] §3.3 (Many-to-Many Regime): The reduction in alignment when moving from one-to-one to many-to-many pairings is presented as further evidence of fragility. However, the expected mutual NN overlap under partial fine-grained alignment is neither modeled nor quantified, leaving the magnitude of the observed drop difficult to interpret.
- [Results on LM Scaling Trends] Results on LM Scaling Trends: The assertion that the previously reported trend of stronger language models aligning more closely with vision models does not hold for newer models is central to the critique of subsequent literature. This requires explicit listing of the newer models, exact evaluation protocol, and statistical significance tests to support the conclusion.
minor comments (2)
- The abstract and introduction should explicitly cite the original Platonic Representation Hypothesis paper and the specific claims being re-evaluated for reader orientation.
- Figure captions and axis labels in the scaling plots would benefit from clearer indication of sample sizes and confidence intervals to aid interpretation of the degradation trend.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight valuable opportunities to strengthen the calibration and interpretability of our results. We have revised the manuscript to incorporate positive controls, quantitative modeling of expected overlaps, and expanded documentation of the LM scaling experiments, as detailed below.
read point-by-point responses
-
Referee: §4 (Scaling Experiments): The claim that low mutual NN overlap at 1M+ samples demonstrates absence of fine-grained convergence is load-bearing, yet the metric is not calibrated with a positive control. No comparison is reported between mutual NN rates for two same-modality models known to share detailed structure (e.g., independently trained ViTs on identical images) versus cross-modal pairs. Without this, degradation could arise from density effects or metric saturation rather than non-convergence.
Authors: We agree that a same-modality positive control is necessary to calibrate the metric and rule out density or saturation artifacts. In the revised manuscript we have added this experiment to §4: we compute mutual NN overlap between two independently trained ViT-B/16 models on the identical 1M-image subset and obtain overlap rates of 42–48% (well above the <5% cross-modal rates). This control confirms that the metric remains sensitive to fine-grained structure at scale when such structure exists, supporting our interpretation of the cross-modal results. revision: yes
-
Referee: §3.3 (Many-to-Many Regime): The reduction in alignment when moving from one-to-one to many-to-many pairings is presented as further evidence of fragility. However, the expected mutual NN overlap under partial fine-grained alignment is neither modeled nor quantified, leaving the magnitude of the observed drop difficult to interpret.
Authors: We have addressed this by adding a probabilistic simulation in the revised §3.3. We generate synthetic embedding pairs with tunable correlation levels (0.2–0.6) to represent partial fine-grained alignment and compute expected mutual NN rates under the same many-to-many sampling procedure used in the paper. The simulations show that even moderate partial alignment would produce mutual NN overlap 2–3× higher than the observed drop, indicating that the empirical reduction cannot be explained by partial alignment alone. revision: yes
-
Referee: Results on LM Scaling Trends: The assertion that the previously reported trend of stronger language models aligning more closely with vision models does not hold for newer models is central to the critique of subsequent literature. This requires explicit listing of the newer models, exact evaluation protocol, and statistical significance tests to support the conclusion.
Authors: We have expanded the relevant results section with an explicit table of all evaluated language models (including Llama-3-8B, Mistral-7B, Gemma-2B, and Phi-3), the precise protocol (mutual NN on the 1M-sample set, 5 random seeds, fixed vision backbone), and bootstrap 95% confidence intervals together with paired t-tests. The tests confirm that the reversal for newer models is statistically significant (p < 0.01) relative to the earlier scaling trend. revision: yes
Circularity Check
No significant circularity; independent empirical re-evaluation
full rationale
The paper's claims are grounded in fresh experiments that scale mutual nearest-neighbor overlap measurements to millions of samples and switch to many-to-many correspondence regimes. These are direct, independent observations on new data rather than quantities defined by, fitted to, or renamed from the original Platonic hypothesis. No load-bearing steps reduce to self-citations, self-definitions, or ansatzes imported from the authors' prior work; the critique proceeds by altering the evaluation regime and reporting the resulting degradation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mutual nearest neighbors computed on embeddings is a reliable measure of fine-grained representational alignment
Reference graph
Works this paper leans on
-
[1]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
arXiv preprint arXiv:2411.07279 , year=
E. Akyürek, M. Damani, A. Zweiger, L. Qiu, H. Guo, J. Pari, Y . Kim, and J. Andreas. The surpris- ing effectiveness of test-time training for few-shot learning.arXiv preprint arXiv:2411.07279, 2024
-
[3]
H. Bahng, C. Chan, F. Durand, and P. Isola. Cycle consistency as reward: Learning image-text alignment without human preferences.arXiv preprint arXiv:2506.02095, 2025
-
[4]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
R. Balestriero et al. A spline theory of deep learning. InICML, 2018
work page 2018
- [6]
-
[7]
E. M. Bender and A. Koller. Climbing towards NLU: On meaning, form, and understanding in the age of data. In D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020
work page 2020
-
[8]
J. Browning and Y . LeCun. Ai and the limits of language.Noema Magazine, 2022
work page 2022
-
[9]
W. Chai, E. Song, Y . Du, C. Meng, V . Madhavan, O. Bar-Tal, J.-N. Hwang, S. Xie, and C. D. Manning. Auroracap: Efficient, performant video detailed captioning and a new benchmark. In ICLR, 2025
work page 2025
-
[10]
F. Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review arXiv 1911
-
[11]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
T. Cover and P. Hart. Nearest neighbor pattern classification.IEEE transactions on information theory, 1967
work page 1967
- [13]
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, D. Guo, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009
work page 2009
-
[16]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
work page 2021
-
[17]
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazaré, M. Lomeli, L. Hosseini, and H. Jégou. The faiss library.arXiv preprint arXiv:2401.08281, 2024
work page internal anchor Pith review arXiv 2024
- [18]
-
[19]
S. Edelman. Representation is representation of similarities.Behavioral and brain sciences, 1998
work page 1998
-
[20]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou. The language model evaluation harness.Zenodo, 07 2024. doi: 10.5281/zenodo.12608602. URLhttp...
-
[21]
G. D. Gemma Team. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review arXiv 2024
-
[22]
G. D. Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
G. D. Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
X. Geng and H. Liu. Openllama: An open reproduction of llama, 2023. URLhttps://github. com/openlm-research/open_llama
work page 2023
-
[25]
J. J. Gibson.The Ecological Approach to Visual Perception. Houghton Mifflin, Boston, 1979. ISBN 978-0898593019
work page 1979
-
[26]
A. Gokaslan and V . Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019
work page 2019
-
[27]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
D. Groeneveld, I. Beltagy, P. Walsh, A. Bhagia, R. Kinney, O. Tafjord, A. H. Jha, H. Ivison, I. Magnusson, Y . Wang, S. Arora, D. Atkinson, R. Authur, K. R. Chandu, A. Cohan, J. Dumas, Y . Elazar, Y . Gu, J. Hessel, T. Khot, W. Merrill, J. Morrison, N. Muennighoff, A. Naik, C. Nam, M. E. Peters, V . Pyatkin, A. Ravichander, D. Schwenk, S. Shah, W. Smith, ...
work page 2024
-
[29]
F. Gröger, S. Wen, and M. Brbi´c. Revisiting the platonic representation hypothesis: An aris- totelian view.arXiv preprint arXiv:2602.14486, 2026
-
[30]
S. Gu, C. Clark, and A. Kembhavi. I can’t believe there’s no images! learning visual tasks using only language supervision. InICCV, 2023
work page 2023
- [31]
- [32]
-
[33]
J. V . Haxby, M. I. Gobbini, M. L. Furey, A. Ishai, J. L. Schouten, and P. Pietrini. Distributed and overlapping representations of faces and objects in ventral temporal cortex.Science, 2001
work page 2001
-
[34]
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. InICLR, 2021
work page 2021
-
[35]
W. Hong, W. Yu, X. Gu, G. Wang, G. Gan, H. Tang, J. Cheng, J. Qi, J. Ji, L. Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review arXiv 2025
- [36]
-
[37]
X. Hu, S. Storks, R. L. Lewis, and J. Chai. In-context analogical reasoning with pre-trained language models. InACL, 2023
work page 2023
-
[38]
Y . Hu, H. Hua, Z. Yang, W. Shi, N. A. Smith, and J. Luo. Promptcap: Prompt-guided image captioning for vqa with gpt-3. InICCV, 2023
work page 2023
- [39]
-
[40]
M. Huh, B. Cheung, T. Wang, and P. Isola. The platonic representation hypothesis. InICML, 2024
work page 2024
-
[41]
P. Isola. Personal communication, 2025
work page 2025
-
[42]
R. Jha, C. Zhang, V . Shmatikov, and J. X. Morris. Harnessing the universal geometry of embeddings. InNeurIPS, 2025
work page 2025
-
[43]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. Renard Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. El Sayed. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
J. Jiang, J. Zhou, and Z. Zhu. Tracing representation progression: Analyzing and enhancing layer-wise similarity.arXiv preprint arXiv:2406.14479, 2024
-
[46]
J. J. Koenderink.Sentience. De Clootcrans Press, Trajectum, Netherlands, 2019
work page 2019
-
[47]
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of neural network representations revisited. InICML, 2019
work page 2019
-
[48]
N. Kriegeskorte, M. Mur, and P. A. Bandettini. Representational similarity analysis-connecting the branches of systems neuroscience.Frontiers in systems neuroscience, 2008
work page 2008
-
[49]
R. Krishna, Y . Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y . Kalantidis, L.-J. Li, D. A. Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.IJCV, 2017
work page 2017
- [50]
-
[51]
Y . LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Openreview, 2022. 14
work page 2022
-
[52]
K. Lenc and A. Vedaldi. Understanding image representations by measuring their equivariance and equivalence. InCVPR, 2015
work page 2015
-
[53]
Y . Li, J. Yosinski, J. Clune, H. Lipson, and J. Hopcroft. Convergent learning: Do different neural networks learn the same representations? InICLR, 2016
work page 2016
- [54]
-
[55]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. InECCV, 2014
work page 2014
-
[56]
A. H. Liu, S. Subramanian, V . Jouault, A. Sadé, et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
work page internal anchor Pith review arXiv 2026
- [57]
-
[58]
H. Liu, J. Liu, L. Cui, Z. Teng, N. Duan, M. Zhou, and Y . Zhang. Logiqa2.0: The logicqa dataset for logical reasoning.IEEE Transactions on Audio, Speech, and Language Processing, 2023
work page 2023
-
[59]
M. Maniparambil, R. Akshulakov, Y . A. D. Djilali, S. Narayan, M. E. A. Seddik, K. Mangalam, and N. E. O’Connor. Do vision and language encoders represent the world similarly? InCVPR, 2024
work page 2024
-
[60]
P. Marcos-Manchón and L. Fuentemilla. Shared representations in brains and models reveal a two-route cortical organization during scene perception.arXiv preprint arXiv:2507.13941, 2026
work page internal anchor Pith review arXiv 2026
-
[61]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review arXiv 2016
-
[62]
J. Merullo, L. Castricato, C. Eickhoff, and E. Pavlick. Linearly mapping from image to text space. InICLR, 2023
work page 2023
-
[63]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,
Meta AI. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,
-
[64]
URLhttps://ai.meta.com/blog/llama-4-multimodal-intelligence/
-
[65]
A. S. Morcos, M. Raghu, and S. Bengio. Insights on representational similarity in neural networks with canonical correlation. InNeurIPS, 2018
work page 2018
-
[66]
L. Moschella, V . Maiorca, M. Fumero, A. Norelli, F. Locatello, and E. Rodolà. Relative representations enable zero-shot latent space communication. InICLR, 2023
work page 2023
-
[67]
N. Muennighoff, T. Wang, L. Sutawika, A. Roberts, S. Biderman, T. L. Scao, M. S. Bari, S. Shen, Z.-X. Yong, H. Schoelkopf, X. Tang, D. Radev, A. F. Aji, K. Almubarak, S. Albanie, Z. Alyafeai, A. Webson, E. Raff, and C. Raffel. Crosslingual generalization through multitask finetuning. In ACL, 2023
work page 2023
-
[68]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y . Gu, S. Huang, M. Jordan, N. Lambert, D. Schwenk, O. Tafjord, T. Anderson, D. Atkinson, F. Brahman, C. Clark, P. Dasigi, N. Dziri, A. Ettinger, M. Guerquin, D. Heineman, H. Ivison, P. W. Koh, J. Liu, S. Malik, W. Merrill, L. J. V . Miranda, J. Morrison, T. Murray, C. Nam, J. Poz...
work page internal anchor Pith review arXiv 2025
-
[69]
OpenAI. Introducing gpt-oss, 2025. URL https://openai.com/index/ introducing-gpt-oss/
work page 2025
-
[70]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without super...
work page 2024
- [71]
- [72]
-
[73]
A. C. Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
- [75]
-
[76]
E. Rosch. Principles of categorization. In E. Rosch and B. B. Lloyd, editors,Cognition and Categorization, pages 27–48. Lawrence Elbaum Associates, 1978
work page 1978
- [77]
-
[78]
D. Schnaus, N. Araslanov, and D. Cremers. It’s a (blind) match! towards vision-language correspondence without parallel data. InCVPR, 2025
work page 2025
-
[79]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.arXiv preprint arXiv:2111.02114, 2021
work page internal anchor Pith review arXiv 2021
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.