CARE-RL: Capability-Aware Reinforcement Learning for Mitigating Cross-Domain Conflicts
Pith reviewed 2026-06-28 18:59 UTC · model grok-4.3
The pith
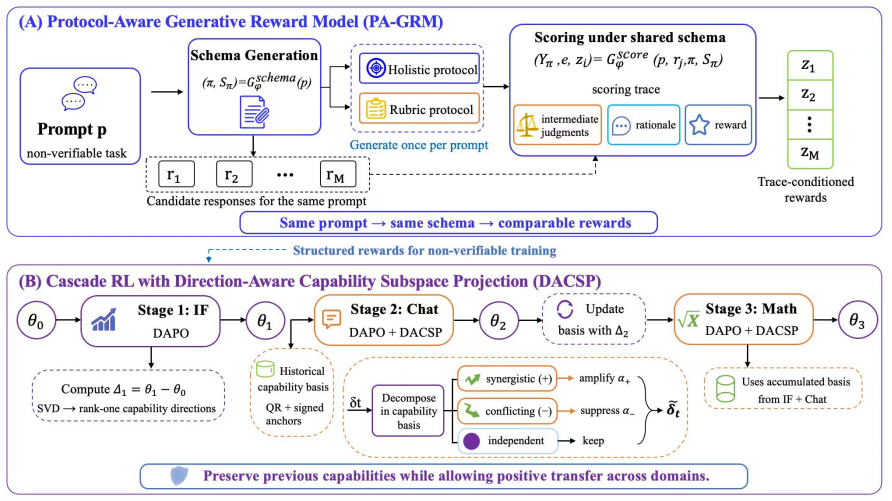
CARE-RL mitigates cross-domain capability conflicts during multi-domain RL for language models by modulating gradient updates with historical direction information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CARE-RL combines the Protocol-Aware Generative Reward Model, which builds prompt-level protocols before scoring open-ended responses, with Direction-Aware Capability Subspace Projection, which extracts historical capability directions from prior RL stages and modulates later parameter updates by amplifying, suppressing, or preserving components accordingly.
What carries the argument
Direction-Aware Capability Subspace Projection (DACSP), which identifies past capability directions and uses them to scale components of the current update vector.
If this is right
- Joint training across verifiable and non-verifiable domains becomes feasible without separate reward models per domain.
- Capability interference decreases, allowing higher combined performance on math, chat, and instruction benchmarks.
- Updates from one domain can be selectively preserved rather than overwritten when a new domain is added.
- The same projection logic can be applied at each RL stage after the first, creating a cumulative direction history.
Where Pith is reading between the lines
- The method implies that capability conflicts are the dominant bottleneck once reward generation is solved, so similar projection steps could help in non-RL multi-task fine-tuning.
- If the subspace extraction scales to longer training histories, the technique might support continual learning across many successive domains.
- The protocol-building step in the reward model could be reused in evaluation settings outside RL, such as preference data collection.
Load-bearing premise
Past capability directions extracted from earlier training stages remain stable and informative enough to guide amplification or suppression in later stages without erasing useful information or creating fresh conflicts.
What would settle it
Run CARE-RL on the same Qwen models and benchmarks; if total average scores fall below the standard multi-domain RL baselines or if performance drops sharply in one domain while rising in others, the conflict-mitigation claim does not hold.
Figures
read the original abstract
Reinforcement learning (RL) with verifiable rewards has achieved strong progress in reasoning-oriented LLMs, but extending it to multi-domain RL remains challenging due to reward unreliability in non-verifiable tasks and capability interference across domains. We propose CARE-RL to combine protocol-aware reward generation with capability-aware optimization for mitigating cross-domain conflicts. For non-verifiable tasks, the Protocol-Aware Generative Reward Model (PA-GRM) constructs prompt-level evaluation protocols and schemas before producing trace-conditioned rewards, enabling task-adaptive yet comparable evaluation of open-ended responses. For multi-domain optimization, Direction-Aware Capability Subspace Projection (DACSP) extracts historical capability directions from previous RL stages and modulates later updates by amplifying aligned components, suppressing conflicting components, and preserving orthogonal updates. Experiments across math, chat, and instruction-following benchmarks show that CARE-RL consistently outperforms standard multi-domain RL baselines, achieving Total Avg scores of 47.9 and 50.7 on Qwen2.5-7B and Qwen3-4B, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CARE-RL, a framework for multi-domain RL in LLMs that integrates the Protocol-Aware Generative Reward Model (PA-GRM) to construct prompt-level evaluation protocols and generate trace-conditioned rewards for non-verifiable tasks, and the Direction-Aware Capability Subspace Projection (DACSP) to extract historical capability directions from prior RL stages and modulate subsequent updates by amplifying aligned components, suppressing conflicting ones, and preserving orthogonal updates. Experiments across math, chat, and instruction-following benchmarks report that CARE-RL outperforms standard multi-domain RL baselines, with Total Avg scores of 47.9 on Qwen2.5-7B and 50.7 on Qwen3-4B.
Significance. If the results hold, the work targets a practically important obstacle in scaling verifiable-reward RL to heterogeneous domains without capability interference. The two introduced components (PA-GRM and DACSP) are novel and, if shown to be effective, could supply a reusable template for conflict-aware multi-task optimization. The reported aggregate scores indicate potential utility, but the overall significance depends on whether the performance lift is driven by the DACSP mechanism rather than PA-GRM alone or other unisolated factors.
major comments (1)
- [DACSP description (methods)] DACSP description (methods): the central claim that historical capability directions can be reliably extracted and used to amplify/suppress/preserve update components without information loss or new conflicts is load-bearing for the cross-domain mitigation result, yet the manuscript supplies neither an explicit definition of “direction,” the projection operator, nor any ablation that isolates this step from PA-GRM. Without these, the geometric separability assumption remains unsupported and the headline performance numbers cannot be attributed to the proposed conflict-mitigation technique.
minor comments (1)
- The abstract states aggregate scores but does not name the exact baselines, report per-domain breakdowns, or include error bars or statistical tests; adding these would strengthen the empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the DACSP component. We agree that the current manuscript does not supply the requested explicit definitions or isolating ablation, and we will revise to address this.
read point-by-point responses
-
Referee: [DACSP description (methods)] DACSP description (methods): the central claim that historical capability directions can be reliably extracted and used to amplify/suppress/preserve update components without information loss or new conflicts is load-bearing for the cross-domain mitigation result, yet the manuscript supplies neither an explicit definition of “direction,” the projection operator, nor any ablation that isolates this step from PA-GRM. Without these, the geometric separability assumption remains unsupported and the headline performance numbers cannot be attributed to the proposed conflict-mitigation technique.
Authors: We acknowledge that the manuscript lacks an explicit mathematical definition of “capability direction,” the precise projection operator, and an ablation isolating DACSP from PA-GRM. This is a substantive gap that prevents full attribution of results to the conflict-mitigation mechanism. In the revised manuscript we will add: (1) a formal definition of directions as the top-k principal components of the covariance matrix of historical policy-gradient vectors from prior RL stages; (2) the explicit projection operator (orthogonal projection onto the span of these directions, with formulas for amplification, suppression, and preservation of components); and (3) new ablation experiments that run the full pipeline with and without the DACSP modulation step while keeping PA-GRM fixed. These additions will directly support the geometric separability claim and allow readers to attribute performance differences. revision: yes
Circularity Check
No circularity detected; method descriptions remain self-contained without reductions to inputs or self-citations.
full rationale
The provided abstract and description introduce PA-GRM and DACSP as conceptual components for reward generation and capability projection, but contain no equations, fitted parameters, or self-citations. No derivation chain is shown that reduces a claimed prediction or result to its own inputs by construction. Experimental performance numbers are presented as benchmark outcomes rather than fitted quantities renamed as predictions. The derivation is therefore self-contained against external benchmarks with no load-bearing circular steps identifiable from the text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning with verifiable rewards has achieved strong progress in reasoning-oriented LLMs
- domain assumption Extending RL to multi-domain settings is challenged by reward unreliability and capability interference
invented entities (2)
-
Protocol-Aware Generative Reward Model (PA-GRM)
no independent evidence
-
Direction-Aware Capability Subspace Projection (DACSP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2501.12948 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2501.12599 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base
Xumeng Wen and Zihan Liu and Shun Zheng and Zhijian Xu and Shengyu Ye and Zhirong Wu and Xiao Liang and Yang Wang and Junjie Li and Ziming Miao and Jiang Bian and Mao Yang , journal =. Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base. 2025 , url =
2025
-
[4]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Yu and Guo, Daya , journal =
-
[5]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks , author=. arXiv preprint arXiv:2504.05118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2505.21493 , year=
Reinforcing general reasoning without verifiers , author=. arXiv preprint arXiv:2505.21493 , year=
-
[8]
Hu, Jingcheng and Zhang, Yinmin and Han, Qi and Jiang, Daxin and Zhang, Xiangyu and Shum, Heung-Yeung , journal =
-
[9]
arXiv preprint arXiv:2510.25528 , year =
Zero Reinforcement Learning Towards General Domains , author =. arXiv preprint arXiv:2510.25528 , year =
-
[10]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains , author =. arXiv preprint arXiv:2507.17746 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Xu, Ran and others , journal =
-
[12]
arXiv preprint arXiv:2602.14069 , year =
Open Rubric System: Scaling Reinforcement Learning with Pairwise Adaptive Rubric , author =. arXiv preprint arXiv:2602.14069 , year =
-
[13]
and Qiu, Xinchi and Whitehouse, Chenxi and Alazraki, Lisa and Goel, Shashwat and Barbieri, Francesco and Willi, Timon and Mathur, Akhil and Leontiadis, Ilias , journal =
Shen, William F. and Qiu, Xinchi and Whitehouse, Chenxi and Alazraki, Lisa and Goel, Shashwat and Barbieri, Francesco and Willi, Timon and Mathur, Akhil and Leontiadis, Ilias , journal =. Rethinking Rubric Generation for Improving
-
[14]
arXiv preprint arXiv:2601.04954 , year =
Precision over Diversity: High-Precision Reward Generalizes to Robust Instruction Following , author =. arXiv preprint arXiv:2601.04954 , year =
-
[15]
arXiv preprint , year =
To Mix or to Merge? Comparing Mixed Reinforcement Learning and Model Merging for General-Domain Reasoning , author =. arXiv preprint , year =
-
[16]
arXiv preprint , year =
Imbalanced Gradients in Multi-Objective Reinforcement Learning for Large Language Models , author =. arXiv preprint , year =
-
[17]
2026 , note =
Anonymous , journal =. 2026 , note =
2026
-
[18]
arXiv preprint arXiv:2305.14251 , year =
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation , author =. arXiv preprint arXiv:2305.14251 , year =
-
[19]
arXiv preprint arXiv:2501.03545 , year =
Beyond Factual Accuracy: Evaluating Coverage of Diverse Factual Information in Long-form Text Generation , author =. arXiv preprint arXiv:2501.03545 , year =
-
[20]
Beyond Reasoning Gains: Mitigating General-Capability Forgetting in Large Reasoning Models
Beyond Reasoning Gains: Mitigating General Capabilities Forgetting in Large Reasoning Models , author =. arXiv preprint arXiv:2510.21978 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization , author =. arXiv preprint arXiv:2601.05242 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2602.11661 , year =
Quark Medical Alignment: A Holistic Multi-Dimensional Alignment and Collaborative Optimization Paradigm , author =. arXiv preprint arXiv:2602.11661 , year =
-
[23]
arXiv preprint arXiv:2603.01562 , year=
RubricBench: Aligning Model-Generated Rubrics with Human Standards , author=. arXiv preprint arXiv:2603.01562 , year=
-
[24]
JudgeBench: A Benchmark for Evaluating LLM-based Judges
Judgebench: A benchmark for evaluating llm-based judges , author=. arXiv preprint arXiv:2410.12784 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
RewardBench 2: Advancing Reward Model Evaluation
Rewardbench 2: Advancing reward model evaluation , author=. arXiv preprint arXiv:2506.01937 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2410.16184 , year=
Rm-bench: Benchmarking reward models of language models with subtlety and style , author=. arXiv preprint arXiv:2410.16184 , year=
-
[27]
Hunter Lightman and Vineet Kosaraju and Yura Burda and Harri Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , journal=. Let. 2023 , doi=
2023
-
[28]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=. doi:10.48550/arXiv.2110.14168 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168
-
[29]
2024 , doi=
Bill Yuchen Lin and Yuntian Deng and Khyathi Chandu and Faeze Brahman and Abhilasha Ravichander and Valentina Pyatkin and Nouha Dziri and Ronan Le Bras and Yejin Choi , journal=. 2024 , doi=
2024
-
[30]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois and Bal. Length-Controlled. arXiv preprint arXiv:2404.04475 , year=. doi:10.48550/arXiv.2404.04475 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.04475
-
[31]
Generalizing Verifiable Instruction Following
Generalizing Verifiable Instruction Following , author=. arXiv preprint arXiv:2507.02833 , year=. doi:10.48550/arXiv.2507.02833 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.02833
-
[32]
Gema, Aryo Pradipta and Leang, Joshua Ong Jun and Hong, Giwon and Devoto, Alessio and Mancino, Alberto Carlo Maria and Saxena, Rohit and He, Xuanli and Zhao, Yu and Du, Xiaotang and Ghasemi Madani, Mohammad Reza and Barale, Claire and McHardy, Robert and Harris, Joshua and Kaddour, Jean and Van Krieken, Emile and Minervini, Pasquale , editor=. Are We Done...
-
[33]
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month=. 2023 , address=. doi:10.18653/v1/2023.acl-long.546 , pages=
-
[34]
Proceedings of the 42nd International Conference on Machine Learning , pages=
Lin, Bill Yuchen and Le Bras, Ronan and Richardson, Kyle and Sabharwal, Ashish and Poovendran, Radha and Clark, Peter and Choi, Yejin , editor=. Proceedings of the 42nd International Conference on Machine Learning , pages=. 2025 , volume=
2025
-
[35]
arXiv preprint arXiv:2504.13941 , year =
Nemotron-CrossThink: Scaling Self-Learning beyond Math Reasoning , author =. arXiv preprint arXiv:2504.13941 , year =
-
[36]
arXiv preprint arXiv:2505.14652 , year =
General-Reasoner: Advancing LLM Reasoning Across All Domains , author =. arXiv preprint arXiv:2505.14652 , year =
-
[37]
arXiv preprint arXiv:2509.20357 , year =
Language Models that Think, Chat Better , author =. arXiv preprint arXiv:2509.20357 , year =
-
[38]
arXiv preprint arXiv:2602.02301 , year =
Advancing General-Purpose Reasoning Models with Modular Gradient Surgery , author =. arXiv preprint arXiv:2602.02301 , year =
-
[39]
arXiv preprint arXiv:2602.05547 , year =
Multi-Task GRPO: Reliable LLM Reasoning Across Tasks , author =. arXiv preprint arXiv:2602.05547 , year =
-
[40]
arXiv preprint arXiv:2512.13607 , year =
Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models , author =. arXiv preprint arXiv:2512.13607 , year =
-
[41]
arXiv preprint arXiv:2603.19220 , year =
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation , author =. arXiv preprint arXiv:2603.19220 , year =
-
[42]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. arXiv preprint arXiv:2101.03961 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Mixtral of Experts , author =. arXiv preprint arXiv:2401.04088 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models , author =. arXiv preprint arXiv:2401.06066 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:2505.02387 , year =
RM-R1: Reward Modeling as Reasoning , author =. arXiv preprint arXiv:2505.02387 , year =
-
[46]
arXiv preprint arXiv:2510.23596 , year =
Think Twice: Branch-and-Rethink Reasoning Reward Model , author =. arXiv preprint arXiv:2510.23596 , year =
-
[47]
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research , author =. arXiv preprint arXiv:2511.19399 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2510.20369 , year =
Ask a Strong LLM Judge when Your Reward Model is Uncertain , author =. arXiv preprint arXiv:2510.20369 , year =
-
[49]
arXiv preprint arXiv:2602.06570 , year =
Baichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making , author =. arXiv preprint arXiv:2602.06570 , year =
-
[50]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
-
[51]
Llama Team , title =. CoRR , volume =. 2024 , url =. doi:10.48550/arXiv.2407.21783 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[52]
CoRR , volume =
Weihao Zeng and Yuzhen Huang and Qian Liu and Wei Liu and Keqing He and Zejun Ma and Junxian He , title =. CoRR , volume =. 2025 , url =
2025
-
[53]
arXiv preprint arXiv:2509.20357 , year =
Adithya Bhaskar and Xi Ye and Danqi Chen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/arXiv.2509.20357 , eprinttype =
-
[54]
CoRR , volume =
Chris Yuhao Liu and Liang Zeng and Yuzhen Xiao and Jujie He and Jiacai Liu and Chaojie Wang and Rui Yan and Wei Shen and Fuxiang Zhang and Jiacheng Xu and Yang Liu and Yahui Zhou , title =. CoRR , volume =. 2025 , url =
2025
-
[55]
2025 , month = sep, howpublished =
NVIDIA , title =. 2025 , month = sep, howpublished =
2025
-
[56]
Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar
Researchqa: Evaluating scholarly question answering at scale across 75 fields with survey-mined questions and rubrics , author=. arXiv preprint arXiv:2509.00496 , year=
-
[57]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Instruction-Following Evaluation for Large Language Models
Instruction-Following Evaluation for Large Language Models , author =. arXiv preprint arXiv:2311.07911 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Advances in Neural Information Processing Systems , volume =
Gradient Surgery for Multi-Task Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[62]
Advances in Neural Information Processing Systems , volume =
Conflict-Averse Gradient Descent for Multi-task Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[63]
arXiv preprint arXiv:2410.12832 , year =
Generative Reward Models , author =. arXiv preprint arXiv:2410.12832 , year =
-
[64]
Proceedings of the 40th International Conference on Machine Learning , pages =
Scaling Laws for Reward Model Overoptimization , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[65]
Proceedings of the 37th International Conference on Machine Learning , pages =
Which Tasks Should Be Learned Together in Multi-task Learning? , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[66]
2025 , eprint =
One Token to Fool LLM-as-a-Judge , author =. 2025 , eprint =
2025
-
[67]
2026 , eprint =
When Domains Interact: Asymmetric and Order-Sensitive Cross-Domain Effects in Reinforcement Learning for Reasoning , author =. 2026 , eprint =
2026
-
[68]
Findings of the Association for Computational Linguistics: EACL 2026 , pages =
Imbalanced Gradients in RL Post-Training of Multi-Task LLMs , author =. Findings of the Association for Computational Linguistics: EACL 2026 , pages =. 2026 , publisher =
2026
-
[69]
2026 , eprint =
To Mix or To Merge: Toward Multi-Domain Reinforcement Learning for Large Language Models , author =. 2026 , eprint =
2026
-
[70]
Crossing the reward bridge: Expanding rl with verifiable rewards across diverse domains , author=. arXiv preprint arXiv:2503.23829 , year=
-
[71]
Smith, and Hannaneh Hajishirzi
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, LJ and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh. R eward B ench: Evaluating Reward Models for Language Modeling. Findings of the Association for Computational Linguistics: NAACL 20...
-
[72]
arXiv preprint arXiv:2506.14965 , year =
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective , author =. arXiv preprint arXiv:2506.14965 , year =
-
[73]
arXiv preprint arXiv:2602.01365 , year =
When Domains Interact: Asymmetric and Order-Sensitive Cross-Domain Effects in Reinforcement Learning for Reasoning , author =. arXiv preprint arXiv:2602.01365 , year =
-
[74]
International Conference on Learning Representations , year =
Spurious Forgetting in Continual Learning of Language Models , author =. International Conference on Learning Representations , year =
-
[75]
2025 , eprint =
A Survey on Progress in LLM Alignment from the Perspective of Reward Design , author =. 2025 , eprint =
2025
-
[76]
2025 , eprint =
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective , author =. 2025 , eprint =
2025
-
[77]
International Conference on Learning Representations , volume=
Generative verifiers: Reward modeling as next-token prediction , author=. International Conference on Learning Representations , volume=
-
[78]
Rlpr: Extrapolating rlvr to general domains without verifiers
RLPR: Extrapolating RLVR to General Domains without Verifiers , author=. arXiv preprint arXiv:2506.18254 , year=
-
[79]
UltraFeedback: Boosting Language Models with Scaled AI Feedback
Ultrafeedback: Boosting language models with scaled ai feedback , author=. arXiv preprint arXiv:2310.01377 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Helpsteer3: Human-annotated feedback and edit data to empower inference-time scaling in open-ended general-domain tasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.