Benchmarking EngGPT2-16B-A3B against Comparable Italian and International Open-source LLMs
Pith reviewed 2026-05-21 08:09 UTC · model grok-4.3
The pith
A new 16B Italian MoE model with 3B active parameters performs as well or better than other native Italian LLMs on most benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
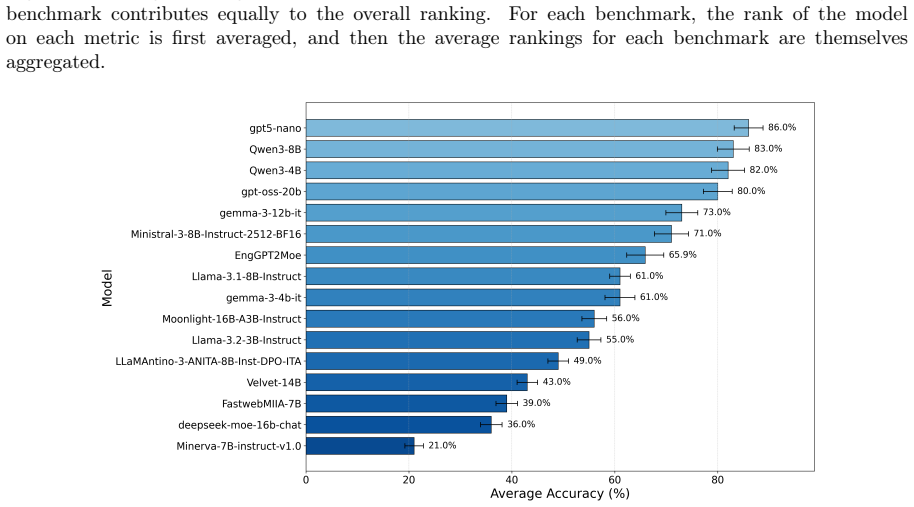
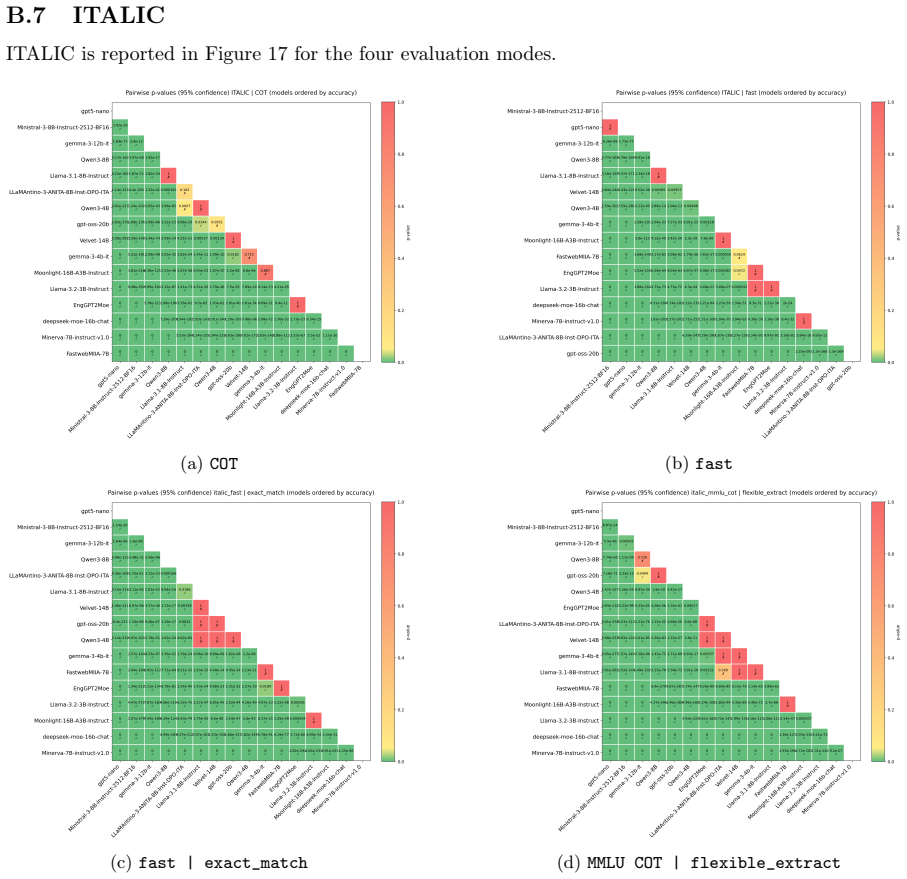
EngGPT2MoE-16B-A3B reports higher or equal scores than other Italian models on ARC-Challenge, GSM8K, AIME24, AIME25, MMLU, HumanEval, and the 32k RULER setting, with the sole exception on ITALIC where Velvet-14B leads. It exceeds DeepSeek-MoE-16B-Chat on all tests and shows mixed outcomes versus other MoE and dense models, leading to the overall finding that the model constitutes a step forward for native Italian Large Language Models.
What carries the argument
The comparative benchmarking across ARC-Challenge, GSM8K, AIME24, AIME25, MMLU, HumanEval, BFCL, RULER at multiple context lengths, and the ITALIC Italian dataset, followed by metric aggregation.
If this is right
- Mixture-of-Experts designs with low active parameters can deliver competitive results for language-specific models.
- Italian models can now be deployed for local applications with less dependence on foreign-trained systems.
- Long-context handling at 32k tokens stands out as a relative strength for extended Italian documents.
- Open release supports further community fine-tuning to close remaining gaps with top international models.
Where Pith is reading between the lines
- Targeted development for other languages could produce similar relative gains with modest active-parameter budgets.
- Greater use of language-specific benchmarks like ITALIC would help prevent over-optimism from English-heavy tests.
- Combining this model's long-context strengths with higher-scoring international models offers a clear next experiment.
Load-bearing premise
The selected benchmarks and their aggregation method give a fair picture of real-world Italian-language capability without undisclosed training-data or evaluation advantages.
What would settle it
A new held-out Italian benchmark or large-scale user study in Italian where EngGPT2MoE-16B-A3B underperforms the compared models on aggregate.
Figures
















read the original abstract
This report benchmarks the performance of ENGINEERING Ingegneria Informatica S.p.A.'s EngGPT2MoE-16B-A3B LLM, a 16B parameter Mixture of Experts (MoE) model with 3B active parameters. Performance is investigated across a wide variety of representative benchmarks, and is compared against comparably-sized open-source MoE and dense models. In comparison with popular Italian models, namely FastwebMIIA-7B, Minerva-7B, Velvet-14B, and LLaMAntino-3-ANITA-8B, EngGPT2MoE-16B-A3B performs as well or better on international benchmarks: ARC-Challenge, GSM8K, AIME24, AIME25, MMLU, and HumanEval (HE). It achieves the best performance for the longest context setting (32k) of the RULER benchmark. On the Italian benchmark dataset ITALIC, the model performs as well or better than the other models except for Velvet-14B, which outperforms it. Compared with popular MoE models of comparable size, the new model reports higher values than DeepSeek-MoE-16B-Chat on all considered benchmarks. It has higher values than Moonlight-16B-A3B on HE, MMLU, AIME24, AIME25, GSM8K, and the 32k RULER setting, but lower on BFCL and some ARC and ITALIC settings. Finally it has lower values than GPT-OSS-20B on most benchmarks, including HE, MMLU, AIME24, AIME25, GSM8K, ARC, BFCL, and the RULER 32k. When compared with popular dense models, EngGPT2MoE-16B-A3B reports higher values on AIME24 and AIME25 than Llama-3.1-8B-Instruct, Gemma-3-12b-it, and Ministral-3-8BInstruct-2512-BF16, but lower values on ITALIC, BFCL, and RULER with a 32k context. When performance is aggregated across all benchmark metrics, EngGPT2MoE-16B-A3B shows higher performance than the Italian models under evaluation while achieving lower results than some of the most performant international models, in particular GPT-5 nano and Qwen3-8B. Taken together, our findings find the new model to be a step forward for native Italian Large Language Models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks EngGPT2MoE-16B-A3B, a 16B-parameter Mixture-of-Experts model with 3B active parameters, on international tasks (ARC-Challenge, GSM8K, AIME24, AIME25, MMLU, HumanEval, RULER-32k, BFCL) and the Italian ITALIC benchmark. It reports direct numerical comparisons against Italian models (FastwebMIIA-7B, Minerva-7B, Velvet-14B, LLaMAntino-3-ANITA-8B) and international MoE/dense models, concluding that the new model performs as well or better than the Italian comparators on most tasks and constitutes a step forward for native Italian LLMs, while trailing some leading international systems.
Significance. If the reported scores rest on comparable evaluation conditions and transparent aggregation, the work supplies a useful snapshot of relative capabilities for open Italian LLMs and demonstrates that an efficient MoE architecture can deliver competitive results on both general and language-specific benchmarks. The inclusion of long-context (RULER-32k) and Italian-specific evaluation adds practical value for the community.
major comments (3)
- [Abstract] The abstract states that 'When performance is aggregated across all benchmark metrics, EngGPT2MoE-16B-A3B shows higher performance than the Italian models under evaluation' yet supplies neither the aggregation formula (mean, z-score, rank sum, or weighted), a summary table of aggregated scores, nor justification for any weighting. This directly supports the central claim of a 'step forward' and must be clarified.
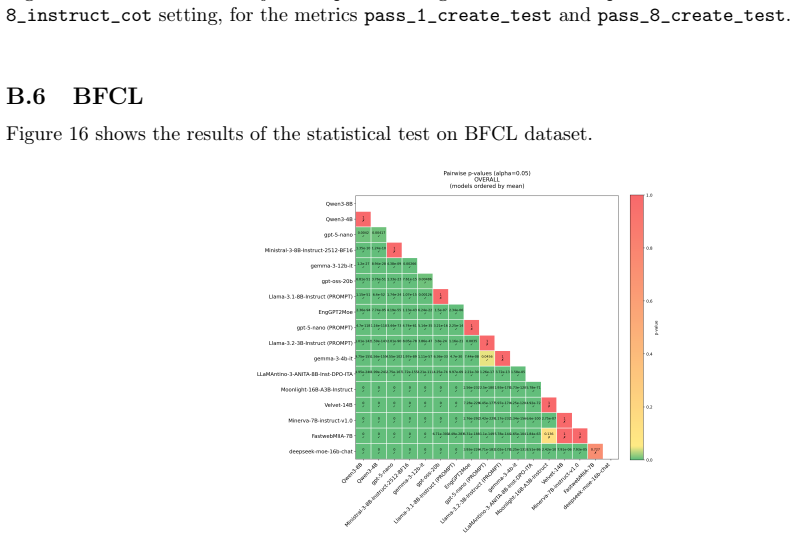
- [Results] Raw benchmark scores are presented without error bars, number of evaluation runs, prompting templates, temperature settings, or statistical significance tests for reported differences. The manuscript also omits any description of training-corpus composition or decontamination procedures for the listed benchmarks; these omissions are load-bearing for the claim that observed edges reflect genuine Italian capability rather than data advantages.
- [Results] On the Italian-specific ITALIC benchmark the model is outperformed by Velvet-14B, yet the headline conclusion treats the model as advancing native Italian performance. The paper should explicitly discuss how this exception is reconciled with the aggregated claim.
minor comments (2)
- [Title and Abstract] Model nomenclature is inconsistent: the title uses 'EngGPT2-16B-A3B' while the abstract and comparisons use 'EngGPT2MoE-16B-A3B'.
- [Abstract] Brief citations or one-sentence descriptions for AIME24/AIME25 and the exact version of RULER would improve accessibility for readers unfamiliar with the benchmarks.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has strengthened the transparency of our work. We have revised the manuscript to address the major comments on aggregation, evaluation details, and the ITALIC exception, while noting limitations where full disclosure is not possible.
read point-by-point responses
-
Referee: [Abstract] The abstract states that 'When performance is aggregated across all benchmark metrics, EngGPT2MoE-16B-A3B shows higher performance than the Italian models under evaluation' yet supplies neither the aggregation formula (mean, z-score, rank sum, or weighted), a summary table of aggregated scores, nor justification for any weighting. This directly supports the central claim of a 'step forward' and must be clarified.
Authors: We agree that the aggregation procedure requires explicit description to support the central claim. In the revised manuscript we now state that aggregated performance is the unweighted average of min-max normalized scores across all benchmarks (normalization performed jointly over the Italian models for fair comparison). We have added a new summary table (Table 7) reporting these aggregated values for all models and a brief justification for the unweighted approach, as it avoids introducing arbitrary weights while still reflecting overall capability. revision: yes
-
Referee: [Results] Raw benchmark scores are presented without error bars, number of evaluation runs, prompting templates, temperature settings, or statistical significance tests for reported differences. The manuscript also omits any description of training-corpus composition or decontamination procedures for the listed benchmarks; these omissions are load-bearing for the claim that observed edges reflect genuine Italian capability rather than data advantages.
Authors: We have expanded the Evaluation section to include the exact prompting templates, temperature settings (0.0 for deterministic generation on all tasks except where sampling was required), and confirmation that each benchmark was evaluated in a single run owing to computational cost. A limitations paragraph now acknowledges the absence of error bars and statistical tests. Detailed training-corpus composition and decontamination procedures remain proprietary and cannot be released; we have added an explicit statement to this effect in the revised text. revision: partial
-
Referee: [Results] On the Italian-specific ITALIC benchmark the model is outperformed by Velvet-14B, yet the headline conclusion treats the model as advancing native Italian performance. The paper should explicitly discuss how this exception is reconciled with the aggregated claim.
Authors: We appreciate the referee drawing attention to this point. The revised Results and Discussion sections now contain an explicit paragraph reconciling the ITALIC result with the overall conclusion. Although Velvet-14B leads on ITALIC, EngGPT2MoE-16B-A3B records higher or equal scores on the six international benchmarks and the long-context RULER-32k task, producing a higher aggregated score. We frame this as evidence that the model advances native Italian LLM development by delivering a more balanced profile—strong general capabilities plus competitive language-specific performance—while benefiting from the efficiency of the 3B-active-parameter MoE design. revision: yes
- Detailed training-corpus composition and decontamination procedures (proprietary information)
Circularity Check
No circularity: pure empirical benchmark reporting with no derivations or self-referential elements
full rationale
This paper consists entirely of empirical benchmark measurements and direct comparisons of raw scores on standard tasks (ARC-Challenge, GSM8K, MMLU, HumanEval, RULER, ITALIC, etc.) against other models. No equations, fitted parameters, predictions, or first-principles derivations appear anywhere in the text. The central claim that the model represents a step forward for native Italian LLMs is presented as a summary of the measured outcomes rather than the output of any prior equation or self-citation chain. The brief mention of aggregation across metrics introduces no definitional loop or reduction to inputs by construction, as no aggregation formula is supplied or required for the reported findings. The work is self-contained against external benchmarks and contains none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Popular benchmarks such as MMLU, GSM8K, ARC, and ITALIC accurately measure the capabilities relevant to the claim of being a step forward for Italian LLMs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
When performance is aggregated across all benchmark metrics, EngGPT2MoE-16B-A3B shows higher performance than the Italian models under evaluation while achieving lower results than some of the most performant international models
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Table 19: Average ranking for each benchmark dataset
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
Tom Brown et al. “Language Models are Few-Shot Learners”. In:Advances in Neural Information Processing Systems. Ed. by H. Larochelle et al. Vol. 33. Curran Associates, Inc., 2020, pp. 1877– 1901
work page 2020
-
[2]
Ashish Vaswani et al. “Attention is all you need”. In:Advances in neural information processing systems30 (2017)
work page 2017
-
[3]
Advances in machine translation: A comprehensive survey of large language models
Devalla Bhaskar Ganesh et al. “Advances in machine translation: A comprehensive survey of large language models”. In:2025 3rd International Conference on Intelligent Data Communication Tech- nologies and Internet of Things (IDCIoT). IEEE. 2025, pp. 1671–1675
work page 2025
-
[4]
Tear:Improvingllm-basedmachinetranslationwithsystematicself-refinement
ZhaopengFengetal.“Tear:Improvingllm-basedmachinetranslationwithsystematicself-refinement”. In:Findings of the Association for Computational Linguistics: NAACL 2025. 2025, pp. 3922–3938
work page 2025
-
[5]
A survey of large language model agents for question answering
Murong Yue. “A survey of large language model agents for question answering”. In:arXiv preprint arXiv:2503.19213(2025)
-
[6]
Controllable text generation for large language models: A survey
Xun Liang et al. “Controllable text generation for large language models: A survey”. In:arXiv preprint arXiv:2408.12599(2024)
-
[7]
A survey on large language model (llm) security and privacy: The good, the bad, and the ugly
Yifan Yao et al. “A survey on large language model (llm) security and privacy: The good, the bad, and the ugly”. In:High-Confidence Computing4.2 (2024), p. 100211
work page 2024
-
[8]
Small language models: Survey, measurements, and insights
Zhenyan Lu et al. “Small language models: Survey, measurements, and insights”. In:arXiv preprint arXiv:2409.15790(2024)
-
[9]
Training Compute-Optimal Large Language Models
Jordan Hoffmann et al. “Training compute-optimal large language models”. In:arXiv preprint arXiv:2203.1555610 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Finetuned Language Models Are Zero-Shot Learners
JasonWeietal.“Finetunedlanguagemodelsarezero-shotlearners”.In:arXiv preprint arXiv:2109.01652 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”. In: Advances in Neural Information Processing Systems35 (2022)
work page 2022
-
[12]
Training Language Models to Follow Instructions with Human Feedback
Long Ouyang et al. “Training Language Models to Follow Instructions with Human Feedback”. In: Advances in Neural Information Processing Systems35 (2022)
work page 2022
-
[13]
Scaling instruction-finetuned language models
Hyung Won Chung et al. “Scaling instruction-finetuned language models”. In:Journal of Machine Learning Research25.70 (2024), pp. 1–53
work page 2024
-
[14]
Toolformer: Language models can teach themselves to use tools
Timo Schick et al. “Toolformer: Language models can teach themselves to use tools”. In:Advances in neural information processing systems36 (2023), pp. 68539–68551
work page 2023
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang et al. “Voyager: An open-ended embodied agent with large language models”. In: arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Yiran Ding et al. “Longrope: Extending llm context window beyond 2 million tokens”. In:arXiv preprint arXiv:2402.13753(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie et al. “Gqa: Training generalized multi-query transformer models from multi-head checkpoints”. In:Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023, pp. 4895–4901
work page 2023
-
[18]
Sliding window attention training for efficient large language models
Zichuan Fu et al. “Sliding window attention training for efficient large language models”. In:arXiv preprint arXiv:2502.18845(2025)
-
[19]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer et al. “OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY- GATED MIXTURE-OF-EXPERTS LAYER”. In:International Conference on Learning Represen- tations. 2017.doi:1701.06538’
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Switch Transformers: Scaling to Trillion Param- eter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, and Noam Shazeer. “Switch Transformers: Scaling to Trillion Param- eter Models with Simple and Efficient Sparsity”. In:Journal of Machine Learning Research23.120 (2022), pp. 1–39
work page 2022
-
[21]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin et al. “GShard: Scaling Giant Models with Conditional Computation and Auto- matic Sharding”. In:arXiv preprint arXiv:2006.16668(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[22]
Ciarfaglia et al.EngGPT2: Sovereign, Efficient and Open Intelligence
G. Ciarfaglia et al.EngGPT2: Sovereign, Efficient and Open Intelligence. 2026. arXiv:2603.16430 [cs.CL].url:https://arxiv.org/abs/2603.16430. 24
-
[23]
Minerva LLMs: The First Family of Large Language Models Trained from ScratchonItalianData
Riccardo Orlando et al. “Minerva LLMs: The First Family of Large Language Models Trained from ScratchonItalianData”.In:Proceedings of the Tenth Italian Conference on Computational Linguis- tics (CLiC-it 2024). Ed. by Felice Dell’Orletta et al. Pisa, Italy: CEUR Workshop Proceedings, Dec. 2024, pp. 707–719.isbn: 979-12-210-7060-6.url:https://aclanthology.o...
work page 2024
-
[24]
Advanced natural-based interaction for the italian language: Llamantino-3-anita
Marco Polignano, Pierpaolo Basile, and Giovanni Semeraro. “Advanced natural-based interaction for the italian language: Llamantino-3-anita”. In:Scientific Reports(2026)
work page 2026
-
[25]
An Yang et al. “Qwen3 technical report”. In:arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Aaron Grattafiori et al. “The llama 3 herd of models”. In:arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Alexander H. Liu et al.Ministral 3. 2026. arXiv:2601.08584 [cs.CL].url:https://arxiv.org/ abs/2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Gemma Team et al.Gemma 3 Technical Report. 2025. arXiv:2503.19786 [cs.CL].url:https: //arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts lan- guage models
Damai Dai et al. “Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts lan- guage models”. In:Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, pp. 1280–1297
work page 2024
-
[30]
gpt-oss-120b & gpt-oss-20b Model Card
SandhiniAgarwaletal.“gpt-oss-120b&gpt-oss-20bmodelcard”.In:arXiv preprint arXiv:2508.10925 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Muon is Scalable for LLM Training
Jingyuan Liu et al. “Muon is scalable for llm training”. In:arXiv preprint arXiv:2502.16982(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Qiguang Chen et al. “Towards reasoning era: A survey of long chain-of-thought for reasoning large language models”. In:arXiv preprint arXiv:2503.09567(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Toward large reasoning models: A survey of reinforced reasoning with large language models
Fengli Xu et al. “Toward large reasoning models: A survey of reinforced reasoning with large language models”. In:Patterns6.10 (2025)
work page 2025
-
[34]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil et al. “Gorilla: Large language model connected with massive apis, 2023”. In:URL https://arxiv. org/abs/2305.15334(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Restgpt: Connecting large language models with real-world restful apis
Yifan Song et al. “Restgpt: Connecting large language models with real-world restful apis”. In: arXiv preprint arXiv:2306.06624(2023)
-
[36]
Art of Problem Solving Wiki, accessed July 2025
AIME.2024 AIME I. Art of Problem Solving Wiki, accessed July 2025. 2024.url:https : / / artofproblemsolving.com/wiki/index.php/2024_AIME_I
work page 2024
-
[37]
AIME.2025 AIME I. Art of Problem Solving Wiki. Held February 6, 2025. 2025.url:https: //artofproblemsolving.com/wiki/index.php/2025_AIME_I
work page 2025
-
[38]
Alignbench: Benchmarking chinese alignment of large language models
Xiao Liu et al. “Alignbench: Benchmarking chinese alignment of large language models”. In:Pro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, pp. 11621–11640
work page 2024
-
[39]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li et al. “Api-bank: A comprehensive benchmark for tool-augmented llms”. In:Proceedings of the 2023 conference on empirical methods in natural language processing. 2023, pp. 3102–3116
work page 2023
-
[40]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark et al. “Think you have solved question answering? try arc, the ai2 reasoning challenge”. In:arXiv preprint arXiv:1803.05457(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li et al. “From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline”. In:arXiv preprint arXiv:2406.11939(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Qin Zhu et al. “Autologi: Automated generation of logic puzzles for evaluating reasoning abilities of large language models”. In:arXiv preprint arXiv:2502.16906(2025)
-
[43]
Shishir G Patil et al. “The berkeley function calling leaderboard (bfcl): From tool use to agen- tic evaluation of large language models”. In:Forty-second International Conference on Machine Learning. 2025
work page 2025
-
[44]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models
Yuzhen Huang et al. “C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models”. In:Advances in neural information processing systems36 (2023), pp. 62991–63010
work page 2023
-
[45]
ChID: A large-scale Chinese IDiom dataset for cloze test
Chujie Zheng, Minlie Huang, and Aixin Sun. “ChID: A large-scale Chinese IDiom dataset for cloze test”. In:Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019, pp. 778–787. 25
work page 2019
-
[46]
CLUE: A Chinese Language Understanding Evaluation Benchmark
Liang Xu et al. “CLUE: A Chinese Language Understanding Evaluation Benchmark”. In:Pro- ceedings of the 28th International Conference on Computational Linguistics. Ed. by Donia Scott, Nuria Bel, and Chengqing Zong. Barcelona, Spain (Online): International Committee on Compu- tational Linguistics, Dec. 2020, pp. 4762–4772.doi:10.18653/v1/2020.coling-main.41...
-
[47]
Cmmlu: Measuring massive multitask language understanding in chinese
Haonan Li et al. “Cmmlu: Measuring massive multitask language understanding in chinese”. In: Findings of the Association for Computational Linguistics: ACL 2024. 2024, pp. 11260–11285
work page 2024
-
[48]
Codeelo: Benchmarking competition-level code generation of llms with human-comparable elo ratings
Shanghaoran Quan et al. “Codeelo: Benchmarking competition-level code generation of llms with human-comparable elo ratings”. In:arXiv preprint arXiv:2501.01257(2025)
-
[49]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua et al. “DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs”. In:Proceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019, pp. 2368–2378
work page 2019
-
[50]
Gorilla: Large language model connected with massive apis
Shishir G Patil et al. “Gorilla: Large language model connected with massive apis”. In:Advances in Neural Information Processing Systems37 (2024), pp. 126544–126565
work page 2024
-
[51]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein et al. “Gpqa: A graduate-level google-proof q&a benchmark”. In:First conference on language modeling. 2024
work page 2024
-
[52]
Training Verifiers to Solve Math Word Problems
KarlCobbeetal.“Trainingverifierstosolvemathwordproblems”.In:arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[53]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora et al. “Healthbench: Evaluating large language models towards improved human health”. In:arXiv preprint arXiv:2505.08775(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Hellaswag: Can a machine really finish your sentence?
Rowan Zellers et al. “Hellaswag: Can a machine really finish your sentence?” In:Proceedings of the 57th annual meeting of the association for computational linguistics. 2019, pp. 4791–4800
work page 2019
-
[55]
Long Phan et al. “Humanity’s last exam”. In:arXiv preprint arXiv:2501.14249(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Evaluating Large Language Models Trained on Code
MarkChenetal.“Evaluatinglargelanguagemodelstrainedoncode”.In:arXiv preprint arXiv:2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[57]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou et al. “Instruction-following evaluation for large language models”. In:arXiv preprint arXiv:2311.07911(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Include: Evaluating multilingual language understanding with regional knowledge
Angelika Romanou et al. “Include: Evaluating multilingual language understanding with regional knowledge”. In:arXiv preprint arXiv:2411.19799(2024)
-
[59]
∞Bench: Extending long context evaluation beyond 100K tokens
Xinrong Zhang et al. “∞Bench: Extending long context evaluation beyond 100K tokens”. In:Pro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, pp. 15262–15277
work page 2024
-
[60]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
ColinWhiteetal.“Livebench:Achallenging,contamination-freellmbenchmark”.In:arXiv preprint arXiv:2406.193144 (2024), p. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain et al. “Livecodebench: Holistic and contamination free evaluation of large language models for code”. In:arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks et al. “Measuring mathematical problem solving with the math dataset”. In:arXiv preprint arXiv:2103.03874(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[63]
Hunter Lightman et al. “Let’s verify step by step”. In:The twelfth international conference on learning representations. 2023
work page 2023
-
[64]
Jiawei Liu et al. “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation”. In:Advances in neural information processing systems36 (2023), pp. 21558–21572
work page 2023
-
[65]
Language Models are Multilingual Chain-of-Thought Reasoners
Freda Shi et al. “Language models are multilingual chain-of-thought reasoners”. In:arXiv preprint arXiv:2210.03057(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
P-mmeval: A parallel multilingual multitask benchmark for consistent evalu- ation of llms
Yidan Zhang et al. “P-mmeval: A parallel multilingual multitask benchmark for consistent evalu- ation of llms”. In:Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025, pp. 4809–4836
work page 2025
-
[67]
Measuring Massive Multitask Language Understanding
Dan Hendrycks et al. “Measuring massive multitask language understanding”. In:arXiv preprint arXiv:2009.03300(2020). 26
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[68]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang et al. “Mmlu-pro: A more robust and challenging multi-task language understanding benchmark”. In:Advances in Neural Information Processing Systems37 (2024), pp. 95266–95290
work page 2024
-
[69]
Aryo Pradipta Gema et al. “Are we done with mmlu?” In:Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025, pp. 5069–5096
work page 2025
-
[70]
Multi-if: Benchmarking llms on multi-turn and multilingual instructions following
Yun He et al. “Multi-if: Benchmarking llms on multi-turn and multilingual instructions following”. In:arXiv preprint arXiv:2410.15553(2024)
-
[71]
Multipl-e: A scalable and polyglot approach to benchmarking neural code generation
Federico Cassano et al. “Multipl-e: A scalable and polyglot approach to benchmarking neural code generation”. In:IEEE Transactions on Software Engineering49.7 (2023), pp. 3675–3691
work page 2023
-
[72]
Gregory Kamradt. “Llmtest_needleinahaystack”. In:GitHub repository(2023)
work page 2023
-
[73]
Nexusraven: a commercially-permissive language model for func- tion calling
Venkat Krishna Srinivasan et al. “Nexusraven: a commercially-permissive language model for func- tion calling”. In:NeurIPS 2023 Foundation Models for Decision Making Workshop. 2023
work page 2023
-
[74]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao et al. “The pile: An 800gb dataset of diverse text for language modeling”. In:arXiv preprint arXiv:2101.00027(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[75]
arXiv preprint arXiv:2504.18428 , year=
Yiming Wang et al. “Polymath: Evaluating mathematical reasoning in multilingual contexts”. In: arXiv preprint arXiv:2504.18428(2025)
-
[76]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh et al. “RULER: What’s the real context size of your long-context language models?” In:arXiv preprint arXiv:2404.06654(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Truthfulqa: Measuring how models mimic hu- man falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. “Truthfulqa: Measuring how models mimic hu- man falsehoods”. In:Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers). 2022, pp. 3214–3252
work page 2022
-
[78]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi et al. “Winogrande: An adversarial winograd schema challenge at scale”. In: Communications of the ACM64.9 (2021), pp. 99–106
work page 2021
-
[79]
Writingbench: A comprehensive benchmark for generative writing
Yuning Wu et al. “Writingbench: A comprehensive benchmark for generative writing”. In:arXiv preprint arXiv:2503.05244(2025)
-
[80]
Bill Yuchen Lin et al. “Zebralogic: On the scaling limits of llms for logical reasoning”. In:arXiv preprint arXiv:2502.01100(2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.