Generative Recursive Reasoning
Pith reviewed 2026-05-21 07:36 UTC · model grok-4.3
The pith
GRAM turns recursive latent reasoning into probabilistic multi-trajectory computation to support multiple hypotheses and unconditional generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
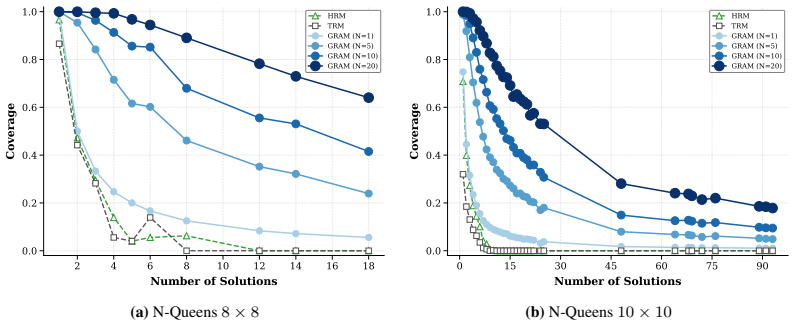
We introduce Generative Recursive reAsoning Models (GRAM), a framework that turns recursive latent reasoning into probabilistic multi-trajectory computation. GRAM models reasoning as a stochastic latent trajectory, enabling multiple hypotheses, alternative solution strategies, and inference-time scaling through both recursive depth and parallel trajectory sampling. This yields a latent-variable generative model supporting conditional reasoning via p_θ(y | x) and, with fixed or absent inputs, unconditional generation via p_θ(x).
What carries the argument
Stochastic latent trajectory that replaces the single deterministic path in recursive reasoning with probabilistic multi-trajectory computation.
Load-bearing premise
Amortized variational inference can train the stochastic latent trajectories to produce useful, non-collapsed multi-hypothesis reasoning without requiring task-specific architectural changes or post-hoc selection of trajectories.
What would settle it
A result on multi-solution tasks showing that sampling additional trajectories yields no gain in solution diversity or accuracy compared to the deterministic baseline.
Figures


















read the original abstract
How should future neural reasoning systems implement extended computation? Recursive Reasoning Models (RRMs) offer a promising alternative to autoregressive sequence extension by performing iterative latent-state refinement with shared transition functions. Yet existing RRMs are largely deterministic, following a single latent trajectory and converging to a single prediction. We introduce Generative Recursive reAsoning Models (GRAM), a framework that turns recursive latent reasoning into probabilistic multi-trajectory computation. GRAM models reasoning as a stochastic latent trajectory, enabling multiple hypotheses, alternative solution strategies, and inference-time scaling through both recursive depth and parallel trajectory sampling. This yields a latent-variable generative model supporting conditional reasoning via $p_\theta(y \mid x)$ and, with fixed or absent inputs, unconditional generation via $p_\theta(x)$. Trained with amortized variational inference, GRAM improves over deterministic recurrent and recursive baselines on structured reasoning and multi-solution constraint satisfaction tasks, while demonstrating an unconditional generation capability. https://ahn-ml.github.io/gram-website
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Generative Recursive reAsoning Models (GRAM) that extend deterministic Recursive Reasoning Models by modeling iterative latent-state refinement as stochastic multi-trajectory computation. This produces a latent-variable generative model supporting conditional reasoning via p_θ(y | x) and unconditional generation via p_θ(x). The approach is trained with amortized variational inference and is claimed to improve over deterministic recurrent and recursive baselines on structured reasoning and multi-solution constraint satisfaction tasks while enabling inference-time scaling via recursive depth and parallel trajectory sampling.
Significance. If the multi-trajectory mechanism produces genuinely distinct and useful hypotheses rather than collapsing, and if the reported gains are robustly quantified, the work would offer a principled extension of recursive models to probabilistic settings. This could support more flexible handling of uncertainty and alternative solutions in neural reasoning without requiring task-specific architectural modifications.
major comments (2)
- [§3 (Training and Inference)] The central claim that amortized variational inference trains the stochastic latent trajectories to yield non-collapsed, useful multi-hypothesis reasoning (without task-specific changes or post-hoc selection) is load-bearing for the distinction from deterministic RRMs. No analysis of trajectory diversity, posterior utilization of stochasticity, or KL-term behavior is referenced to rule out collapse to a single effective path.
- [Abstract and §4 (Experiments)] The abstract and results summary assert improvements over baselines on structured reasoning and multi-solution tasks, yet supply no quantitative metrics, error bars, dataset sizes, ablation controls, or statistical significance tests. This prevents verification that gains arise from the probabilistic multi-trajectory component rather than capacity or training differences.
minor comments (2)
- [Abstract] Notation for the generative model p_θ(y | x) and p_θ(x) is introduced clearly in the abstract but should be cross-referenced to the precise definitions of the latent trajectory variables and transition functions in the methods section for consistency.
- [Abstract] The website link is provided but the manuscript should include a brief summary of any additional experimental details or visualizations hosted there to ensure self-contained evaluation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript introducing Generative Recursive reAsoning Models (GRAM). We address each major comment below, providing clarifications and committing to specific revisions that strengthen the presentation of our training procedure and experimental results without altering the core claims.
read point-by-point responses
-
Referee: [§3 (Training and Inference)] The central claim that amortized variational inference trains the stochastic latent trajectories to yield non-collapsed, useful multi-hypothesis reasoning (without task-specific changes or post-hoc selection) is load-bearing for the distinction from deterministic RRMs. No analysis of trajectory diversity, posterior utilization of stochasticity, or KL-term behavior is referenced to rule out collapse to a single effective path.
Authors: We agree that the manuscript would benefit from explicit supporting analysis. In the revised version we will add to §3: (i) visualizations of distinct latent trajectories on example inputs, (ii) quantitative diversity metrics such as average pairwise Euclidean distance between final latent states across sampled trajectories, and (iii) plots of the KL divergence term over training epochs together with posterior utilization statistics (e.g., entropy of the approximate posterior). These additions will directly demonstrate that the stochasticity is actively used rather than collapsed. revision: yes
-
Referee: [Abstract and §4 (Experiments)] The abstract and results summary assert improvements over baselines on structured reasoning and multi-solution tasks, yet supply no quantitative metrics, error bars, dataset sizes, ablation controls, or statistical significance tests. This prevents verification that gains arise from the probabilistic multi-trajectory component rather than capacity or training differences.
Authors: The current manuscript contains tables reporting accuracy and success rates on the evaluated tasks, but we accept that error bars, explicit dataset cardinalities, ablation controls isolating the stochastic component, and significance testing are not present. We will revise §4 to include standard deviations over five random seeds, precise dataset sizes and splits, an ablation removing the stochastic latent transitions, and paired t-test p-values for all baseline comparisons. The abstract will be updated to reference these quantitative details. revision: yes
Circularity Check
No circularity: GRAM derivation introduces independent stochastic trajectories and VI training.
full rationale
The paper's core contribution is the definition of GRAM as a latent-variable model that converts deterministic recursive reasoning into stochastic multi-trajectory sampling, trained end-to-end via amortized variational inference to support both conditional p_θ(y|x) and unconditional p_θ(x) generation. This architecture and training procedure are presented as novel extensions beyond existing deterministic RRMs, with performance gains demonstrated empirically on structured reasoning and constraint satisfaction tasks. No load-bearing step reduces a claimed prediction or uniqueness result to a self-citation, fitted parameter renamed as output, or ansatz smuggled from prior author work; the derivation chain remains self-contained against external benchmarks and does not equate any output quantity to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Amortized variational inference can learn a useful posterior over stochastic latent trajectories for reasoning tasks.
invented entities (1)
-
GRAM (Generative Recursive reAsoning Model)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRAM models reasoning as a stochastic latent trajectory... z_t ~ p_θ(z_t | z_{t-1}, e_x) ... ϵ_t ~ N(μ_θ(u_t), σ²_θ(u_t)I) ... hierarchical instantiation z=(h,l)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Trained with amortized variational inference... ELBO... deep supervision over N_sup consecutive supervision steps
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[2]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[3]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
work page 2024
-
[4]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Reasoning by superposition: A theoretical perspective on chain of continuous thought.arXiv preprint arXiv:2505.12514, 2025
-
[6]
Halil Alperen Gozeten, M Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak. Continuous chain of thought enables parallel exploration and reasoning.arXiv preprint arXiv:2505.23648, 2025
-
[7]
Looped transformers are better at learning learning algorithms.arXiv preprint arXiv:2311.12424,
Liu Yang, Kangwook Lee, Robert Nowak, and Dimitris Papailiopoulos. Looped transformers are better at learning learning algorithms.arXiv preprint arXiv:2311.12424, 2023
-
[8]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Thinking, fast and slow.Farrar, Straus and Giroux, 2011
Daniel Kahneman. Thinking, fast and slow.Farrar, Straus and Giroux, 2011
work page 2011
-
[12]
arXiv:1709.08568 [cs.LG].https: //arxiv.org/abs/1709.08568
Yoshua Bengio. The consciousness prior.arXiv preprint arXiv:1709.08568, 2017
-
[13]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[14]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. Arc- agi-2: A new challenge for frontier ai reasoning systems.arXiv preprint arXiv:2505.11831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791
-
[16]
Ronald J Williams and Jing Peng. An efficient gradient-based algorithm for on-line training of recurrent network trajectories.Neural computation, 2(4):490–501, 1990
work page 1990
-
[17]
Unbiasing Truncated Backpropagation Through Time
Corentin Tallec and Yann Ollivier. Unbiasing truncated backpropagation through time.arXiv preprint arXiv:1705.08209, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartold- son, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Text generation beyond discrete token sampling.arXiv preprint arXiv:2505.14827, 2025
Yufan Zhuang, Liyuan Liu, Chandan Singh, Jingbo Shang, and Jianfeng Gao. Text generation beyond discrete token sampling.arXiv preprint arXiv:2505.14827, 2025
-
[20]
Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, Chenyang Zhao, Shuohang Wang, Yelong Shen, and Xin Eric Wang. Soft thinking: Unlocking the reasoning potential of llms in continuous concept space.arXiv preprint arXiv:2505.15778, 2025
-
[21]
Soft tokens, hard truths.arXiv preprint arXiv:2509.19170, 2025
Natasha Butt, Ariel Kwiatkowski, Ismail Labiad, Julia Kempe, and Yann Ollivier. Soft tokens, hard truths.arXiv preprint arXiv:2509.19170, 2025
-
[22]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Compressing chain-of-thought into continuous space via self-distillation.arXiv preprint arXiv:2502.21074, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Hybrid latent reasoning via reinforcement learning.arXiv preprint arXiv:2505.18454, 2025
Zhenrui Yue, Bowen Jin, Huimin Zeng, Honglei Zhuang, Zhen Qin, Jinsung Yoon, Lanyu Shang, Jiawei Han, and Dong Wang. Hybrid latent reasoning via reinforcement learning.arXiv preprint arXiv:2505.18454, 2025
-
[24]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, et al. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation.arXiv preprint arXiv:2507.10524, 2025
-
[25]
Amirkeivan Mohtashami, Matteo Pagliardini, and Martin Jaggi. Cotformer: A chain-of- thought driven architecture with budget-adaptive computation cost at inference.arXiv preprint arXiv:2310.10845, 2023
-
[26]
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise lora.arXiv preprint arXiv:2410.20672, 2024
-
[27]
Finding structure in time.Cognitive science, 14(2):179–211, 1990
Jeffrey L Elman. Finding structure in time.Cognitive science, 14(2):179–211, 1990
work page 1990
-
[28]
Long short-term memory.Neural computation, 9(8): 1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8): 1735–1780, 1997
work page 1997
-
[29]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder- decoder for statistical machine translation.arXiv preprint arXiv:1406.1078, 2014. 12
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations.arXiv preprint arXiv:1909.11942, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[31]
Depth-adaptive transformer.arXiv preprint arXiv:1910.10073, 2019
Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer.arXiv preprint arXiv:1910.10073, 2019
-
[32]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
A Recurrent Latent Variable Model for Sequential Data
Junyoung Chung, Kyle Kastner, Laurent Dinh, Kratarth Goel, Aaron Courville, and Yoshua Bengio. A recurrent latent variable model for sequential data, 2016. URL https://arxiv. org/abs/1506.02216
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
Sequential Neural Models with Stochastic Layers
Marco Fraccaro, Søren Kaae Sønderby, Ulrich Paquet, and Ole Winther. Sequential neural models with stochastic layers, 2016. URLhttps://arxiv.org/abs/1605.07571
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Rahul G. Krishnan, Uri Shalit, and David Sontag. Deep kalman filters, 2015. URL https: //arxiv.org/abs/1511.05121
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[36]
Learning Latent Dynamics for Planning from Pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels, 2019. URL https: //arxiv.org/abs/1811.04551
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[37]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[38]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[40]
ARC-Prize-Foundation. ARC-AGI benchmarking: Leaderboard and dataset for the ARC-AGI benchmark.https://arcprize.org/leaderboard, 2026. Accessed: 2026-1-22
work page 2026
-
[41]
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
work page 2024
-
[42]
Shane Barratt and Rishi Sharma. A note on the inception score.arXiv preprint arXiv:1801.01973, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[44]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
work page 2021
-
[45]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[46]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[47]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[48]
Simo Ryu. Minimal implementation of a d3pm (structured denoising diffusion models in discrete state-spaces), in pytorch.https://github.com/cloneofsimo/d3pm, 2024
work page 2024
-
[49]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 13
work page 2023
-
[50]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
work page 2002
-
[51]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
work page 2012
-
[52]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
work page 2018
-
[53]
Yuxin Wu and Kaiming He. Group normalization. InProceedings of the European conference on computer vision (ECCV), pages 3–19, 2018
work page 2018
-
[54]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
Improved techniques for training score-based generative models
Yang Song and Stefano Ermon. Improved techniques for training score-based generative models. Advances in neural information processing systems, 33:12438–12448, 2020
work page 2020
-
[57]
P. Erd˝os and A. Rényi. On the strength of connectedness of a random graph.Acta Mathematica Academiae Scientiarum Hungarica, 12(1):261–267, Mar 1964. ISSN 1588-2632. doi: 10.1007/ BF02066689. URLhttps://doi.org/10.1007/BF02066689
-
[58]
Henrique Lemos, Marcelo Prates, Pedro Avelar, and Luis Lamb. Graph colouring meets deep learning: Effective graph neural network models for combinatorial problems. In2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), pages 879–885. IEEE, 2019
work page 2019
-
[59]
Alexey L. Pomerantsev. Principal component analysis (pca).Encyclopedia of Autism Spectrum Disorders, 2014. URLhttps://api.semanticscholar.org/CorpusID:2534141
work page 2014
-
[60]
Multidimensional binary search trees used for associative searching.Com- mun
Jon Louis Bentley. Multidimensional binary search trees used for associative searching.Com- mun. ACM, 18:509–517, 1975. URL https://api.semanticscholar.org/CorpusID: 13091446. 14 A Additional Method Details A.1 Adaptive Computation Time GRAM optionally adopts adaptive computation time (ACT) [ 8–10] at inference, allowing each trajectory to terminate at a ...
work page 1975
-
[61]
Input Tokens (B, C, H, W) Linear Scaling[−1,1] (B, C, H, W)
Norm. Input Tokens (B, C, H, W) Linear Scaling[−1,1] (B, C, H, W)
-
[62]
Conv Conv2d5×5(p= 2) (B, D/2, H, W)SiLU→GN(32) Conv2d5×5(p= 2) (B, D/2, H, W)SiLU→GN(32)
-
[63]
Patch Flatten Patches (B, Np, P 2 · D 2 ) Linear Projection (B, Np, D) Hyperparameters.Following Wang et al. [8], Jolicoeur-Martineau [9], both the input and output are represented as sequences of shape [B, L], where B denotes the batch size and L the context length. Each input sequence includes 16 fixed puzzle embedding tokens. The latent states ht and l...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.